

33.2 XML 
Das Modul xml der Standardbibliothek erlaubt es, XML-Dateien einzulesen und zu schreiben. XML (kurz für »Extensible Markup Language«) ist eine standardisierte Beschreibungssprache, die es ermöglicht, komplexe, hierarchisch aufgebaute Datenstrukturen in einem lesbaren Textformat abzuspeichern. XML kann daher gut zum Datenaustausch bzw. zur Datenspeicherung verwendet werden. Besonders in der Welt des Internets finden sich viele auf XML basierende Beschreibungssprachen, wie beispielsweise XHTML, RSS, MathML oder SVG.
An dieser Stelle erhalten Sie eine kurze Einführung in XML. Dazu dient folgende einfache XML-Datei, die eine Möglichkeit darstellt, den Inhalt eines Python-Dictionarys dauerhaft abzuspeichern:
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<eintrag>
<schluessel>Hallo</schluessel>
<wert>0</wert>
</eintrag>
<eintrag>
<schluessel>Welt</schluessel>
<wert>1</wert>
</eintrag>
</dictionary>
Die erste Zeile der Datei ist die XML-Deklaration. Diese optionale Angabe kennzeichnet die verwendete XML-Version und das Encoding, in dem die Datei gespeichert wurde. Durch Angabe des Encodings, in diesem Fall UTF-8, können auch Umlaute und andere Sonderzeichen korrekt verarbeitet werden. Näheres zu Encodings erfahren Sie im Zusammenhang mit Strings in Abschnitt 13.4.4.
Abgesehen von der XML-Deklaration besteht ein XML-Dokument aus Tags. Ein Tag gibt es wie eine Klammer in einer öffnenden und einer schließenden Variante. Es stellt damit eine Art Gruppe dar, die weitere Tags enthalten kann. Jedes Tag hat einen Namen, den Tag-Namen. Um ein Tag zu öffnen, wird dieser Tag-Name in spitze Klammern geschrieben. Ein schließendes Tag besteht aus dem Tag-Namen, der zusammen mit einem Slash ebenfalls in spitze Klammern geschrieben wird. Das folgende Beispiel zeigt ein öffnendes Tag, direkt gefolgt von dem entsprechenden schließenden Tag:
<wert></wert>
Zwischen einem öffnenden und dem korrespondierenden schließenden Tag können sowohl Text als auch weitere Tags stehen. Auf diese Weise lässt sich eine hierarchische Struktur erstellen, die dazu in der Lage ist, auch komplexe Datensätze abzubilden.
Zudem können Sie bei einem Tag Attribute angeben. Dazu erweitern wir das vorangegangene Beispiel dahingehend, dass der Datentyp der Schlüssel und Werte des abzubildenden Dictionarys als Attribut des jeweiligen schluessel- bzw. wert-Tags gespeichert wird.
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<eintrag>
<schluessel typ="str">Hallo</schluessel>
<wert typ="int">0</wert>
</eintrag>
<eintrag>
<schluessel typ="str">Welt</schluessel>
<wert typ="int">1</wert>
</eintrag>
</dictionary>
Ein Attribut stellt ein Schlüssel-Wert-Paar dar. Im Beispiel wird jedem schluessel- und wert-Tag ein Attribut typ verpasst, über das der Datentyp des Schlüssels bzw. des Wertes angegeben werden kann. Den Wert eines XML-Attributs müssen Sie immer in Anführungszeichen schreiben.
[»] Hinweis
Eine Besonderheit bei XML-Tags stellen körperlose Tags dar. Ein körperloses Tag sieht folgendermaßen aus:
<tag attr="wert" />
Ein körperloses Tag ist öffnendes und schließendes Tag zugleich und darf demzufolge nur über Attribute verfügen. Ein solches Tag kann keinen Text oder weitere Tags enthalten. Ein XML-Parser behandelt ein körperloses Tag, als stünde <tag attr="wert"></tag> in der XML-Datei.
Zum Einlesen von XML-Dateien stellt Python, wie die meisten anderen Programmiersprachen oder XML-Bibliotheken auch, verschiedene Parser zur Verfügung. Der Begriff des Parsers ist nicht auf XML beschränkt, sondern bezeichnet allgemein ein Programm, das eine Syntaxanalyse bestimmter Daten eines speziellen Formats leistet.
Grundsätzlich können zwei Herangehensweisen an das XML-Dokument unterschieden werden:
- Das Dokument wird als Ganzes gelesen und zu einer Klassenstruktur aufbereitet. Inhalte können erst bearbeitet werden, nachdem das Dokument vollständig eingelesen wurde. Diese Methode ermöglicht den wahlfreien Datenzugriff.
- Das Dokument wird sequenziell gelesen. Inhalte können bereits bearbeitet werden, wenn das Dokument noch nicht vollständig eingelesen wurde. Außerdem muss das Dokument zu keiner Zeit vollständig in den Arbeitsspeicher geladen werden.
Für den ersten Ansatz stehen im Modul xml die Parser dom und ElementTree zur Verfügung. Während dom das standardisierte Document Object Model implementiert, das in äquivalenter Form auch für viele andere Programmiersprachen verfügbar ist, stellt ElementTree eine auf Python zugeschnittene Schnittstelle zu XML-Dateien bereit. Aus diesem Grund werden wir an dieser Stelle ausschließlich auf ElementTree eingehen.
Für die zweite, sequenzielle Herangehensweise an ein XML-Dokument können Sie das Modul sax des Pakets xml verwenden. Dieses Modul lernen Sie in Abschnitt 33.2.2, »SAX – Simple API for XML«, kennen.
33.2.1 ElementTree
Das Modul xml.etree.ElementTree liest eine XML-Datei vollständig ein und bereitet die enthaltenen Daten zu einer Baumstruktur auf. Damit ermöglicht es, auf einzelne Elemente der XML-Datei zuzugreifen und diese zu modifizieren. Tags werden in dem resultierenden Element Tree durch Klassen repräsentiert, die sogenannten Knoten (engl. nodes). Durch Methoden und Attribute dieser Knotenklassen können die enthaltenen Informationen ausgelesen oder verändert werden.
Diese Herangehensweise ist vor allem dann interessant, wenn ein wahlfreier Zugriff auf die XML-Daten erforderlich ist. Unter einem wahlfreien Zugriff versteht man den punktuellen Zugriff auf verschiedene, voneinander unabhängige Teile des Datensatzes. Das Gegenteil des wahlfreien Zugriffs ist das sequenzielle Einlesen der XML-Datei. Dieser Ansatz wird mit dem SAX-Parser verfolgt, der in Abschnitt 33.2.2 besprochen wird.
Da die Datei zur Erzeugung des Element Trees stets vollständig eingelesen wird, ist die Verwendung von ElementTree für große Dateien speicherintensiv. Im Gegensatz dazu liest das Konkurrenzmodell SAX immer nur kleine Teile der XML-Daten ein und stellt sie sofort zur Weiterverarbeitung zur Verfügung. Diese Herangehensweise benötigt weniger Arbeitsspeicher und erlaubt es, Teile der gespeicherten Daten bereits zu verwenden, beispielsweise anzuzeigen, während die Datei selbst noch nicht vollständig eingelesen ist. Ein wahlfreier Zugriff auf die XML-Daten und ihre Manipulation ist mit SAX allerdings nicht möglich.
Der Element Tree
Kommen wir darauf zu sprechen, wie die XML-Daten bei Verwendung von ElementTree aufbereitet werden. Betrachten Sie dazu noch einmal unser vorangegangenes Beispiel einer XML-Datei:
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<eintrag>
<schluessel typ="str">Hallo</schluessel>
<wert typ="int">0</wert>
</eintrag>
<eintrag>
<schluessel typ="str">Welt</schluessel>
<wert typ="int">1</wert>
</eintrag>
</dictionary>
Mit dem ElementTree-Parser werden die XML-Daten zu einem Baum aufbereitet. Ein Baum besteht aus einzelnen Knoten, die durch Klassen abgebildet werden. Jede dieser Knotenklassen enthält verschiedene Referenzen auf benachbarte Knoten, nämlich:
- ihr Elternelement (engl. parent). Das ist der Knoten, der im Baum direkt über diesem Knoten steht.
- ihre Kindelemente (engl. children). Das sind alle Knoten, die im Baum direkt unter diesem Knoten stehen.
- ihre Geschwisterelemente (engl. siblings). Das sind alle Knoten, die im Baum direkt neben diesem Knoten stehen und dasselbe Elternelement haben.
Somit enthält jeder Knoten des Baums Referenzen zu allen umliegenden verwandten Knoten. Auf diese Weise lässt sich der Baum vollständig durchlaufen und verarbeiten. Die aus dem oben dargestellten Beispiel erzeugte Baumstruktur sieht so aus:
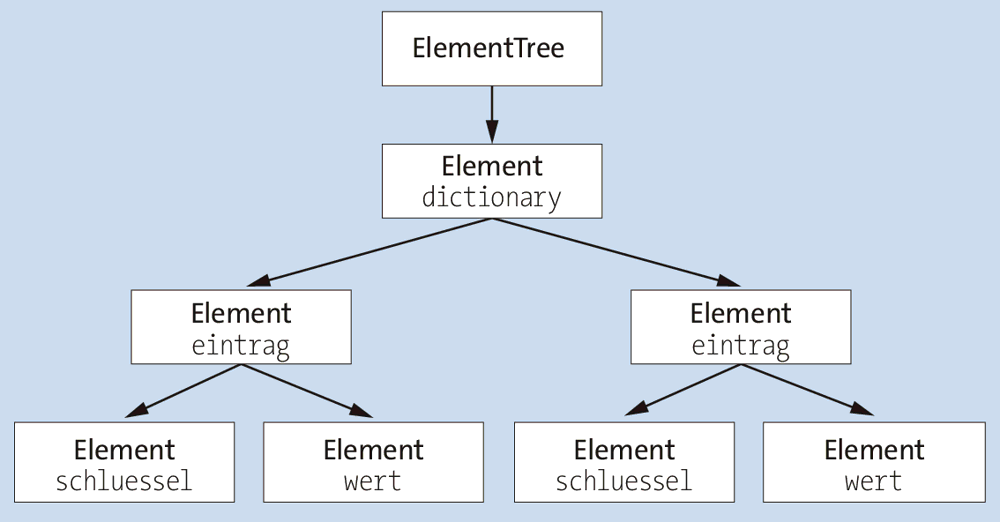
Abbildung 33.1 Erzeugter Element Tree
Die Wurzel des Element Trees (engl. root) ist eine Instanz der Klasse ElementTree, die eine Hierarchie von Element-Instanzen enthält, die jeweils über einen Tag-Namen verfügen. Außerdem können Element-Instanzen eine beliebige Menge von Attributen besitzen und einen Text enthalten.
Eine XML-Datei lesen
An dieser Stelle zeigen wir Ihnen die Verwendung von ElementTree an einem einfachen Beispiel. Dazu rufen wir uns erneut unsere Beispieldatei ins Gedächtnis, deren Zweck es war, den Inhalt eines Python-Dictionarys abzubilden:
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<eintrag>
<schluessel typ="str">Hallo</schluessel>
<wert typ="int">0</wert>
</eintrag>
</dictionary>
Die Datei besteht aus einem Tag erster Ordnung namens dictionary, in dem mehrere eintrag-Tags vorkommen dürfen. Jedes eintrag-Tag enthält zwei untergeordnete Tags namens schluessel und wert, die gemeinsam jeweils ein Schlüssel-Wert-Paar des Dictionarys repräsentieren. Der Datentyp des Schlüssels bzw. des Wertes wird über das Attribut typ festgelegt, das bei den Tags schluessel und wert vorkommen muss.
Ein Programm, das ElementTree verwendet, um eine XML-Datei dieses Formats zu laden, sieht folgendermaßen aus:
import xml.etree.ElementTree as ElementTree
typen = {
"int" : int,
"str" : str
}
def lese_element(element):
typ = element.get("typ", "str")
try:
return typen[typ](element.text)
except KeyError:
return element.text
def lade_dict(dateiname):
d = {}
baum = ElementTree.parse(dateiname)
tag_dict = baum.getroot()
for eintrag in tag_dict:
tag_schluessel = eintrag.find("schluessel")
tag_wert = eintrag.find("wert")
d[lese_element(tag_schluessel)] = lese_element(tag_wert)
return d
Zunächst wird die Funktion lese_element implementiert, die aus der Element-Instanz eines schluessel- oder wert-Tags das Attribut typ ausliest und den vom jeweiligen Tag umschlossenen Text in den durch typ angegebenen Datentyp konvertiert. Der Inhalt des Tags wird dann als Instanz des passenden Datentyps zurückgegeben.
Die Hauptfunktion des Beispielprogramms lade_dict bekommt den Dateinamen einer XML-Datei übergeben und soll die darin enthaltenen Daten zu einem Python-Dictionary aufbereiten. Dazu wird die XML-Datei zunächst mithilfe der Funktion parse des Moduls ElementTree zu einem Baum aufbereitet. Dieser Funktion kann sowohl ein Dateiname als auch ein geöffnetes Dateiobjekt übergeben werden. Danach wird der Referenz tag_dict das Wurzelelement des Baums zugewiesen, um auf diesem weiterzuoperieren.
Die nun folgende Schleife iteriert über alle Kindelemente des Wurzelelements, also über alle eintrag-Tags. In jedem Iterationsschritt werden die ersten Kindelemente mit den Tag-Namen schluessel und wert gesucht und den Referenzen tag_schluessel und tag_wert zugewiesen. Am Ende des Schleifenkörpers werden die Element-Instanzen der jeweiligen schluessel- oder wert-Tags durch die Funktion lese_text geschleust, was den im Tag-Körper enthaltenen Text in eine Instanz des korrekten Datentyps konvertiert. Die resultierenden Instanzen werden als Schlüssel bzw. als Wert in das Dictionary d eingetragen. Schließlich wird das erzeugte Dictionary d zurückgegeben.
Das mit lade_dict aus der eingangs angegebenen XML-Datei gelesene Dictionary sieht folgendermaßen aus:
>>> lade_dict("dict.xml")
{'Hallo': 0}
[»] Hinweis
Anstatt die XML-Daten aus einer Datei zu lesen, können sie auch in einem String vorliegen und mithilfe der Methode fromstring zu einem Element Tree aufbereitet werden:
>>> daten = "<tag attr='wert'/>"
>>> ElementTree.fromstring(daten)
<Element 'tag' at 0x7f4762a31548>
Beachten Sie, dass in diesem Fall eine Element-Instanz zurückgegeben wird und keine ElementTree-Instanz.
Eine XML-Datei schreiben
Im vorangegangenen Abschnitt wurde das Einlesen einer XML-Datei behandelt. Selbstverständlich existiert auch das umgekehrte Problem: In einem Programm entstandene Daten sollen in einem XML-Format exportiert werden.
Dazu muss zunächst ein Element Tree erzeugt werden. Dies kann, wie oben beschrieben, durch das Einlesen einer Datei bzw. eines Strings geschehen. Alternativ lässt sich ein Element Tree auch elementweise erzeugen:
>>> dictionary = ElementTree.Element("dictionary")
>>> eintrag = ElementTree.SubElement(dictionary, "eintrag")
>>> schluessel = ElementTree.SubElement(eintrag, "schluessel", {"typ":"str"})
>>> schluessel.text = "Hallo"
>>> wert = ElementTree.SubElement(eintrag, "wert", {"typ":"int"})
>>> wert.text = "0"
Zunächst wird eine Element-Instanz mit dem Tag-Namen dictionary erzeugt, die als Wurzel unseres Baums fungiert. Die Funktion SubElement erlaubt es dann, Elemente in den Baum einzufügen. Dazu müssen das gewünschte Elternelement und der Tag-Name übergeben werden. Optional kann ein Dictionary mit Attribut-Wert-Paaren übergeben werden.
Nachdem ein Element Tree konstruiert wurde, kann die Funktion tostring verwendet werden. Diese schreibt eine Element-Instanz mit all ihren Unterelementen als XML in einen String und gibt diesen zurück:
>>> ElementTree.tostring(dictionary)
b'<dictionary><eintrag><schluessel typ="str">Hallo</schluessel><wert typ="int">0</wert></eintrag></dictionary>'
Anstatt die Daten als String zu exportieren, können sie auch direkt in eine Datei geschrieben werden. Dazu existiert die Methode write, der sowohl ein Dateiname als auch ein geöffnetes Dateiobjekt übergeben werden kann. In diesem Fall muss jedoch zuvor eine ElementTree-Instanz erzeugt werden:
>>> et = ElementTree.ElementTree(dictionary)
>>> et.write("file.xml")
Über die optionalen zweiten Parameter der Methoden tostring und write kann ein Encoding zum Schreiben festgelegt werden.
Attribute der Klasse Element
Im vorangegangenen Abschnitt wurde auf das Attribut text der erzeugten Element-Instanzen zugegriffen, um den Text festzulegen, den sie enthalten. Es existieren insgesamt vier dieser Attribute, die in Tabelle 33.2 kurz erläutert werden:
| Attribut | Beschreibung |
|---|---|
| attrib | Referenziert ein Dictionary, das alle im Element enthaltenen XML-Attribute als Schlüssel-Wert-Paare enthält. |
| tag | Referenziert den Tag-Namen des Elements. |
| tail | Referenziert den Text, der in der XML-Datei zwischen dem schließenden Tag des Elements und dem nächsten öffnenden oder schließenden Tag steht. |
| text | Referenziert den Text, der in der XML-Datei zwischen dem öffnenden Tag des Elements und dem nächsten öffnenden oder schließenden Tag steht. |
Tabelle 33.2 Attribute der Klasse Element
Jedes dieser Attribute kann sowohl gelesen als auch geschrieben werden.
XML-Attribute schreiben und lesen
Die Klasse Element definiert die Methoden get und set, um auf ihre XML-Attribute[ 138 ](nicht zu verwechseln mit den Attributen der Klasse Element selbst ) zuzugreifen:
>>> wert.get("typ")
'int'
>>> wert.set("typ", "str")
>>> wert.get("typ")
'str'
Der Methode get kann ein optionaler Standardwert übergeben werden, der zurückgegeben wird, falls das Element über kein Attribut des gewünschten Namens verfügt.
Einen Element Tree durchlaufen
Grundsätzlich erbt die Klasse Element alle Eigenschaften einer Liste. Es ist also insbesondere möglich, über einen Index auf Kindelemente zuzugreifen. Deshalb können die Kindelemente einer Element-Instanz ganz selbstverständlich in einer Schleife durchlaufen werden:
>>> for e in eintrag:
... print(e.tag)
...
schluessel
wert
Jedes Element eines Element Trees bietet darüber hinaus die Methode iter an, die einen Iterator über alle in der Hierarchie untergeordneten Elemente, inklusive des Elements, auf dem die Methode gerufen wird, zurückgibt. Auf diese Weise lässt sich auch der in den vorangegangenen Abschnitten erstellte Element Tree komfortabel durchlaufen:
>>> list(dictionary.iter())
[<Element 'dictionary' at 0x7f4762a31638>,
<Element 'eintrag' at 0x7f476187e278>,
<Element 'schluessel' at 0x7f476187e188>,
<Element 'wert' at 0x7f4762a314f8>]
Über den optionalen Parameter tag lässt sich der Iterator auf Elemente mit einem bestimmten Tag-Namen einschränken:
>>> list(dictionary.iter("wert"))
[<Element 'wert' at 0x7f4762a314f8>]
Wenn eine ElementTree-Instanz durchlaufen werden soll, kann dies über das Wurzelelement geschehen, das über die Methode getroot erreichbar ist:
>>> et = ElementTree.ElementTree(dictionary)
>>> list(et.getroot().iter("wert"))
[<Element 'wert' at 0x7f4762a314f8>]
Elemente im Element Tree finden
Die Klasse Element bietet die Methoden find, findall und findtext an, um untergeordnete Elemente nach bestimmten Kriterien zu durchsuchen. Das Suchkriterium wird über einen sogenannten Pfad definiert. Betrachten wir dazu die folgende XML-Datei:
<A>
<B>
<D>Hallo</D>
</B>
<C>
<E>
<F>Welt</F>
</E>
</C>
</A>
Diese XML-Datei laden wir in eine ElementTree-Instanz und führen dann auf dem Element A einige Suchoperationen aus.
>>> et = ElementTree.parse("test.xml")
>>> e = et.getroot()
Zunächst suchen wir mithilfe des Wildcard-Zeichens * und der Methode find nach einem beliebigen Tag-Namen. Das erste passende Element ist das Element B, das zurückgegeben wird:
>>> e.find("*")
<Element 'B' at 0x7f15ce584f10>
Die Methode find durchsucht nur die direkten Kindelemente des Elements, für das sie aufgerufen wird. Daher führt eine Suche nach dem Tag-Namen E zu keinem Ergebnis:
>>> e.find("E")
>>>
Um nach Elementen zu suchen, die tiefer in der XML-Hierarchie liegen, muss ein Pfad übergeben werden. Dieser kann auch Wildcards enthalten.
>>> e.find("C/*/F")
<Element 'F' at 0x7f15ce58a050>
Die Methoden findall und findtext funktionieren ähnlich wie find, mit dem Unterschied aber, dass findall eine Liste aller passenden Element-Instanzen zurückgibt und findtext den in der passenden Element-Instanz enthaltenen Text.
Elemente einfügen und entfernen
Wie bereits gesagt, kann eine Element-Instanz als Liste ihrer Kindelemente gesehen werden, sie erbt sogar die Funktionalität einer Liste. Das betrifft insbesondere auch die Möglichkeit, sie zu erweitern. Kindelemente lassen sich also über die Methoden append, extent, remove und clear einer Liste hinzufügen bzw. daraus entfernen:
>>> x = ElementTree.Element("x")
>>> x.append(ElementTree.Element("y"))
>>> x.append(ElementTree.Element("z"))
>>> ElementTree.tostring(x)
b'<x><y /><z /></x>'
33.2.2 SAX – Simple API for XML
Die Simple API for XML, kurz SAX, baut im Gegensatz zu ElementTree kein vollständiges Abbild der XML-Datei im Speicher auf, sondern liest die Datei fortlaufend ein und setzt den Programmierer durch Aufrufen bestimmter Funktionen davon in Kenntnis, dass beispielsweise ein öffnendes oder schließendes Tag gelesen wurde. Diese Herangehensweise hat einen Vorteil: Beim Laden sehr großer XML-Dateien können bereits eingelesene Teile weiterverarbeitet werden, obwohl die Datei noch nicht vollständig eingelesen worden ist.
Allerdings sind mit der Verwendung von SAX auch einige Nachteile verbunden. So ist beispielsweise, anders als bei ElementTree, kein wahlfreier Zugriff auf einzelne Elemente der XML-Daten möglich. Außerdem sieht SAX keine Möglichkeit vor, die XML-Daten komfortabel zu verändern oder wieder zu speichern.
Das Einlesen einer XML-Datei durch einen SAX-Parser, in der SAX-Terminologie auch Reader genannt, geschieht ereignisgesteuert. Das bedeutet, dass der Programmierer beim Erstellen des Readers verschiedene Callback-Funktionen einrichten und mit einem bestimmten Event verknüpfen muss. Wenn beim Einlesen der XML-Datei durch den Reader dann das besagte Event auftritt, wird die damit verknüpfte Callback-Funktion aufgerufen und somit der Code ausgeführt, den der Programmierer für diesen Zweck vorgesehen hat. Ein Event kann beispielsweise das Auffinden eines öffnenden Tags sein.
Der SAX-Reader stellt also nur die Infrastruktur zum Einlesen der XML-Datei bereit. Ob und in welcher Form die gelesenen Daten aufbereitet werden, entscheidet allein der Programmierer.
[»] Hinweis
Die Beschreibungssprache HTML für Webseiten basiert zu großen Teilen auf XML, erlaubt aber etwas größeren syntaktischen Freiraum.[ 139 ](Der neuere Standard XHTML genügt hingegen den strengeren XML-Regeln. ) Aus diesem Grund lässt sich nicht jedes HTML-Dokument mit jedem XML-Parser einlesen.
Speziell für das Parsen von HTML-Dokumenten existiert das Modul html.parser in der Standardbibliothek. Die dort enthaltene Klasse HTMLParser implementiert einen SAX-Parser für HTML-Dokumente.
Beispiel
Die Verwendung von SAX möchten wir Ihnen direkt an einem einfachen Beispiel zeigen. Dazu dient uns das bereits bekannte Szenario: Ein Python-Dictionary wurde in einer XML-Datei abgespeichert und soll durch das Programm eingelesen und wieder in ein Dictionary verwandelt werden. Die Daten liegen im folgenden Format vor:
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<eintrag>
<schluessel typ="str">Hallo</schluessel>
<wert typ="int">0</wert>
</eintrag>
</dictionary>
Zum Einlesen dieser Datei dient das folgende Programm, das einen SAX-Reader verwendet:
import xml.sax as sax
class DictHandler(sax.handler.ContentHandler):
typen = {
"int" : int,
"str" : str
}
def __init__(self):
self.ergebnis = {}
self.schluessel = ""
self.wert = ""
self.aktiv = None
self.typ = None
def startElement(self, name, attrs):
if name == "eintrag":
self.schluessel = ""
self.wert = ""
elif name in ("schluessel", "wert"):
self.aktiv = name
try:
self.typ = self.typen[attrs["typ"]]
except KeyError:
self.typ = str
def endElement(self, name):
if name == "eintrag":
self.ergebnis[self.schluessel] = self.typ(self.wert)
elif name in ("schluessel", "wert"):
self.aktiv = None
def characters(self, content):
if self.aktiv == "schluessel":
self.schluessel += content
elif self.aktiv == "wert":
self.wert += content
Zunächst wird die Klasse DictHandler angelegt, in der wir alle interessanten Callback-Funktionen, auch Callback-Handler genannt, in Form von Methoden implementieren. Die Klasse muss von der Basisklasse sax.handler.ContentHandler abgeleitet werden.
Ein Nachteil des SAX-Modells ist es, dass wir nach jedem Schritt den aktuellen Zustand speichern müssen, damit beim nächsten Aufruf einer der Callback-Funktionen klar ist, ob der eingelesene Text beispielsweise innerhalb eines schluessel- oder eines wert-Tags gelesen wurde. Aus diesem Grund legen wir im Konstruktor der Klasse einige Attribute an:
- self.ergebnis für das resultierende Dictionary
- self.schluessel für den Inhalt des aktuell bearbeiteten Schlüssels
- self.wert für den Inhalt des aktuell bearbeiteten Wertes
- self.aktiv für den Tag-Namen des Tags, das zuletzt eingelesen wurde
- self.typ für den Datentyp, der im Attribut typ eines schluessel- oder wert-Tags steht
Zuerst implementieren wir die Methode startElement, die immer dann aufgerufen wird, wenn ein öffnendes Tag eingelesen wurde. Die Methode bekommt den Tag-Namen und die enthaltenen Attribute als Parameter übergeben. In dieser Methode wird zunächst ausgelesen, um welches öffnende Tag es sich handelt. Im Falle eines schluessel- oder wert-Tags wird self.name entsprechend angepasst und das Attribut typ des Tags ausgelesen.
Die Methode endElement wird aufgerufen, wenn ein schließendes Tag eingelesen wurde. Auch ihr wird der Tag-Name als Parameter übergeben. Im Falle eines schließenden eintrag-Tags fügen wir das eingelesene Schlüssel-Wert-Paar, das aus self.schluessel und self.wert besteht, in das Dictionary self.ergebnis ein. Wenn ein schließendes schluessel- oder wert-Tag gefunden wurde, wird das Attribut self.aktiv wieder auf None gesetzt, sodass keine weiteren Zeichen mehr verarbeitet werden.
Die letzte Methode characters wird aufgerufen, wenn Zeichen eingelesen wurden, die nicht zu einem Tag gehören. Der SAX-Reader garantiert nicht, dass eine zusammenhängende Zeichenfolge auch in einem einzelnen Aufruf von characters resultiert. Je nachdem, welchen Namen das zuletzt eingelesene Tag hatte, werden die gelesenen Zeichen an self.schluessel oder self.wert angehängt.
Schließlich fehlt noch die Hauptfunktion lade_dict des Beispielprogramms, in der der SAX-Parser erzeugt und gestartet wird.
def lade_dict(dateiname):
handler = DictHandler()
parser = sax.make_parser()
parser.setContentHandler(handler)
parser.parse(dateiname)
return handler.ergebnis
Im Funktionskörper wird die Klasse DictHandler instanziiert und durch die Funktion make_parser des Moduls xml.sax ein SAX-Parser erzeugt. Dann wird die Methode setContentHandler des Parsers aufgerufen, um die DictHandler-Instanz mit den enthaltenen Callback-Handlern anzumelden. Zum Schluss wird der Parsing-Prozess durch Aufruf der Methode parse eingeleitet.
Das mit lade_dict aus der eingangs angegebenen XML-Datei gelesene Dictionary sieht folgendermaßen aus:
>>> lade_dict("dict.xml")
{'Hallo': 0}
Die Klasse ContentHandler
Die Klasse ContentHandler dient als Basisklasse und implementiert alle SAX-Callback-Handler als Methoden. Um einen SAX-Parser einsetzen zu können, muss eine eigene Klasse erstellt werden, die von ContentHandler erbt und die benötigten Callback-Handler überschreibt. Eine Instanz einer von ContentHandler abgeleiteten Klasse wird von der Methode setContentHandler des SAX-Parsers erwartet. Tabelle 33.3 listet die wichtigsten Callback-Handler auf, die in einer von ContentHandler abgeleiteten Klasse überschrieben werden können.
| Methode | Beschreibung |
|---|---|
| startDocument() | Wird einmalig aufgerufen, wenn der SAX-Parser damit beginnt, ein XML-Dokument einzulesen. |
| endDocument() | Wird einmalig aufgerufen, wenn der SAX-Parser ein XML-Dokument vollständig eingelesen hat. |
| startElement(name, attrs) | Wird aufgerufen, wenn ein öffnendes Tag eingelesen wurde. |
| endElement(name) | Wird aufgerufen, wenn ein schließendes Tag mit dem Namen name eingelesen wurde. |
| characters(content) | Wird aufgerufen, wenn ein Textabschnitt eingelesen wurde. |
| ignorableWhitespace( whitespace) | Wird aufgerufen, wenn Whitespace-Zeichen eingelesen wurden. |
Tabelle 33.3 Methoden der Klasse ContentHandler
 Python 3
Python 3 Jetzt Buch bestellen
Jetzt Buch bestellen






