


34.5 Mit mehreren Tabellen arbeiten
34.5.1 Der Weg über JOIN-Abfragen
Bisher haben wir immer nur eine Tabelle im DataSet betrachtet. Das entspricht aber nur in wenigen Fällen den üblichen Anforderungen in der Praxis. Um beispielsweise die Frage zu beantworten, welche Artikel von den einzelnen Lieferanten stammen, sind zwei Tabellen notwendig: Products und Suppliers. Die meisten Tabellen einer Datenbank stehen mit anderen Tabellen in Beziehung. Meistens handelt es sich dabei um eine 1:n-Beziehung. Beispielsweise stammen von einem Lieferanten mehrere Artikel. Allerdings berücksichtigt die Northwind-Datenbank nicht, dass ein bestimmtes Produkt durchaus auch von mehreren Lieferanten angeboten werden könnte. Dann müsste die Beziehung zwischen den beiden Tabellen durch eine m:n-Beziehung beschrieben werden, die normalerweise in drei Tabellen aufgelöst wird, die miteinander jeweils in einer 1:n-Beziehung stehen.
Wenden wir uns für die weiteren Ausführungen nun den beiden Tabellen Products und Suppliers zu, deren Beziehung Sie in Abbildung 34.3 sehen.
Um Daten aus mehreren Tabellen auszuwerten, werden üblicherweise JOIN-Abfragen benutzt. Wollen Sie zum Beispiel wissen, welche Produkte von den einzelnen Lieferanten angeboten werden, könnte die Abfrage wie folgt lauten:
SELECT Suppliers.CompanyName, Suppliers.ContactName,
Products.ProductName, Products.UnitPrice
FROM Suppliers INNER JOIN
Products ON Suppliers.SupplierID = Products.SupplierID
Das Ergebnis der Abfrage sehen Sie in Abbildung 34.4.
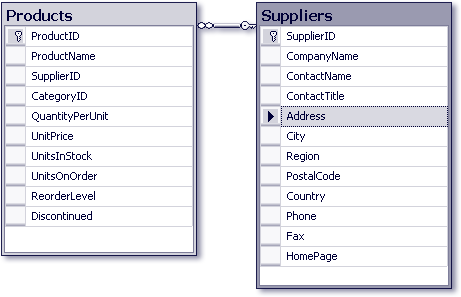
Abbildung 34.3 Die Beziehung zwischen den Tabellen »Products« und »Suppliers«
JOIN-Abfragen haben einige Vorteile:
- Das Ergebnis lässt sich filtern.
- Das Resultat steht in einer überschaubaren Ergebnismenge.
- JOIN-Abfragen sind anerkannter Standard.
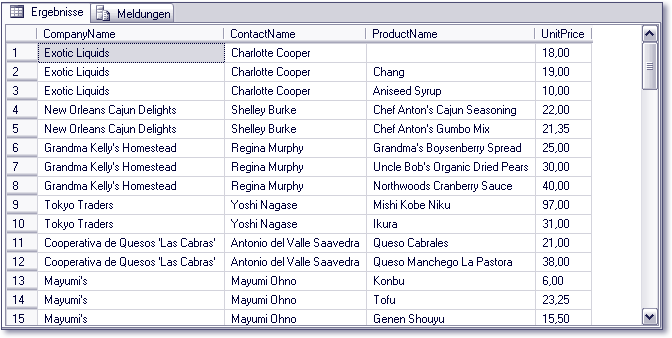
Abbildung 34.4 Ergebnisliste einer JOIN-Abfrage
Bei kritischer Betrachtung stehen den Vorteilen auf der anderen Seite aber auch schwerwiegende Nachteile gegenüber:
- Die Daten einer JOIN-Abfrage sind schwierig zu aktualisieren. Insbesondere beim Löschen oder Hinzufügen einer Datenzeile in einer JOIN-Abfrage wird die Problematik deutlich. Löschen Sie beispielsweise eine Datenzeile, stellt sich sofort die Frage, ob nur die Datenzeile in der Detailtabelle, also auf der n-Seite einer Beziehung gelöscht werden soll oder gleichzeitig auch die Datenzeile in der übergeordneten Mastertabelle, also der 1-Seite.
- JOIN-Abfragen geben redundante Daten zurück. Lassen Sie sich beispielsweise die Artikelliste und zu jedem Artikel auch noch die notwendigen Informationen des entsprechenden Lieferanten ausgeben, werden die Lieferanteninformationen mehrfach zurückgeliefert (siehe dazu auch Abbildung 34.4).
- Änderungen in einer JOIN-Abfrage sind schwer zu synchronisieren. Firmiert sich einer der Lieferanten um und tragen Sie das im Abfrageergebnis ein, muss die Änderung sofort zur Datenbank übermittelt und die gesamte Abfrage erneut ausgeführt werden.
34.5.2 Mehrere Tabellen in einem DataSet
ADO.NET löst die Nachteile, die eine JOIN-Abfrage hat, auf eine eigene Art und Weise. Dazu wird die JOIN-Abfrage in Einzeltabellen aufgeteilt, die miteinander in Beziehung gesetzt werden. Mit anderen Worten: Es wird ein Teil der Originaldatenbank abgebildet. Die Beziehung zwischen zwei Tabellen wird durch ein Objekt vom Typ DataRelation beschrieben.
Obschon solchermaßen strukturierte DataSets schwer zu filtern sind, überwiegen die Vorteile. So werden weniger Daten zurückgegeben als bei einer JOIN-Abfrage. Damit wird sowohl die Netzbelastung als auch die Auslastung des lokalen Speichers so gering wie möglich gehalten. Zudem ist es viel einfacher, Daten zu aktualisieren. Löschen Sie zum Beispiel einen Datensatz aus der Detailtabelle (n-Seite), möchten Sie vermutlich nicht auch gleichzeitig den entsprechenden Datensatz der Mastertabelle (1-Seite) löschen. Beide Informationen sind in einer JOIN-Abfrage jedoch in einer Datenzeile zusammengefasst. Operieren Sie mit einer DataRelation zwischen zwei DataTable-Objekten, lässt sich der Datensatz aus der Detailtabelle löschen, ohne dass zwangsläufig auch die entsprechende Datenzeile der Mastertabelle gelöscht wird.
34.5.3 Eine DataRelation erzeugen
Mit Hilfe einer DataRelation werden zwei DataTable-Objekte über DataColumn-Objekte miteinander verknüpft. In der Products/Suppliers-Beziehung ist die Tabelle Suppliers das übergeordnete und die Tabelle Products das untergeordnete Element der Beziehung. Dies ist vergleichbar mit einer Primärschlüssel-Fremdschlüssel-Beziehung. Beziehungen werden zwischen einander entsprechenden Spalten in der übergeordneten und der untergeordneten Tabelle erstellt. Das heißt, dass der Datentyp für beide Spalten identisch sein muss.
Aus einer längeren Liste möchten wir Ihnen einen der DataRelation-Konstruktoren vorstellen.
public DataRelation(string relationName, DataColumn parentColumn,
DataColumn childColumn)
Dem ersten Parameter teilen Sie mit, unter welchem Namen die DataRelation angesprochen werden soll, der zweite Parameter erwartet die Referenz auf die übergeordnete Spalte der Mastertabelle (1-Seite), der dritte Parameter die Referenz auf die untergeordnete Spalte der Detailtabelle (n-Seite).
Nachdem eine DataRelation erzeugt worden ist, muss sie dem DataSet bekannt gegeben werden. Dazu enthält das DataSet eine Auflistung vom Typ DataRelationCollection. Die Eigenschaft Relations des DataSets gibt die Referenz auf die Auflistung zurück.
Das folgende Listing zeigt, wie die Beziehung zwischen den beiden Tabellen Suppliers und Products festgelegt wird.
SqlConnection con = new SqlConnection();
con.ConnectionString = "...";
SqlCommand cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "SELECT * FROM Suppliers; " +
"SELECT * FROM Products";
DataSet ds = new DataSet();
SqlDataAdapter da = new SqlDataAdapter(cmd);
da.TableMappings.Add("Table", "Lieferanten");
da.TableMappings.Add("Table1", "Produkte");
da.Fill(ds);
// Erzeugen einer Beziehung zwischen den beiden Tabellen
DataColumn colMaster = ds.Tables["Lieferanten"].Columns["SupplierID"];
DataColumn colDetail = ds.Tables["Produkte"].Columns["SupplierID"];
DataRelation rel = new DataRelation("LieferantenProdukte",
colMaster, colDetail);
ds.Relations.Add(rel);
Listing 34.11 Tabellenbeziehungen mit Programmcode erstellen
34.5.4 DataRelations und Einschränkungen
Erzeugen Sie eine DataRelation zwischen zwei Tabellen, wie zuvor gezeigt, werden ein UniqueConstraint auf der Mastertabelle sowie ein ForeignKeyConstraint auf der Detailtabelle erstellt.
Haben Sie vor dem Erstellen der DataRelation Einschränkungen definiert, die einer Unique- und einer Fremdschlüsseleinschränkung entsprechen, übernimmt die neue DataRelation die vorhandenen Einschränkungen und erzeugt implizit keine neuen.
Andererseits können Sie auch das implizite Erzeugen der Einschränkungen unterdrücken. Dazu übergeben Sie dem Konstruktor der DataRelation im vierten Parameter false:
DataRelation rel = new DataRelation("LieferantenProdukte",
colMaster, colDetail, false);
Das ForeignKeyConstraint-Objekt im Detail
Das ForeignKeyConstraint-Objekt gehört zur ConstraintCollection der Detailtabelle, also der Tabelle auf der n-Seite einer 1:n-Beziehung. Es weist nicht nur eine Reihe von Eigenschaften auf, um die Beziehung zwischen den beiden Tabellen zu untersuchen, sondern legt darüber hinaus fest, wie sich die beiden Tabellen verhalten, wenn in der übergeordneten Mastertabelle Daten geändert oder Datenzeilen gelöscht werden.
Das folgende Codefragment zeigt, wie Sie die Eigenschaften Table, RelatedTable, Columns und RelatedColumns auswerten. Die Auswertung basiert auf der Beziehung, die weiter oben zwischen den beiden Tabellen Suppliers und Products codiert worden ist.
ConstraintCollection constr = ds.Tables["Produkte"].Constraints;
foreach (Constraint cTemp in constr) {
if (cTemp is ForeignKeyConstraint) {
Console.Write("Untergeordnete Tabelle: ");
Console.WriteLine(((ForeignKeyConstraint)cTemp).Table);
Console.Write("Untergeordnete Spalte(n): ");
foreach (DataColumn col in ((ForeignKeyConstraint)cTemp).Columns)
Console.WriteLine(col.ColumnName);
Console.Write("Übergeordnete Tabelle: ");
Console.WriteLine(((ForeignKeyConstraint)cTemp).RelatedTable);
Console.Write("Übergeordnete Spalte(n): ");
foreach (DataColumn col in ((ForeignKeyConstraint)cTemp).
RelatedColumns)
Console.WriteLine(col.ColumnName);
}
}
Listing 34.12 Auswertung in Beziehung stehender Tabellen
Table liefert die Referenz auf die untergeordnete Tabelle, RelatedTable die auf die übergeordnete Tabelle (Mastertabelle). Columns beschreibt die Spalten der untergeordneten Tabelle der Einschränkung, RelatedColumns die der übergeordneten Tabelle. Beide zuletzt genannten Eigenschaften liefern ein DataColumn-Array zurück, weil mehrere Spalten ein gemeinsames Merkmal für die Beziehung zwischen zwei Tabellen darstellen können.
Wichtiger als die Auswertung der Eigenschaften einer Beziehung sind diejenigen Eigenschaften, über die das Verhalten der Relation festgelegt wird. Löschen Sie beispielsweise eine Datenzeile in der Mastertabelle, stellt sich die Frage, wie sich die verknüpften Datenzeilen in der untergeordneten Detailtabelle verhalten sollen. Sollen Sie ebenfalls gelöscht werden? Oder sollen Sie in der Detailtabelle erhalten bleiben? Was ist, wenn in der Mastertabelle ein Wert geändert wird? Wird dann der Wert in der untergeordneten Tabelle ebenfalls aktualisiert?
Die Steuerung dieses Verhaltens wird von den Eigenschaften UpdateRule und DeleteRule bestimmt. Beide Eigenschaften sind vom Typ Rule. Dabei handelt es sich um eine Enumeration im Namespace System.Data. Die Werte der Enumeration sind in der folgenden Tabelle angegeben.
| Wert | Beschreibung |
|
Cascade |
Hierbei handelt es sich um den Standardwert. Wird eine Datenzeile in der Mastertabelle gelöscht (geändert), werden auch alle Detaildatenzeilen gelöscht (geändert). |
|
None |
Es wird keine Aktion ausgeführt und stattdessen eine Ausnahme ausgelöst. |
|
SetDefault |
Die Werte in den verknüpften Datenzeilen der Detailtabelle werden auf Standardwerte eingestellt. Die Standardwerte werden über die Eigenschaft DefaultValue des DataColumn-Objekts festgelegt. |
|
SetNull |
Die Werte in den verknüpften Datenzeilen werden auf DBNull festgelegt. |
Eine dritte Eigenschaft, die in diesem Zusammenhang auch noch erwähnt werden sollte, ist AcceptRejectRule. Sie gibt an, wie mit den verknüpften Datenzeilen umgegangen wird, wenn in der Mastertabelle AcceptChanges oder RejectChanges aufgerufen wird.
Die Eigenschaft kann nur zwei Werte annehmen: entweder AcceptRejectRule.None oder AcceptRejectRule.Cascade. Der Vorgabewert ist None. Das bedeutet, dass der Aufruf von AcceptChanges oder RejectChanges auf eine Datenzeile sich nicht auf die untergeordneten Datenzeilen auswirkt. Wenn Sie die Eigenschaft AcceptRejectRule auf Cascade setzen, wird die Aktion an diejenige untergeordnete Datenzeile weitergegeben, die vom ForeignKeyConstraint-Objekt definiert ist.
34.5.5 In Beziehung stehende Daten suchen
DataRelation-Objekte werden hauptsächlich dazu benutzt, um Daten, die in verschiedenen DataTable-Objekten enthalten sind, zu suchen. Zu diesem Zweck stellt eine DataRow drei Methoden zur Verfügung, die auf einer DataRelation basieren:
GetChildRows sucht, ausgehend von einer Datenzeile in der Mastertabelle, alle zugehörigen untergeordneten Datenzeilen in der Detailtabelle. Dazu übergeben Sie der Methode die DataRelation, die beide Tabellen miteinander verknüpft. Sie erhalten als Ergebnis ein DataRow-Array.
DataRow[] GetChildRows(DataRelation)
Ausgehend von der untergeordneten Zeile einer Detailtabelle ruft GetParentRow die zugehörige übergeordnete Datenzeile aus einer Mastertabelle ab. Auch dieser Methode müssen Sie die DataRelation zwischen den beiden Tabellen angeben; der Rückgabewert ist eine einzige Datenzeile.
DataRow getParentRow(DataRelation)
Sollte zwischen zwei Tabellen eine n:m-Beziehung bestehen, können Sie die GetParentRows-Methode einsetzen.
DataRow[] GetParentRows(DataRelation)
Ich möchte Ihnen nun in einem Beispielprogramm die Benutzung der Methoden zeigen. Die Aufgabenstellung dazu lautet, dass zu den einzelnen Aufträgen (Tabelle Orders) die bestellten Produkte (Tabelle Products) aufgelistet werden sollen. Zwischen diesen beiden Tabellen besteht eine m:n-Beziehung, die durch die Tabelle Order Details in zwei 1:n-Beziehungen aufgelöst wird (siehe Abbildung 34.5).

Abbildung 34.5 Die Beziehungen zwischen den Tabellen »Orders«, »Order Details« und »Products«
// Beispiel: ..\Kapitel 34\DataRelationNavigation
static void Main(string[] args) {
SqlConnection con = new SqlConnection();
con.ConnectionString = "...";
SqlCommand cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "SELECT * FROM Orders; " +
"SELECT * FROM [Order Details]; " +
"SELECT * FROM Products";
DataSet ds = new DataSet();
SqlDataAdapter da = new SqlDataAdapter(cmd);
da.TableMappings.Add("Table", "Bestellungen");
da.TableMappings.Add("Table1", "Bestelldetails");
da.TableMappings.Add("Table2", "Produkte");
da.Fill(ds);
// DataRelation zwischen Orders und OrderDetails erzeugen
DataColumn colMaster = ds.Tables["Bestellungen"].Columns["OrderID"];
DataColumn colDetail = ds.Tables["Bestelldetails"].Columns
["OrderID"];
DataRelation rel =
new DataRelation("Bestellungen_Bestelldetails", colMaster, colDetail);
ds.Relations.Add(rel);
// DataRelation zwischen OrderDetails und Products erzeugen
colMaster = ds.Tables["Produkte"].Columns["ProductID"];
colDetail = ds.Tables["Bestelldetails"].Columns["ProductID"];
rel = new DataRelation("Produkte_ Bestelldetails", colMaster, colDetail);
ds.Relations.Add(rel);
// Zu jeder Bestellung die bestellten Artikel anzeigen
foreach (DataRow rowOrder in ds.Tables["Bestellungen"].Rows)
{
Console.WriteLine("Autor: {0}", rowOrder["OrderID"]);
foreach (DataRow rowOrderDetail in rowOrder.GetChildRows(
ds.Relations["Bestellungen_Bestelldetails"]))
{
DataRow rowProduct;
rowProduct = rowOrderDetail.GetParentRow(
ds.Relations["Produkte_Bestelldetails"]);
Console.WriteLine("Artikel: {0}", rowProduct["ProductName"]);
}
Console.WriteLine(new string('-', 40));
}
Console.ReadLine();
}
Listing 34.13 Navigation unter Nutzung einer DataRelation
In diesem Beispiel werden vor dem Füllen des DataSets den drei beteiligten Tabellen zunächst über TableMappings sprechende Bezeichner zugewiesen. Hier ist ein solches Vorgehen besonders empfehlenswert, um den Code besser lesbar zu gestalten. Nachdem der SqlDataAdapter die Daten abgerufen hat, werden in einer äußeren foreach-Schleife alle Datenzeilen der Tabelle Orders nacheinander durchlaufen. Auf jeder Datenzeile (also Bestellnummer) wird GetChildRows aufgerufen. Diese Methode liefert ein DataRow-Array zurück, das alle Datenzeilen aus Order Details enthält, die dieser Bestellnummer entsprechen. Aus der gefundenen Datenzeile wird anschließend das Feld ProductID extrahiert und mit GetParentRow die entsprechende Datenzeile in der Tabelle Products gesucht. Letztere liefert uns den Artikelnamen.
34.5.6 Ergänzung zum Speichern von Schemainformationen in einer XML-Schemadatei
In Abschnitt 34.3.5 habe ich gezeigt, wie Sie die Schemainformationen mit der Methode WriteXmlSchema des DataSets in einer XML-Schemadatei speichern können. Ich hatte Ihnen das auch an einem Beispiel demonstriert, das die Metadaten einer Tabelle in die Schemadatei schrieb. Sie können selbstverständlich auf die gleiche Weise auch die Metadaten mehrerer in einem DataSet befindlicher Tabellen in einer Datei bereitstellen. Allerdings gibt es dabei einen besonderen Punkt zu beachten: Beabsichtigen Sie, auch die Beziehungen zwischen den Tabellen in der Schemadatei zu speichern, müssen Sie die Beziehungen zwischen den Tabellen zuerst mit Programmcode definieren, bevor Sie die Methode WriteXmlschema aufrufen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



