


3.6
Dimensionierung und Performance
Sie wissen aus dem vorherigen Abschnitt, wie man an bestehenden Systemen Messdaten erfasst – sei es, dass ein Performance-Problem zu lösen ist, sei es, dass Vergleichswerte für die Dimensionierung einer neuen Hardware beschafft werden sollen.
Ein Problem bei der Analyse von Performance-Daten ist, dass die zu ziehenden Schlussfolgerungen mitunter recht komplex sind und auf der Betrachtung mehrerer Leistungsindikatoren beruhen. Wenn Applikationsserver (wie beispielsweise SQL Server oder Exchange Server) dazukommen, gibt es diverse weitere Objekte und Indikatoren, die ebenfalls berücksichtigt werden sollten. In den folgenden Abschnitten möchte ich Ihnen einige allgemeingültige Hinweise geben, mit denen sich etliche Fragestellungen schon beantworten lassen sollten.
In meiner Praxis ist das »häufigste Problem« die Performance der Speichersysteme, weshalb ich mich mit diesem Thema am ausführlichsten befassen möchte.
3.6.1
Festplatte & Co.
Also, wie fange ich diplomatisch an? Mein Beruf ist es, durch die Lande zu ziehen und IT-Abteilungen bei der Einführung und Optimierung von Microsoft-Produkten zu unterstützen. Leider treffe ich gar nicht so selten auf Server, bei denen die Festplattenbereiche einfach nach dem Motto »Hauptsache, die Größe passt« dimensioniert sind. So finden sich dann Datenbankserver, in denen ein aus drei Platten bestehendes RAID5 mit SATA-Platten werkelt. Gut, »die Größe passt« – nicht aber die Performance.
Einführung
Dieser Abschnitt baut im Grunde genommen auf Abschnitt 3.1.4, »Festplatten«, auf. Lesen Sie bitte gegebenenfalls zur Einführung auch dort nochmals nach.
Das »richtige« Disk-Layout
Damit ein Server performant, möglichst ausfallsicher und wartbar ist, müssen beim Disk-Layout ein paar Grundregeln eingehalten werden. Ich will es mal so formulieren: Perfekter geht immer, von einem gewissen Mindeststandard sollten Sie aber keinesfalls abweichen. Mir ist klar, dass dieser Mindeststandard im Zweifelsfall höhere Anschaffungskosten bedeutet, Sie sollten aber keinesfalls an der falschen Stelle sparen. Wenn Sie das doch tun und später irgendetwas Vermeidbares passiert, heißt es dann garantiert »Du hast mir das nicht deutlich genug erklärt« und garantiert nicht »Na ja, ich wollte halt sparen, und es war leider am falschen Ende« (beachten Sie in den beiden Aussagen das »Du« und das »Ich«). Also:
- Regel #1: Server werden nur mit fehlertoleranten Plattenkonfigurationen, also RAID-Sets, in Betrieb genommen. Alles andere ist grob fahrlässig.
- Regel #2: Das Betriebssystem wird auf einem RAID1-Set installiert.
- Regel #3: Auf das Betriebssystem-RAID-Set (!) kommen keine Produktivdaten, auch nicht auf eine separate Partition dieses RAID-Sets.
Zu Regel #1: Warum ein Server im Produktivbetrieb zwingend eine fehlertolerante Festplattenkonfiguration haben sollte bzw. muss, braucht wohl nicht weiter diskutiert zu werden.
Zu Regel #2: Dafür, dass das Betriebssystem auf einem RAID1 und nicht etwa auf einem RAID5 liegen sollte, gibt es direkt mehrere Begründungen:
- Für das Betriebssystem wird nicht sonderlich viel Speicherplatz benötigt. Natürlich sind die Zeiten der 4-GB-Partitionen (NT4) längst vorbei, aber mit einer 24-GB-Partition könnte man schon gut leben. Wenn man auch Regel #3 betrachtet, die ein eigenes RAID-Set für das Betriebssystem fordert, bietet sich allein wegen der Größe ein RAID1 an. Mit 36-GB-Festplatten ist die Bruttokapazität eines RAID1, das bekanntlich mit zwei Festplatten aufgebaut werden kann, 36 GB; ein RAID5 benötigt mindestens drei Festplatten und kommt mit diesen auf die nicht benötigte höhere Kapazität von brutto 72 GB.
- Änderungen am System, insbesondere das Einspielen von Updates und Patches, haben immer
ein gewisses »Restrisiko«: Jeder Admin kann vermutlich eine Horrorgeschichte erzählen,
wie ein wichtiger Server nach dem Einspielen eines »total unkritischen Updates« nicht
mehr startete. Ich habe mir angewöhnt, vor dem Einspielen von Updates eine Festplatte
aus dem Spiegel (RAID1) zu ziehen und das Update nur auf eine Platte laufen zu lassen.
War das Update erfolgreich, kommt die gezogene Platte wieder zurück, und der RAID-Controller
baut den Spiegel neu auf. Ist das Update aus irgendeinem Grund schiefgegangen, starte
ich von der gezogenen Platte und bin innerhalb von Sekunden wieder auf dem ursprünglichen
Zustand. Man könnte dieses System noch perfektionieren und mit einer dritten Platte
arbeiten, womit man dann bei dem altbekannten kalten Spiegel wäre.
Aber egal, ob dritte Platte oder nicht: Mit einem RAID5 sind solche Verfahren nicht möglich; das geht nur mit einem RAID1!
Zu Regel #3: Für die Regel #3 (keine Produktivdaten auf dem RAID-Set des Betriebssystems) gibt es auch mehrere Begründungen:
- Wenn Sie die Argumentationslinie im vorangegangenen Abschnitt gelesen haben, liegt das erste Argument klar auf der Hand. Wenn man als Fallback-Szenario beim Einspielen von Patches mit einem aufgebrochenen Spiegel (zwei Platten) oder einem kalten Spiegel (dritte Platte) arbeitet, wäre es natürlich sehr lästig, auch noch jede Menge Produktivdaten mitzuschleppen.
- Der zweite große Aspekt sind die Fehlerdomänen: Verlieren Sie das RAID-Set mit dem Betriebssystem, lässt es sich relativ zügig wieder aufbauen, ohne dass Sie lang und breit über Produktivdaten nachdenken müssen.
- Überhaupt ist die Verwaltung deutlich übersichtlicher, wenn die auf den RAID-Sets abgelegten Daten deutlich physikalisch voneinander getrennt sind.
- Ein weiteres wesentliches Argument ist die Performance. Die Anzahl der Spindeln für Datenbereiche, insbesondere im Datenbankumfeld, wird man sorgfältig errechnen. Es ist keineswegs optimal, eine Betriebssystempartition, die unter anderem ein pagefile.sys und dergleichen schreiben muss, auf die genau »ausbalancierten« Daten-RAID-Sets schreiben zu lassen.
Für einen Datenbankserver ergibt sich also im Minimum das Layout aus Abbildung 3.40:
- Das Betriebssystem wird auf einem RAID1-Set installiert.
- Die Datenbank-Dateien kommen auf ein RAID1, RAID10 oder RAID5. Welches RAID-Set gewählt wird, hängt von den Performance- und den Kapazitätsanforderungen ab.
- Die Logs der Datenbank werden auf einem separaten physikalischen RAID-Set gespeichert. Dies geschieht einerseits aus Redundanzaspekten (damit Sie im Fehlerfall nicht Datenbank und Logs verlieren), andererseits stecken Performance-Aspekte dahinter.
- Um im Fall des Verlusts einer einzelnen Festplatte aus einem RAID-Set möglichst schnell wieder fehlertolerant zu sein, planen Sie eine oder mehrere HotSpare-Platten ein.
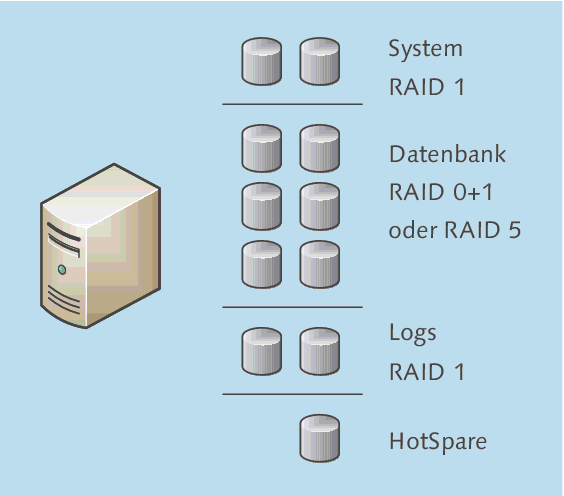
Abbildung 3.40 Einfaches (!) Disklayout für einen kleinen Datenbankserver. Gezeichnet sind hier drei physikalische RAID-Sets und nicht nur drei Partitionen eines RAID-Sets!
Bei sehr stark belasteten Servern könnte man gegebenenfalls noch weitere physikalische RAID-Sets planen:
- Man könnte über ein separates RAID-Set für pagefile.sys nachdenken.
- Bei stark belasteten Datenbankservern wird man sowohl die Datenbanken als auch die Logs auf mehrere physikalische RAID-Sets verteilen.
- Bei »speziellen« Servern wird es noch weitere Anforderungen geben: Beispielsweise wird für stark belastete Exchange Server empfohlen, die Mail-Warteschlangen auf eigene RAID-Sets zu legen. Bei großen SharePoint-Servern empfiehlt es sich, die Suchindizes auf separaten RAID-Sets zu speichern.
IOPS und Warteschlange
Wie bereits in Abschnitt 3.1.4, »Festplatten«, erläutert wurde, ist die in Hinblick auf Performance wesentliche Kenngröße die Anzahl der IO-Operationen (IO = In/Out = Eingabe/Ausgabe) pro Sekunde, angegeben als IOPS.
Bei einer 15-k-SCSI/FC-Festplatte kann man ca. von 170 IOPS ausgehen. Prinzipiell spielt das elektrische Interface zunächst keine Rolle; bei der gleichen »Mechanik« würde auch eine SATA-Platte diese IOPS-Leistung liefern können. Der wesentliche Punkt ist, dass die SATA-Platten deshalb billiger sind, weil sie mechanisch simpler gefertigt werden – aber schauen Sie ruhig selbst ins Datenblatt, die Leistung der SCSI/FC-Platten ist immer deutlich besser.
Bei der Betrachtung von Platten-Performance-Werten wird übrigens immer gern mit dem Durchsatz (in MB/s) argumentiert (oder geprahlt, je nachdem). Der erreichbare Durchsatz ist zwar in vielen Situationen extrem wichtig, ist aber letztendlich nur das Produkt aus der IOPS-Leistung und der Blockgröße – mehr dazu folgt ein wenig später im Unterabschnitt »Blockgrößen«.
Wenn Sie die Platten-Performance eines bestehenden Systems analysieren möchten (sei es zum Performance-Troubleshooting oder um Anhaltspunkte für eine neue Hardware zu bekommen), hilft Ihnen der Systemmonitor. Das Objekt Physikalischer Datenträger enthält 20 Leistungsindikatoren, mit denen die wesentlichen Aspekte erkannt werden können (Abbildung 3.41).
Für einen ersten Überblick eignen sich folgende Leistungsindikatoren:
- Übertragungen/s: Dies sind die pro Sekunde durchgeführten Schreib- und Leseoperationen, also die auf dem System durchgeführten IOPS.
- Lesevorgänge/s: Dies sind die lesenden Zugriffe. Die Summe der Leistungsindikatoren Lese- und Schreibvorgänge ergibt den Wert des Indikators Übertragungen/s. Für die Dimensionierung von RAID-Sets ist es wichtig, das Verhältnis von Lese- und Schreibzugriffen zu kennen.
- Schreibvorgänge/s: Die schreibenden Zugriffe.
- Durchschnittliche Warteschlangenlänge des Datenträgers: Vorsicht – es gibt auch Leistungsindikatoren, die die Warteschlangenlänge für Lese- und Schreibvorgänge ausgeben.
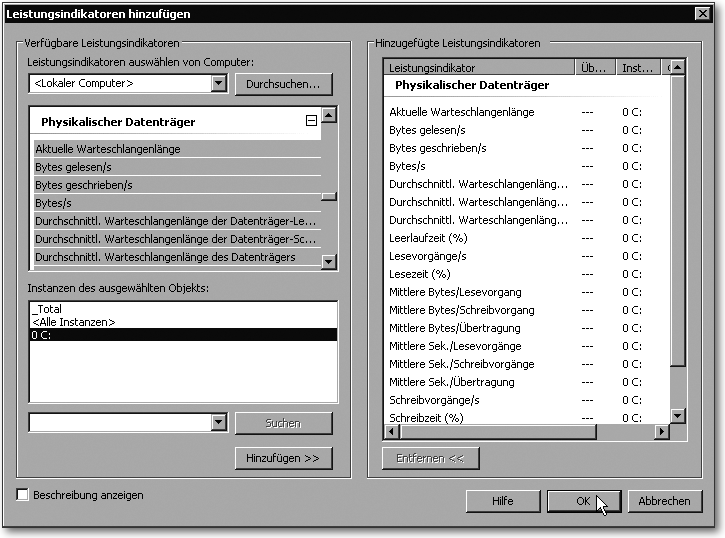
Abbildung 3.41 Jede Menge Leistungsindikatoren – der Systemmonitor weiß alles (oder zumindest recht viel) über die physikalischen Datenträger.
Die Durchschnittliche Warteschlangenlänge ist bei der Performance-Analyse extrem wichtig, daher möchte ich zunächst besprechen, was es damit auf sich hat. Eine schematische Darstellung sehen Sie in Abbildung 3.42:
- Wenn eine Applikation Daten von der Festplatte lesen oder darauf schreiben möchte, wird eine Anforderung erzeugt.
- Das Betriebssystem stellt diese Anforderung in eine Warteschlange (Queue). Für jede Festplatte im System existiert eine separate Warteschlange.
- Das Festplattensystem (bestehend aus Controller, Festplatten, RAID-Set etc.) holt diese Anforderungen nach dem FIFO-Prinzip (First In – First Out) aus der Warteschlange und verarbeitet sie.
Erzeugen die Anwendungen auf dem Server wesentlich mehr Anforderungen, als das Festplattensystem verarbeiten kann, gibt es entsprechend viele wartende Anforderungen und das Gesamtsystem ist langsam – einfach deshalb, weil die verschiedenen Anwendungen darauf warten, dass ihre Festplattenzugriffe endlich bedient werden.
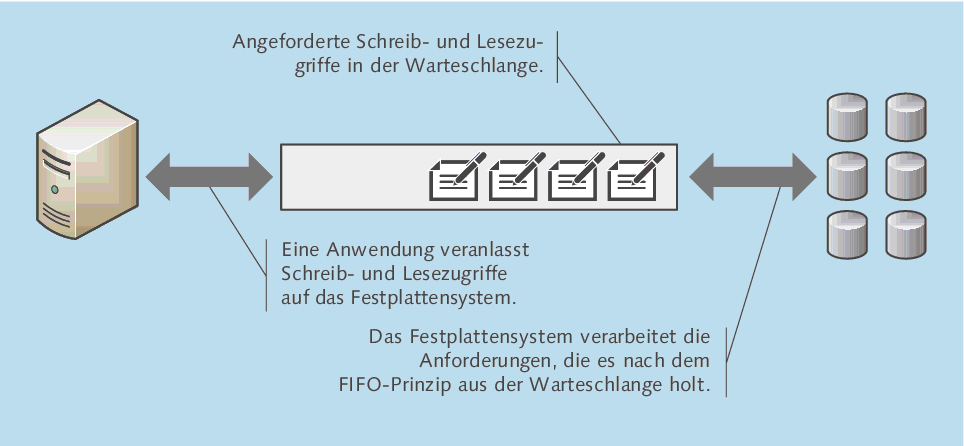
Abbildung 3.42 Schematische Darstellung: Zugriffe auf das Festplattensystem landen zunächst in einer Warteschlange.
Optimalerweise werden die in die Warteschlange gestellten Anforderungen sofort verarbeitet, sodass die Warteschlangenlänge 0 beträgt.
Literaturwert
Der Literaturwert ist übrigens, dass die durchschnittliche Warteschlangenlänge kleiner als die Anzahl der Spindeln (d. h. Festplatten) im RAID-Set sein sollte. Bei dem in der Abbildung gezeichneten RAID-Set mit sechs Platten sollte die gemessene durchschnittliche Warteschlangenlänge also zwischen 0 und 6 liegen.
Was bedeutet es nun, wenn Sie eine durchschnittliche Warteschlangenlänge messen, die deutlich höher als der optimale Wert liegt? Es gibt zwei Schlussfolgerungen:
- Erstens wird die Performance Ihres Servers schlecht sein. Die Anwendungen (z. B. SQL Server, Exchange, File Services) müssen auf die Abarbeitung ihrer jeweiligen Anforderungen an das Festplattensystem warten und lassen folglich auch die Benutzer warten, die mit dem System arbeiten wollen.
- Die gemessenen IOPS-Werte (Leistungsindikatoren wie Übertragungen/s) zeigen nicht den Performance-Bedarf, sondern die maximale Leistung des Festplattensystems an – sind also wertlos.
Warteschlangenlänge
Der Leistungsindikator Durchschnittliche Warteschlangenlänge erfüllt also direkt zwei Aufgaben:
- Er zeigt Ihnen auf einen Blick ein Performance-Problem.
- Er zeigt Ihnen, ob die gemessenen IOPS-Werte überhaupt aussagekräftig sind.
Gelegentliche Spitzenwerte, die deutlich höher liegen, sind tolerierbar, solange es erklärbare Werte sind, die in ganz eng begrenzten Zeitfenstern auftreten. Wenn beispielsweise bei einem nächtlichen Massendatenimport, der nach zehn Minuten beendet ist, eine deutlich verlängerte Warteschlange zu beobachten ist, kann man damit wahrscheinlich leben. Es ist ein erklärbarer und zeitlich eingrenzbarer Effekt.
Es gibt übrigens noch drei weitere Werte, die man zur Bestimmung von Performance-Problemen betrachten kann:
- Mittlere Sek./Übertragung
- Mittlere Sek./Lesevorgänge
- Mittlere Sek./Schreibvorgänge
Diese Werte geben an, wie lange eine Übertragung (bzw. ein Lese- oder Schreibvorgang) im Durchschnitt gedauert hat. Diese Werte sollten nicht größer als 10 ms sein.
IOPS und RAID-Sets (oder: Rechnen macht erfolgreich)
Nun haben Sie Messdaten erfasst oder vom Softwarehersteller Vorgaben erhalten, die in eine konkrete Plattenkonfiguration umgesetzt werden müssen. In diesem Abschnitt zeige ich Ihnen, wie Sie an diese Aufgabe herangehen.
Angenommen, Sie haben auf einem existierenden Datenbankserver die Leistungswerte aus Tabelle 3.1 erfasst.
| Datenbank-RAID-Set | |
|
Lesende IOPS |
750 |
|
Schreibende IOPS |
250 |
|
Durch. Warteschlange |
3 |
| Log-RAID-Set | |
|
Lesende IOPS |
50 |
|
Schreibende IOPS |
200 |
|
Durch. Warteschlange |
2 |
Als Erstes kontrollieren Sie die Warteschlangenlänge und stellen fest, dass hier keine übermäßigen Werte zu finden sind – die IOPS-Werte zeigen also den tatsächlichen Bedarf und geben nicht lediglich die maximalen Möglichkeiten des Festplattensystems an.
Wir gehen von der Verwendung von FC/SCSI-Platten mit einer Drehzahl von 15 k aus. Man kann also eine IOPS-Leistung von 170 pro Festplatte annehmen.
Einfluss des RAID-Levels
Neben der nativen Performance der Festplatten sind die Einflüsse der gewählten RAID-Level natürlich nicht zu vernachlässigen. Tabelle 3.2 zeigt, wie viele I/Os bei den jeweiligen RAID-Leveln für einen Schreibvorgang benötigt werden. Sie sehen, dass RAID5 vergleichsweise viele I/Os pro Schreibvorgang benötigt, was natürlich massiv Performance kostet. Aus diesem Grunde ist RAID5 für RAID-Sets ungeeignet, auf die sehr viel und schnell geschrieben werden muss.
Diesen Effekt finden Sie in der Literatur (und bei Google) unter dem Stichwort Write Penalty.
| RAID-Level | I/Os pro Schreibvorgang |
|
0 |
1 |
|
1 und 1+0 |
2 |
|
5 |
4 |
Zum besseren Verständnis sehen Sie in Abbildung 3.43 eine stark vereinfachte Darstellung:
- Die Applikation (z. B. Exchange Server) fordert eine schreibende IO-Operation beim Betriebssystem an, beispielsweise um eine E-Mail zu schreiben.
- Das Betriebssystem übermittelt die Anfrage (eine IO-Operation) durch diverse Schichten (z. B. Treiber etc.) an den Controller.
- Der Controller führt die Schreiboperation auf dem RAID-Set aus. Wegen der Write Penalty beim Schreiben auf ein RAID5-Set werden 4 IO-Operationen benötigt.
Es ergibt sich also die Faustregel: Bei Nutzung eines RAID5-Sets benötigt eine schreibende Operation »vor« dem Controller vier IOs »hinter« dem Controller.
Durch intelligentes Caching können moderne RAID-Controller diesen Effekt »klein halten« und so diese Schwäche von RAID5 ein wenig ausgleichen – das gilt natürlich auch für SAN-Storage-Systeme, die häufig über mehrere Gigabyte an Cache-Memory verfügen. Sie sollten sich aber nicht zu sehr darauf verlassen, dass der Cache schon alles ausgleichen wird:
- Kein Hersteller lässt sich auf Aussagen ein, wie effizient tatsächlich der Schreib-Cache ist (10 %, 20 %, 30 %). Das ist aber kein böswilliges Unterschlagen von Fakten – vielmehr sind konkrete Aussagen schlicht und ergreifend nicht möglich, da die Cache-Effizienz unter anderem vom Anwendungsszenario abhängt.
- In sehr stark belasteten Systemen könnte der Cache »voll« sein. Ab diesem Moment läuft das System mit der nativen Geschwindigkeit der Festplatten.
Es macht also durchaus Sinn, bei der Dimensionierung nicht nach dem Motto »der Cache hat ja noch immer alles ausgebügelt« vorzugehen, sondern den Performance-Bedarf einigermaßen präzise zu ermitteln.
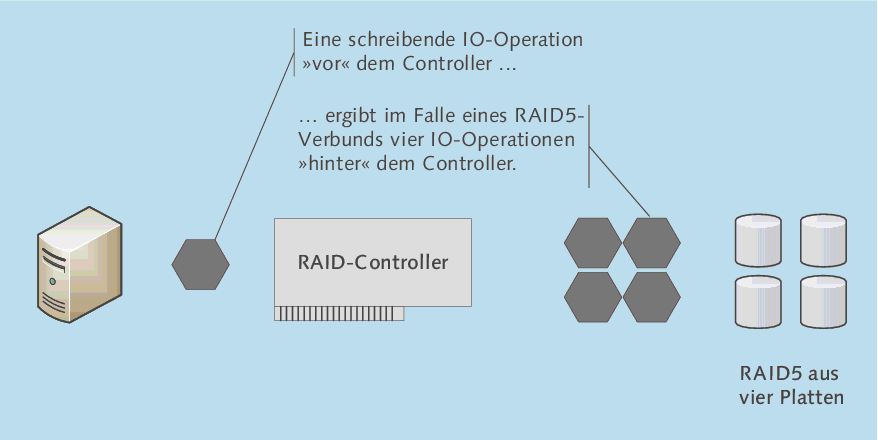
Abbildung 3.43 IOPS vor und hinter dem Controller
Tabelle 3.3 und Tabelle 3.4 fassen die bisherigen Erkenntnisse zusammen und zeigen zu der Kombination »Platte und RAID-Level« die zu erwartende IOPS-Leistung (bei einer Schreib-Lese-Relation von 1:2 und 1:1). Die Angabe des Werts für ein RAID0 ist dabei eher von akademischem Interesse; RAID0 bietet keine Redundanz gegenüber dem Ausfall einer Platte und kommt daher als Speicherort für Daten nicht wirklich infrage.
Bei einer etwas anderen Projektion kann man folgenden Vergleich ziehen. Wir vergleichen die mögliche IO-Leistung eines RAID5 aus 10-k-Platten mit einem RAID1+0 aus 15-k-Platten (Tabelle 3.5):
Sie sehen also, dass bei Auswahl geeigneter Platten und RAID-Level eine erhebliche Steigerung der Storage-Performance zu erreichen ist.
Hinweis
Die hier aufgeführten Werte sind natürlich nur als Anhaltswerte zu verstehen. Zum einen gibt es Unterschiede zwischen den Platten der unterschiedlichen Hersteller, zum anderen spielen natürlich auch die RAID-Controller und andere Systemparameter eine beeinflussende Rolle.
Zurück zum Beispiel
Mit dem im vorherigen Abschnitt erworbenen Wissen können Sie nun aus den Angaben in Tabelle 3.1 eine Plattenkonfiguration errechnen.
Zunächst kümmern wir uns um das RAID-Set, auf dem die Datenbank liegen soll:
- Tabelle 3.6 errechnet die Anzahl der benötigten Platten bei Verwendung eines RAID10-Sets.
- Tabelle 3.7 zeigt die Rechnung für ein RAID5.
| Lesen | Schreiben | Gesamt | IOPS/Platte | Anzahl Platten | |
|
Vor dem Controller |
750 |
250 |
|
|
|
|
Hinter dem Controller |
750 |
500 |
1 250 |
170 |
7,35294118 |
| Lesen | Schreiben | Gesamt | IOPS/Platte | Anzahl Platten | |
|
Vor dem Controller |
750 |
250 |
|
|
|
|
Hinter dem Controller |
750 |
1 000 |
1 750 |
170 |
10,2941176 |
Festzustellen ist, dass Sie allein aufgrund der Performance bei einem RAID5 deutlich mehr Platten benötigen. Dies ist auf die ungünstige Write Penalty bei einem RAID5 zurückzuführen.
Kommen wir nun zu dem RAID-Set, auf dem die Logs gespeichert werden sollen. Ein Merkmal der Logs ist, dass relativ viel geschrieben und eher wenig gelesen wird. Das klingt sehr nach RAID10, oder? Die Tabellen zeigen die Berechnungen:
- Tabelle 3.8 zeigt die Anzahl der benötigten Platten, wenn ein RAID10 verwendet wird. Hinweis: Für das Log-Volume verwendet man häufig ein RAID1. Für ein solches gelten dieselben Überlegungen wie für das RAID10. In diesem Fall benötigen wir allerdings 2,6-Platten. Ein RAID1 genügt nicht, sondern ein RAID10 mit 4 Platten muss konfiguriert werden.
- Tabelle 3.9 zeigt die Anzahl der benötigten Platten bei Verwendung eines RAID5.
| Lesen | Schreiben | Gesamt | IOPS/Platte | Anzahl Platten | |
|
Vor dem Controller |
50 |
200 |
|
|
|
|
Hinter dem Controller |
50 |
400 |
450 |
170 |
2,64705882 |
| Lesen | Schreiben | Gesamt | IOPS/Platte | Anzahl Platten | |
|
Vor dem Controller |
50 |
200 |
|
|
|
|
Hinter dem Controller |
50 |
800 |
850 |
170 |
5 |
Ich möchte nun die »Erkenntnisse« aus den Berechnungen zusammenfassen und zwei mögliche Konfigurationen vorstellen:
-
Tabelle 3.10 zeigt das Festplattenlayout, wenn für den Datenbankbereich ein RAID10 verwendet wird.
Tabelle 3.10 Dimensionierung des Plattenbereichs, Datenbank auf RAID10
Verwendung RAID-Level Anzahl Platten Betriebssystem
RAID1
2
Datenbank
RAID10
8
Log
RAID10
4
HotSpare
%
1
Gesamt
15
-
Tabelle 3.11 zeigt das Festplattenlayout, wenn der Datenbankbereich auf ein RAID5 gelegt wird.
Tabelle 3.11 Dimensionierung des Plattenbereichs, Datenbank auf RAID5
Verwendung RAID-Level Anzahl Platten Betriebssystem
RAID1
2
Datenbank
RAID5
11
Log
RAID10
4
HotSpare
%
1
Gesamt
18
Vier Anmerkungen zu den resultierenden Konfigurationen
- Datenbankarchitekten werden immer versuchen, die Datenbanken so aufzuteilen, dass diese über mehrere kleine RAID-Sets verteilt werden. Vermutlich würde man in der Praxis also kein RAID10-Set mit 8 Platten, sondern vier RAID1-Sets (insgesamt dann auch 8 Platten) vorfinden. Gleichfalls würde man die Logfiles über zwei RAID1-Sets verteilen, anstatt ein großes RAID10 einzurichten. Von der Anzahl der Platten ändert sich zusammenfassend allerdings nichts. Das in Tabelle 3.11 gezeigte Plattenlayout wäre zwar von den Performance-Anforderungen her ebenfalls möglich – kein Datenbankarchitekt würde aber ein solches System akzeptieren.
- In dem in Tabelle 3.11 gezeigten Beispiel wird ein RAID5 aus 11 Platten gebildet. In der Praxis versucht man, RAID5-Sets nicht größer als sechs Platten werden zu lassen: RAID5 verkraftet bekanntlich nur den Ausfall einer einzigen Platte, bei RAID5-Sets mit sehr vielen Platten ist die Gefahr eines zweiten Ausfalls vor dem Austausch der defekten Platte einfach zu hoch.
- Die hier vorgestellten Berechnungen gelten sowohl für lokal angeschlossene Platten als auch für die Plattenkonfiguration von Speichersystemen im SAN. Trotz aller Festplattenvirtualisierungsansätze, mit denen uns diverse Hersteller beglücken, fällt letztendlich doch alles auf die Plattenphysik zurück. Große Caches können zwar viel bewirken, Sie sollten aber »seriös« dimensionieren und nicht allein auf die Effizienz des Caches hoffen – das hat oftmals üble Folgen.
- In Ihren Berechnungen müssen Sie natürlich berücksichtigen, dass während der Standzeit des Systems vermutlich Steigerungen der Performance-Anforderungen zu berücksichtigen sind.
Und die Kapazität?
Sie sind vielleicht ein wenig erstaunt, dass ich die ganze Zeit Platten-Sizing allein nach Performance-Gesichtspunkten durchgeführt habe. Das ist durchaus so beabsichtigt, denn in den meisten Fällen bestimmt die Performance die Anzahl der benötigten Spindeln. Wenn Sie beispielsweise errechnet haben, dass Sie für den Datenbankbereich ein RAID-Set auf acht Platten im RAID10-Verbund benötigen, können Sie folgende unformatierte Kapazitäten erreichen:
- Mit 72-GB-Platten: 288 GB
- Mit 145-GB-Platten: 580 GB
- Mit 300-GB-Platten: 1.200 GB
Sie können nun also bestimmen, welche Größe die einzelne Platte haben soll – berücksichtigen Sie auch die Kapazitätssteigerungen während der Standzeit des Systems.
Falls Sie auch mit den Platten mit der größten Kapazität nicht die erforderliche Größe erreichen, müssen Sie die Anzahl der Platten erhöhen – was natürlich auch kein Problem ist. Andersherum wäre es übrigens fatal: Würde man nur nach dem Kriterium »Größe« dimensionieren, würde man für 1.000 GB Festplattenspeicher mit einem RAID5 mit vier 300-GB-Platten locker hinkommen. Sie hätten dann aber vermutlich ein massives Performance-Problem, denn eine solche Konfiguration leistet bei einem Schreib-Lese-Verhältnis von 1:3 nur ca. 550 IOPS im Gegensatz zu den geforderten 1.000 IOPS.
Hinweis
Also lautet der Grundsatz bei der Dimensionierung von RAID-Sets, insbesondere bei der Ermittlung der Anzahl der benötigten Festplatten: Performance first!
Blockgrößen
In den bisherigen Abschnitten habe ich mich sehr stark auf die IOPS-Werte konzentriert, was insbesondere bei der Betrachtung von Datenbanken aller Art das vordringliche Kriterium ist. Es gibt aber etliche Anwendungsfälle, in denen es primär um den Durchsatz, also um die pro Sekunde transportierten Megabytes geht. Ein echter Klassiker sind dabei Backup-to-Disk-Szenarien, in denen es einfach darum geht, möglichst viele MBs in möglichst kurzer Zeit auf möglichst billige Platten zu schaufeln.
Aber beginnen wir von vorn:
An der IOPS-Leistung der Platte kann man nichts verändern, wohl aber am Durchsatz. Dieser hängt davon ab, mit welcher Blockgröße das RAID-Set formatiert ist:
- Mit einer Blockgröße von 512 Bytes wäre der (durchschnittliche) Durchsatz: 512 Bytes × 170 IOPS = 85 kB/s
- Eine Blockgröße von 64 k führt zu: 64 kB × 170 IOPS = 10,6 MB/s
- Eine Blockgröße von 1 MB führt zu: 1 MB × 170 IOPS = 170 MB/s
Es ist also entscheidend wichtig, die beste Blockgröße für den jeweiligen Anwendungsfall zu kennen. Im günstigsten Fall gibt es dedizierte Vorgaben oder Empfehlungen des Softwareherstellers: Microsoft empfiehlt für Exchange Server 2007 beispielsweise die Verwendung einer Blockgröße von 64 k.
Nicht pauschal die maximale Größe wählen
Bevor jemand hier etwas in den falschen Hals bekommt: Es ist keine gute Idee, pauschal immer die maximale vom Controller angebotene Blockgröße zu wählen, weil dabei der höchste Wert für den Durchsatz herauskommt. Es hängt stets vom Anwendungsfall ab!
Das Thema mit der Blockgröße ist übrigens in der Praxis häufig eine böse Falle. Ich habe häufig Szenarien erlebt, in denen einem Kunden ein SATA-Plattensystem mit 10 Festplatten für Backup-To-Disk-Aufgaben verkauft und installiert worden ist. Hier nun ein wenig Mathematik:
- Bei einer modernen SATA-Platte kann man in etwa mit einer IOPS-Leistung von ca. 90 IOPS rechnen.
- Bei einem RAID-Set mit 10 Platten wäre die Gesamtleistung demnach 900 IOPS. Da beim Backup-To-Disk aber kontinuierlich geschrieben wird, ist die Write Penalty zu berücksichtigen. Bei einem RAID10-Verbund verbleiben also noch 450 IOPS für die Datenspeicherung. Anmerkung dazu: Man könnte überlegen, den Backup-To-Disk-Speicher als RAID0 auszulegen. Absolut tödlich ist allerdings ein RAID5.
Etliche Kunden beklagen sich nun über schlechte Leistungen des Backup-To-Disk-Systems, das ja schließlich mit U320-SCSI angeschlossen sei, aber trotzdem nur 25 MB/s verarbeiten könne.
Wenn Sie die vorherigen Ausführungen und Abschnitt 3.1.4 gelesen haben, wissen Sie, dass SATA-Platten generell nicht so performant wie FC/SCSI-Platten arbeiten. Warum werden diese dann trotzdem für Backup-To-Disk-Anwendungen verkauft, bei denen es ja auf Performance ankommt?
Ganz einfach: Bei Backup-To-Disk werden riesige Dateien geschrieben, sodass eine extreme Blockgröße kein Problem darstellt. Formatiert man das Backup-To-Disk-RAID-Set mit einer Blockgröße von 1 MB, lässt sich mit dem SATA-Festplatten-System, das im Schreibbetrieb 450 IOPS leistet, immerhin ein Durchsatz von 450 MB/s erreichen. Das liegt weit über den Möglichkeiten des elektrischen Interfaces (U320 SCSI, also 320 MB/s).
In der zuvor erwähnten Kundensituation kommt der magere Durchsatz von ca. 25 MB/s dadurch zustande, dass die Formatierung mit einer Blockgröße von 64 k durchgeführt wurde (64 k × 450 IOPS = 28,1 MB/s). Wählt man die »richtige« Blockgröße, bekommt man das Backup-to-Disk auch zum Fliegen! Prüfen Sie also, ob es für die jeweilige Anwendung Empfehlungen vom Softwarehersteller gibt.
Bei Datenbanken kommt es zwar in erster Linie auf die mögliche IOPS-Leistung an, nichtsdestotrotz wird das System nicht performant laufen, wenn Sie eine für den Verwendungszweck völlig ungeeignete Blockgröße wählen.
Achten Sie auf die Blockgröße
Beim Anlegen des RAID-Sets durch den RAID-Controller wird bereits die »physikalische Blockgröße« festgelegt. Sie müssen also bereits alle wichtigen Entscheidungen in diesem frühem Moment getroffen haben. Ein Ändern ist im Allgemeinen nur durch Auflösen des RAIDs und Neuanlegen möglich.
Achten Sie darauf, dass die Blockgröße im RAID-Controller wirklich auf den gewünschten Wert eingestellt ist – kontrollieren Sie das auch bei vorhandenen Systemen! Es ist nicht damit getan, nur bei der Formatierung durch das Betriebssystem die benötigte Blockgröße einzustellen.
3.6.2
Hauptspeicher
Das wesentliche Problem beim Hauptspeicher ist das Swapping – also das Auslagern von Speicherbereichen auf die Festplatte. Halten Sie auf bestehenden Systemen insbesondere den Leistungsindikator Speicher\Seiten/s im Blick – er muss stets kleiner als 1.000 sein.
Um es ganz deutlich zu sagen: Es ist kein Problem, dass der Server in das Pagefile schreibt – eine gewissen Aktivität ist dort immer zu verzeichnen. Das darf aber, um es einmal etwas salopp zu formulieren, nicht überhandnehmen.
Bei der Dimensionierung von neuen Systemen können Sie, abgesehen von den Empfehlungen des Herstellers, auf die (Mess-)Erfahrungen mit dem Altsystem zurückgreifen.
Bedenken Sie aber, dass sich aufgrund der 64-Bit-Technologie für die Softwareentwickler ganz neue Möglichkeiten eröffnet haben. Bei 4 GB war bei 32-Bit-Systemen die Grenze erreicht, was bedeutete, dass für eine Applikation höchsten 3 GB nutzbarer Speicher zur Verfügung standen. Im 64-Bit-Adressraum gibt es ganz andere Möglichkeiten, von denen Entwickler durchaus auch Gebrauch machen.
Ohne jetzt ins Detail gehen zu wollen – Sie sollten nicht unbedingt von einem Hauptspeicherausbau von 4 GB bei dem alten 32-Bit-System auf den Bedarf einer komplett auf 64-Bit-Technologie gehobenen Anwendungslandschaft schließen. Ein kleines Beispiel dazu:
- In einen Exchange 2003-Server brauchten Sie nicht mehr als 4 GB Hauptspeicher zu stecken – er hätte damit nicht umgehen können.
- Ein Exchange 2007-Server benötigt in einer mittelgroßen Umgebung durchaus 16 GB Hauptspeicher und mehr. Aufgrund der 64-Bit-Architektur kann er den zusätzlichen Speicher sinnvoll nutzen – und braucht ihn übrigens auch.
3.6.3
Prozessor
Zur Begutachtung der Prozessorleistung gibt es (obwohl es natürlich viel mehr zu messen gibt) zwei Leistungsindikatoren, auf die Sie in jedem Fall achten sollten:
- Prozessor\Prozessorzeit (%): Dieser Leistungsindikator sollte keinesfalls dauerhaft über 90 % liegen.
- System\Prozessor-Warteschlangenlänge: Dieser Leistungsindikator sollte kleiner als 2 sein.
Zu beachten ist, dass eine hohe Prozessorlast auch eine Folge von einem Performance-Engpass in einem anderen Bereich sein kann. Der Klassiker ist eine hohe Prozessorbelastung in Folge von extrem hoher Auslagerungsaktivität (Swapping) durch fehlenden Hauptspeicher.
Die vergleichsweise preisgünstigen 2-Wege-Systeme mit Quad-Core-Prozessoren sind mittlerweile so leistungsfähig, dass sie auch in großen Umgebungen für komplexe Serveraufgaben herangezogen werden können.
3.6.4
Netzwerkkonnektivität
In heutigen geswitchten Netzen sind »echte Netzwerkprobleme« selten. Sie können folgende Indikatoren betrachten:
- Netzwerkschnittstelle\Gesamtanzahl Bytes/s: Dieser Wert sollte 60 % der möglichen Geschwindigkeit der Netzwerkkarte nicht überschreiten. Bei einer 100-Mbit/s-Karte sollte er also nicht über 6 MB/s liegen.
- Netzwerkschnittstelle\Ausgehende Pakete Fehler/s: Dieser Wert muss stets 0 betragen.
Einige Zeilen weiter oben habe ich von »echten Netzwerkproblemen« geschrieben – gibt es auch »unechte Probleme«? Auch wenn die Formulierung ein wenig unglücklich ist: Ja, die gibt es.
In vielen Netzen gibt es beispielsweise Probleme mit der Namensauflösung. Die Server verbringen dann viel Zeit damit, umständlich Namen durch Broadcasting zu ermitteln, oder sie wollen immer wieder einen Server ansprechen, den es gar nicht mehr gibt. Fehlerhafte DNS-Konfiguration ist eine üble Angelegenheit, insbesondere für die Gesamt-Performance des Netzes. »Fehlerhaft« kann dabei bedeuten, dass in der IP-Konfiguration des Servers (oder Clients) DNS-Server eingetragen sind, die gar nicht mehr existieren, oder dass die Replikation zwischen DNS-Servern nicht funktioniert und dergleichen mehr.
Solcherlei Fehler werden häufig einer mangelhaften Performance des Netzwerks zugeschrieben – und dann wundert man sich, dass auch ein Upgrade auf Gigabit-Technologie keine Wende bringt.
Wenn Sie also vermuten, dass Ihr Netzwerk zu langsam ist, würde ich im Allgemeinen empfehlen, zunächst diese »unechten Netzwerkprobleme« auszuschließen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen




