


3.2
Storage-Architekturen
Klassischerweise werden Server mit einer ausreichenden Menge an lokalen Platten ausgestattet (DAS = Direct Attached Storage). Technisch gibt es hier auch bei großen Plattenanzahlen wenige Probleme, da moderne Server mit mehreren RAID-Controllern durchaus mehrere Dutzend Platten ansteuern können.
Seit einiger Zeit ist im Rechenzentrumsbereich der Trend zu einer Speicherkonsolidierung zu beobachten. Hierbei wird ein Speichernetz (SAN , Storage Area Network) aufgebaut, das ein oder mehrere Storage-Systeme enthält, auf dem bzw. denen die Server sämtliche Daten ablegen. In einer speicherkonsolidierten Umgebung ergeben sich folgende Vorteile (die Reihenfolge stellt keine Gewichtung dar):
- einfachere Verwaltung (insbesondere Erweiterbarkeit etc.)
- höhere Verfügbarkeit (Um diese auch tatsächlich zu erreichen, sind einige Maßnahmen notwendig.)
- erweiterte Funktionen wie Snapshotting, Cloning etc.
3.2.1
SAN, NAS, iSCSI
Da es für den Zugriff auf zentrale Speicherressourcen mehrere Technologien am Markt gibt, werden wir diese zunächst kurz betrachten und vor dem Anwendungshintergrund auf »Brauchbarkeit« prüfen. Die wesentlichen Stichwörter in diesem Zusammenhang sind:
- SAN: Obwohl der Begriff SAN, Storage Area Network, grundsätzlich für alle Arten von Speichernetzen, also unabhängig von der Technologie, steht, wird er im Allgemeinen als Synonym für ein FibreChannel-SAN verwendet. FibreChannel ist heute die am weitesten verbreitete Technologie zum Aufbau von Speichernetzen.
- NAS: Network Attached Storage ist, wie der Name ja schon vermuten lässt, ein Speichersystem, das direkt an das bestehende LAN (im Allgemeinen Ethernet) angeschlossen werden kann. Primär handelt es sich bei den NAS-Systemen um Fileserver. Zu beachten ist, dass auf ein Fileshare kein Blocklevel-Zugriff besteht, weshalb dort im Allgemeinen keine Datenbankdateien liegen können.
- iSCSI: Mittels iSCSI kann ein Blocklevel-Zugriff auf eine im Netz stehende Speicherressource erfolgen. Professionelle NAS-Systeme (der bekannteste Hersteller ist übrigens die Firma Network Appliance) unterstützen den iSCSI-Zugriff, sodass die Speicherbereiche dieser Systeme auch von Datenbankservern verwendet werden können.
Wir benötigen für die Speicherung von Datenbanken also Speicherorte, auf die ein Blocklevel-Zugriff möglich ist – am besten über SCSI. Gebräuchlich sind drei Ansätze, die in Abbildung 3.1 dargestellt sind:
- Direct Attached Storage (Hier könnte man übrigens noch nach »klassischem« parallelem SCSI und SAS differenzieren.)
- FibreChannel-SAN
- iSCSI
Allen Technologien ist gemeinsam, dass letztendlich SCSI verwendet wird – vereinfacht gesagt sind lediglich die Transportmedien unterschiedlich. Diese Aussage ist eigentlich zu verallgemeinert, da es unterschiedliche Versionen (oder Evolutionsstufen) des SCSI-Protokolls gibt. Für einen ersten Überblick brauchen wir aber nicht zu tief ins Detail zu gehen.
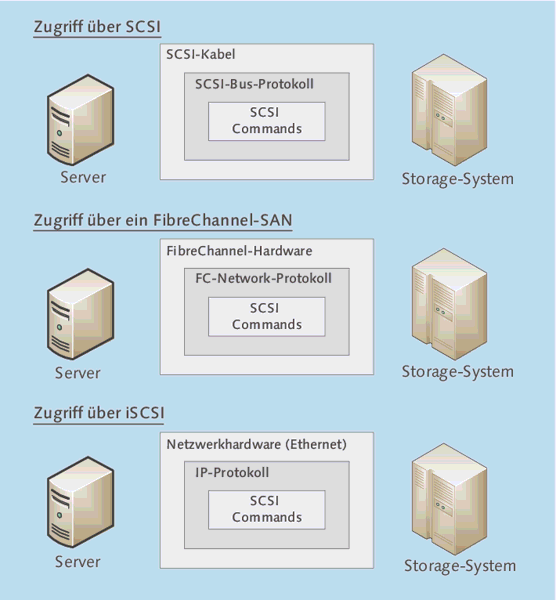
Abbildung 3.1 DAS, FC-SAN und iSCSI basieren letztendlich auf SCSI.
FibreChannel
FibreChannel ist momentan der Standard, um Speichernetze aufzubauen. Ohne jetzt langatmig den Protokoll-Stack durchgehen zu wollen, folgen hier stichwortartig die wichtigsten Informationen:
- Vereinfacht gesagt ist die oberste Protokollschicht das SCSI-Protokoll, das wir auch für die Ansteuerung lokaler Platten und Geräte verwenden. Andere Protokolle wie IP, IPI, FICON etc. können ebenfalls verwendet werden, dies soll uns hier aber nicht weiter interessieren. FibreChannel und SCSI ist eine sehr bewährte und performante Kombination.
- FibreChannel wird heute zumeist über Glasfaser-Verbindungen betrieben. FibreChannel kann auch über Kupfer gefahren werden, dies findet sich allerdings nur selten. Je nach Wellenlänge des Lasers, dem Fasertyp und der Übertragungsgeschwindigkeit (1 Gbit/s, 2 Gbit/s, 4 Gbit/s) variieren die möglichen maximalen Kabellängen zwischen 100 m und 50 km.
- Die momentan aktuelle Übertragungsgeschwindigkeit (d. h., für sie sind Produkte verfügbar) ist 4 Gbit/s.
- Server, die in ein FibreChannel-SAN eingebunden werden sollen, benötigen einen oder mehrere wFibreChannel-Hostbus-Adapter (FC-HBA).
- An Infrastruktur-Komponenten werden FibreChannel-Switches benötigt. Vor einigen Jahren waren Hubs verfübar, mit denen FibreChannel Arbitrated Loop (FC-AL) gefahren wurde. Der Loop wird aber für die Verbindung zwischen Servern und Storage-Systemen heute nicht mehr verwendet.
- Die Storage-Systeme verfügen meist über zwei RAID-Controller mit FibreChannel-Eingängen.
Abbildung 3.2 zeigt den schematischen Aufbau eines pfad-redundanten SANs auf FibreChannel-Basis.
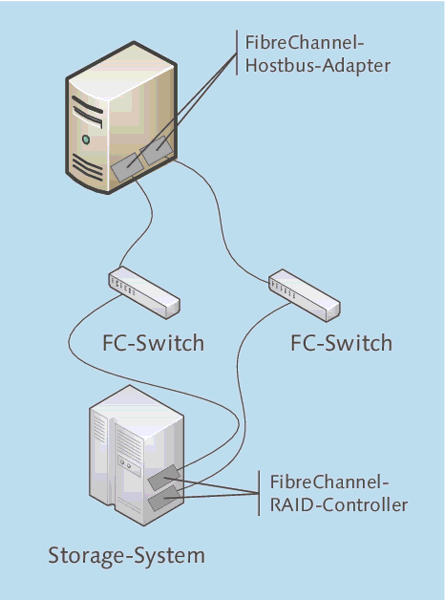
Abbildung 3.2 Schematischer Aufbau eines SANs auf FibreChannel-Basis
Zusammenfassend bieten Storage-Lösungen auf FibreChannel-Basis folgende Vorteile:
- Es gibt eine sehr breite Unterstützung durch Hardware- und Softwarehersteller.
- Die Technologie hat mittlerweile einen hohen Reifegrad erreicht.
- Das System ist sehr performant.
- Hochverfügbare Lösungen können aufgebaut werden.
Faustregel: Benötigen Sie höchste Performance und Verfügbarkeit, wählen Sie FibreChannel.
iSCSI
Mit iSCSI kann über das IP-Netz auf ein Storage-System so zugegriffen werden, als sei es lokal über SCSI angeschlossen. Somit ist ein Blocklevel-Zugriff möglich.
Abbildung 3.3 zeigt eine netzwerkorientiertere Sichtweise. Sie sehen, dass die SCSI-Kommandos und -Daten in TCP/IP-Pakete eingekapselt werden. Da TCP/IP-Pakete nicht nur innerhalb eines Netzwerksegments, sondern letztendlich durch das ganze Internet übertragen werden, könnte man theoretisch auf ein Storage-System in Manaus (Brasilien, Amazonas-Gebiet) zugreifen. Das ist natürlich ein in der Praxis nicht relevantes Beispiel, da es bei Speicherzugriffen entscheidend auf Latenzzeit und Performance ankommt, und diese werden über eine interkontinentale WAN-Strecke nicht gegeben sein, zumal man die Pakete noch VPN-mäßig behandeln müsste – aber Sie sehen, was vielleicht in Zukunft möglich sein könnte.
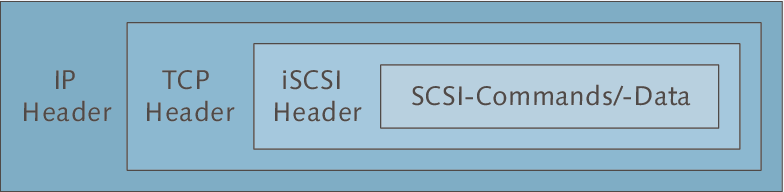
Abbildung 3.3 Das iSCSI-Protokoll kapselt SCSI-Kommandos und -Daten in TCP/IP-Pakete.
iSCSI kann serverseitig mit herkömmlichen Netzwerkkarten genutzt werden. Alternativ gibt es iSCSI-Hostbus-Adapter (z. B. Adaptec 7211C/F), die sich gegenüber dem Betriebssystem wie ein SCSI-Controller verhalten und »nach draußen« über einen Gigabit-Ethernet-Anschluss verfügen. Die meisten mir bekannten iSCSI-Installationen nutzen nicht die speziellen iSCSI-HBAs, sondern arbeiten mit üblichen Netzwerkkarten und wickeln das iSCSI-Protokoll softwarebasiert ab. Natürlich gibt es gute Gründe für die Verwendung der iSCSI-HBA, beispielsweise die geringere Prozessorbelastung oder die Möglichkeit, über iSCSI zu booten (nicht mit allen HBAs!).
Beim Einsatz von iSCSI in der Praxis wird man, zumindest in einer größeren Umgebung, einige Aspekte berücksichtigen müssen:
- Es empfiehlt sich, Netzwerk- und Storage-Datenströme zu trennen. Es ist hierfür nicht unbedingt notwendig, einen separaten Switch zu beschaffen, allerdings sollte der Server Netzwerk- und Storage-Datenverkehr über unterschiedliche Netzwerkkarten abwickeln. Wenn die Netzwerkkarten an einen Switch angeschlossen werden, ist zu prüfen, ob dieser über genügend Bandbreite auf Backplane-Ebene verfügt, was bei modernen Geräten gegeben sein sollte. Nicht vergessen: iSCSI über langsamere Strecken als Gigabit-Ethernet zu fahren, macht keinen Sinn!
- Ebenso wie im FibreChannel-Bereich gilt, dass es redundante Pfade zwischen Server und Storage-System geben sollte. Der Ausfall eines Switches/Switchports oder einer Netzwerkkarte ist stets möglich.
- Im Übrigen gilt natürlich auch hier, dass die »sicherste« Konfiguration aus zwei Storage-Systemen besteht, die über einen gespiegelten Datenbestand verfügen.
Um die Kommunikation zwischen Server und Storage-System zu realisieren, gibt es zwei Objekttypen: Initiatoren und Targets.
- Der Initiator ist die serverseitige Komponente, die den Zugriff auf eine Storage-Ressource initiiert.
Der Initiator kann als Hardware- (iSCSI-HBA) oder als Softwarelösung implementiert
sein. Seit Windows Server 2008 ist der iSCSI-Initiator bereits im Betriebssystem integriert.
Anmerkung: Einen Softwareinitiator für Windows 2000 (ab SP4), XP und den Windows Server 2003 können Sie kostenlos von der Microsoft-Website herunterladen (navigieren Sie zu http://www.microsoft.com/downloads, und geben Sie als Suchbegriff iSCSI ein).
- Ein Target ist ein Speicherbereich, der von einem Storage-System zur Verfügung gestellt wird. Die clientseitigen Initiatoren verbinden sich mit diesem Target und können auf den Speicherbereich über SCSI-Befehle zugreifen. Targets können eine Hard- oder Softwarelösung sein: Die Filer-Systeme von Network Appliance sind ein Beispiel für Hardware-iSCSI-Targets. Im Bereich der Software-Targets gibt es diverse Produkte, die auf einem Windows Server aufsetzen und diesen um diese Funktion erweitern. Die Windows Server ab Server 2012 bringen von Haus aus eine iSCSI-Target-Funktionalität mit.
iSCSI ist eine interessante und kostengünstige Technologie, die stetig an Bedeutung gewinnt. Momentan kommt man im Rechenzentrumsbereich nach wie vor kaum an einer FibreChannel-Lösung vorbei. Das liegt letztendlich auch daran, dass die »hoch-endigeren« Speichersysteme bislang nur mit FibreChannel-Konnektivität erhältlich sind.
Weiterhin ist zu berücksichtigen, dass deutlich mehr praktische Erfahrungen mit SAP-Installationen in FC-SANs vorliegen als in iSCSI-Umgebungen.
3.2.2
SAN-Architektur
Der (theoretische) erste Schritt in eine konsolidierte Speicherumgebung ist in Abbildung 3.4 gezeigt: Der Plattenspeicher wird in ein zentrales Storage-System verschoben, und die Server greifen über einen Switch darauf zu. Welche Infrastruktur (FibreChannel, iSCSI) verwendet wird, ist prinzipiell unerheblich!
Meine Segenswünsche begleiten denjenigen, der seiner Geschäftsleitung eine solche Konfiguration als »Hochverfügbarkeit« angepriesen hat. Solch eine Konfiguration wird sich (hoffentlich) in keinem Rechenzentrum finden, denn es gibt bezüglich der Verfügbarkeit nur Schlechtes zu vermelden:
- Die komplette Infrastruktur (FC-HBA im Server, Switch, Kabel) ist nicht redundant.
- Das Storage-System verfügt nur über einen Controller.
- Das Storage-System selbst ist ein Single Point of Failure.
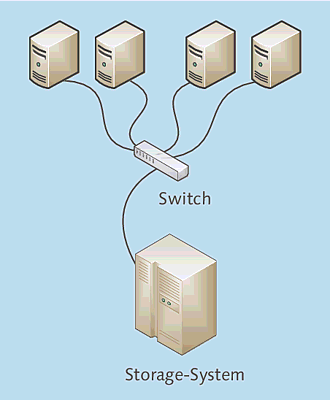
Abbildung 3.4 Speicherkonsolidierung mit einem Datenpfad zwischen Servern und Storage-System
Heute lässt sich eine solche Konfiguration eigentlich gar nicht mehr aufbauen, da die meisten Storage-Systeme generell über zwei Controller verfügen und somit immer pfadredundant angebunden werden. Höchstens im absoluten Einsteigersegment wird sich die in Abbildung 3.4 gezeigte Konfiguration finden – das ist dann aber keine Speicherarchitektur, der man mit gutem Gewissen unternehmenskritische Daten anvertrauen kann!
Die nächste Verbesserung ist die Einrichtung einer Umgebung, in der mehrere (im Allgemeinen zwei) Pfade von den Servern zum Storage-System führen. Das meiste ist doppelt vorhanden (Abbildung 3.5):
- Jeder Server verfügt über zwei FibreChannel-Hostbus-Adapter (FC-HBA).
- Zwei Switches sorgen für Redundanz.
- Das Storage-System verfügt über zwei RAID-Controller, die auf dieselben Plattenbereiche
zugreifen können.
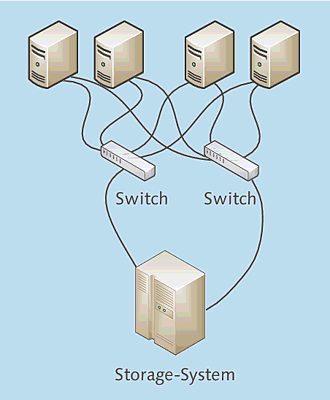
Abbildung 3.5 Speicherkonsolidierte Umgebung mit redundanten Pfaden
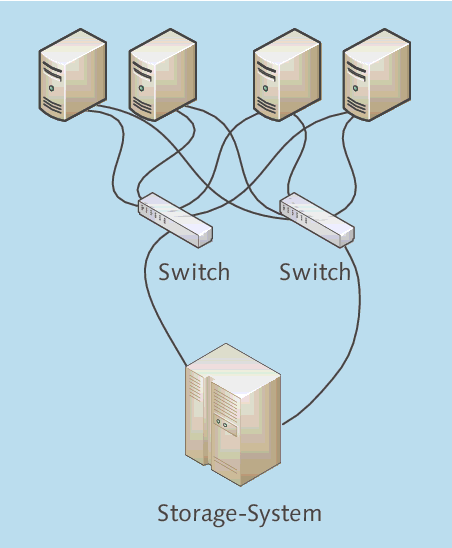
Diese Konfiguration ist bereits eine deutliche Verbesserung, da der Ausfall eines Switches, eines Kabels und sogar eines RAID-Controllers im Storage-System nicht zum Ausfall des Gesamtsystems führt. Diese Konfiguration ist heute gewissermaßen der Standard für eine speicherkonsolidierte Umgebung.
Zu beachten ist, dass das Betriebssystem mit der Multibus-Konfiguration zurechtkommen muss: Ein und derselbe Plattenbereich des Storage-Systems ist für den Server über mehrere Pfade zu erreichen. Im Windows Logical Disk Manager würde dieser Plattenbereich mehrfach angezeigt werden. Bereits Windows Server 2008 verfügt über eine Softwarekomponente, die das Multipathing unterstützt (DMP). Sie kann als Feature Multipfad-E/A installiert werden.
Sie werden es schon geahnt haben: Der nächste Schritt ist die Einführung eines zweiten Storage-Systems. Die Daten werden permanent zwischen den beiden Storage-Systemen gespiegelt oder direkt vom Server doppelt geschrieben (Abbildung 3.6).
Damit diese Architektur sinnvoll ist, dürfen die beiden Storage-Systeme natürlich nicht in einem Raum stehen oder im selben Rack eingebaut sind. Realistische Störfallszenarien sind beispielsweise ein lokaler Kabelbrand oder ein Wasserrohrbruch – wenn das zweite Storage-System sich nur einen Meter weiter im selben Raum befindet, wäre es vermutlich genauso betroffen.
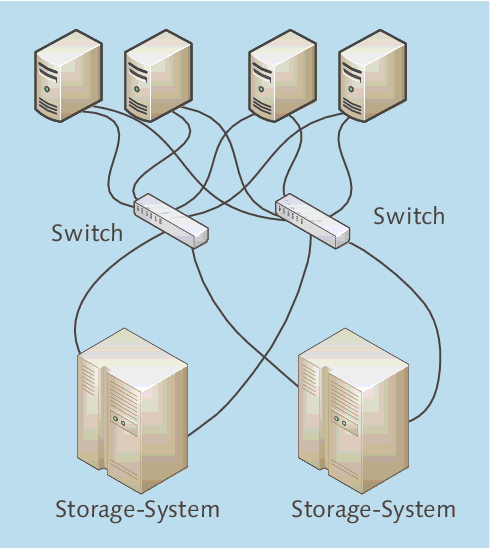
Abbildung 3.6 Speicherkonsolidierte Umgebung mit zwei Storage-Systemen
Es ergibt sich nun die Frage, wie die Daten zwischen den Storage-Systemen gespiegelt werden können. Bei den »höherwertigen« (nicht Entry-Level-) Systemen kann als kostenpflichtige Option (Achtung: dies ist generell sehr teuer) die Funktion der controller-basierten Spiegelung erworben werden.
Der Ablauf der synchronen controller-basierten Spiegelung ist in Abbildung 3.7 gezeigt:
- Ein Server schreibt/ändert einen Block auf dem Storage-System.
- Das primäre Storage-System repliziert diesen Block auf das sekundäre System.
- Das sekundäre System informiert das primäre System, dass die Schreiboperation erfolgreich war.
- Das primäre Storage-System meldet dem Server die erfolgreiche Beendigung des Schreib-/Änderungsvorgangs.
Folgende Aspekte gilt es noch zu beachten:
- Sie müssen entscheiden, wie sich das Gesamtsystem verhalten soll, wenn das primäre
System die Verbindung zum sekundären System verliert. Wenn das wichtigste Ziel ist,
dass Sie absoluten Datengleichstand zwischen beiden Systemen haben, muss im Fehlerfall
das Komplettsystem stehen bleiben. Alternativ kann das primäre System weiterlaufen
und wird die aufgelaufenen Änderungen an das sekundäre senden, sobald die Verbindung
wiederhergestellt ist.
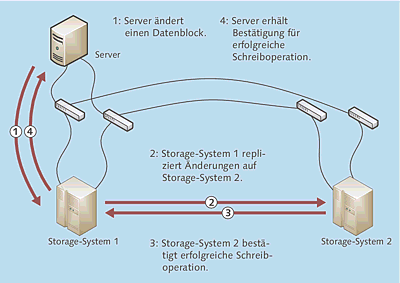
Abbildung 3.7 Ablauf der synchronen controller-basierten Spiegelung
- Wenn zwischen den beiden Storage-Systemen keine Glasfaserstrecke liegt, sondern nur eine langsamere Verbindung (z. B. ATM, FCIP oder iFCP) besteht, würde die synchrone Spiegelung das System signifikant ausbremsen – schließlich ist die Schreiboperation aus Sicht des Servers erst beendet, wenn beide Systeme geschrieben haben. In diesem Fall wird man im Allgemeinen eine asynchrone Replikation wählen: Hierbei wird die Schreiboperation direkt nach dem Schreiben auf das primäre System als erfolgreich an den Server zurückgemeldet; die Replikation auf das sekundäre System wird parallel durchgeführt, läuft aber zeitlich nach. Die Datenbestände auf den Storage-Systemen sind bei der asynchronen Spiegelung nicht zu jeder Zeit absolut identisch.

Beim Ausfall des primären Storage-Systems sind einige Schritte notwendig:
- Dem sekundären Storage-System muss mitgeteilt werden, dass es nun das Hauptsystem ist. Dies kann skriptgesteuert erfolgen.
- Die Server müssen auf ein anderes Storage-System zugreifen. Auch hierfür gibt es Software, die diese Maßnahme durchführt.
Generell müssen Sie entscheiden, ob Sie eine Maschine entscheiden lassen wollen, dass das primäre Storage-System ausgefallen ist und die Funktionen geschwenkt werden, oder ob ein Administrator diese Entscheidung treffen soll. Für letztere Vorgehensweise gibt es durchaus gute Gründe: Es wäre zumindest möglich, dass die Fehlererkennung anschlägt, obwohl das primäre Storage-System sehr wohl noch funktioniert, beispielsweise wegen eines Kommunikationsproblems des Überwachungsrechners.
Als Alternative zur controller-basierten Spiegelung der Storage-Systeme kann eine host-basierte Spiegelung eingesetzt werden. Die Funktionsweise ist in Abbildung 3.8 gezeigt und eigentlich verblüffend einfach: Man sorgt einfach dafür, dass die Server die Daten auf beide Storage-Systeme gleichzeitig schreiben – im Endeffekt ist das ein serverbasiertes RAID1, das mit Windows Server 2012 problemlos zu realisieren ist. Die neuen Storage Pools helfen!
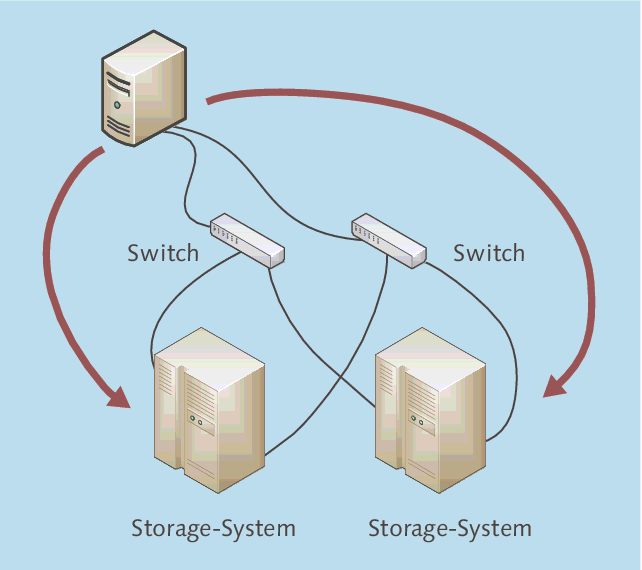
Abbildung 3.8 Funktionsweise der host-basierten Spiegelung
Auf beiden Storage-Systemen wird eine identische Plattenkonfiguration eingerichtet. Auf den Servern werden beide Plattenbereiche angezeigt, und im Server wird eine Spiegelung eingerichtet.
Beim Ausfall eines Storage-Systems wird der Server mit den Daten des verbleibenden Storage-Systems arbeiten. Der Failover-Fall ist hier vergleichsweise einfach, weil der Server mit dem verbliebenen System, mit dem er ja ohnehin bereits aktiv kommuniziert, weiterarbeiten kann – und ohne dass wie bei der controller-basierten Lösung großartig Funktionen geschwenkt werden müssten.
Ist das ausgefallene Storage-System wieder da, müssen natürlich die Änderungen nachgefahren bzw. die Spiegel komplett neu aufgebaut werden.
Bezüglich der Performance ist Folgendes zu vermelden:
- Lesevorgänge werden etwas schneller durchgeführt werden, weil von beiden Storage-Systemen gelesen werden kann.
- Bei Schreibvorgängen ist natürlich die doppelte Datenmenge zu transportieren, weil der Server die geänderten Daten schließlich zu zwei Storage-Systemen transportieren muss. Das Performance-Nadelöhr ist im Allgemeinen aber die Platten- bzw. RAID-Performance und nicht die Breite des Transportwegs. Sofern die Bandbreite zwischen FibreChannel-Hostbus-Adapter und Switch genügend groß ist, dürfte das doppelte Schreiben kein Performance-Problem darstellen. Das softwaremäßige Bilden eines Spiegels stellt nur eine geringe Prozessorbelastung dar. Die Situation muss natürlich jeweils konkret nachgerechnet werden!
- Wichtig ist, dass beide Storage-Systeme hochperformant an den Server angebunden sind. Wenn ein System direkt über FibreChannel und das andere über eine langsame FCIP- oder iFCP-Strecke angebunden ist, wird die Gesamt-Performance dem langsameren System entsprechen – die host-basierte Spiegelung ist immer synchron!
Signifikante Vorteile der host-basierten Spiegelung sind:
- Die Lösung ist vergleichsweise preiswert. Ein zweites Strorage-System nebst Platten muss sowohl bei der controller- als auch bei der host-basierten Lösung beschafft werden. Die Lizenzen für die controller-basierte Spiegelung sind durchgängig bei allen Herstellern sehr teuer.
- Die host-basierte Spiegelung funktioniert mit allen Storage-Systemen. Die controller-basierte Spiegelung ist im Allgemeinen für Entry-Level-Systeme nicht erhältlich.
3.2.3
Premium Features von Storage-Systemen
Storage-Systeme bieten gegenüber serverseitigen RAID-Controllern einige zusätzliche Möglichkeiten, die beim Umgang mit den dort gespeicherten Daten recht hilfreich sein können. Die Rede ist hier von Snapshotting und Cloning. Diese Features müssen generell separat bezahlt werden und tragen von Hersteller zu Hersteller verschiedene Produktnamen – die Funktion ist aber generell ähnlich.
Snapshotting
Eine der interessantesten und gleichzeitig leistungsfähigsten Möglichkeiten ist die Nutzung der Snapshot-Technologie; ihr häufigster Verwendungszweck ist das Backup. Häufig ist das Problem schlicht und ergreifend, dass die Datenmenge zu groß für das zur Verfügung stehende Backup-Fenster ist.
Das Snapshot-Verfahren an sich ist schnell erklärt (das Verfahren wird schematisch und stark vereinfacht dargestellt):
- Alle Dateien auf der Partition des Servers werden geschlossen, im Zweifelsfall müssen Applikationen angehalten werden. Die Cache-Buffer werden geleert.
- Nun wird der eigentliche Snapshot durchgeführt. Als Ergebnis entsteht ein weiteres »virtuelles« Volume. Das Snapshotting dauert nur wenige Sekunden, letztendlich werden keine Daten kopiert, sondern es wird »nur« ein virtuelles Laufwerk erzeugt, das zunächst keine eigenen Daten hält, sondern auf die Originaldaten zugreift.
- Auf Wunsch kann das neu entstandene Laufwerk vom Backup-Server gemountet und gesichert werden.
Schauen wir ein wenig hinter die Kulissen des Snapshots. Beim Snapshotting gibt es mehrere »Vorgehensweisen«, nämlich Copy-on-Write und Split-Mirror. Die meisten Storage-Systeme arbeiten mit dem erstgenanntem Ansatz.
Bei einem Copy-on-Write-Snapshot wird zunächst ein »virtuelles Volume« erzeugt, das selbst keine Daten enthält, sondern auf die Blöcke des Original-Volumes verweist. Dies ist vereinfacht in Abbildung 3.9 dargestellt: Das Snapshot-Volume sieht für eine Anwendung genau so aus wie ein »normales« Volume, man kann ihm natürlich auch einen Laufwerksbuchstaben zuweisen. Greift man beispielsweise auf den dritten Block des Snapshot-Volumes zu, liest man tatsächlich den dritten Block des Original-Volumes.
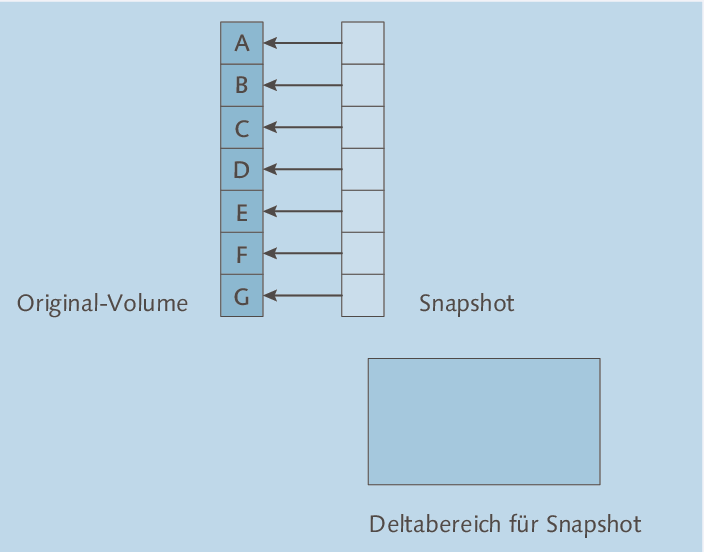
Abbildung 3.9 Copy-on-Write-Snapshot direkt nach dem Erzeugen
Direkt nach dem Erzeugen wird also für den Snapshot kaum Plattenplatz benötigt, da beim Zugriff auf das Snapshot-Volume die Daten vom Original-Plattenbereich gelesen werden. Natürlich wird für die Verwaltung des Snapshots (z. B. Zuweisung zu Blöcken auf dem Original-Volume) Plattenplatz benötigt. Dieser ist im Vergleich zu den eigentlichen Produktionsdaten aber sehr gering.
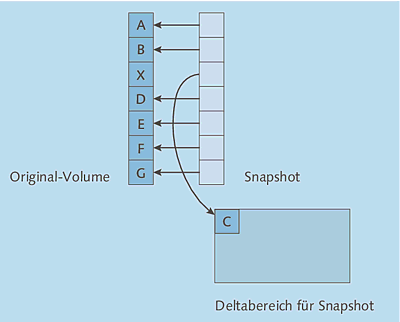
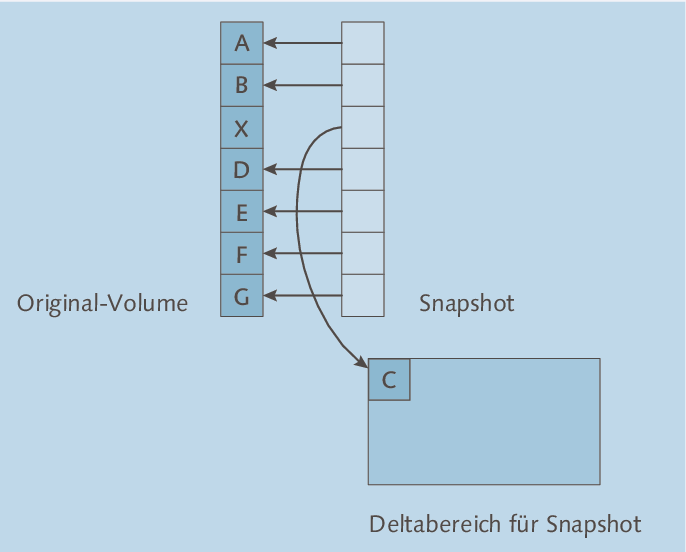
Interessant ist nun das Verhalten des Systems, wenn sich auf dem Original-Volume Blöcke ändern. Dies ist in Abbildung 3.10 schematisch gezeigt:
- Ändert sich auf dem Original-Volume ein Block (in der Abbildung wird aus dem C ein X), wird dessen ursprünglicher Inhalt in einen Deltabereich geschrieben.
- In dem Snapshot-Volume wird nun die »Verpointerung« geändert, sodass der Snapshot
noch immer den ursprünglichen Block enthält, der nun allerdings im Deltabereich liegt.
Volume Shadow Copy Services
Im vorherigen Abschnitt war die Rede davon, dass vor dem Auslösen des Snapshots die Daten im Filesystem konsistent sein müssen, was beispielsweise dadurch möglich ist, dass man die Datenbank anhält oder in einen Backup-Mode versetzt. Microsoft hat für die Sicherung von SQL Server und Exchange Server die Volume Shadow Copy Services entwickelt. Dieses Verfahren werde ich Ihnen an dieser Stelle kurz vorstellen.
Der Volume Shadow Copy Service dürfte vielen Administratoren als einfache Möglichkeit bekannt sein, Dateien zu »snapshotten« und mittels Explorer wiederherzustellen. In den deutschen Windows-Versionen spricht man von Volumen-Schattenkopien. Der Volume Shadow Copy Service bietet wesentlich mehr als nur die Möglichkeit, Snapshots von freigegebenen Ordnern anzufertigen. Es handelt sich vielmehr um eine Technologie, die von Backup-Systemen und Applikationsservern genutzt werden kann, und ebenso kann Storage-Hardware eingebunden werden. Dies alles funktioniert aber nicht ohne das Zutun der entsprechenden Hersteller.
Die Architektur des Volume Shadow Copy Service (VSS) ist in Abbildung 3.11 dargestellt: Neben dem eigentlichen Dienst besteht das System aus Writer, Requestor und Providern.
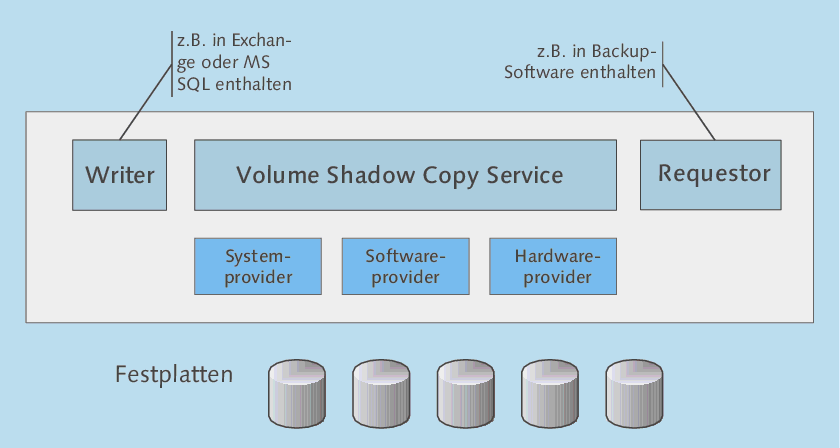
Abbildung 3.11 Schematische Darstellung des Volume Shadow Copy
Die Komponenten haben folgende Aufgaben:
- Requestor: Diese Komponente initiiert einen VSS-gestützten Backup-Vorgang. Im Normalfall wird dies eine Backup-Software sein, die VSS unterstützt. Die meisten »gängigen« Backup-Produkte können als VSS-Requestor arbeiten, beispielsweise das mit dem Betriebssystem mitgelieferte NTBackup oder Veritas BackupExec.
- Writer: Ein Writer ist eine Funktionalität, die in der zu sichernden Applikation integriert ist, beispielsweise in Exchange oder SQL Server. Die Writer-Komponente sorgt beispielsweise dafür, dass eine Datenbank in einen konsistenten »sicherbaren« Zustand gebracht wird. Bei dem zuvor vorgestellten Verfahren über Nicht-VSS-Snapshots hatten wir die Datenbank angehalten bzw. in einen Backup-Mode versetzt. Beim VSS-Verfahren wird der Writer beauftragt, die Applikation entsprechend »vorzubereiten«. Darüber hinaus liefert der Writer beispielsweise Informationen, welche Dateien tatsächlich gesichert werden müssen etc. Mit dem Betriebssystem werden einige Writer mitgeliefert, und einige Applikationen bringen ebenfalls Writer mit. Beispiele für VSS-vorbereitete Applikationen sind Exchange 2003/2007 und SQL-Server 2000/2005/2008.
- Provider: Der Provider übernimmt die eigentliche Arbeit der Erstellung des Snapshots, initiiert also je nach Provider einen Copy-on-Write- oder Split-Mirror-Snapshot. VSS sieht drei Provider-Typen vor: System-, Software- und Hardwareprovider. Letzterer löst die Bildung eines Snapshots auf einem RAID-Controller aus, beispielsweise in einem zentralen Storage-System. Der Systemprovider wird mit Windows Server 2012 mitgeliefert (er war übrigens auch in Windows 2008/2003 enthalten) und erstellt einen Snapshot auf Softwarebasis. Die dritte Gruppe sind Softwareprovider: Ein Beispiel wäre die Ihnen bereits bekannte Veritas Storage Foundation mit FlashSnap-Option. Dieses Softwareprodukt kann ebenfalls als VSS-Provider arbeiten und beherrscht die Erstellung von Split-Mirror-Snapshots. Der mit Windows Server mitgelieferte Systemprovider kann nur Copy-on-Write-Snapshots erstellen.
Der Ablauf eines Backup-Vorgangs mit VSS-Unterstützung sieht wie in Abbildung 3.12 gezeigt aus.
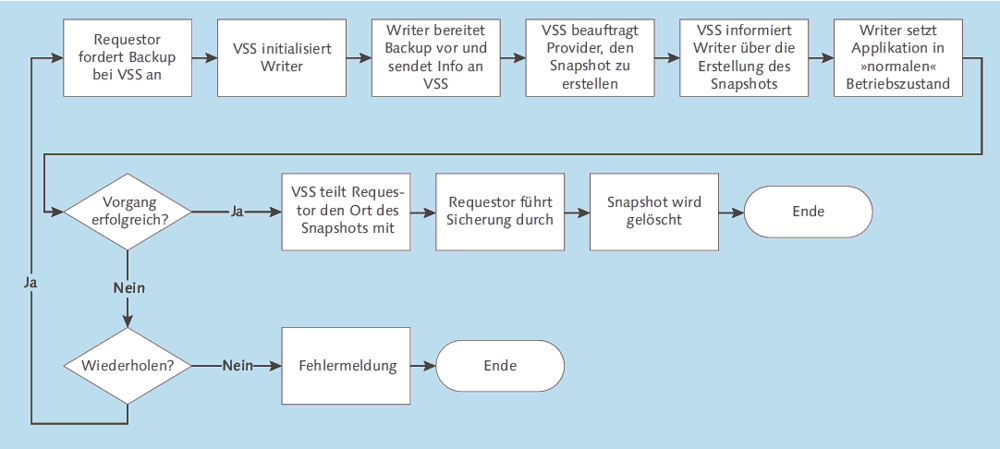
Abbildung 3.12 Ablauf eines Backup-Vorgangs mit VSS-Unterstützung
Generell gilt, dass der Volume Shadow Copy Service die vorhandenen Provider in dieser Reihenfolge verwenden wird:
- Hardwareprovider
- Softwareprovider
- Systemprovider
Ein Requestor (d. h. eine Backup-Software) kann diese Reihenfolge übrigens überschreiben. Wichtig ist also, dass Sie bei der Beschaffung eines Storage-Systems darauf achten, dass Software für die Nutzung als VSS-Hardware-Provider mitgeliefert wird.
Der Volume Shadow Copy Service bietet noch einige weiterführende Möglichkeiten, von denen ich insbesondere Shadow Copy Transport nennen möchte. Hierbei geht es um die Realisierung eines Off-Host-Backups. Für Shadow Copy Transport gelten folgende Voraussetzungen:
- Das Serverbetriebssystem ist Windows Server 2012 (Windows Server 2008 Enterprise oder Datacenter gehen auch. Das Verfahren ist auch mit Windows Server 2003 Enterprise oder Datacenter möglich.)
- Ein Hardwareprovider muss genutzt werden; es wird also ein externes Storage-System mit Snapshotting und VSS-Unterstützung benötigt.
Cloning
Cloning ist vergleichsweise unspektakulär. Es geht darum, Kopien eines Datenbestands zu erzeugen, die dann von einem anderen System genutzt werden können. Zu Zwecken der Datensicherung wird man eher auf die Kombination Snapshot und anschließende Tape-Sicherung zurückgreifen. Für das Cloning sind beispielsweise diese Einsatzgebiete zu nennen:
- Erzeugen von Kopien eines aktuellen Datenbestands für Entwicklungs- oder Testsysteme
- Erzeugen einer Kopie zu einem Stichtag (z. B. Monats- oder Geschäftsjahresende), um diesen Datenbestand eingehend zu analysieren, ohne das Produktivsystem zu belasten
3.2.4
Virtualisierung
Eines der Hype-Wörter im Storage-Umfeld lautet »Virtualisierung«. Dieser Abschnitt zeigt Ihnen einige marktgängige Ansätze.
Controller-basierte Virtualisierung
Ende des Jahres 2001 stellte die Firma Compaq ein System namens Enterprise Virtual Array vor. Hauptmerkmal dieses Systems war die controller-basierte Virtualisierung – ein Alleinstellungsmerkmal.
Diese Technologie ist der Übernahme von Compaq durch Hewlett Packard nicht zum Opfer gefallen: HP vertreibt unter seinem eigenen Namen die Produkte EVA 4x00, EVA 6x00 und EVA 8x00. Ersteres richtet sich an kleinere mittelständische Umgebungen, Letzteres ist für Umgebungen mit sehr hohem Leistungsbedarf gedacht.
Die Besonderheit bei den EVA-Systemen ist nun, dass nicht, wie bei anderen Systemen üblich, für jede LUN ein RAID-Set aus dedizierten Platten gebildet wird, sondern dass die LUNs sämtliche Platten einer Diskgroup nutzen – und zwar jeweils mit dem am besten geeigneten RAID-Level.
SAN-basierte Virtualisierung
Die im vorherigen Abschnitt vorgestellte controller-basierte Virtualisierung trennt letztendlich den Server von der »konkreten« Festplatte, d. h., die Server »wissen« nicht mehr, auf welchen physikalischen Festplatten die geschriebenen oder gelesenen Daten gespeichert werden.
Man kann diese Virtualisierung natürlich weiterführen. Stellen Sie sich eine große Umgebung vor, in der neben vielen Servern nicht nur ein, sondern mehrere Storage-Systeme existieren. Systemarchitekten und -administratoren werden sich in einer solchen Umgebung mit recht großem Aufwand der Frage widmen müssen, welche Speicherbereiche der Server sinnvoll auf welche Storage-Systeme gelegt werden können (Abbildung 3.13).
Die Wolke in Abbildung 3.13 deutet die Lösung dieses Problems an: nämlich eine Virtualisierungsschicht zwischenzuschalten, die dafür sorgt, dass jeder Server genügend große Speicherbereiche sieht, sich aber nicht Gedanken darüber machen muss (sich Gedanken zu machen ist vermutlich eher die Aufgabe des Administrators), auf welchem Storage-System die Daten tatsächlich liegen. In dieser schönen heilen Welt sind Speicheraufrüstungen auch kein Problem mehr: Alle Storage-Systeme sind voll? Kein Problem, fügen wir einfach eine weitere Maschine hinzu!
Zur technischen Umsetzung der Virtualisierung gibt es zwei Ansätze: die In-Band- und die Out-of-Band-Virtualisierung.

Abbildung 3.13 Eine große Umgebung mit vielen Servern und mehreren Storage-Systemen
In-Band-Virtualisierung
Bei der In-Band-Virtualisierung liegt der »Virtualisierer« im Datenstrom. Der Server sieht Speicherbereiche, die er mounten kann und von denen er lesen und schreiben kann. In Wahrheit wird ihm dieser Speicher vom Virtualisierer nur vorgegaukelt, denn der Speicher liegt auf den Storage-Systemen, mit denen der Server aber nicht direkt Daten austauscht.
Wie in Abbildung 3.14 angedeutet ist, bestehen die Virtualisierer häufig aus einem Cluster. Beispielsweise liegt dem IBM SAN Volume Controller (SVC) ein xSeries-Cluster (xSeries sind Intel-basierte Server) zugrunde. Ein weiterer Hersteller, der solche Virtualisierer anbietet, ist die Firma Datacore.
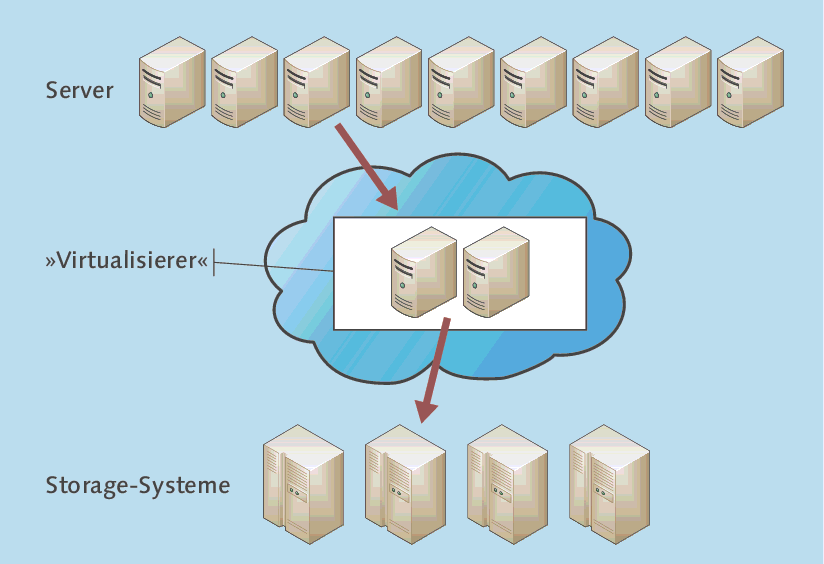
Abbildung 3.14 Funktionsweise der In-Band-Virtualisierung
Out-of-Band-Virtualisierung
Das Prinzip der Out-of-Band-Virtualisierung ist in Abbildung 3.15 gezeigt. Ihr Hauptmerkmal ist, dass der Virtualisierer nicht im Datenpfad liegt. Ein spezieller Treiber auf dem Server sorgt dafür, dass die Metadaten (»welcher Block auf welchem Speichersystem«) vom Virtualisierer abgerufen werden. Der Zugriff auf den Speicher erfolgt dann direkt über FibreChannel-Switches.
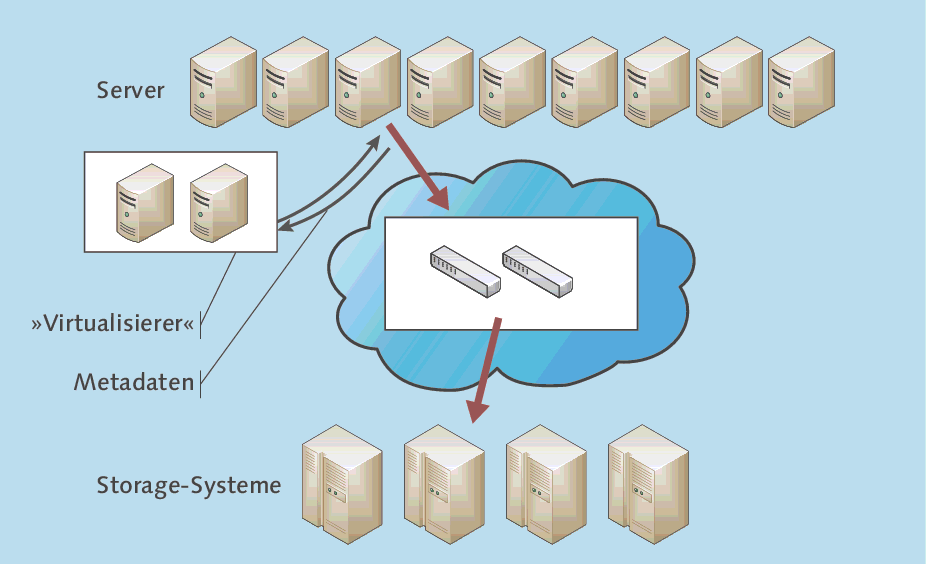
Abbildung 3.15 Funktionsweise der Out-of-Band-Virtualisierung
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen




