


15.2 Disaster Recovery und Hochverfügbarkeit 

15.2.1 Katastrophenfall
In Abbildung 15.2 bin ich schon auf einen Disaster Recovery-Prozess einer physikalischen Maschine eingegangen, um die Vorzüge einer virtuellen Maschine zu demonstrieren. Das ist aber noch lange nicht alles, wie Sie im folgenden Vergleichsbeispiel erkennen können:
Server1 (physikalisch)
|
Betriebssystem |
Microsoft Windows 2000 Server |
|
Service Pack-Stand |
Service Pack 3 |
|
RAID Controller |
ICP Vortex |
|
RAID Level |
RAID 1 (2 Festplatten) |
Server2 (virtuell)
|
Betriebssystem |
Microsoft Windows 2000 Server |
|
Service Pack-Stand |
Service Pack 3 |
|
RAID Controller |
durch Wirt-System abgedeckt |
|
RAID Level |
durch Wirt-System abgedeckt |
Die Hardware von Server1 wurde komplett zerstört und die Daten der Festplatte sind nicht mehr wiederherstellbar. Nun wird folgender Prozess eingeleitet:
- Analyse, welche Hardware defekt ist
- Mitteilung an den Händler, der den Support anbietet
- Händler kommt vor Ort und tauscht die Hardware
- Herunterladen und anschließendes Kopieren der aktuellen RAID Controller-Treiber für das Betriebssystem auf Diskette
- Einrichtung der RAID-Konfiguration auf dem Server (bei mehreren Festplatten muss vielleicht eine Dokumentation vorhanden sein)
- Installation des Betriebssystems (Einbindung der RAID-Treiber, Lizenzschlüssel wird benötigt, Partitionsgröße wird benötigt) – falls die Daten nicht direkt verfügbar sind, wird dies schon zu einem Problem.
- Installation des Servicepacks (Service Pack-Stand muss identisch sein mit jenem zum Zeitpunkt der Sicherung) – dies hört sich simpel an, allerdings neigt man für gewöhnlich dazu, das aktuellste Servicepack einzuspielen, was in diesem Fall (momentan SP 4) zu aktuell wäre, wodurch das Disaster Recovery fehlschlüge.
- Installation des Backup-Agenten
- Rücksicherung der Daten in einer bestimmten Reihenfolge. – Die Reihenfolge ist sehr wichtig und entscheidet über das Gelingen eines Disaster Recovery.
Wie Sie sehen, birgt dieser Prozess eine ganzes Bündel an Fallstricken und Fehlerquellen. Ohne eine lückenlose Dokumentation des Serversystems und des Disaster Recovery-Prozesses an sich, ist ein Fehlschlagen schon vorprogrammiert (Dieses Risiko wird durch den Zeitdruck, unter dem der Administrator in diesem Moment steht, nicht gerade geringer). Natürlich kann man diesen Prozess mit Imaging Tools wie Acronis TrueImage Server oder Disaster Recovery Tools wie Cristie CBMR vereinfachen.
Im Falle der Virtualisierung wäre ein Hardwareausfall der virtuellen Hardware nicht möglich. RAID Controller und RAID-Konfiguration wären im Normalfall nicht vorhanden, da alles über das Wirt-System geregelt wird. Nun wären wir schon bei Punkt 6, d. h., es werden fünf Installationsschritte übersprungen. Schritt 6 und 7 können auch noch beschleunigt werden, indem mit Templates gearbeitet wird. Wenn Sie Templates zum Erstellen einer neuen virtuellen Maschine verwenden, können Sie je nach Performance des Systems mit ungefähr 15 Minuten bis zur Fertigstellung rechnen. In unserem Beispiel wären wir daher in 15 Minuten bei Schritt 8 und müssten nur noch den Backup-Agenten installieren und die Rücksicherung anstoßen. Was dies in Stunden ausmacht, können Sie sich selbst ausrechnen.
Wirt-System
Das Disaster Recovery eines Wirt-Systems ist natürlich wie bei einem normalen physikalischen System auch mit Fehlerquellen und Problemen gespickt. Allerdings ist man in diesem Fall deutlich flexibler, weil man die Daten des Wirt-Systems und der virtuellen Maschinen voneinander trennen kann, beispielsweise mittels SAN, iSCSI oder NAS oder einfach durch Trennung der RAID-Gruppen. Da ein Plattendefekt viel wahrscheinlicher ist als die komplette Zerstörung des Serversystems, reicht selbst die Auftrennung der RAID-Gruppen in System- und VM-Daten zumeist aus. Wenn man einmal von den Daten der virtuellen Maschinen absieht, bleibt nicht mehr allzu viel Wichtiges auf dem Wirt-System bestehen. Nur noch die Konfiguration und Oberflächeneinstellungen sind von einem Ausfall betroffen. Sie können jedoch über eine manuelle Neuinstallation sehr schnell wiederhergestellt werden.
Es wäre ideal, die Wirt-Systeme pärchenweise einzusetzen, die sich im Fehlerfall gegenseitig abdecken könnten. Allerdings kann keines der Virtualisierungsprodukte von Hause aus einen wirkungsvollen Cluster für den Ausfall eines Wirt-Systems bereitstellen, weshalb die virtuellen Maschinen entweder per Skript oder per Hand auf dem anderen System gestartet werden müssten. Aber dazu später mehr.
Darüber hinaus wird ein Server, der als Wirt-System zur Virtualisierung dient, deutlich besser und ausfallsicherer auzustatten sein als ein Standardserver, da von seinem Ausfall zig Server betroffen wären. Dies bedeutet im Umkehrschluss auch eine geringere Wahrscheinlichkeit eines irreparablen Serverausfalles.
15.2.2 Cluster – virtuelle Maschine
Es gibt aber auch Systeme, deren Ausfall schon im Minutenbereich Probleme auslöst. Als Beispiel sei ein Datenbankserver angeführt, dessen Ausfall das komplette Unternehmen lahmlegen würde, da alle relevanten Daten auf ihm liegen. Hier reicht es nicht aus, den Server im Fehlerfall schnellstmöglich wieder aufzusetzen, sondern es muss ein anderer Server unmittelbar einspringen und den Dienst übernehmen. Einen solchen Serververbund, der gleiche Dienste anbietet, nennt man »Cluster«. Ein Cluster kann durch verschiedene Produkte eingerichtet werden. Stellvertretend seien Microsoft Advanced Server, Legato Advanced Co Standby oder Linux genannt.
Nun hat es sich in der letzten Zeit bewährt, entweder virtuelle Maschinen zu clustern bzw. – was noch verbreiteter ist – physikalische Maschinen mit virtuellen Maschinen zu clustern. Da im Fehlerfall der Dienst nicht zwingend in gleicher Geschwindigkeit laufen muss, kann hier eine virtuelle Maschine vorübergehend sehr kostspielige Physik ersetzen. Ein Datenbankserver mit vier CPUs und 4 GB RAM kostet schon ein Stange Geld, diesen zweimal für den Fehlerfall vorzuhalten, noch einmal deutlich mehr. Eine virtuelle Maschine, die mit zwei virtuellen CPUs und 3,6 GB RAM läuft, wäre zwar langsamer, aber sie ist billiger und, was viel wichtiger ist, der Dienst fällt nicht aus.
Ich gehe in diesem Kapitel nur auf die grundsätzlichen Möglichkeiten eines Clusters im Zusammenhang mit virtuellen Maschinen ein. Wie diese technisch realisiert wird, erfahren Sie in Anhang A, in dem Sie auch Tipps zu solchen Konstellationen finden.
VM/VM-Cluster
Cluster zwischen virtuellen Maschinen auf dem gleichen Wirt-System können Sie mit jeder der drei Virtualisierungsprodukte betreiben. Die dazu meist notwendige Quorum Disk wird dann als Shared angelegt und kann so von mehreren virtuellen Maschinen angesprochen werden. Während Microsoft Virtual Server VM-VM Cluster nur zu Testzwecken und nicht in einer produktive Umgebung unterstützt, macht das VMware sehr wohl. Bei VMs, die auf verschiedenen Wirt-Systemen laufen sollen, bietet Ihnen VMware ESX in Verbindung mit einem SAN die beste Unterstützung.
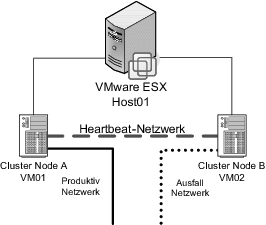
Abbildung 15.5 Ein »In-Box Cluster«, so genannt, weil beide Cluster-Knoten auf dem gleichen Wirt-System laufen
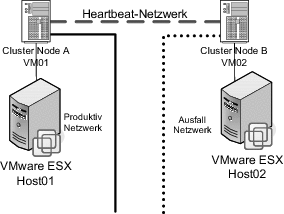
Abbildung 15.6 Dieser Cluster erstreckt sich über zwei VMware ESX Server und bietet daher einen deutlich höheren Ausfallschutz als ein In-Box Cluster.
VM – Physik Cluster
Wie schon vorher erwähnt, ist ein VM/Physik-Cluster eine durchaus praktikable und gängige Methode, günstige und zuverlässige Cluster zwischen Systemen aufzubauen. Diese Art von Clustern wird allerdings nur von VMware ESX in Verbindung mit einem SAN Storage unterstützt. In diesem Fall wird die Quorum Disk auf einem LUN erstellt, das sowohl der VM (als System LUN/Disk) als auch dem physikalische System (als normale Festplatte) zugewiesen wird.
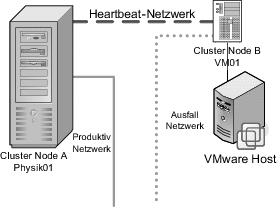
Abbildung 15.7 So sieht ein Cluster zwischen einem virtuellen und einem physikalischen System aus.
15.2.3 Cluster – Wirt-System
Lückenlos funktionierende Cluster zwischen Wirt-Systemen bietet Ihnen momentan keines der Virtualisierungsprodukte. Unter Microsoft Virtual Server können zwar die Wirt-Systeme miteinander geclustert werden, dies deckt aber nicht den Ausfall einer virtuellen Maschine ab, d. h., wenn auf ServerA eine VM ausfällt, wird diese nicht automatisch auf ServerB gestartet. Dies ist jedoch genau die Funktion, die man von einem Wirt-System-Cluster erwarten würde. Allerdings gibt es verschiedene Produkte von Drittanbietern am Markt, mit denen Sie einen funktionierenden Cluster zwischen Wirt-Systemen einrichten können(Leostream). Sie können sich mit entsprechendem Know-how einen solchen Cluster auch skriptieren.
Bei einer Ankündigung kommender Features Ende Oktober 2004 war auch von einer Funktion namens Distributed Availability Services (DAS) die Rede, die ein Failover von virtuellen Maschinen auf andere Wirt-Systeme zur Verfügung stellen wird. Wann und in welcher Form diese Funktionen implementiert werden, ist allerdings noch nicht bekannt.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Ihre Meinung
Ihre Meinung



