


10.4 Einführung in die Netzwerkprogrammierung
Die Programmierung von Netzwerkanwendungen ist ein spannendes und sehr umfangreiches Thema. Es gibt zahlreiche gute Bücher, die diese faszinierende Disziplin der Softwareentwicklung ausführlich beschreiben; in Anhang B werden einige von ihnen vorgestellt. In diesem Abschnitt wird speziell die Programmierung von TCP/IP-Netzwerkanwendungen beschrieben; die herausragende Bedeutung dieser Protokollfamilie muss nicht noch einmal betont werden.
Die konkrete Programmiersprache, in der die Grundlagen der Netzwerkprogrammierung erklärt werden, ist Perl – in kaum einer anderen Sprache sind die Schnittstellen für die Netzwerkprogrammierung so bequem zu benutzen. Allerdings lassen sich die Beispiele leicht in anderen Programmiersprachen nachvollziehen, weil die verwendete Programmierschnittstelle für fast alle Sprachen und Plattformen in ähnlicher Art verfügbar ist. Um dies zu beweisen, wird anschließend ein echter kleiner Webserver in Ruby implementiert.
10.4.1 Die Berkeley Socket API
Die Grundlage für die Programmierung von TCP/IP-Anwendungen ist die Verwendung von Sockets. Die TCP/IP-Kommunikation zwischen zwei Programmen findet stets über zwei Sockets statt, die man als die beiden Enden einer Netzwerkverbindung verstehen kann, vergleichbar mit dem aus Hör- und Sprechmuschel bestehenden Telefonhörer: Wenn eine Netzwerkanwendung einer verbundenen Anwendung etwas mitteilen möchte, schreibt sie in deren Socket hinein; die Anwendung an der Gegenstelle kann die Information aus ihrem eigenen Socket lesen. Anders als die zuvor beschriebenen Pipes ist ein Socket-Paar stets bidirektional, kann also zum Lesen und zum Schreiben gleichzeitig verwendet werden.
Erfreulicherweise ist die Socket-Programmierung schon vor langer Zeit standardisiert worden. An der University of California in Berkeley, an der auch Unix zu seiner vollen Blüte gereift ist, wurde eine Programmierschnittstelle für die Programmierung von TCP/IP-Netzwerkanwendungen geschrieben, die Berkeley Socket API. Eine API (Application Programming Interface) ist eine standardisierte Sammlung von Funktionen und Schnittstellen für die Programmierung bestimmter Anwendungen.
Die ursprüngliche Fassung der Berkeley Socket API wurde als Sammlung von Bibliotheken und Header-Dateien für die Programmiersprache C unter BSD-Unix geschrieben. Genau dieser Umstand sorgt dafür, dass C, Unix und das Internet bis heute eine untrennbare Einheit bilden. Dennoch wurden in der Folgezeit Fassungen der Socket API für viele verschiedene Programmiersprachen und Betriebssysteme geschrieben. Beispielsweise verfügen alle Windows-Systeme über die leicht angepasste Windows Socket Library (WinSock). In diesem Abschnitt wird die Netzwerkprogrammierung am Beispiel der Programmiersprache Perl vorgestellt, da es eine Reihe interessanter Perl-Module gibt, die die Entwicklung von Netzwerkanwendungen erleichtern.
Bevor Sie die Funktionen der Berkeley Socket API in Perl effizient verwenden können, sollten Sie mithilfe von use Socket das Modul Socket importieren. Zwar sind die eigentlichen Funktionen in den Sprachkern von Perl eingebaut, aber ohne die zahlreichen Konstanten für bestimmte Einstellungen, die in diesem Modul definiert sind, ist ihre Verwendung undenkbar.
Die im Folgenden genannten Funktionen – die in C genauso lauten und ähnliche Parameter haben – dienen dem Einrichten und Konfigurieren von Sockets.
Sockets erzeugen
Der Befehl zur Erzeugung eines Sockets hat die folgende grundlegende Syntax:
Diese Anweisung erzeugt ein neues Socket, dem das Dateihandle SOCK für Lese- und Schreiboperationen zugeordnet ist (natürlich können Sie statt SOCK einen beliebigen Dateihandle-Bezeichner verwenden).
Der Parameter $domain enthält einen Wert für das Einsatzgebiet des Sockets. Die entsprechenden Konstanten werden im Modul Socket definiert: AF_INET bezeichnet ein Socket für eine TCP/IP-Verbindung, während AF_Unix ein sogenanntes Unix-Domain-Socket erzeugt. Unix-Domain-Sockets sind ein beliebtes Mittel für die Internet-Prozesskommunikation auf Unix-Systemen. Sie verwenden als Kommunikationsbasis keine Netzwerkverbindung, sondern eine Pipe-ähnliche Datei im Dateisystem. Im Folgenden werden nur AF_INET-Sockets behandelt.
In $type wird eine Konstante für den Socket-Typ angegeben. Es existieren die beiden grundsätzlichen Typen SOCK_STREAM für ein Stream-Socket und SOCK_DGRAM für ein Datagramm-Socket. Stream-Sockets werden in aller Regel für TCP-Verbindungen verwendet, weil sie eine dauerhafte Verbindung zwischen zwei Netzwerkknoten erzeugen. Datagramm-Sockets sind dagegen für die UDP- und ICMP-Netzwerkkommunikation vorgesehen, weil sie verbindungslos sind.
Der vierte Parameter, $proto, erwartet schließlich einen Integer, der das zu benutzende Kommunikationsprotokoll angibt. Zwar existieren zur Angabe des Protokolls keine Konstanten, aber dafür können Sie die Funktion getprotobyname() verwenden. Genau wie die gleichnamige C-Bibliotheksfunktion beziehungsweise der entsprechende Unix-Systemaufruf wandelt sie ein durch seinen Namen angegebenes Protokoll in die entsprechende Nummer um, indem sie es in der Standarddatei /etc/protocols nachschlägt. Für Unix-Domain-Sockets wird dagegen die Konstante PF_UNSPEC (»kein bestimmtes Protokoll«) angegeben.
Die folgenden beiden Beispielzeilen erzeugen ein TCP-Stream-Socket beziehungsweise ein UDP-Datagramm-Socket:
socket (TCP_SOCK, AF_INET, SOCK_STREAM,
getprotobyname ('tcp'));
socket (UDP_SOCK, AF_INET, SOCK_DGRAM,
getprotobyname ('udp'));
Adressen und Ports
Wie die IP-Adressierung funktioniert und was TCP- und UDP-Ports zu bedeuten haben, wurde in Kapitel 4, »Netzwerkgrundlagen«, ausführlich erläutert. Für die Socket-Programmierung müssen Adressen und Ports in speziellen Strukturen gespeichert werden, die der C-Standardbibliothek entstammen. Zu diesem Zweck werden verschiedene Bibliotheksfunktionen zur Verfügung gestellt, die der Umwandlung von Hostnamen, Adressen und Ports in das korrekte Format dienen:
- gethostbyname ($hostname)
Diese Funktion wandelt den angegebenen Hostnamen in die entsprechende IP-Adresse um. Damit dies korrekt funktioniert, benötigen Sie Zugriff auf einen Namensdienst, der in der Lage ist, den entsprechenden Hostnamen aufzulösen, im Internet also beispielsweise auf einen DNS-Server. Das Ergebnis ist eine Struktur, die den Hostnamen und die in ASCII-Zeichen gepackte IP-Adresse enthält. - inet_aton ($host_oder_ip)
Mithilfe dieser Funktion wird ein Hostname oder eine IP-Adresse in dezimaler Vierergruppenschreibweise (zum Beispiel 192.168.0.9) in vier ASCII-Zeichen verpackt. Viele Socket-Funktionen benötigen diese Schreibweise. inet_ntoa ($pack_adr) erledigt übrigens die umgekehrte Aufgabe und wird mitunter benötigt, um die mit einem Datenpaket empfangene Adresse des Gegenübers zu entschlüsseln. - sockaddr_in ($port, $pack_adr)
Die Funktion sockaddr_in macht aus einer Portangabe und einer mithilfe von inet_aton gepackten Adresse eine speziell verpackte Host-Port-Struktur, die Sie für die Angabe der Gegenstelle bei einer Netzwerkverbindung verwenden können. Das folgende Beispiel erstellt eine solche Struktur für den Zugriff auf Port 80 (den HTTP-Server) auf dem Host www.galileo-computing.de:$webserver = sockaddr_in
(80, inet_aton ('www.galileo-computing.de'));Interessanterweise ist sockaddr_in gleichzeitig in der Lage, die umgekehrte Umwandlung vorzunehmen: Wenn Sie ein gepacktes Host-Port-Paar aus einem Datenpaket erhalten, können Sie es folgendermaßen entpacken:
($port, $host) = sockaddr_in ($pack_port_host);
- getservbyname ($service, $proto)
Statt der numerischen Angabe des Ports können Sie die sogenannten Well-known Ports mit Nummern bis 1023, die bei gängigen Serverdiensten eingesetzt werden, auch durch ihren Namen angeben und per getservbyname umwandeln. Als zweites Argument benötigen Sie dazu das Transportprotokoll ('tcp' oder 'udp'). Zum Beispiel können Sie folgendermaßen eine Verbindung zu dem FTP-Server ftp.uni-koeln.de herstellen:$port = getservbyname ('ftp', 'tcp');
$ftpserver = sockaddr_in
($port, inet_aton ('ftp.uni-koeln.de'));
Verbindungen herstellen, Daten senden und empfangen
Was als Nächstes mit dem Socket geschieht, hängt zum einen davon ab, ob Sie ein Stream- oder ein Datagramm-Socket erzeugt haben und, falls es ein Stream-Socket ist, ob Sie gerade einen Client oder einen Server schreiben.
UDP-Datagramm-Sockets können Sie nach dem Erstellen ohne weitere Formalitäten verwenden, um einfache Nachrichten zu versenden oder von anderen UDP-Anwendungen zu empfangen. Dazu werden die Anweisungen send() und recv() verwendet:
- send (SOCK, $data, 0, $receiver);
Diese Anweisung sendet den Dateninhalt $data über das Socket SOCK an den Empfänger $receiver. Der Empfänger wird als sockaddr_in-Struktur angegeben (siehe vorigen Abschnitt). Der dritte Parameter ist normalerweise 0; er kann in sehr seltenen Fällen einen speziellen Wert für besondere Routing-Einstellungen enthalten. - recv (SOCK, $data, $maxlength, 0);
Die Anweisung recv() empfängt ein UDP-Datagramm. Der gelesene Wert wird in der Variablen $data gespeichert, während das Funktionsergebnis den Absender des Datagramms angibt. Von den meisten UDP-Servern können Sie Daten nur dann empfangen, wenn Sie zuvor mithilfe von send() eine Anfrage an sie geschickt haben.
Auf UDP-Anwendungen wird hier nicht weiter eingegangen. Bei TCP-Sockets sieht die Angelegenheit komplizierter aus: Falls Sie einen Server programmieren, der eine Dienstleistung zur Verfügung stellt, müssen Sie das Socket zum lauschenden (»listening«) Socket machen. Schreiben Sie dagegen einen Client, müssen Sie als Nächstes eine Verbindung zu einem Server-Socket herstellen.
Beispielsweise können Sie folgendermaßen eine Verbindung zu dem Webserver www.galileodesign.de herstellen und ihm eine GET-Anfrage schicken; anschließend werden sämtliche zurückgegebenen Zeilen gelesen und am Bildschirm angezeigt:
#!/usr/bin/perl -w
use Socket;
use IO::Handle;
$port = getservbyname ('http', 'tcp');
$dest = sockaddr_in
($port, inet_aton ('www.galileodesign.de'));
socket (SOCK, AF_INET, SOCK_STREAM,
getprotobyname ('tcp'));
connect (SOCK, $dest);
# Socket in den Autoflush-Modus schalten:
SOCK->autoflush (1);
# HTTP-Anfrage für Startseite senden:
print SOCK "GET / HTTP/1.0\n\n";
# Antwort des Servers zeilenweise ausgeben:
while ($line = <SOCK>) {
chomp $line;
print "$line\n";
}
Dieses Programm übernimmt tatsächlich die Hälfte der Funktionalität eines Browsers: Es richtet eine HTTP-Anfrage an einen Webserver und liest das erhaltene Dokument. Der kompliziertere Teil eines Browsers ist freilich nicht enthalten, nämlich derjenige, der den erhaltenen HTML-Code interpretiert und ein formatiertes Dokument daraus macht. Stattdessen wird die gesamte Ausgabe des Servers einfach angezeigt, und zwar nicht nur das eigentliche HTML-Dokument (die Startseite von Galileo Design), sondern auch sämtliche HTTP-Header.
In diesem Programm werden einige neue Funktionen verwendet:
- connect (SOCK, $dest);
Diese Anweisung stellt eine Verbindung zu einem TCP-Server her, der mithilfe der gepackten Adresse $dest angegeben wird. Anschließend können Sie das Socket wie ein Dateihandle verwenden, um Daten daraus zu lesen und hineinzuschreiben. - SOCK->autoflush(1);
Die Funktion autoflush ist im Modul IO::Handle definiert, das aus diesem Grund mithilfe von use eingebunden wird. Sie sorgt dafür, dass Schreiboperationen in das Socket (beziehungsweise ein beliebiges Dateihandle) unmittelbar abgeschickt und nicht gepuffert werden, bis mehr Daten zusammenkommen. Falls Sie die Zeile weglassen, bleibt das Programm einfach kommentarlos stehen.
Die restlichen Socket-Funktionen wurden zuvor schon erläutert. Die eigentliche Kommunikation mit dem Server erfolgt über die Funktion print und den Operator <>; die Verwendung dieser Anweisungen mit Dateihandles wurde bereits im vorigen Kapitel erklärt.
Interessant ist noch die eigentliche GET-Anfrage, die an den Webserver geschickt wird:
GET / HTTP/1.0
Es wird also die Startseite der Website (/) über das Protokoll HTTP 1.0 angefordert. In diesem Zusammenhang können Sie die aktuelle Variante HTTP 1.1 nicht verwenden, weil sie einen Host-Header erwartet. Die Anfrage muss, wie hier gezeigt, durch zwei Zeilenumbrüche abgeschlossen werden.
Für einen Server sind zusätzlich die folgenden Anweisungen wichtig:
- bind (SOCK, $addr);
Diese Anweisung bindet ein zuvor erzeugtes Socket an eine (lokale) sockaddr_in-Adresse. Sie können jede Ihrer lokalen Schnittstellenadressen, die Loopback-Adresse (127.0.0.1) oder die Konstante INADDR_ANY (für jede beliebige Adresse) verwenden.Noch wichtiger als die Adresse selbst ist übrigens der Port, den Sie mithilfe von sockaddr_in in die Struktur einfügen, weil es der spezifische Port ist, auf dem der Server lauschen soll. Beachten Sie, dass Sie unter Unix root-Rechte benötigen, um einen der Well-known Ports unter 1024 anzusprechen. Darüber hinaus ist es ein erhebliches Sicherheitsrisiko, ein selbst geschriebenes und nicht sicherheitsoptimiertes Programm auf einem solchen Port laufen zu lassen, den die Schnüffel-Tools potenzieller Angreifer standardmäßig auf Angriffsmöglichkeiten überprüfen.
Das folgende Beispiel bindet ein Socket an jede beliebige Adresse des Servers und lauscht an Port 11111:
bind (SOCK, sockaddr_in (11111, INADDR_ANY));
- listen (SOCK, $max_queue);
Die Anweisung listen benötigt ein mithilfe von bind gebundenes Socket und wandelt es in ein lauschendes Socket um: Dieses Socket wartet auf den Verbindungsversuch eines Clients mithilfe von connect, wie er eingangs erläutert wurde. Das Argument $max_queue gibt die maximale Größe der Warteschlange dieses Sockets an, bestimmt also, wie viele Clientverbindungen darauf warten können, akzeptiert zu werden. Normalerweise wird hierfür die Konstante SOMAXCONN verwendet, die den maximalen Wert enthält, den das Betriebssystem zulässt. - $remote_addr = accept (SOCK_CONN, SOCK);
Sobald auf dem lauschenden Socket eine Verbindung eingeht, wird die nächste Programmzeile ausgeführt – normalerweise enthält sie einen solchen accept-Befehl. SOCK_CONN ist ein neues, mit dem Client verbundenes Socket, das durch diese Anweisung erzeugt wird. Die gepackte Adresse des Clients steht im Funktionsergebnis.
Das Modul IO::Socket
Eine große Erleichterung für Perl-Programmierer ist die Verwendung des Moduls IO::Socket statt der bisher behandelten Bibliotheksbefehle. Das Modul stellt bequeme Funktionen zur Verfügung, die die meisten komplexen Umwandlungsbefehle überflüssig machen. Beachten Sie, dass die Anweisungen, die in diesem Abschnitt behandelt werden, nicht kompatibel mit der C-Standardbibliothek und der ursprünglichen Berkeley Socket API sind.
Eingebunden wird das Modul folgendermaßen:
use IO::Socket;
Beachten Sie, dass das Modul von IO::Handle abgeleitet ist und deshalb bereits die zuvor erwähnte Funktion autoflush enthält. Die IO::*-Module verfolgen alle einen objektorientierten Ansatz, der hier einfach intuitiv verwendet wird. Auf die objektorientierte Programmierung mit Perl geht dieses Buch dagegen aus gutem Grund nicht ein – sie ist ziemlich komplex und umständlich und lässt sich nicht mit der Eleganz von Java- geschweige denn Ruby-Klassen messen.[Anm.: Deshalb wurde die gesamte Objektorientierung in der kommenden Perl-Version 6 grunderneuert.]
Mithilfe der IO::Socket-API wird ein neues Socket folgendermaßen eingerichtet:
$sock = IO::Socket::INET->new (@args);
Beachten Sie, dass $sock formal kein Dateihandle ist, sondern eine Referenz auf ein Socket, die von der entsprechenden Funktion zurückgegeben wird. Wenn Sie die strenge Syntaxüberprüfung (use strict) verwenden, müssen Sie diese Variable also mithilfe von my deklarieren. In allen anderen Belangen funktioniert die Referenz wie ein gewöhnliches Socket. Die Funktion IO::Socket::INET->new erzeugt übrigens nur Sockets vom Typ AF_INET; für Unix-Domain-Sockets müssen Sie dagegen IO::Socket::Unix->new aufrufen.
Die Argumentliste @args gibt die Eigenschaften des Sockets als Name-Wert-Paare an. Die wichtigsten dieser Einstellungen sind folgende:
- PeerAddr übergibt die Adresse des entfernten Hosts. Sie können einen Hostnamen oder eine IP-Adresse verwenden. Wenn Sie PeerAddr angeben, wird nach der Erzeugung des Sockets automatisch connect() aufgerufen, es handelt sich also um eine Eigenschaft für ein Client-Socket.
- PeerPort ist der entfernte Port. Alternativ können Sie ihn auch, durch Doppelpunkt getrennt, bei PeerAddr angeben.
- LocalAddr gibt die lokale Adresse an.
- LocalPort ist der lokale Port. Geben Sie nur LocalPort, nicht aber LocalAddr an, so wird für die Adresse automatisch INADDR_ANY eingetragen – in der Regel genau das, was Sie benötigen.
- Proto ist der Name oder die Nummer des zu verwendenden Protokolls, also 'tcp' oder 'udp'.
- Listen gibt die Größe der Lauschwarteschlange an. Wenn dieses Argument vorhanden ist, wird darüber hinaus automatisch listen() aufgerufen, sodass das Socket zum lauschenden Socket wird.
- Type gibt den Socket-Typ an, also eine der Konstanten SOCK_STREAM oder SOCK_DGRAM.
Das folgende Beispiel erzeugt ein typisches TCP-Client-Socket, das eine Verbindung zum FTP-Server der Uni Köln herstellt:
my $sock = IO::Socket::INET->new
(Proto => 'tcp',
PeerAddr => 'ftp.uni-koeln.de',
PeerPort => 'ftp');
Um dagegen ein lauschendes Socket einzurichten, das für einen Server verwendet werden kann, können Sie beispielsweise folgenden Befehl benutzen:
my $listen = IO::Socket::INET->new
(Proto => 'tcp',
LocalPort => 22222,
Listen => SOMAXCONN);
Dieses Socket lauscht also auf Port 22222 an jeder beliebigen Adresse des Hosts und lässt so viele wartende Verbindungsversuche zu, wie das Betriebssystem erlaubt.
10.4.2 Ein praktisches Beispiel
Mit dem Wissen aus dem vorigen Abschnitt ist es eigentlich kein Problem, beliebige Server und Clients in Perl zu programmieren. Falls Sie wohlbekannte Protokolle implementieren möchten, müssen Sie die entsprechenden RFCs lesen und Punkt für Punkt abarbeiten. Für das Buch »Apache 2« habe ich zur Verdeutlichung des Grundprinzips einen kleinen Webserver geschrieben, der einen winzigen Ausschnitt der HTTP-Spezifikation erfüllt – die einfache Auslieferung statischer Dokumente funktioniert unproblematisch. Eine Beschreibung sowie eine Downloadmöglichkeit finden Sie unter http://buecher.lingoworld.de/apache2/server.html. In Abschnitt 10.4.3 finden Sie ebenfalls einen kleinen Webserver, allerdings in Ruby geschrieben.
Der Server
Das folgende Beispiel implementiert einen einfachen Server, der nach einer Clientanmeldung jede Anfrage mit der Anzahl der bisherigen Anfragen dieses Clients sowie mit Datum und Uhrzeit beantwortet. Falls der Dateninhalt der Anfrage "reset" lautet, wird die Anzahl zurückgesetzt; bei "exit" wird die Verbindung beendet. Hier zunächst der Sourcecode:
#!/usr/bin/perl -w
use strict;
use IO::Socket;
# Lauschendes Socket erzeugen
my $listen = IO::Socket::INET->new
(Proto => 'TCP',
LocalPort => 11111,
Listen => SOMAXCONN);
print "Server lauscht an Port 11111 ...\n";
# Logdatei zum Anhängen öffnen
open LOG, ">>log.txt";
# Accept-Schleife
while (1) {
# Keine Anfrage? Nächster Durchlauf!
next unless my $conn = $listen->accept();
# Verbindungsaufbau - Child-Prozess erzeugen
my $child = fork;
if ($child == 0) {
# Im Child-Prozess? Verbindung verarbeiten
handle_conn ($conn);
# Wieder da? Child beenden
exit (0);
}
}
sub handle_conn {
my $anzahl = 0;
my $sock = shift;
my $peer = $sock->peerhost;
print " Connection from $peer\n";
# Anfragen lesen
while (my $request = <$sock>) {
$request =~ s/\s*$//;
# Beenden bei "exit"
last if $request eq "exit";
# reset?
$anzahl = 0 if $request eq "reset";
# Datum und Uhrzeit
my $now = scalar localtime;
# Anzahl erhöhen
$anzahl++;
# Ausgabe
print $sock "${anzahl}. Anfrage: $now\n";
# Log-Eintrag
print LOG "${peer}: \"${request}\" ($now)\n";
}
print $sock "Bye.\n";
print " Connection closed by $peer\n";
}
Das lauschende Socket wird nach dem eingangs gezeigten Schema erstellt; der Server lauscht an Port 11111. Die accept()-Schleife springt jeweils sofort mit next() zum nächsten Durchgang, falls kein Verbindungswunsch eines Clients eintrifft. Ist dies der Fall, wird zunächst mithilfe von fork() ein Child-Prozess erstellt, der sich exklusiv um den neuen Client kümmert. Auf diese Weise kann der Server mehrere Clients gleichzeitig bedienen. Dieses einfache Nebenläufigkeitsmodell wird als Forking-Server bezeichnet; für Hochleistungsserver ist es nicht geeignet, da das Erstellen neuer Prozesse im laufenden Betrieb zu lange dauert.
Der Child-Prozess ruft die Subroutine handle_conn() auf. Sie liest die Clientanfragen zeilenweise aus dem akzeptierten Socket; das Ersetzen von Whitespace am Ende – s/\s*// – ist wegen der unterschiedlichen Zeilenumbrüche sicherer als chomp(). Der Server reagiert je nach Befehl auf die Anfragen, wie zuvor dargestellt. Bei "exit" wird die Schleife mit last() beendet.
Wie es sich für einen Server gehört, führt er eine Log-Datei über alle Clientzugriffe. Jeder Eintrag hat das Format Client-IP: "Anfrage" (Datum/Uhrzeit). Beispiel:
127.0.0.1: "reset" (Wed May 06 23:02:16 2005)
Der Client
Der Client ist noch trivialer als der Server und soll vor allem demonstrieren, dass es üblich ist, hinter den Kulissen andere Befehle zu verwenden als die Benutzereingaben. Er akzeptiert eine Eingabe nach der anderen, sendet sie – eventuell in modifizierter Form – an den Server und gibt dessen Antworten aus. Nach der Eingabe von 'x' – dem Serverbefehl "exit" – wird er beendet. Hier das kurze Listing:
#!/usr/bin/perl -w
use strict;
use IO::Socket;
# Host von Kommandozeile oder localhost
my $host = $ARGV[0] || "localhost";
# Server-Verbindung
my $sock = IO::Socket::INET->new
(Proto => 'tcp',
PeerAddr => $host,
PeerPort => 11111);
print "<0> zurücksetzen, <X> beenden, <Enter> Info.\n";
# Kommunikations-Schleife
while (1) {
print "> ";
my $eingabe = <>;
chomp $eingabe;
# Je nach Eingabe Befehle an den Server senden
if ($eingabe eq '0') {
# Zähler zurücksetzen
print $sock "reset\n";
} elsif ($eingabe =~ /^x$/i) {
# Verbindung beenden
print $sock "exit\n";
} else {
# Normal: Anzahl/Datum erfragen
print $sock "$eingabe\n";
}
# Serverantwort lesen
my $antwort = <$sock>;
$antwort =~ s/\s*$//;
print "Antwort von $host: $antwort\n";
# Beenden?
last if $eingabe =~ /^x$/i;
}
10.4.3 Ein Ruby-Webserver
Es folgt hier ein etwas umfangreicheres TCP-Server-Beispiel: ein Ruby-basierter HTTP-Server. Wenn Sie einen voll ausgestatteten Webserver benötigen, wählen Sie am besten Apache – er wird in Kapitel 13, »Server für Webanwendungen«, ausführlich beschrieben. Hier geht es lediglich um die einfachste Grundfunktionalität: Wenn Sie mithilfe eines Browsers eine statische Datei anfordern, wird sie ausgeliefert.
Dieser Server erläutert im Schnelldurchlauf die Verwendung von Sockets, Prozessen und Threads in Ruby. Dabei ahmt er ansatzweise sogar ein interessantes Feature von Apache 2 nach: Sie können selbst bestimmen, ob der Server die Nebenläufigkeit durch Forking, also durch neue Prozesse, oder durch Threading bereitstellen soll. Die Prozess-Variante funktioniert allerdings nur auf Unix-Systemen; Ruby für Windows enthält keine fork-Implementierung. Das Programm stellt aber automatisch fest, auf welcher Plattform es läuft, und ignoriert die betreffende Einstellung unter Windows.
Schritt für Schritt soll der Webserver folgende Aufgaben durchführen:
- Konfiguration aus Kommandozeilenparametern lesen oder auf Standardwerte setzen:
- Architektur: forked oder threaded; Unix-Standardwert forked,
Windows nur threaded - TCP-Port; Standardwert 8000
- Website-Stammverzeichnis; Standard: htdocs unterhalb des Serververzeichnisses
- Indexseite: die Startseite, die automatisch geliefert werden soll, wenn ein Client ein Verzeichnis anfordert; Standardwert index.html
- Architektur: forked oder threaded; Unix-Standardwert forked,
- Am eingestellten TCP-Port auf Client-Verbindungsanfragen lauschen
- Eingehende Verbindungen verarbeiten, gleichzeitig auf weitere lauschen. Dazu wird je nach Architektur ein neuer Prozess beziehungsweise Thread für die Clientanfrage erzeugt, während der Parent-Prozess beziehungsweise Haupt-Thread weiter die accept-Schleife ausführt.
- Innerhalb der Clientverbindung die Clientanfrage auswerten und den URL-Pfad in einen Datei- oder Verzeichnispfad unterhalb des Stammverzeichnisses umwandeln; im letzteren Fall den Namen der Indexseite anfügen
- Die Anfrage beantworten. Falls der Client eine andere Anfrage-Methode als GET verwendet hat, das heißt eine andere Dienstleistung als die Lieferung einer Datei erwartet, erhält er eine Fehlermeldung mit dem Status 501 Not Implemented. Andernfalls sucht der Server nach der angeforderten Datei. Wenn sie nicht vorhanden ist, antwortet er mit dem Status 404 Not Found. Ansonsten liefert er die Datei aus, mitsamt dem Status 200 OK.
In Abbildung 10.2 sehen Sie ein Flussdiagramm, das die Arbeitsschritte des Servers illustriert.
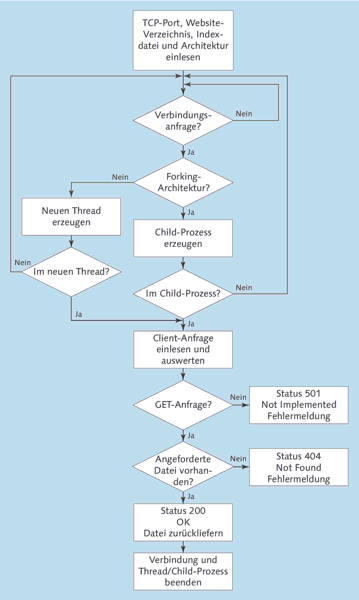
Abbildung 10.2 Flussdiagramm mit dem Schema des Ruby-Webservers
Code-Dokumentation
Als Erstes wird – ähnlich wie in Perl – die (mit Ruby gelieferte) Socket-Bibliothek importiert; dies erledigt die Zeile
require "socket"
Diese Bibliothek liefert einen Socket-Zugriff in Form bequemer Klassen wie TCPSocket für TCP-Clients oder TCPServer für einen TCP-Server. Der kleine Webserver verwendet die Klasse TCPServer.
Da Methoden in Ruby nur aufgerufen werden können, wenn sie weiter oben im Code bereits definiert wurden, kommt die Methode zur Verarbeitung von Clientanfragen als Erste an die Reihe. Als Argument nimmt sie das von accept gelieferte Client-Socket entgegen, sodass ihr Methodenkopf so aussieht:
def handle_conn(conn)
...
end
Innerhalb der Methode wird für die Log-Datei als Erstes die IP-Adresse des Clients ermittelt. Diese steht in der Struktur socket.peeraddr, ein Array mit vier Elementen. Hier zum Beispiel der Inhalt bei einem Client-Socket, das mit www.heise.de, Port 80, verbunden ist:
["AF_INET", 80, "www.heise.de", "193.99.144.85"]
Es handelt sich also um Protokollfamilie, Port, Hostname des Verbindungspartners (falls verfügbar) sowie dessen IP-Adresse. Die benötigte Information steht demzufolge in peeraddr[3]:
client_ip = conn.peeraddr[3]
Nun wird die erste Zeile aus der Clientanfrage gelesen:
request = conn.gets
Es handelt sich um die eigentliche HTTP-Anfrage, die zum Beispiel wie folgt lautet, wenn ein Browser das Dokument index.html aus dem obersten Verzeichnis der Website anfordert:
GET /index.html HTTP/1.1
Alle nachfolgenden Zeilen der Anfrage sind Header mit genaueren Angaben, die dieser Server nicht auswertet. Der Aufbau von HTTP-Anfragen wird in Kapitel 13, »Server für Webanwendungen«, ganz genau erläutert.
Anschließend wird die Anfrage in ihre drei Bestandteile Methode, URL-Pfad und HTTP-Protokollversion zerlegt:
(method, uri, http) = request.split(/\s+/)
Dem URL-Pfad wird nun das Website-Verzeichnis des Servers vorangestellt. Dieser Pfad steht in der globalen Variablen $docroot und wurde entweder von der Kommandozeile gelesen oder auf den Standardwert htdocs unterhalb des Serververzeichnisses selbst gesetzt:
uri.sub!(%r|^/?|, "#{$docroot}/")
Auch die Indexseite (Startseite) steht in einer globalen Variablen; ihr Standardwert ist index.html. Wenn die angeforderte Ressource ein Verzeichnis ist, wird dieser Dateiname automatisch angehängt:
if File.directory?(uri)
uri.sub!(%r|/?$|, "/#{$dirindex}")
end
Als Nächstes werden Datum und Uhrzeit in zwei verschiedenen Formaten benötigt; einmal für die Log-Datei und einmal für den HTTP-Header Date. Details lesen Sie an entsprechender Stelle im Quellcode.
Nun wird die Serverantwort vorbereitet. Es gibt drei verschiedene Varianten:
- Wenn die Anfragemethode anders lautet als GET, kann dieser Server sie nicht verarbeiten. Er antwortet deshalb mit dem Status 501 Not Implemented und schickt zusätzlich eine kurze, für Menschen lesbare Meldung im HTML-Format mit.
- Falls die angeforderte Datei nicht existiert, antwortet der Server mit 404 Not Found.
- Wenn diese beiden Fehler ausgeschlossen werden konnten, wird die angeforderte Datei ausgeliefert; der zugehörige Status ist 200 OK.
Da die Antwort in allen drei Fällen dasselbe Grundformat besitzt, genügt es, den letzten Fall zu betrachten. Für diesen wird zunächst der MIME-Type (Datentyp) der Datei ermittelt, den der Browser benötigt, um die Datei korrekt anzeigen zu können. Dazu schlägt der Server die Endung der angeforderten Datei in dem globalen Hash $mime_types nach:
mime_type = "text/plain"
$mime_types.each_key { |ext|
if uri =~ /\.#{ext}$/
mime_type = $mime_types[ext]
end
}
Wenn die Endung nicht vorhanden ist, bleibt es bei text/plain, das heißt, der Browser soll die Antwort als Klartext betrachten. Wenn Sie möchten, können Sie auch application/octet-stream als Standardtyp angeben, den MIME-Type für beliebige Binärtypen. In diesem Fall wird der Server unbekannte Dateien zum Download anbieten.
Der Browser erwartet, dass ein Server ihm die Länge der gelieferten Ressource mitteilt. Ruby kann sie mithilfe der Klassenmethode File.size ermitteln:
len = File.size(uri)
Dann wird die Datei geöffnet, in einem Schritt komplett gelesen und in der Variablen body gespeichert:
bodyfile = File.open(uri, 'r')
body = bodyfile.read
bodyfile.close
Als Nächstes werden Statuscode und -meldung für die Serverantwort gespeichert:
statuscode = 200
statusmsg = "OK"
Anschließend generiert der Server noch ein Array mit diversen Headern, die er zur Antwort hinzufügt:
headers = []
headers << "Date: #{serverdate}"
headers << "Server: #{$server_token}"
headers << "Connection: close"
headers << "Content-Type: #{mime_type}"
headers << "Content-Length: #{len}"
Datum, MIME-Type und Body-Länge wurden bereits erwähnt. Hinzu kommen die Selbstidentifikation des Servers sowie die Angabe, dass er die Verbindung mit Auslieferung der aktuellen Antwort schließt.
Damit ist der spezifische Teil der Antworterzeugung beendet; der Rest der Methode gilt für alle drei Statusvarianten. In jedem Fall enthält body nun das (aus der Datei gelesene oder erzeugte) Antwortdokument, in headers sind die verschiedenen HTTP-Header gespeichert, und die Variablen statuscode und statusmsg enthalten die Statusinformationen.
Bevor der Client seine Antwort erhält, nimmt der Server noch einen Eintrag in seine Log-Datei vor:
$log.puts "#{client_ip} - - [#{logdate}] \"#{request}\" #{statuscode} #{len}"
Das verwendete Format besteht aus folgenden Komponenten:
- Client-IP-Adresse
- Username (hier -, da dieser Server keine Authentifizierung unterstützt)
- Client-Ident-Angabe[Anm.: Hier wird auch bei ausgewachsenen Webservern nur etwas angezeigt, wenn auf dem Client ein Ident-Server gemäß RFC 1413 läuft; dies kommt nur selten vor, sodass in diesem Feld fast immer – steht.] (ebenfalls -)
- Datum in eckigen Klammern
- die gesamte Client-Anfragezeile in Anführungszeichen
- der Statuscode der Antwort
- die Länge des Bodys in Byte
Dieses Format heißt Common Log Format und wird auch von professionellen Webservern wie Apache standardmäßig verwendet. Vorteil: Sie können diese Datei mithilfe beliebiger Webstatistik-Software auswerten.
Zum Schluss erhält der Client die lang ersehnte Antwort. Wichtig ist, dass Zeilen in klartextbasierter TCP-Netzwerkkommunikation wie unter Windows mit den beiden Zeichen CR (ASCII-Code 13) und LF (ASCII-Code 10) enden, während die Unix-Plattform nur LF verwendet. Deshalb wird jeweils print statt puts verwendet, und die im Hauptteil der Anwendung definierte Konstante CRLF wird angehängt.
Die gesamte Ausgabe sieht wie folgt aus; Header und Body werden dabei durch eine Leerzeile voneinander getrennt:
conn.print "#{http} #{statuscode} #{statusmsg}#{CRLF}"
headers.each { |header|
conn.print "#{header}#{CRLF}"
}
conn.print CRLF
conn.print body
Im globalen Teil der Anwendung werden zunächst einige nicht konfigurierbare Grundwerte festgelegt. Dazu gehört die Plattform, auf der der Server gerade läuft. Sie steht in der Konstanten RUBY_PLATFORM und wird durch Vergleich mit dem Muster /win/ auf "Windows" oder "Unix" normalisiert:
if RUBY_PLATFORM =~ /win/i
$os = "Windows"
else
$os = "Unix"
end
Danach werden Name und Versionsnummer des Servers gesetzt, und alle drei Angaben werden dann zu dem Server-Identifikations-String $server_tokens verbunden; dieser lautet dann zum Beispiel "EasyHTTPServer/0.01 (Unix)". Anschließend werden noch der Hash mit den MIME-Types sowie die Konstante CRLF initialisiert. Lesen Sie dazu den Quellcode für Details.
Die restlichen Serverparameter sind konfigurierbar. Beim Start können null bis vier Kommandozeilenparameter übergeben werden, die von links nach rechts wie folgt interpretiert werden:
- Serverarchitektur, threaded oder forked
- Server-TCP-Port (Standard 8000)
- Stammverzeichnis der Website, standardmäßig htdocs unterhalb des Serververzeichnisses
- Name der Indexdatei, die bei Anforderung eines Verzeichnisses automatisch geliefert wird; Standard: index.html
Kommandozeilenparameter stehen in dem Array ARGV; das Auslesen funktioniert immer gleich. Deshalb hier als Beispiel nur das Lesen der Serverarchitektur mitsamt Plattformunterschied. Wie Sie sehen, wird das Ergebnis als Symbol gespeichert:
if $os == "Unix"
if ARGV[0] && ARGV[0] == 'threaded'
$architecture = :threaded
else
$architecture = :forked
end
else
$architecture = :threaded
end
Bevor es endgültig losgeht, wird noch die Log-Datei zum Anhängen geöffnet. Es handelt sich um die Datei access.log im Serververzeichnis:
$log = File.open('access.log', 'a')
Nun wird das lauschende Server-Socket erzeugt, was sich dank der Komfortklasse TCPServer auf folgende lapidare Zeile reduziert:
server = TCPServer.new($port)
Threads werden in Ruby standardmäßig in einem Array verwaltet. Deshalb muss für die Thread-Architektur ein solches – zunächst leeres – Array erzeugt werden:
if $architecture == :threaded
threads = []
end
Nun folgt die accept-Schleife, die in Ruby üblicherweise fast genauso aufgebaut wird wie in Perl:
loop do
# Weiter, falls keine Anfrage eintrifft
next unless conn = server.accept
# Anfrage verarbeiten
...
end
Die Verarbeitung der Clientanfrage funktioniert nun je nach Architektur leicht unterschiedlich, sodass zunächst eine Fallunterscheidung benötigt wird:
if $architecture == :forked
# Prozessbasierte Verarbeitung
...
else
# Thread-basierte Verarbeitung
...
end
Beim Forking-Server wird natürlich zuerst einmal fork aufgerufen:
client = fork
Im Child-Prozess hat fork den Rückgabewert nil; hier braucht nur noch die bereits ausführlich dokumentierte Methode handle_conn aufgerufen zu werden:
if client == nil
handle_conn(conn)
else
# Parent-Prozess ...
end
Damit die beendeten Child-Prozesse nicht als Zombies im Speicher zurückbleiben, enthält der else-Teil für den Parent-Prozess eine sogenannte trap (»Falle«), die das Signal SIGCLD eines terminierten Childs abfängt und die Klassenmethode Process.wait aufruft, um den Zombie-Zustand zu beenden (Details zu Unix-Prozessen inklusive Zombies lesen Sie in Kapitel 5, »Betriebssystemgrundlagen«):
trap("SIGCLD") {
Process.wait
}
Die Threading-Variante ergänzt das Array threads zunächst um einen neuen Thread. Der Aufruf Thread.new nimmt einen Block entgegen, in dem der Code steht, den der Thread ausführen soll. Variablen, die Sie als Argumente an new übergeben, stehen innerhalb des Blocks als Thread-lokale Variablen zur Verfügung – auf diese Weise wird die Parent-Variable conn hier zur Thread-Variablen client. Mit dieser wird dann handle_conn aufgerufen. Nach dem Rücksprung wird die Clientverbindung geschlossen:
threads << Thread.new(conn) { |client|
handle_conn(client)
client.close
}
Das Listing
In Listing 10.1 sehen Sie den kompletten, noch einmal ausführlich kommentierten Quellcode des kleinen Webservers. Sie brauchen ihn natürlich nicht abzutippen, sondern finden ihn auf der Buch-Website zum Download.
#######################
# #
# EasyHTTPServer/0.01 #
# #
#######################
# Socket-Bibliothek importieren
require "socket"
# --------------------------------
# Methode handle_conn:
# Client-Anfrage verarbeiten
def handle_conn(conn)
# IP-Adresse des anfragenden Hosts
client_ip = conn.peeraddr[3]
# Client-Anfrage lesen
request = conn.gets
# evtl. links und rechts Whitespace entfernen
request.strip!
# Anfrage zerlegen
(method, uri, http) = request.split(/\s+/)
# URI auf das Server-Verzeichnis umsetzen
uri.sub!(%r|^/?|, "#{$docroot}/")
# Wenn URI ein Verzeichnis ist, Indexdatei verwenden
if File.directory?(uri)
uri.sub!(%r|/?$|, "/#{$dirindex}")
end
# Formatiertes Datum erzeugen
now = Time.new
# Logdatei -- z. B. 09/May/2007:13:44:56 +0200
parts = now.to_s.split(' ')
logdate = sprintf "%s/%s/%s:%s %s", parts[2], parts[1],
parts[5], parts[3], parts[4]
# Date-Header -- z. B. Thu, 28 Jun 2007 21:12:07 GMT
serverdate = now.strftime("%a, %b %d %Y %H:%M:%S %z")
if method != 'GET'
# Es werden NUR GET-Anfragen beantwortet
statuscode = 501
statusmsg = "Not Implemented"
body = <<END_NI_BODY
<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//Final//EN\">
<html>
<head>
<title>501 Not Implemented</title>
</head>
<body>
The request method #{method} is not supported by this server.<br>
Server: #{$server_token}<br>
#{serverdate}
</body>
</html>
END_NI_BODY
len = body.length
headers = []
headers << "Allow: GET"
headers << "Date: #{serverdate}"
headers << "Server: #{$server_token}"
headers << "Connection: close"
headers << "Content-Type: text/html"
headers << "Content-Length: #{len}"
elsif !(File.exist?(uri))
# Angeforderte Datei existiert nicht
statuscode = 404
statusmsg = "Not Found"
body = <<END_NF_BODY
<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//Final//EN\">
<html>
<head>
<title>404 Not Found</title>
</head>
<body>
The requested resource #{uri} could not be found on this server.<br>
Server: #{$server_token}<br>
#{serverdate}
</body>
</html>
END_NF_BODY
len = body.length
headers = []
headers << "Date: #{serverdate}"
headers << "Server: #{$server_token}"
headers << "Connection: close"
headers << "Content-Type: text/html"
headers << "Content-Length: #{len}"
else
# Datei existiert => lesen und zurückgeben
# Wird der MIME-Type der angeforderten Datei unterstützt?
# Standardtyp: text/plain
mime_type = "text/plain"
$mime_types.each_key { |ext|
if uri =~ /\.#{ext}$/
mime_type = $mime_types[ext]
end
}
# Dateigröße für Content-length ermitteln
len = File.size(uri)
# Angeforderte Datei komplett in body einlesen
bodyfile = File.open(uri, 'r')
body = bodyfile.read
bodyfile.close
statuscode = 200
statusmsg = "OK"
headers = []
headers << "Date: #{serverdate}"
headers << "Server: #{$server_token}"
headers << "Connection: close"
headers << "Content-Type: #{mime_type}"
headers << "Content-Length: #{len}"
end
# Ausgabe in die Logdatei
$log.puts "#{client_ip} - - [#{logdate}] \"#{request}\" #{statuscode} #{len}"
# Ausgabe der Daten an den Client
conn.print "#{http} #{statuscode} #{statusmsg}#{CRLF}"
headers.each { |header|
conn.print "#{header}#{CRLF}"
}
conn.print CRLF
conn.print body
conn.close
end
# --------------------------------
# Globale Konfigurationsvariablen; nicht änderbar
# Betriebssystem
if RUBY_PLATFORM =~ /win/i
$os = "Windows"
else
$os = "Unix"
end
# Servername
$server = "EasyHTTPServer"
# Version
$version = "0.01"
# Server Informations-String
$server_token = sprintf "%s/%s (%s)",
$server, $version, $os
# Erkannte MIME-Types
$mime_types = {'htm' => 'text/html', 'html' => 'text/html',
'css' => 'text/css', 'js' => 'text/javascript',
'txt' => 'text/plain', 'gif' => 'image/gif',
'jpg' => 'image/jpeg', 'png' => 'image/png',
'swf' => 'application/x-shockwave-flash'}
# Konstante für Zeilenende
CRLF = "\r\n"
# --------------------------------
# Konfiguration von der Kommandozeile lesen
# oder auf Standardwerte setzen
if ARGV[0] && ARGV[0] == '-h'
# Nur Hilfe abgefragt
print <<ENDHELP
#{$server_token}
Usage: $0 -h | -v | [ARCHITECTURE [PORT
[SERVER_DIRECTORY
[DIRECTORY_INDEX]]]]
-h Print this help message and exit
-v Print version information and exit
PORT Listening Port (Default: 8000)
SERVER_DIRECTORY Public Web Server Directory
(Default: ./htdocs)
DIRECTORY_INDEX Name. of Index File
(Default: index.html)
ARCHITECTURE Server Architecture: forked|threaded
(forked is only available on
Unix-like systems)
ENDHELP
exit
elsif ARGV[0] && ARGV[0] == '-v'
# Nur Version abgefragt
print <<ENDVERSION
#{servertoken}
Written by Sascha Kersken (sk@lingoworld.de)
For the Galileo Press book
'IT-Handbuch für Fachinformatiker' (2008)
http://buecher.lingoworld.de/fachinfo
This program may be used, distributed and modified
under terms of the GNU General Public License
(See file COPYING in this directory)
ENDVERSION
exit
end
# Normalfall: Server soll ausgeführt werden
# $architecture: Serverarchitektur
# 1. Kommandozeilenargument
# Standard: :threaded (Windows), :forked (Unix)
if $os == "Unix"
if ARGV[0] && ARGV[0] == 'threaded'
$architecture = :threaded
else
$architecture = :forked
end
else
# Windows unterstützt nur Thread-Server
$architecture = :threaded
end
# $port: Server-TCP-Port
# 2. Kommandozeilenargument
# Standard: 8000
if ARGV[1]
$port = ARGV[1]
else
$port = 8000
end
# $docroot: Server-Wurzelverzeichnis
# 3. Kommandozeilenargument
# Standard: Unterverzeichnis "htdocs"
# des aktuellen Verzeichnisses
if ARGV[2]
$docroot = ARGV[2]
else
$docroot = 'htdocs'
end
# $dirindex: Name der Indexdatei in jedem Verzeichnis
# 4. Kommandozeilenargument
# Standard: index.html
if ARGV[3]
$dirindex = ARGV[3]
else
$dirindex = 'index.html'
end
# --------------------------------
# Logdatei initialisieren
$log = File.open('access.log', 'a')
# TCPServer erzeugen
server = TCPServer.new($port)
puts "#{$server} running on port #{$port} ..."
puts
puts "Server Directory: #{$docroot}"
puts "Index Document: #{$dirindex}"
puts "Server Architecture: #{$architecture}"
# Thread-Array für Threaded-Server
if $architecture == :threaded
threads = []
end
# Accept-Schleife
loop do
# Weiter, falls keine Anfrage eintrifft
next unless conn = server.accept
# Anfrage eingetroffen
if $architecture == :forked
# Forking: Child-Prozess erzeugen
client = fork
if client == nil
# Im Child-Prozess Anfrage verarbeiten
handle_conn(conn)
else
# Im Parent trap für Ende eines Childs
trap("SIGCLD") {
# Reaping
Process.wait
}
end
else
# Threading: Thread hinzufügen
threads << Thread.new(conn) { |client|
# Anfrage verarbeiten
handle_conn(client)
# Client-Socket schließen
client.close
}
end
end
Listing 10.1 Der Ruby-Webserver ews.rb
Benutzerinformationen
Starten Sie den Server durch Eingabe von
> ruby ews.rb
Optional können Sie einen bis vier Parameter mit folgender Bedeutung angeben:
- Architektur: Geben Sie forked für einen Forking-Server oder threaded für eine Thread-basierte Architektur an. Unter Unix ist der Standardwert forked. Auf Windows-Systemen ist dagegen nur threaded möglich; andere Angaben werden ignoriert.
- Server-Port (Standard 8000): Hier können Sie einen anderen Port wählen, falls dieser frei ist. Wichtig: Unter Unix benötigen Sie root-Rechte, um eine Portnummer zu verwenden, die kleiner als 1024 ist – das gilt natürlich auch für den Standard-HTTP-Port 80.
- Stammverzeichnis der Website (Standard: das Verzeichnis htdocs unterhalb des Serververzeichnisses): Dieser Pfad gibt das Verzeichnis an, das die freigegebenen Dateien enthält. Wenn Sie der Angabe keinen Slash (/) voranstellen, gilt sie relativ zum Verzeichnis des Servers. Unter Windows können Sie dabei sowohl den Unix-Slash (/) als auch den plattformspezifischen Backslash (\) als Pfad-Trennzeichen einsetzen.
- Indexdokument (Standard index.html): Der Name einer Datei, die der Server auszuliefern versucht, wenn in der Anfrage ein Verzeichnis ohne Dateinamen angegeben wurde.
Der Server erzeugt in seinem Verzeichnis eine Log-Datei namens access.log. Ihr zuvor beschriebenes Format, das Common Logfile Format (CLF), wird auch von professionellen Webservern wie Apache verwendet.
Um auf einem Unix-System einen Forking-Server auf Port 8080 im Verzeichnis /home/user/mywebdocs zu starten, müssen Sie Folgendes eingeben:
$ ruby ews.rb forked 8080 /home/user/mywebdocs
Hier ein entsprechendes Beispiel für Windows mit dem Stammverzeichnis C:\Daten\mywebdocs:
> ruby ews.rb threaded 8080 C:/Daten/mywebdocs
Die Reihenfolge der vier Parameter ist verbindlich, das heißt, Sie müssen zur Änderung des zweiten bis vierten auch die vorigen explizit angeben – selbst dann, wenn Sie für diese den Standardwert beibehalten möchten.
Nachdem Sie den Server gestartet haben, können Sie einen beliebigen Browser[Anm.: Falls Sie ein stilechtes Gegenstück suchen: Für mein Buch »Praxiswissen Ruby« habe ich einen Ruby-basierten Konsolenbrowser geschrieben, den Sie im Listing-Paket unter http://buecher.lingoworld.de/ruby herunterladen können.] auf Ihrem Rechner (oder einem anderen Rechner in Ihrem LAN) öffnen und ein Dokument anfordern, das sich im freigegebenen Verzeichnis des Webservers befindet. Angenommen, der Server läuft unter seinem Standardport 8000 auf demselben Rechner wie der Browser. Wenn Sie in diesem Fall die Startseite im Stammordner des Servers aufrufen möchten, müssen Sie Folgendes in die Adressleiste des Browsers eingeben:
http://127.0.0.1:8000
Wichtig: Die Angabe http://, die bei »normalen« Internetadressen mit dem TCP-Standardport 80 weggelassen werden kann, muss bei einem anderen Port in den meisten Browsern explizit eingegeben werden.
Um den Server zu beenden, müssen Sie unter Unix die Tastenkombination  +
+  drücken, auf einem Windows-System dagegen +
drücken, auf einem Windows-System dagegen +  (auf englischen Tastaturen ist die Taste [Unterbrechung] mit
(auf englischen Tastaturen ist die Taste [Unterbrechung] mit  beschriftet).
beschriftet).
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen




