


16 Weitere Datei- und Datenformate
Es gibt keine größere Illusion als die Meinung, Sprache sei ein Mittel der Kommunikation
zwischen Menschen.
– Elias Canetti
XML ist eine hervorragende Erfindung, und so hat es sich zu einem der wichtigsten Datenaustauschformate entwickelt. Dennoch gibt es zahlreiche Anwendungsfälle, in denen es teils aus historischen, teils aus praktischen Gründen nicht die richtige Wahl ist. Deshalb werden in diesem Kapitel einige andere Formate vorgestellt.
Die Wahl des richtigen Dateiformats ist unerlässlich, um effizient mit bestimmten Anwendungen zu arbeiten und um jeweils kompatible Daten für den weiteren Workflow zu erzeugen. Deshalb werden in diesem Kapitel die wichtigsten Charakteristika verschiedener Formate für Text, formatierten Text, Grafiken, Bilder und Multimedia-Daten behandelt.
Beachten Sie, dass dieses Kapitel die Datei- und Datenformate ausschließlich aus Anwendersicht beschreibt. Sie erfahren hier also nicht, wie Sie als Programmierer bestimmte Dateiformate lesen, schreiben und interpretieren können. Es ist aber ohnehin eine eher schlechte Idee, dies im Produktiveinsatz durch eigene Programme zu tun (zur Übung ist es dagegen ideal). Zu immer mehr Formaten gibt es fertige Bibliotheken für die einzelnen Programmiersprachen.
16.1 Textdateien und Zeichensätze
Die einfachste Dateisorte sind einfache Textdateien, in denen jedes Zeichen sich selbst repräsentiert, in denen also keine binären Steuercodes vorkommen. Reine Textdateien werden trotzdem nicht nur zur Speicherung von Texten in menschlichen Sprachen verwendet. Es existieren auch viele textbasierte Formate, in denen Steuerungs-, Formatierungs- und Strukturbefehle im Klartext gespeichert werden, sodass sie von Menschen gelesen und geändert werden können. Wichtige Beispiele sind XML, HTML, die Satzsprache LaTeX, die Druckseitenbeschreibungssprache PostScript und nicht zuletzt die zahlreichen proprietären Konfigurationsdateien für Betriebssysteme und Anwendungen. Dies macht einen großen Teil der Bedeutung von Textdateien aus.
Sie haben in Kapitel 7, »Linux«, erfahren, wie Textdateien mithilfe verschiedener System-Tools und Editoren verarbeitet werden können. In Kapitel 9, »Grundlagen der Programmierung«, wurde die programmierte Verarbeitung von Textdateien bereits kurz behandelt. Aber bisher wurde noch nicht genau darauf eingegangen, was wirklich in einer Textdatei gespeichert wird.
Formal betrachtet handelt es sich bei einer Textdatei um eine Abfolge von Speicherblöcken, in denen verschiedene Bitmuster für die unterschiedlichen Zeichen stehen. Wie breit der einzelne Speicherblock ist, hängt dabei vom verwendeten Zeichensatz ab. Beispielsweise wird der verbreitete ASCII-Zeichensatz mit seinen Erweiterungen in der Regel in Dateien und Datenstrukturen mit 8 Bit pro Zeichen gespeichert; für Unicode stehen Varianten mit 16 oder 32 Bit oder sogar mit variabler Bit-Breite zur Verfügung.
Der ursprüngliche ASCII-Zeichensatz (American Standard Code for Information Interchange) wurde in den 60er-Jahren des 20. Jahrhunderts entwickelt. Er entstand durch das einfache Durchnummerieren sämtlicher Zeichen und Funktionen, die eine US-amerikanische Schreibmaschine erzeugen kann. Es gibt also nicht nur ASCII-Codierungen für Buchstaben, Ziffern und einige Sonderzeichen, sondern auch für typische Schreibmaschinenfunktionen wie den Zeilenvorschub (Line Feed), den Wagenrücklauf (Carriage Return) oder sogar die Glocke (Bell), deren Ton das baldige Zeilenende anzeigt. Diese Steuerzeichen werden von den verschiedenen Terminals, Shells oder Texteditoren unterschiedlich genutzt.
Der ASCII-Code selbst ist nur 7 Bit breit, enthält also 128 Zeichen. Da er in der Regel in 8 Bit großen Einheiten gespeichert wird, bleibt das erste Bit echter ASCII-Zeichen 0. Der verfügbare Platz von weiteren 128 Zeichen, die bei einer Speicherung in ganzen Bytes übrig bleibt, wurde zuerst von IBM als »erweiterter ASCII-Code« genutzt. In der Folge wurden die verschiedensten Zeichensätze entwickelt, die die ersten 128 Zeichen mit ASCII gemeinsam haben und die restlichen 128 für eigene Erweiterungen nutzen. Eine gängige standardisierte Fassung ist der ANSI-Zeichensatz, der beispielsweise in den Windows-Versionen der meisten lateinisch schreibenden europäischen Sprachen zum Einsatz kommt. Er enthält die wichtigsten west- und mitteleuropäischen Sonderzeichen wie etwa deutsche Umlaute oder französische Buchstaben mit Akzent. ANSI steht für »American National Standards Institute«, es handelt sich um das US-Pendant zum deutschen DIN oder zur internationalen ISO.
16.1.1 Das Problem des Zeilenumbruchs
Das einzige Sonderzeichen, das in jeder Textdatei geduldet wird und eine universelle
Bedeutung besitzt, ist der Zeilenumbruch. Er entsteht bei der manuellen Eingabe durch
das Drücken der Eingabetaste ( oder
oder  ). Ärgerlicherweise wird er selbst in ASCII-Textdateien für die verschiedenen Plattformen
durch unterschiedliche Zeichen dargestellt:
). Ärgerlicherweise wird er selbst in ASCII-Textdateien für die verschiedenen Plattformen
durch unterschiedliche Zeichen dargestellt:
- Unix-Varianten wie Linux, FreeBSD und Solaris verwenden ein einzelnes Line Feed (LF, ASCII-Code 10).
- Das klassische Mac OS bis Version 9 benutzte ein einzelnes Carriage Return (CR, ASCII-Code 13). Allerdings verwendet Mac OS X standardmäßig das LF, da es sich um ein Unix handelt; einige Texteditoren bieten allerdings noch optionale Unterstützung für das veraltete Format.
- Windows und MS-DOS verwenden eine Kombination aus beiden Zeichen: ein CR, gefolgt von einem LF (in der Regel als CRLF bezeichnet). Diese Zeichenfolge wird übrigens auch in der Netzwerkkommunikation von vielen klartextbasierten Protokollen eingesetzt (siehe Kapitel 4, »Netzwerkgrundlagen«).
Die Verwendung unterschiedlicher Zeichen für Zeilenumbrüche führt immer wieder zu Problemen bei der Konvertierung oder beim Öffnen von Textdateien, die unter einem anderen Betriebssystem gespeichert wurden. Beispielsweise sehen Sie beim Öffnen einer Windows-Textdatei unter dem klassischen Mac OS ein kleines Quadrat (als nicht darstellbares Sonderzeichen) am Anfang jeder neuen Zeile, während Sie unter Windows nur kleine Quadrate anstelle der Zeilenumbrüche sehen, wenn Sie eine Mac- oder Unix-Textdatei öffnen.
Dieses Problem lässt sich durch intelligente Editoren in den Griff bekommen, beispielsweise erkennt TextPad für Windows (Demoversion unter www.textpad.com) die Fremdformate automatisch und stellt die Dateien intern um. Auch der in Mac OS X eingebaute GUI-Texteditor TextEdit kann sich auf Windows-Zeilenendungen einstellen.
Unter Linux sind spezielle Konverterprogramme für die Konsole verfügbar: dos2unix Dateiname konvertiert die angegebene Datei mit Windows-Zeilenumbrüchen auf Unix-Umbrüche; unix2dos Dateiname erledigt die umgekehrte Aufgabe. Für Mac- und Windows-Benutzer ist zusätzlich das Programm ASCon-A nützlich, weil es nicht nur die Zeilenendungen in beide Richtungen konvertiert, sondern auch gleich die Umlaute und andere diakritische Zeichen dem jeweiligen Zeichensatz anpasst. Die Software kann für beide Plattformen kostenlos unter der URL http://www.medienwerkstatt-online.de/products/ascona/ascona.html heruntergeladen werden.
Wenn Sie innerhalb von Anwendungsprogrammen mit Text arbeiten, haben Sie übrigens kein Problem mit Zeilenumbrüchen: Textverarbeitungsprogramme wie Microsoft Word oder OpenOffice.org speichern auch die enthaltenen Texte in ihrem eigenen Format, in dem die Zeilenumbrüche speziell geschützt werden. Dabei spielt es auch keine Rolle, ob das jeweilige Programm ein binäres oder ein XML-basiertes Dateiformat verwendet.
Auch Programmiersprachen beschäftigen sich mit dem Problem der unterschiedlichen Zeilenumbrüche. Wenn Sie in den Sprachen, die in diesem Buch näher behandelt werden, also C, Java, Perl und Ruby, die Escape-Sequenz \n ausgeben, gilt sie als logischer Zeilenumbruch, es wird also hinter den Kulissen das jeweils passende Zeichen oder die korrekte Zeichenfolge erzeugt. Dennoch steht \n eigentlich für das LF, also das Zeichen mit dem ASCII-Code 10, während \r das CR (ASCII-Code 13) repräsentiert.
Die Programmiersprache Perl geht noch einen Schritt weiter: Sie definiert eine spezielle Variable namens $/, den Input Record Separator. Diese enthält das jeweils aktuelle Zeichen oder die Zeichenfolge, die als Zeilentrenner für den Operator <> gilt. Wenn Sie eine Textdatei erhalten, die von einer anderen Plattform stammt, können Sie den Wert der Variablen einfach überschreiben: Entweder sichern Sie ihren Wert in einer zweiten Variablen, oder Sie erstellen mithilfe des Schlüsselworts local eine gleichnamige lokale Variable, die die »offizielle« Variable innerhalb des aktuellen Gültigkeitsbereichs ausblendet. Wenn Sie $/ einen neuen Wert zuweisen, müssen Sie allerdings darauf achten, dass Sie die Zeichen CR und LF nicht einfach durch \r beziehungsweise \n (den logischen Umbruch) darstellen dürfen, sondern über ihre ASCII-Codes ansprechen müssen. Dies geschieht in Perl (genau wie in den meisten anderen in diesem Buch behandelten Sprachen) durch einen Backslash mit dem nachstehenden oktalen Zeichencode: \012 steht für LF, \015 stellt CR dar.
Das folgende kurze Beispiel dient dem zeilenweisen Einlesen einer klassischen Mac-Textdatei auf einer beliebigen Plattform:
local $/ = "\015";
open (MAC, "<mactextfile.txt") || die "Geht nicht!\n";
while ($line = <MAC>) {
chomp $line;
push @text, $line;
}
close MAC;
Sie können in $/ übrigens auch einfach einen leeren String speichern, um eine Textdatei vollständig auf einmal zu »saugen«:
my $umbr = $/; # alten Wert schützen
$/ = ""; # "Saug"-Modus
open (FILE, "<test.txt") || die "Geht nicht!\n";
my $text = <FILE>; # alles auf einmal lesen
close FILE;
$/ = $umbr; # $/ wiederherstellen
16.1.2 Zeichensätze
In diesem Abschnitt werden die Grundlagen einiger Zeichensätze behandelt – vom einfachen ASCII- bis zum komplexen Unicode-Zeichensatz.
ASCII
Der ASCII-Zeichensatz (gesprochen »äskie«) ist der wichtigste und grundlegendste aller Computerzeichensätze. Viele klassische Konsolen- oder Netzwerkanwendungen verarbeiten keine Zeichen über reines ASCII hinaus; Bezeichner in traditionellen Programmiersprachen wie C dürfen ebenfalls nur aus ASCII-Zeichen bestehen.
Der ASCII-Zeichensatz geht auf einen ANSI-Vorschlag von 1963 zurück und wurde im Wesentlichen bei IBM ausgearbeitet, vor allem von Robert Bemer (www.bobbemer.com), der unter anderem auch einen entscheidenden Beitrag zur Entwicklung der Programmiersprache COBOL geleistet hat. 1968 wurde der ASCII-Code standardisiert.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0 |
NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
HAT |
LF |
VT |
FF |
CR |
SO |
SI |
| 1 |
DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
| 2 |
SP |
! |
» |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
- |
. |
/ |
| 3 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
| 4 |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
| 5 |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
| 6 |
` |
a |
b |
c |
D |
e |
F |
g |
h |
I |
j |
k |
l |
m |
n |
o |
| 7 |
p |
q |
r |
s |
T |
u |
V |
w |
x |
Y |
z |
{ |
| |
} |
~ |
DEL |
Tabelle 16.1 zeigt zunächst den gesamten ASCII-Zeichensatz. Die Nummerierung ist hexadezimal; in der jeweiligen Zeile ist die hohe (Sechzehner-)Stelle eines Codes zu sehen, in der Spalte die niedrige (Einer-)Stelle. Das Zeichen 'A' besitzt also zum Beispiel den Code 41 (dezimal 65).
Die Zeichen 0 bis 31 (hexadezimal 00 bis 1F) sind Steuerzeichen, die mit ihren traditionellen Kurznamen verzeichnet wurden. Beispielsweise ist 0A (dezimal 10) das bereits erwähnte Line Feed, 0D (13) ist das Carriage Return, und 00 (das Zeichen '\0') wird vor allem als Abschlussmarkierung für C-Strings verwendet.
Wie Sie sehen, haben die Entwickler sich bemüht, bestimmte Zeichenklassen an charakteristischen Stellen unterzubringen. Außerdem kommen die Ziffern und die beiden Sätze von Buchstaben in ihrer natürlichen Reihenfolge vor: Die Ziffernzeichen '0' bis '9' befinden sich auf den Positionen 48 bis 57 (hexadezimal 30 bis 39), die Großbuchstaben 'A' bis 'Z' auf 65 bis 90 (hexadezimal 41 bis 5A) und die Kleinbuchstaben 'a' bis 'z' auf 97 bis 122 (hexadezimal 61 bis 7A).
ASCII-Erweiterungen
In den 80er-Jahren war es so gut wie selbstverständlich, auf einem Home- oder Personal Computer keine deutschen Umlaute und sonstigen Sonderzeichen zur Verfügung zu haben: ASCII ist nur für englische Texte geeignet, alle anderen Sprachen mussten ihre Sonderzeichen umschreiben (ae für ä und so weiter) oder spezielle diakritische Kennzeichnungen einfach weglassen (zum Beispiel im Französischen ohne Akzente).
Da Computer jedoch ab einem bestimmten Zeitpunkt im großen Stil Einzug in Firmen und Behörden hielten und die Schreibmaschine als Korrespondenzwerkzeug zunehmend ablösten, war dieser Zustand irgendwann nicht mehr erträglich: Deutscher Text ohne Umlaute und ähnliche falsche Schreibweisen anderer Sprachen sind viel schlechter lesbar als richtig geschriebener Text. Da niemand seinen Kunden auf Dauer solche Notlösungen in Geschäftsbriefen zumuten wollte, mussten die fehlenden Zeichen integriert werden.
Erfreulicherweise verwenden alle heutigen Computer Bytes, die 8 Bit groß sind (das war in der Frühzeit der Computergeschichte nicht immer selbstverständlich; der eingangs genannte ASCII-Entwickler Bob Bemer war übrigens einer derjenigen, die sich dafür eingesetzt hatten). Aus diesem Grund war es weitverbreitete Praxis, jedes einzelne, eigentlich nur 7 Bit breite, ASCII-Zeichen in einem 8 Bit großen Block zu speichern. In einem Byte war also Platz für weitere 128 Zeichen, die man irgendwie ausnutzen konnte.
IBM war das erste Unternehmen, das einen solchen Zeichensatz einführte. Der sogenannte erweiterte ASCII-Zeichensatz enthielt die wichtigsten diakritischen Zeichen west- und mitteleuropäischer Sprachen sowie eine Reihe von geraden und gewinkelten Linien und anderen Grafikzeichen, um konsolenbasierte Benutzeroberflächen realisieren zu können. Dieser Zeichensatz wurde beispielsweise in leicht abgewandelter Form von MS-DOS verwendet.
Andere Hersteller erfanden ihre eigenen erweiterten Zeichensätze. Zum Beispiel entschied sich Apple für eine Eigenentwicklung, in der die 128 Zeichen über ASCII anders belegt wurden. Deswegen können Sie bis heute eine deutsche Mac-Textdatei nur mit Fehlern unter Windows lesen und umgekehrt.
Apropos Windows: Microsoft entschloss sich, für Windows nicht den erweiterten ASCII-Zeichensatz von IBM oder die MS-DOS-Variante davon zu verwenden, sondern den inzwischen standardisierten ANSI-Zeichensatz: Da Windows eine grafische Benutzeroberfläche war, wurden die verschiedenen Grafikzeichen nicht mehr gebraucht, um Fenster oder Menüs zu zeichnen. Den frei gewordenen Platz benutzt der ANSI-Zeichensatz für mehr internationale diakritische Zeichen. Das ist der Grund dafür, warum ein Konsolenprogramm, das Sie in einem Windows-Editor schreiben, statt deutscher Umlaute seltsame Sonderzeichen anzeigt. Die von DOS übernommene Windows-Konsole verwendet nach wie vor den alten MS-DOS-Zeichensatz!
Als Computer sich in immer mehr Ländern zu verbreiten begannen, fiel unangenehm auf, dass die ANSI-Zeichen noch nicht einmal für alle lateinisch geschriebenen Sprachen geeignet waren. Beispielsweise benutzen Sprachen wie Tschechisch oder Türkisch einige besondere Zeichen, um spezielle Laute zu kennzeichnen.
Die Betriebssystemhersteller begegneten diesem Problem, indem sie für jedes Land, in dem das entsprechende System verkauft wurde, einen angepassten Zeichensatz oder eine sogenannte Codepage erstellten, um die Besonderheiten der jeweiligen Sprache darstellen zu können. Neben den verschiedenen Varianten der lateinischen Schrift wurden so auch andere Buchstabenalphabete realisiert, beispielsweise Kyrillisch, Griechisch, Hebräisch oder Arabisch. Für die beiden Letztgenannten musste natürlich zusätzlich das Problem gelöst werden, dass sie von rechts nach links geschrieben werden. Für sich allein genommen ist das noch nicht einmal schwierig, vielmehr bereitet die Mischung mit englischem Text (also der umgekehrten Schreibrichtung), der für die Programmierung und Ähnliches eingesetzt wird, Kopfzerbrechen.
Mit den betriebssystemabhängigen Lösungen waren einige Jahre lang fast alle recht zufrieden. Anwendungsprogramme, die für Mac OS und Windows verfügbar waren, verwendeten ohnehin ihre eigenen inneren Mechanismen für den Erhalt des korrekten Zeichensatzes. Zum Problem wurden diese Insellösungen erst, als sich das Internet immer schneller ausbreitete. Deshalb wurde für plattformübergreifende Kompatibilität ein international gültiger Standard für Zeichensätze geschaffen: ISO 8859. Die wichtigsten ISO-8859-Zeichensätze werden in Tabelle 16.2 gezeigt.
Beachten Sie, dass es noch weitaus mehr angepasste Zeichensätze gibt als die hier dargestellten. Nicht »totzukriegen« sind beispielsweise die traditionellen Mac-Zeichensätze.
Unicode
Um das ganze Problem der Schriften ein für alle Mal in den Griff zu bekommen, wurde schließlich das Unicode-System erfunden. Hier wurde von vornherein mehr Speicherplatz für das einzelne Zeichen eingeplant, um mehr unterschiedliche Zeichen darstellen zu können. Die ursprünglichen Unicode-Versionen verwendeten 16 Bit pro Zeichen, um bis zu 65.536 Zeichen darstellen zu können; seit Unicode 3.1 gibt es auch spezielle Varianten mit 3 oder 4 Byte, um noch erheblich mehr Zeichen in Unicode unterzubringen.
Das größte Problem, das Unicode mit sich bringt, ist, dass das System bisher noch nicht von allen Betriebssystemen, Programmiersprachen, APIs und Anwendungen verwendet wird. Um dieses Problem zu verringern, wurde Unicode so konstruiert, dass die untersten 256 Zeichen genau dem Zeichensatz ISO-Latin-1 entsprechen.
Die spezielle Unicode-Codierung UTF-8 kann ASCII-Zeichen sogar einfach in einem Byte darstellen und verwendet spezielle Codes zur Darstellung höherer Zeichen. Auf diese Weise ist UTF-8 mit ASCII abwärtskompatibel. Auf den meisten Linux-Systemen ist UTF-8 inzwischen die Standardcodierung, und auch auf anderen Systemen verbreitet sie sich glücklicherweise immer weiter.
Die ursprüngliche Teilmenge von Unicode, die 16 Bit breite Zeichen verwendet, wird als Basic Multilingual Pane (BMP) bezeichnet. Es handelt sich um die wichtigsten Zeichen lebender Sprachen, mathematische Sonderzeichen sowie grundlegende Piktogramme, Schmuckelemente und andere Symbole (Dingbats). In Tabelle 16.3 sehen Sie eine Übersicht über einige wichtige Codebereiche des BMP-Bereichs von Unicode. Die Codes von Unicode-Zeichen werden üblicherweise im Hexadezimalcode mit vorangestelltem U+ geschrieben; beim BMP-Bereich werden vier Hexadezimalstellen verwendet, ansonsten je nach Bedarf mehr.
Eine Übersicht über alle Zeichenbereiche von Unicode erhalten Sie auf der Website des Unicode-Konsortiums: http://www.unicode.org. Dort finden Sie außerdem PDF-Dokumente zum Download, in denen jedes einzelne Zeichen zu sehen ist.
Unicode wird inzwischen von den meisten Betriebssystemen unterstützt. Den Anfang machte Windows NT 4.0, das 1996 auf den Markt kam und den damaligen 16-Bit-Unicode als festgelegtes Textformat verwendete (intern ist dies bei allen NT-Nachfolgern noch immer der Fall). Inzwischen sind auch neuere Unix- und Linux-Versionen mit Unicode-Unterstützung ausgestattet.
Bei den Programmiersprachen machte Java den Anfang: Die Sprache verwendete von Anfang an Unicode in verschiedenen Codierungen. Der Java-Datentyp char (einzelnes Zeichen) besitzt eine Breite von 16 Bit und ist somit groß genug, um ein BMP-Unicode-Zeichen aufzunehmen. In C wurde dazu nachträglich der 16 Bit breite Datentyp wchar_t eingeführt. Perl unterstützt Unicode erst seit Version 5.8.
Auch immer mehr Anwendungsprogramme unterstützen Unicode. Wichtig ist dies besonders für Layout- und Textverarbeitungsprogramme. Die Unicode-Verwendung in Anwendungsprogrammen geht oft einher mit der Unterstützung des neuen OpenType-Schriftformats.
Schrift- und Tastatureinstellungen
Die in den vorigen Abschnitten besprochene theoretische Unterstützung verschiedener lokaler Zeichensätze oder des Unicode-Systems nutzt in der Praxis natürlich nur dann etwas, wenn auf dem verwendeten Rechner entsprechende Schriften installiert sind und die Tastaturbelegung so geändert werden kann, dass die speziellen Zeichen anderer Schriftsysteme über die Tastatur eingegeben werden können.
Die reine Anzeige fremder Schriften ist besonders für Webseiten wichtig. Folgerichtig bieten Webbrowser wie der Microsoft Internet Explorer ein relativ einfaches System zum Umstellen der Zeichencodierung und zum Nachladen verschiedenster Zeichensätze an. Diese Darstellung anderer Zeichensätze ermöglicht aber noch lange nicht deren Eingabe!
Die meisten aktuellen Betriebssysteme bieten eine einfache Möglichkeit, das Tastaturlayout auf viele verschiedene Schriften umzustellen und entsprechende Zeichensätze zu installieren. Unter Windows seit XP nehmen Sie die Einstellung der auswählbaren Tastaturlayouts beispielsweise folgendermaßen vor:
- Wählen Sie Start · Systemsteuerung · Regions- und Spracheinstellungen.
- Wechseln Sie auf die Registerkarte Sprachen. Über den Button Details nehmen Sie die eigentlichen Einstellungen für Tastatur-Eingabeschemata vor.
- Mit Hinzufügen können Sie zahlreiche Sprachen und Eingabeschemata installieren.
- Nachdem Sie die Auswahl bestätigt haben, steht Ihnen in der Taskleiste ein Umschalter zur Verfügung, mit dessen Hilfe Sie die verschiedenen Sprachen und Gebietsschemata nach den Länderkürzeln aussuchen können. Moderne Anwendungen wie Word oder InDesign suchen beim Umschalten in der Regel auch gleich eine Schrift aus, die die benötigten Zeichen darstellen kann. Auch das Umschalten der Schreibrichtung für verschiedene Sprachen funktioniert normalerweise problemlos.
Unter Mac OS X steht Ihnen ein sehr ähnliches Verfahren zur Verfügung; hier finden Sie die erforderlichen Einstellungen unter Systemeinstellungen · Landeseinstellungen.
Nun müssen Sie nur noch herausfinden, mit welcher Taste welches Zeichen einer Sprache produziert wird. Bei lateinisch geschriebenen Sprachen kann die Belegung geringfügig (Z und Y sowie einige Satzzeichen vertauscht bei englischer Tastaturbelegung), aber auch erheblich von der deutschen abweichen (zum Beispiel AZERTY statt QWERTZ bei französischem Tastaturlayout). Für nichtlateinische Schriften gelten dagegen völlig andere Regeln: Fremde Buchstabenschriften (Griechisch, Arabisch und so weiter) sind natürlich »irgendwie« auf die Tasten der Tastatur verteilt.
Viel komplexer wird es dagegen bei den ostasiatischen Silbenschriften: In der Regel werden chinesische oder japanische Zeichen anhand einer Lateinumschrift eingegeben, Sie können sich das passende Zeichen daraufhin aus einer Liste aussuchen. Bestimmte Zeichen erkennt ein solches Eingabesystem sogar bereits aus dem Kontext richtig.
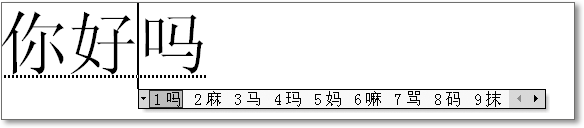
Abbildung 16.1 Eingabe chinesischer Zeichen unter Windows XP
Ein Beispiel: Chinesisch schreiben auf lateinischen Tastaturen
In Abbildung 16.1 sehen Sie ein Beispiel für die Eingabe chinesischer Schriftzeichen unter Windows XP (in neueren Versionen funktioniert es genauso). Die chinesische Sprache kennt viele Tausend Silbenzeichen, aber nur verhältnismäßig wenige unterschiedliche Sprechsilben. Erschwerend kommt hinzu, dass es vier verschieden gesprochene, bedeutungsunterscheidende Betonungen gibt, die bei den üblichen Eingabesystemen nicht mit eingegeben werden.
In dem Beispiel sind die vereinfachten chinesischen Schriftzeichen zu sehen, die in der Volksrepublik aufgrund einer Schriftreform eingeführt wurden (Taiwan verwendet dagegen bis heute die noch komplexeren traditionellen Schriftzeichen). Die Lateinumschrift wurde ebenfalls vereinheitlicht; die chinesische Regierung hat vor Jahren ein verbindliches System namens Hanyu Pinyin eingeführt. Dies ersetzt die zum Teil abenteuerlichen Versuche portugiesischer Jesuitenpater und englischer Seefahrer; statt »Peking« heißt es beispielsweise korrekt »Beijing«.
Um die in Abbildung 16.1 gezeigeten Zeichen zu produzieren, müssen Sie die folgenden Silben eingeben: NI HAO MA (das Leerzeichen schließt jeweils die Eingabe einer Silbe ab). Da dieser Satz »Wie geht es dir?« bedeutet und sehr häufig vorkommt, hat das System auf Anhieb die korrekten Zeichen ausgewählt. Wird ein Zeichen dagegen falsch erkannt, können Sie einmal auf die linke Pfeiltaste drücken, um die im Bild gezeigte Auswahlleiste zu erhalten. Bei den meisten Silben besteht sie aus mehreren Abschnitten, die Sie durch die Pfeil-Buttons rechts erreichen können. Unter Mac OS X ist der Mechanismus sehr ähnlich.
16.1.3 Textbasierte Dateiformate
Viele wichtige Dateiformate, die in reinem Text geschrieben werden, lernen Sie in anderen Kapiteln dieses Buches kennen: Im vorigen Kapitel wurde beispielsweise bereits ausführlich die allgemeine Auszeichnungssprache XML behandelt; in Kapitel 17, »Webseitenerstellung mit (X)HTML und CSS«, kommt die Webseitenbeschreibungssprache HTML an die Reihe. Auch die verschiedenen Programmiersprachen und diverse Arten von Konfigurationsdateien lassen sich letzten Endes als Textdateiformate bezeichnen.
An dieser Stelle werden deshalb nur zwei Beispiele für textbasierte Formate angeführt: die Satzsprache LaTeX und die Druckseitenbeschreibungssprache PostScript. Ein drittes Beispiel ist das von Microsoft definierte Rich Text Format (RTF), das als rudimentäres Austauschformat für formatierten Text zwischen verschiedenen Anwendungen eingesetzt werden kann.
LaTeX
Die WYSIWYG-Dokumentenverarbeitung im Bereich des Textsatzes war nicht zu allen Zeiten selbstverständlich. Fotosatzmaschinen und frühe computerbasierte Satz- und Layoutsysteme verwendeten angepasste Spezialsprachen, um das Layout und den Textinhalt von Druckdokumenten zu beschreiben.
Eine der bekanntesten Textsatzsprachen wurde in den 80er-Jahren von Donald E. Knuth[Anm.: Der Name wird »K-nooth« (englisch) ausgesprochen.] entworfen. Hauptberuflich war er ein sehr bekannter Informatikprofessor – sein Hauptwerk ist das bisher dreibändige (der vierte Band erscheint zurzeit in kleineren Teilen), auf sieben Bände ausgelegte »The Art of Computer Programming«. 1982 gab er das Manuskript des ersten Bandes beim Verlag ab und war enttäuscht über den schlechten Satz, der dabei herauskam. Dies veranlasste ihn, mit der Arbeit an seinem eigenen Textsatzsystem zu beginnen, genannt TeX (gesprochen »Tech« – mit »ch« wie in »Blech«).
Zusammen mit TeX entwickelte Knuth ein weiteres Programm namens METAFONT zur Definition vektorbasierter elektronischer Schriften. Die wichtigsten Ideen von METAFONT führten später zur Entwicklung der Adobe-PostScript-Schriften. In TeX gesetzte Dokumente bestechen durch ihre hohe Qualität, die nicht einmal von professionellen Layoutprogrammen wie InDesign oder QuarkXPress erreicht wird, sondern höchstens von der Kunst des manuellen Bleisatzes. Außerdem ist kein anderes Programm in der Lage, in ähnlicher Perfektion mathematische Formeln zu setzen.
Andererseits ist TeX schwer zu benutzen; es müssen Unmengen von Konfigurationsanweisungen geschrieben werden, bevor das eigentliche Dokument gesetzt werden kann. Aus diesem Grund fügten andere Entwickler eine Makrosammlung namens LaTeX hinzu, die viele der Konfigurationsarbeiten durch Zusammenfassung erleichtert, sodass Autoren sich mehr auf den eigentlichen Text konzentrieren können als auf die Satzsprache.
Eine richtige Einführung in LaTeX würde an dieser Stelle erheblich zu weit führen; deshalb soll ein kurzes Beispieldokument genügen:
\begin{document}
\textbf{\Large LaTeX}
LaTeX ist eine Makrosammlung, die auf der Satzsprache TeX von
\emph{D.E.Knuth}\footnote{Der Autor der bekannten Art Of Computer Programming.} basiert.
LaTeX bietet eine Reihe von Vorteilen:
\begin{itemize}
\item
Gestochen scharfer Textsatz.
\item
Mathematische Formeln in Perfektion.
\item
Listen, Tabellen und Abbildungen ohne Probleme.
\end{itemize}
\end{document}
Wie Sie sehen, werden Formatierungsbefehle mit \befehl eingeleitet; die Inhalte, die ein Befehl umschließt, stehen in geschweiften Klammern. Der hier gezeigte Beispielcode würde etwa folgende Ausgabe erzeugen:
LaTeX
LaTeX ist eine Makrosammlung, die auf der Satzsprache TeX von D. E. Knuth basiert. LaTeX bietet eine Reihe von Vorteilen:
- gestochen scharfer Textsatz
- mathematische Formeln in Perfektion
- Listen, Tabellen und Abbildungen ohne Probleme
Ein solches Dokument erhält die Dateiendung .tex und wird vom eigentlichen LaTeX-Programm in eine DVI-Datei (Device-Independent Print File) umgewandelt, die über das Programm dvips in PostScript konvertiert werden kann. Die freie PostScript-Implementierung GhostScript ermöglicht schließlich die Vorschau und Ausgabe des Dokuments. Auf einem Unix-System gäben Sie dazu beispielsweise folgende Befehle ein:
$ latex latexinfo.tex
$ dvips latexinfo.dvi
$ gs latexinfo.ps
Die meisten modernen LaTeX-Distributionen bieten sogar die Möglichkeit, direkt in einem Schritt aus LaTeX-Dokumenten das modernere PDF-Format zu generieren. Das funktioniert so:
$ pdflatex latexinfo.tex
PostScript
Die von Adobe eingeführte Druckseitenbeschreibungssprache PostScript wurde für die millimetergenaue Platzierung von Text, Vektorgrafik und Bildern erfunden, die für die Ausgabe auf Laserdruckern und Belichtern erforderlich ist. Die Sprache verfügt über eingebaute Funktionen zur Formatierung von Text und zur Anfertigung von Vektorzeichnungen; Pixelbilder werden dagegen mit der PostScript-Datei verknüpft.
Es handelt sich zwar um ein textbasiertes Format, aber in aller Regel gibt es niemand von Hand ein. PostScript-Dokumente werden fast immer von entsprechenden Druckertreibern erzeugt. Eine PPD (PostScript Printer Description, Druckerbeschreibungsdatei) wird dabei verwendet, um die speziellen Fähigkeiten des verwendeten Druckers wie Auflösung, Farbfähigkeit und eingebaute Schriften zu bestimmen. Aus diesen Gründen würde es auch keinen Sinn ergeben, hier PostScript-Code darzustellen.
Wenn Sie ein PostScript-Dokument als Datei speichern möchten, müssen Sie Ihren Druckertreiber anweisen, die Druckdaten an die Datei statt an den Drucker selbst zu senden.
Eine spezielle Variante von PostScript ist das EPS-Format (Encapsulated PostScript). Es wird eher zu den Bilddateiformaten gerechnet, da es von den meisten Grafik- und Bildbearbeitungsprogrammen exportiert und geöffnet werden kann. EPS-Dateien sind die bevorzugte Methode, um Vektorgrafiken oder gemischte Pixel-Vektor-Grafiken in Layoutdokumente zu importieren. Gegenüber dem klassischen PostScript-Format weist EPS die folgenden Besonderheiten auf:
- Die Konturen von Schriftarten können ähnlich wie bei PDF mit in das Dokument verpackt werden.
- Pixelbilder werden nicht verknüpft, sondern ihr Datenbestand wird grundsätzlich in das EPS eingebettet.
- EPS-Dokumente sind auf eine einzige Seite beschränkt, während PostScript beliebig viele Seiten einnehmen kann.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



