


7 Linux
Really, I’m not out to destroy Microsoft.
That will just be a completely unintentional side effect.
– Linus Torvalds[Anm.: Wirklich, ich habe nicht vor, Microsoft zu zerstören. Dies wird nur ein vollkommen
unbeabsichtigter Nebeneffekt sein.]
Nachdem Sie im vorigen Kapitel das Wichtigste über Windows erfahren haben, geht es hier um eine andere gängige Systemplattform: Linux, inzwischen das am weitesten verbreitete System der Unix-Familie. Viele der Informationen in diesem Kapitel gelten auch für andere Unix-Varianten. Apples Betriebssystem Mac OS X, dessen Unterbau eine BSD-Unix-Version namens Darwin ist, wird im nächsten Kapitel vorgestellt.
Das Betriebssystem Linux wird, wie bereits in Kapitel 5, »Betriebssystemgrundlagen«, erwähnt, in verschiedenen Distributionen angeboten. Die wichtigsten sind:
- openSUSE, früher SUSE Linux genannt, wurde von der Nürnberger Firma SUSE AG entwickelt, die inzwischen zu Novell gehört. Novell wiederum wurde vor einigen Jahren von Attachmate aufgekauft; die Unterstützung für openSUSE wurde seitdem vermindert, aber nicht eingstellt. Die Distribution wurde früher in zwei verschiedenen Versionen angeboten: der Personal Edition für Privatanwender, die vorzugsweise mit Desktopanwendungen ausgestattet war, und der Professional Edition für Entwickler, Systemadministratoren oder Unternehmen, die zahlreiche Netzwerkanwendungen, Server, Entwicklungswerkzeuge und andere professionelle Programme enthielt. Inzwischen wird die Distribution als Community-Projekt unter dem Namen openSUSE weitergepflegt. Auch die von SUSE bereitgestellten Installations- und Verwaltungsprogramme wurden dafür unter der GPL freigegeben. Zusätzlich gibt es kommerzielle Produkte von Novell, etwa den SUSE Linux Enterprise Server.
- Red Hat Linux stammt von dem gleichnamigen amerikanischen Unternehmen und ist die beliebteste Distribution in den USA. Die Entwicklung verlief schon vor einigen Jahren wie bei openSUSE: Ursprünglich wurden eine Personal Edition und eine Professional Edition angeboten. Aus der stark erweiterten Personal-Variante ging das freie Community-Projekt Fedora Linux (früher Fedora Core Linux) hervor, während Unternehmenslösungen weiterhin unter dem Namen Red Hat verkauft werden.
- Debian GNU/Linux ist eine kleinere Distribution mit dem besonderen Vorteil, dass alle Bestandteile voll und ganz aus freier Software unter der GPL bestehen, auch das Installationsprogramm. Dafür ist die Installation komplizierter als bei den anderen Distributionen, für Linux-Einsteiger ist diese Distribution daher nicht zu empfehlen. Fortgeschrittene Anwender können die Distribution dagegen am stärksten an eigene Bedürfnisse anpassen. Es gibt allerdings besonders einsteigerfreundliche Distributionen wie Ubuntu Linux, die wiederum auf Debian basieren. Auch das direkt von CD bootende Live-System Knoppix besitzt einen Debian-Unterbau.
- Mandriva Linux ist aus dem Zusammenschluss des französischen Distributors Mandrake mit der brasilianischen Firma Conectiva entstanden und überzeugt ähnlich wie SUSE durch einen besonders großen Lieferumfang und ein gut durchdachtes Installationsprogramm.
Neben diesen häufigsten Distributionen werden unzählige weitere angeboten, jede von ihnen besitzt ihre besonderen Eigenschaften, Vor- und Nachteile. Die Unterschiede treten nicht so sehr beim normalen Arbeiten mit dem System zutage, sondern nur bei der Installation neuer Programme und bei Konfigurationsarbeiten.
Die meisten hier genannten Linux-Distributionen können Sie frei aus dem Internet herunterladen. Bei den Download-Dateien handelt es sich meist um die ISO-Images der Installations-DVDs oder -CDs. Jede handelsübliche Brennsoftware kann diese auf einen Datenträger brennen. In Tabelle 7.1 sehen Sie die URLs der wichtigsten Distributionen.
| Distribution | Website |
|
openSUSE |
|
|
Fedora Linux |
|
|
Debian GNU/Linux |
|
|
Ubuntu Linux |
|
|
Knoppix |
|
|
Mandriva Linux |
Eine andere Variante freier Unix-Derivate bilden die verschiedenen BSD-Systeme. Hier die wichtigsten, jeweils mit ihrer Projekt-Website für Informationen und Downloads:
- FreeBSD (http://www.freebsd.org/)
- OpenBSD (http://www.openbsd.org/)
- NetBSD (http://www.netbsd.org/)
Eine weitere interessante kostenlose Alternative ist OpenSolaris, die Community-Variante von Sun Solaris. Sie können es unter http://solaris.java.net/ herunterladen.
Viele der hier genannten Distributionen und Systeme bieten übrigens Live-CDs oder Live-DVDs. Sie können die entsprechenden Images herunterladen, auf einen Datenträger brennen und direkt davon booten, um die Betriebssysteme risikolos auszuprobieren. Eine andere interessante Lösung besteht darin, sie in einer Virtualisierungssoftware wie VMware oder Xen zu starten; in diesem Fall kann das Image sogar ohne Brennvorgang als virtueller Datenträger eingestellt werden.
7.1 Arbeiten mit der Shell
Auch wenn so gut wie alle Distributionen inzwischen schon bei der Installation eine grafische Benutzeroberfläche einrichten, sollten Sie sich den Umgang mit der Konsole angewöhnen. Die mächtigsten Funktionen des Systems werden nach wie vor über die Kommandozeile aufgerufen; grafische Steuerprogramme dafür stehen nicht flächendeckend und schon gar nicht durchgehend als Open Source zur Verfügung.
7.1.1 Booten und Login
Die meisten Linux- oder Unix-Versionen verfügen über irgendeine Art von Bootmenü, das gleich nach dem Einschalten des Rechners und den BIOS-Meldungen angezeigt wird. Falls mehrere Betriebssysteme installiert sind, können Sie hier eines auswählen; ansonsten stehen nur verschiedene Optionen für das System selbst zur Verfügung. In Abbildung 7.1 sehen Sie als Beispiel den Startbildschirm des Bootmanagers von Ubuntu. Wählen Sie in Ihrem entsprechenden Menü das gewünschte System aus, oder warten Sie, bis die automatische Vorauswahl aktiv wird.
Nach dem eigentlichen Booten gelangen Sie zu einem Anmeldebildschirm, sofern Sie keinen
automatischen Log-in eingestellt haben. Dieser Bildschirm kann entweder textbasiert
sein wie in Abbildung 7.2 oder aber grafisch wie in Abbildung 7.3. In jedem Fall müssen Sie Ihren Benutzernamen und Ihr Passwort eingeben und anschließend
 drücken. Bei einem textbasierten Log-in gibt die Passworteingabe übrigens keinerlei
optisches Feedback, während bei den meisten grafischen Anmeldebildschirmen Sternchen
(***) angezeigt werden.
drücken. Bei einem textbasierten Log-in gibt die Passworteingabe übrigens keinerlei
optisches Feedback, während bei den meisten grafischen Anmeldebildschirmen Sternchen
(***) angezeigt werden.
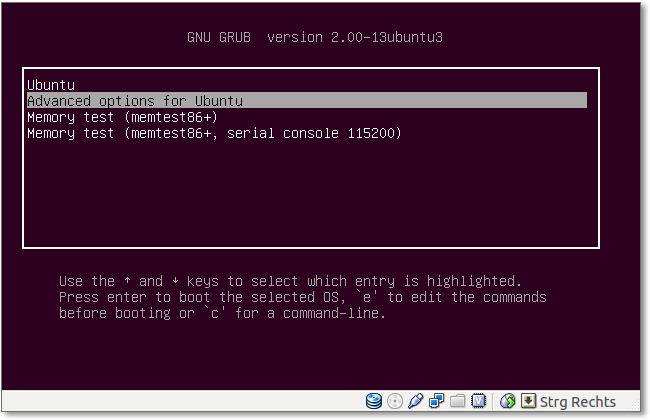
Abbildung 7.1 Das Bootmenü von Ubuntu
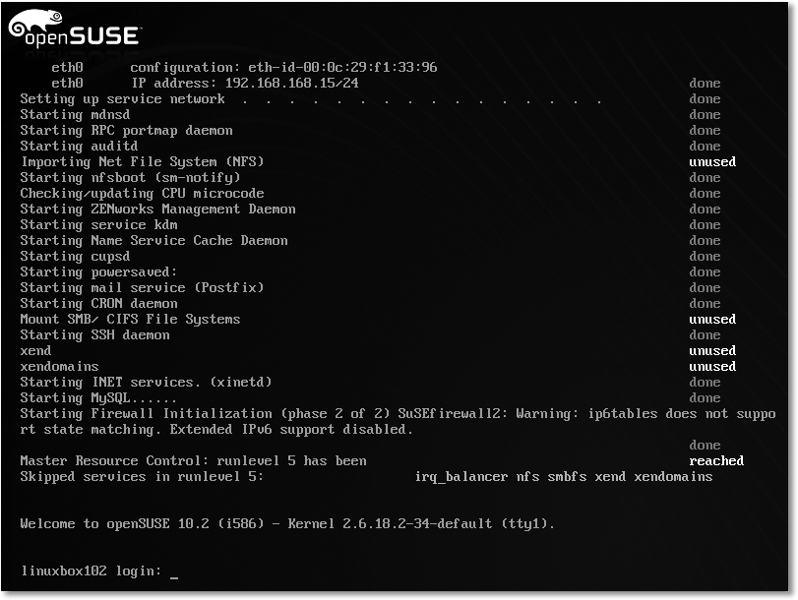
Abbildung 7.2 Textbasierter Boot- und Log-in-Bildschirm von openSUSE
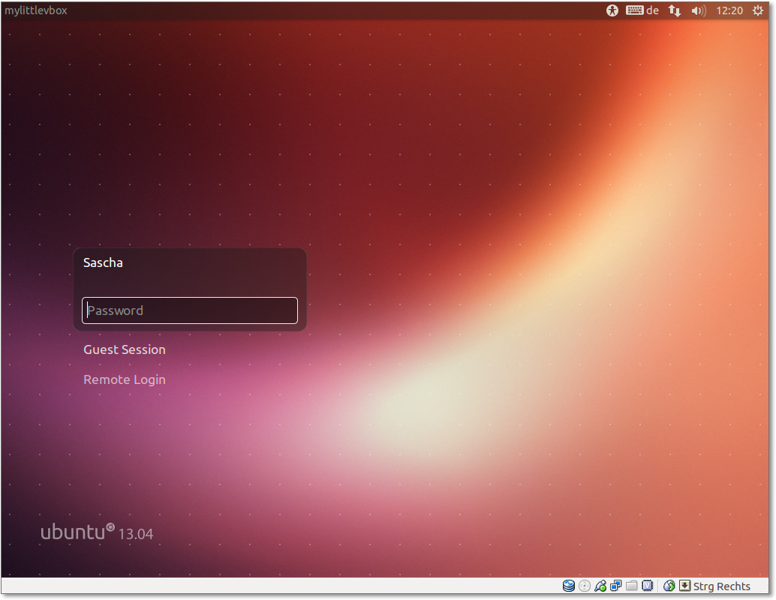
Abbildung 7.3 Grafischer Log-in bei Ubuntu
In der Regel wird bei der Installation des Systems ein Passwort für den Superuser mit dem vorgegebenen Benutzernamen root eingerichtet. Sie sollten sich niemals als root anmelden, wenn Sie mit dem System nur normal arbeiten möchten, weil Sie als root wirklich alles dürfen und so versehentlich das gesamte System beschädigen könnten. Die Hauptaufgabe des Benutzers root ist die Systemadministration. Aus diesem Grund wird bei fast jeder Linux-Installation automatisch ein normaler Benutzer eingerichtet.
Einige Systeme – zum Beispiel Ubuntu und Mac OS X – gehen einen anderen Weg: hier wird kein separater root-Account eingerichtet, sondern die Systeme erlauben dem Standardbenutzer, über die im weiteren Verlauf des Kapitels besprochenen Kommandos su oder sudo root-Rechte zu erlangen.
Für jeden Benutzer, dessen Anmeldedaten auf traditionelle Weise lokal gespeichert werden, existiert ein Eintrag in der Datei /etc/passwd. Dieser Eintrag enthält verschiedene jeweils durch Doppelpunkt getrennte Informationen:
Username:Passwort:UID:GID:Info:Home:Shell
Username und Passwort erklären sich von selbst. Die UID ist die numerische User-ID des Benutzers, die GID entsprechend die Nummer der Gruppe, der er angehört. Info enthält eine Klartextinformation über den Benutzer wie den vollständigen Namen, eine Telefonnummer oder E-Mail-Adresse (der Originalname des Feldes lautet GECOS[Anm.: Der Name stammt von einem gleichnamigen Großrechner-Betriebssystem der 60er-Jahre des 20. Jahrhunderts.]). Diese Informationen können über das Netzwerk mit einem Programm namens finger ermittelt werden. Home gibt das bereits zuvor besprochene Home-Verzeichnis dieses Benutzers an (in der Regel /home/Username). Shell gibt schließlich an, welche Shell dem Benutzer nach dem Log-in präsentiert wird – die verschiedenen Shells werden in Abschnitt 7.1.3, »Grundfunktionen der Shell«, besprochen. Ein konkreter Eintrag könnte beispielsweise folgendermaßen aussehen:
user:x:102:100:Irgendjemand:/home/user:/bin/bash
Der Username und das Passwort sind die wichtigsten Informationen. Nur eine korrekt eingegebene Kombination aus beiden ermöglicht die Anmeldung eines Benutzers. Das Passwort steht an dieser Stelle nicht etwa im Klartext (es ließe sich leicht von jedem Benutzer oder sogar von einem externen Angreifer stehlen), sondern verschlüsselt – aus im Folgenden erläuterten Gründen ist im Beispieleintrag übrigens gar kein Passwort zu sehen, sondern nur die Markierung x. Das eingesetzte Verschlüsselungsverfahren ist bei korrekter Implementierung so beschaffen, dass die Einträge nicht wieder entschlüsselt werden können (Einwegverschlüsselung). Das Passwort, das ein Benutzer eingibt, wird vielmehr auf dieselbe Art und Weise verschlüsselt wie die /etc/passwd-Einträge. Anschließend wird das Ergebnis mit dem gespeicherten, verschlüsselten Passwort verglichen. Eine Übereinstimmung bedeutet, dass das Passwort wohl korrekt sein muss.
Da der Verschlüsselungsweg bekannt ist, könnte ein Angreifer, dem ein Diebstahl der Datei /etc/passwd gelingt, einfach nacheinander eine Liste von Wörtern verschlüsseln und mit den gespeicherten Passwörtern vergleichen. Es gibt sogar ein Programm namens crack, das diesen Job automatisch durchführt, und die passenden Wortlisten für die verschiedensten Sprachen erhalten Sie leicht aus dem Internet.
Die Schlussfolgerung sollte klar sein: Verwenden Sie als Passwort niemals ein Wort, das in einem Wörterbuch vorkommen könnte. Eine beliebige Kombination aus Großbuchstaben, Kleinbuchstaben und Ziffern ist dagegen ziemlich sicher. Die Frage ist nur, wie Sie sich ein solches Passwort merken können – aus naheliegenden Gründen sollten Sie es nirgendwo aufschreiben. Das wäre in etwa so klug, als würden Sie die Geheimzahl für Ihre EC-Karte mit einem Folienstift auf die Karte selbst schreiben.
Eine einfache Methode, ein sicheres Passwort zu erfinden und es sich zu merken, besteht darin, die Anfangsbuchstaben eines beliebigen Satzes als Passwort zu verwenden. Visuell passende Buchstaben können Sie durch Ziffern ersetzen (zum Beispiel 1 statt i); Groß- und Kleinschreibung ergeben sich in deutschen Sätzen automatisch.
Beispielsweise würde aus dem Satz »Mit Linux wär’ das nicht passiert«[Anm.: Seien Sie froh, wenn Sie den Satz nicht kennen – er bildet oft den Auftakt zu den sinnlosen »Mein Betriebssystem ist besser als deines«-Debatten im Heise-Forum.] die Buchstabenkombination MLwdnp, auf die niemand kommen kann. Allerdings ist es am sichersten, die acht Zeichen, die in klassischen Unix-Passwörtern zulässig sind, auch auszunutzen.[Anm.: Diese Beschränkung gilt für die veraltete crypt-Verschlüsselung. Bei moderneren Einwegverschlüsselungsverfahren wie MD5, SHA1 oder Blowfish kann das Passwort beliebig lang sein.] Eine Brute-Force-Attacke (englisch für »rohe Gewalt«), bei der ein Angreifer jede erdenkliche Zeichenkombination durchprobiert, würde dadurch nämlich so lange dauern, dass sie sich nicht lohnt.
Modernere Unix-Systeme führen übrigens einen zusätzlichen Schutzmechanismus ein: Die eigentlichen Passwörter werden gar nicht mehr in der Datei/etc/passwd verwahrt, sondern in /etc/shadow. Diese Datei besitzt einen ähnlichen Aufbau wie /etc/passwd, ist aber nur für den User root lesbar und nicht für alle Benutzer.
7.1.2 Virtuelle Terminals
Falls Ihr System mit einer grafischen Oberfläche startet, befinden Sie sich nach der
Anmeldung auf dem Desktop, der Schreibtischoberfläche. Hier sehen Sie verschiedene Symbole, Menüs und andere
Bedienelemente, die in Abschnitt 7.5.2, »Desktops«, behandelt werden. Wechseln Sie an dieser Stelle zunächst in eine Textmodus-Konsole,
indem Sie die Tastenkombination  +
+  +
+  betätigen.
betätigen.
Jedes Linux-System bietet mehrere virtuelle Terminals zum Arbeiten an, in jedem von ihnen können Sie sich unter einem beliebigen Benutzernamen
anmelden und jeweils andere Programme ausführen. Standardmäßig sind sechs virtuelle
Terminals eingerichtet, die über + bis +  aufgerufen werden können. Mit +
aufgerufen werden können. Mit +  wechseln Sie dagegen wieder zur grafischen Oberfläche, falls diese gestartet wurde.
Aus der GUI heraus müssen Sie zusätzlich die -Taste festhalten, um wieder in eines der Textterminals zu wechseln.
wechseln Sie dagegen wieder zur grafischen Oberfläche, falls diese gestartet wurde.
Aus der GUI heraus müssen Sie zusätzlich die -Taste festhalten, um wieder in eines der Textterminals zu wechseln.
Alternativ können Sie auch innerhalb der grafischen Oberfläche ein Terminalfenster öffnen, beispielsweise das Programm xterm oder eine modernere, komfortablere Variante. Halten Sie einfach Ausschau nach einem Icon, das einen schwarzen Textbildschirm zeigt. In KDE heißt das zuständige Programm beispielsweise Konsole, in GNOME einfach Terminal. Zusätzlich gibt es Drittanbieter-Terminals wie Terminator, dessen Fläche in mehrere unabhängige Teile unterteilt werden kann.
Wenn Sie sich an der Konsole erfolgreich angemeldet haben, erhalten Sie eine Eingabeaufforderung (Prompt). Der Prompt kann je nach Konfiguration sehr unterschiedlich aussehen. In der Regel sehen Sie etwa Folgendes:
user@rechner: ~ $
Statt user wird der Benutzername angezeigt, unter dem Sie sich angemeldet haben; hinter dem @ steht der Name des Rechners, auf dem Sie gerade arbeiten. Auf diese Angaben folgt der Pfad des aktuellen Arbeitsverzeichnisses. Im zuvor gezeigten Beispiel befindet sich der Benutzer in seinem Home-Verzeichnis (auf dieses Beispiel bezogen /home/user), das durch die Tilde gekennzeichnet wird. Das Dollarzeichen bildet schließlich den Abschluss; dahinter blinkt der Cursor für die Befehlseingabe. Statt des Dollarzeichens erscheint bei manchen Shells > oder ein anderes Zeichen.
Wenn Sie als Benutzer root angemeldet sind, bekommen Sie einen etwas anderen Prompt zu sehen; beispielsweise folgenden:
rechner: ~ #
Es wird also kein Benutzername angezeigt, und hinter der Pfadangabe folgt eine Raute (#) statt des Dollarzeichens. Auch root befindet sich in diesem Beispiel in seinem Home-Verzeichnis, standardmäßig /root.
In den folgenden Beispielen wird der Prompt einfach als Dollarzeichen dargestellt. Wenn für einen Befehl root-Rechte erforderlich sind, wird dagegen die Raute verwendet. Benutzereingaben sind in den Beispielen jeweils fett gesetzt, um sie vom Prompt und von der Ausgabe des Systems abzusetzen.
7.1.3 Grundfunktionen der Shell
Das Programm, das Ihre Befehle entgegennimmt und zu interpretieren versucht, wird Shell genannt. Es gibt nicht die Linux-Shell, sondern eine Reihe verschiedener Shell-Programme, die sich bis zu einem gewissen Grad voneinander unterscheiden. Höchstwahrscheinlich läuft in Ihrem System eine Shell, die als bash bezeichnet wird. Geben Sie den folgenden Befehl ein, um herauszufinden, welche Shell Sie ausführen:
$0 ist eine spezielle Variable, die jeweils den Namen des zurzeit laufenden Programms enthält. Die Ausgabe dürfte zum Beispiel /bin/bash oder /bin/sh lauten. Die gängigsten Shells werden in der folgenden Liste aufgeführt:
- sh oder bsh, die Bourne Shell, benannt nach ihrem Entwickler, war die ursprüngliche Shell des Bell-Labs-Unix. Sie beherrscht die kleinste gemeinsame Menge der Fähigkeiten aller anderen Shells.
- csh, die C-Shell, und ihre Erweiterung tcsh enthalten eine Reihe spezieller Funktionen, die von der Programmiersprache C beeinflusst wurden und besonders den Bedürfnissen von C-Programmierern entgegenkommen.
- bash, die Bourne Again Shell (ein nettes Wortspiel), ist die GNU-Weiterentwicklung der ursprünglichen Bourne Shell mit vielen interessanten Zusatzfunktionen. Diese Shell ist in allen Linux-Distributionen und zum Beispiel auch unter Mac OS X als Standard voreingestellt. Trotzdem werden alle hier Genannten und meist noch weitere mitgeliefert.
- ksh, die Korn Shell, ist der offizielle, bei AT&T entwickelte Nachfolger der bsh. Sie vereint einige Vorteile von Bourne- und C-Shell mit eigenen Erweiterungen. Die ksh selbst ist nicht frei verfügbar, es gibt aber eine freie Variante namens pdksh (Public Domain Korn Shell).
- sash, die Stand-alone Shell, ist ein nützliches Hilfsmittel zur Fehlerbehebung: Viele Standard-POSIX-Dienstprogramme sind direkt in die Shell selbst eingebaut und brauchen nicht zusätzlich bereitgestellt zu werden. Ihre Namen beginnen normalerweise mit einem Minuszeichen, um sie von der voll ausgestatteten GNU-Version dieser Tools zu unterscheiden. Für Rettungssysteme, die vom USB-Stick oder sogar von der Diskette starten, ist die sash ideal.
Um Missverständnissen vorzubeugen, sollten Sie zunächst verstehen, dass über 90 % der Eingaben, die Sie an der Kommandozeile vornehmen, unter allen Shells identisch sind: Es handelt sich nämlich bei diesen Eingaben überhaupt nicht um Shell-Kommandos. Die meisten »Unix-Befehle« sind separate Systemprogramme, die sich für gewöhnlich im Verzeichnis /bin befinden und mit der Shell nichts zu tun haben. Die Shells unterscheiden sich insbesondere in der Art und Weise, wie die Funktionen der Systemprogramme durch intelligente Verknüpfungen erweitert werden können.
Die Konfiguration, mit der die Shell (und übrigens auch jedes andere Programm) ausgeführt wird, heißt Umgebung (Environment). Sie besteht aus der User- und Group-ID, unter der das Programm läuft, aus dem aktuellen Arbeitsverzeichnis sowie aus einer Reihe von Umgebungsvariablen, die von dem Programm ausgelesen werden. Die Shell bezieht ihre Umgebung aus diversen Konfigurationsdateien, insbesondere aus:
- /etc/profile: zentrale Konfigurationsdatei für alle Shells und alle User. Diese Datei sollte nicht editiert werden; ändern Sie stattdessen ~/.bashrc, oder erstellen Sie eine benutzerspezifische ~/profile.local.
- /etc/profile.d/*: zentrale Konfigurationsdateien für bestimmte Aspekte einzelner Shells
- ~/.bashrc: bash-spezifische Einstellungen für einen einzelnen Benutzer in dessen Home-Verzeichnis
Beispielsweise wurde erst in der csh die Möglichkeit eingeführt, Programme im Hintergrund zu starten: Wenn Sie ein &-Zeichen an einen Befehl anhängen, gelangt dessen Ausgabe nicht auf den Bildschirm, und Sie können sofort den nächsten Befehl eingeben. Es wird beim Aufruf des Befehls lediglich dessen Prozess-ID ausgegeben. Inzwischen bieten fast alle Shells diese Option an. Hier sehen Sie ein einfaches Beispiel, in dem die Suche nach Dateien, deren Name mit einem a beginnt, in den Hintergrund verbannt wird:
$ find . -name a* &
[1] 3125
$
Die Funktion des Befehls find wird im weiteren Verlauf des Kapitels noch genauer erläutert.
In eckigen Klammern wird eine Job-Nummer angezeigt; dahinter erscheint die PID. Statt 3125 werden Sie wahrscheinlich eine andere zu sehen bekommen. Mithilfe des Befehls fg (für »foreground« – nicht etwa »fat grin«, wie in Chats und Foren üblich) können Sie die Ausgabe des Befehls im Vordergrund fortsetzen. Falls sich mehrere Prozesse im Hintergrund befinden, müssen Sie die Job-Nummer angeben. Beispiel:
$ fg 1
Ebenso können Sie ein bereits laufendes Programm nachträglich in den Hintergrund stellen,
indem Sie die Tastenkombination +  betätigen. Auch in diesem Fall werden Job-Nummer und PID angezeigt, und Sie können
das Programm mit fg zurückholen.
betätigen. Auch in diesem Fall werden Job-Nummer und PID angezeigt, und Sie können
das Programm mit fg zurückholen.
In der Regel bestehen die Befehle, die Sie eingeben, aus dem Namen des gewünschten Systemprogramms und einer durch Leerzeichen getrennten Liste von Parametern. Einige der Parameter sind Optionen, die bei den meisten Befehlen mit einem Minuszeichen beginnen, andere geben dagegen konkrete Werte wie Pfad- oder Dateinamen, Bezeichnungen und Ähnliches an.
Anweisungen werden durch das Drücken von abgeschlossen und unmittelbar ausgeführt. Zu lange Eingaben können Sie aber durch
einen Backslash (\) und auf mehrere Zeilen aufteilen. Hier ein Beispiel, das in allen Dateien des aktuellen
Verzeichnisses und allen Unterverzeichnissen nach dem Text "in diesem Fall werden Job-Nummer und PID angezeigt" sucht:
$ grep -r \
> "in diesem Fall werden Job-Nummer und PID angezeigt" \
> *
Die Shell sucht nach der Eingabe eines Kommandos in der folgenden Reihenfolge nach einer Möglichkeit, es auszuführen:
- alias-Definitionen (siehe Abschnitt 7.3, »Automatisierung«)
- Shell-Built-ins, das heißt Kommandos, die in das Shell-Binary selbst eingebaut sind
- Externe Programme – die in der Umgebungsvariablen PATH angegebenen Verzeichnisse werden der Reihe nach durchsucht.
Falls der eingegebene Befehl an keinem der genannten Orte gefunden wird, erhalten Sie eine Fehlermeldung. Falls Sie die bash verwenden und irrtümlich das Windows-Kommando cls zum Bildschirmlöschen eingeben, erhalten Sie beispielsweise diese Ausgabe:
bash: cls: command not found
Möchten Sie wissen, ob es sich bei einem Kommando um ein Alias, ein Shell-Built-in oder ein Programm handelt, können Sie type Kommando eingeben. Hier für jeden Typ ein Beispiel:
$ type ls
ls is aliased to `/bin/ls $LS_OPTIONS'
$ type alias
alias is a shell builtin
$ type mkdir
mkdir is hashed (/bin/mkdir)
Wenn Sie den Namen eines Programms eingeben, sucht die Shell in ganz bestimmten Verzeichnissen nach diesem Programm. Diese Verzeichnisse sind in einer Umgebungsvariablen namens PATH festgelegt. Möchten Sie diese Liste lesen, geben Sie Folgendes ein:
$ echo $PATH
/bin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/share/bin
Der Befehl echo gibt sämtlichen folgenden Text in der nächsten Zeile aus. Das Dollarzeichen sorgt dafür, dass die Shell das folgende Wort als den Namen einer Variablen auffasst, deren Wert ausgegeben werden soll. Beachten Sie, dass Unix-Systeme, anders als Windows, auch bei Variablennamen zwischen Groß- und Kleinschreibung unterscheiden und dass diese Variable PATH heißt, nicht etwa Path oder path.
Der Wert der Variablen PATH besteht aus einer Liste von absoluten Pfadangaben (mit / beginnend), die durch Doppelpunkte voneinander getrennt werden. In der Praxis ist die Liste meist erheblich länger als im zuvor gezeigten Beispiel.
Im Folgenden soll ein Verweis auf das aktuelle Verzeichnis hinzugefügt werden. Üblicherweise wird ein Programm nämlich nicht einfach ausgeführt, wenn Sie sich in seinem Verzeichnis befinden, sondern nur, wenn dieses Verzeichnis auch in PATH steht. Um dies zu ändern, können Sie die spezielle Verzeichnisangabe . (einen einzelnen Punkt) hinzufügen, da dieser Punkt jeweils das aktuelle Verzeichnis repräsentiert.
Falls Sie den Inhalt der Variablen ändern möchten, funktioniert das in den verschiedenen Shells unterschiedlich. Hier sehen Sie Beispiele für die zuvor genannten Shells:
- sh, bsh, bash und ksh: export PATH=$PATH:.
- csh und tcsh: set PATH=$PATH:.
Der Wert, der PATH in den beiden Beispielen zugewiesen wird, nämlich $PATH:., bedeutet: bisheriger Wert von PATH, Doppelpunkt, anschließender Punkt. Die vollständige Pfadliste aus dem zuvor gezeigten Beispiel sähe nach dieser Änderung folgendermaßen aus:
/bin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/share/bin:.
In der Praxis sollten Sie sich gut überlegen, ob Sie diese Änderung durchführen möchten, da sie ein gewisses Sicherheitsrisiko darstellt. Wenn Sie den Punkt angeben möchten, gehört er auf jeden Fall ans Ende von PATH, weil Ihnen ein Angreifer ansonsten ein Programm unterjubeln könnte, das denselben Namen trägt wie ein Systemprogramm und deshalb stattdessen ausgeführt würde, falls Sie sich im entsprechenden Verzeichnis befinden. Die Verzeichnisse in PATH werden nämlich der Reihe nach durchprobiert, bis ein Programm mit dem angeforderten Namen gefunden wird. Wird es nirgendwo gefunden, erscheint eine Fehlermeldung.
Alle modernen Unix-Shells beherrschen die sehr bequeme Funktion der Eingabevervollständigung: Wenn Sie einen Befehl oder den Pfad einer Datei eintippen, können Sie zwischenzeitlich
die  -Taste betätigen. Wenn der Befehl oder Pfad zu diesem Zeitpunkt bereits eindeutig
ist, also nur noch eine Interpretation zulässt, wird er komplett ausgeschrieben. Bei
Zweideutigkeiten wird er nur zum Teil ergänzt, und es ertönt ein Warnton. Das folgende
Beispiel zeigt, wie Sie aus Ihrem Home-Verzeichnis schnell in das darunterliegende
Verzeichnis dokumente wechseln:
-Taste betätigen. Wenn der Befehl oder Pfad zu diesem Zeitpunkt bereits eindeutig
ist, also nur noch eine Interpretation zulässt, wird er komplett ausgeschrieben. Bei
Zweideutigkeiten wird er nur zum Teil ergänzt, und es ertönt ein Warnton. Das folgende
Beispiel zeigt, wie Sie aus Ihrem Home-Verzeichnis schnell in das darunterliegende
Verzeichnis dokumente wechseln:
user@rechner: ~ # cd do
user@rechner: ~/dokumente #
Angenommen, in Ihrem Home-Verzeichnis befindet sich ein weiteres Verzeichnis namens
dokumente2. In diesem Fall wird durch zwar das Wort »dokumente« ergänzt, aber die Shell weiß noch nicht, ob Sie wirklich
das Verzeichnis dokumente meinen oder dokumente2. Deshalb wird der besagte Warnton ausgegeben. Wenn Sie zweimal drücken, wird in den meisten modernen Shells eine Liste der möglichen Alternativen
angezeigt.
Ähnlich komfortabel ist die History aller bereits eingegebenen Befehle. Mit den Pfeiltasten auf der Tastatur können Sie
darin nach oben oder nach unten blättern; die früheren beziehungsweise späteren Befehle
werden dadurch wieder angezeigt. Wenn der gewünschte Befehl erscheint, können Sie
ihn ändern und anschließend mithilfe von ausführen.
Neuere Versionen der bash speichern die History übrigens in einer Datei namens .bash_history in Ihrem Home-Verzeichnis, sodass sie beim nächsten Log-in wieder zur Verfügung steht.
In der bash können Sie außerdem viele praktische Tastenkürzel verwenden. Es gibt zwei verschiedene Modi, die nach den im weiteren Verlauf des Kapitels vorgestellten Texteditoren Emacs und vi benannt sind. Im standardmäßig eingestellten Emacs-Modus können Sie unter anderem folgende Tastenkombinationen verwenden:
 oder +
oder +  bewegt den Cursor ein Zeichen nach links;
bewegt den Cursor ein Zeichen nach links;  oder +
oder +  navigiert ein Zeichen nach rechts.
navigiert ein Zeichen nach rechts.
- + wandert um ein Wort nach links und + eines nach rechts; als Grenze gilt jeweils ein Leerzeichen.
- Mit +
 oder
oder  gelangen Sie zum Zeilenanfang, mit +
gelangen Sie zum Zeilenanfang, mit +  oder
oder  zum letzten Zeichen der Zeile.
zum letzten Zeichen der Zeile.
 oder +
oder +  löscht das Zeichen unter dem Cursor, während
löscht das Zeichen unter dem Cursor, während  oder +
oder +  das links davon befindliche Zeichen entfernt.
das links davon befindliche Zeichen entfernt.
- Mit +
 entfernen Sie ein Wort.
entfernen Sie ein Wort.
- +
 löscht den Text von der Cursorposition bis zum Zeilenende.
löscht den Text von der Cursorposition bis zum Zeilenende.
- +
 entfernt den gesamten Inhalt der Zeile.
entfernt den gesamten Inhalt der Zeile.
- +
 startet die inkrementelle Suche nach einem History-Eintrag (inkrementell bedeutet,
dass die Eingabe eines Zeichens jeweils sofort zum ersten infrage kommenden Text springt).
startet die inkrementelle Suche nach einem History-Eintrag (inkrementell bedeutet,
dass die Eingabe eines Zeichens jeweils sofort zum ersten infrage kommenden Text springt).
- +
 beziehungsweise +
beziehungsweise +  ermöglichen das Blättern im Puffer des Terminal(fenster)s.
ermöglichen das Blättern im Puffer des Terminal(fenster)s.
- +
 löscht den Bildschirm.
löscht den Bildschirm.
In modernen Terminalemulationen können Sie einen beliebigen Text durch Ziehen mit
gedrückter linker Maustaste markieren. Ein Klick mit der mittleren Maustaste oder
dem Scrollrad fügt diesen Text dann an der Textcursorposition wieder ein. Mäuse mit
zwei Tasten lassen sich dabei so konfigurieren, dass ein Klick auf beide Tasten gleichzeitig
die mittlere Taste emuliert. Bei den meisten modernen Systemen funktioniert das Verfahren
auch distributionsweit; in GUI-Programmen wird aber zusätzlich auch die Variante über
die Zwischenablage unterstützt – +  zum Kopieren beziehungsweise +
zum Kopieren beziehungsweise +  zum Ausschneiden und +
zum Ausschneiden und +  zum Einfügen.
zum Einfügen.
Wie bereits erwähnt, sollten Sie nicht permanent als User root arbeiten. Mitunter müssen Sie aber zwischendurch eine Konfigurationsaufgabe erledigen,
die nur dem Superuser gestattet ist. Es ist sicherlich keine sehr bequeme Lösung,
sich mithilfe von logout abzumelden und als root wieder anzumelden. Angenehmer ist zu diesem Zweck der Befehl su, der für substitute user oder auch superuser steht: Wenn Sie als gewöhnlicher Benutzer su eingeben, werden Sie nach dem root-Passwort gefragt. Falls Sie es korrekt eingeben, können Sie nun einzelne Befehle
als root ausführen. Mit exit oder + erhalten Sie Ihre normale Shell zurück.
Als root können Sie mit su auch im Namen eines anderen Users agieren, ohne dessen Passwort zu kennen. Dazu müssen Sie lediglich su Benutzername eingeben.
Wenn Sie nur einen einzigen Befehl als root ausführen möchten, können Sie auch einfach sudo Kommando eingeben – auch hier werden Sie nach dem Passwort gefragt.
Wie bereits erwähnt, existiert auf Ubuntu, Mac OS X und einigen anderen Systemen kein echter root-User mehr. Deshalb müssen Sie hier als Standardbenutzer (der bei der Systeminstallation angelegt wurde) stattdessen Ihr eigenes Passwort eingeben, um mit su oder sudoroot-Rechte zu bekommen.
7.1.4 Hilfefunktionen
Traditionell ist jedes Unix-System mit einem eingebauten Hilfesystem ausgestattet, den im vorletzten Kapitel erwähnten Manpages (kurz für manual pages, also Handbuchseiten). Bei Linux-Systemen kommt ein neueres, komfortableres System namens GNU info hinzu. Bei den GNU-Tools, also praktisch allen Systemprogrammen, sind die info-Seiten in der Regel aktueller und ausführlicher als die Manpages.
Manpages
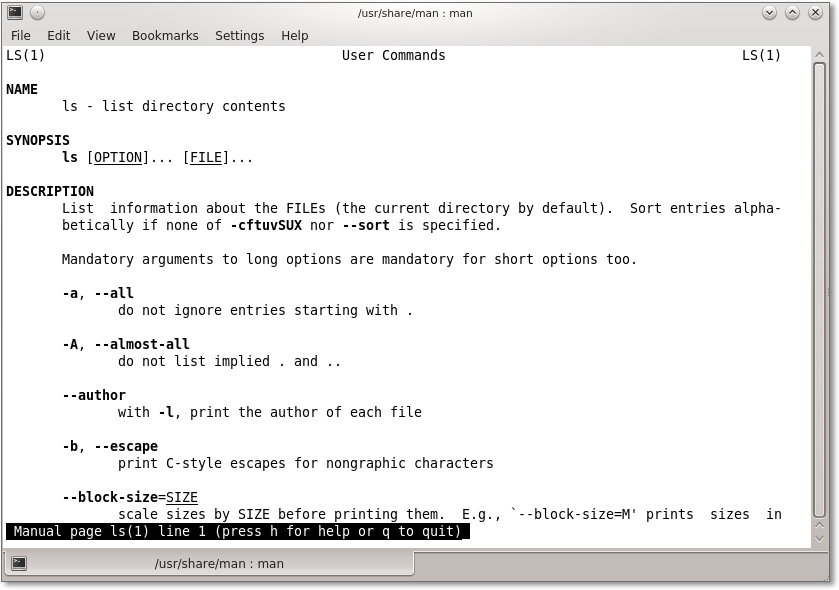
Eine Manpage liefert Informationen über einen bestimmten Befehl, ein Hilfsprogramm oder eine Konfigurationsdatei. Um sie anzuzeigen, wird das Programm man verwendet. Geben Sie beispielsweise Folgendes ein, falls Sie Hilfe zum Befehl ls benötigen, der Verzeichnisinhalte auflistet:
$ man ls
Zuerst formatiert man die Hilfeseite, was eine Weile dauern kann. Danach wird die Seite angezeigt (siehe Abbildung 7.4), und Sie können mithilfe der folgenden Tasten, die vom im Folgenden angesprochenen Pager-Programm less bereitgestellt werden, darin blättern und navigieren:
- , oder
 – eine Zeile weiter
– eine Zeile weiter
 oder
oder  – eine Zeile zurück
– eine Zeile zurück
- , Leertaste oder – eine Fensterseite weiter
- oder – eine Fensterseite zurück
- – zum Textanfang
- – zum Textende
 Suchbegriff – vorwärts nach dem angegebenen Begriff suchen
Suchbegriff – vorwärts nach dem angegebenen Begriff suchen
 Suchbegriff – rückwärts suchen
Suchbegriff – rückwärts suchen
 – nächstes Vorkommen des Suchbegriffs
– nächstes Vorkommen des Suchbegriffs
 + – nächstes Vorkommen des Suchbegriffs in der jeweils anderen Richtung
+ – nächstes Vorkommen des Suchbegriffs in der jeweils anderen Richtung
- – Hilfeseite zur Bedienung von less
 – Programm beenden
– Programm beenden
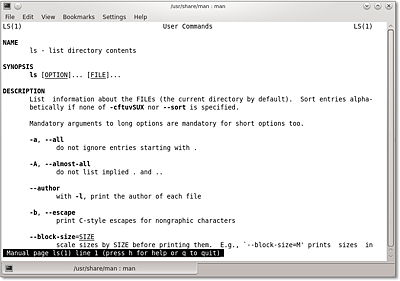
Abbildung 7.4 Die Manpage zum Befehl »ls« im KDE-Terminal »Konsole«
Jede Manpage gehört zu einer bestimmten Kategorie, die jeweils durch eine der folgenden Nummern oder Buchstaben gekennzeichnet werden:
- 0: Include-Dateien für eigene C-Programme (siehe Kapitel 9, »Grundlagen der Programmierung«)
- 1: Shell-Programme
- 2: Systemaufrufe (Kerneldienste)
- 3: Bibliotheksfunktionen (C-Standardbibliothek und so weiter)
- 4: Beschreibung der Gerätedateien (/dev/*) und anderer Spezialdateien
- 5: Konfigurationsdatei-Formate
- 6: Spiele
- 7: Makros (kombinierte Programme)
- 8: Administrationsbefehle (in der Regel root vorbehalten)
- 9: Kernelroutinen
- n: (new) neue Tools
- l: (local) lokale Tools
- p: (public) öffentliche Tools
- o: (old) veraltete Tools
Die Buchstaben-Sektionen sind veraltet und werden üblicherweise nicht mehr verwendet. Einige optionale Programme benutzen auch eigene Kategorien. Sie müssen die Kategorie immer dann angeben, wenn es mehrere Einträge mit dem gewünschten Namen gibt.
In diesem Fall lautet die Syntax man Kategorie Eintrag. Beispiel:
$ man 1 passwd
Der Befehl whatis Eintrag oder man -f Eintrag zeigt sämtliche Manpages mit dem angegebenen Namen an; die Sektionen stehen in Klammern:
$ whatis passwd
passwd (lssl) - compute password hashes
passwd (1) - change user password
passwd (5) - password file
Die Option man -k String oder das gleichbedeutende Kommando apropos verwendet den eingegebenen Text dagegen als Teilstring:
$ apropos passwd
htpasswd2 (1) - Manage user files for basic authentication
ldappasswd (1) - change the password of an LDAP entry
passwd (1) - change user password
gpasswd (1) - change group password
[...]
GNU info
Das Hilfesystem GNU info wird durch den Befehl info aktiviert. Wenn Sie kein Stichwort eingeben, wird der Directory Node angezeigt, in dem Sie eine Übersicht über die verschiedenen Themen erhalten. Die Tastenkürzel, mit denen Sie in GNU info navigieren können, entsprechen im Großen und Ganzen dem in Abschnitt 7.4.2 vorgestellten Editor GNU Emacs. Hier die wichtigsten im Überblick:
- + (forward) – ein Zeichen weiter
- + (backward) – ein Zeichen zurück
- + (next) – eine Zeile weiter
- +
 (previous) – eine Zeile zurück
(previous) – eine Zeile zurück
- + – zum Zeilenanfang
- + – zum Zeilenende
- Leertaste – eine Bildschirmseite weiter
- oder – eine Bildschirmseite zurück
 Thema (menu) – ruft die info-Seite zum angegebenen Thema auf. Falls es zu dem Wort unter dem Cursor eine Seite
gibt, wird diese automatisch eingetragen.
Thema (menu) – ruft die info-Seite zum angegebenen Thema auf. Falls es zu dem Wort unter dem Cursor eine Seite
gibt, wird diese automatisch eingetragen.
- (next) – eine Seite im aktuellen Oberthema weiterblättern
- (previous) – eine Seite zurückblättern
- (up) – eine Ebene nach oben; die oberste Ebene ist der Directory Node
- (last) – zurück zur vorher angezeigten Seite
- (help) – Hilfe zu info selbst; zurück mit
 – tabellarische Kurzübersicht über info; zurück mit
– tabellarische Kurzübersicht über info; zurück mit - – info beenden
In Abbildung 7.5 sehen Sie als Beispiel die GNU-info-Seite zum Befehl ls.
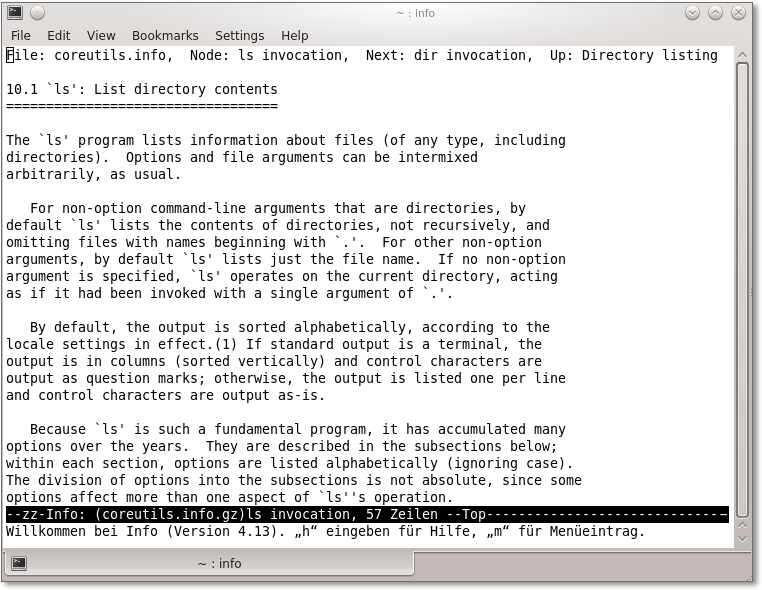
Abbildung 7.5 Die GNU-info-Seite zu »ls« im KDE-Terminal »Konsole«
7.1.5 Pipes und Ein-/Ausgabeumleitung
Eine der praktischsten Eigenschaften der Unix-Shells besteht in der Umleitung von Ein- und Ausgabe sowie deren Verkettung. Mit der Ausgabe eines Befehls können Sie mehr tun, als sie einfach auf dem Bildschirm darzustellen, und die Eingabe muss nicht unbedingt von der Tastatur stammen: Sie können die Eingabe für einen Befehl aus einer Datei holen, die Ausgabe in eine Datei schreiben und schließlich die Ausgabe des einen Befehls als Eingabe für den nächsten verwenden. Auf diese Weise können Sie die einfachen Bausteine der Systembefehle zur Erledigung komplexer Aufgaben einsetzen.
Die StandardI/O-Kanäle
Die Standardbibliothek der Programmiersprache C kennt drei Standardkanäle (Streams) zur Ein- und Ausgabe (Input/Output oder kurz I/O):
- stdin ist die Standardeingabe. Sie ist normalerweise mit der Tastatur verknüpft.
- stdout, die Standardausgabe, wird per Voreinstellung auf die Konsole geleitet.
- stderr schließlich ist die Standard-Fehlerausgabe. Auch sie landet für gewöhnlich auf der Konsole. Vorteil: Wenn Sie stdout in eine Datei umleiten, werden Fehlermeldungen noch immer angezeigt.
Da Unix und andere Betriebssysteme in C geschrieben sind, besitzen auch sie diese Eigenschaften (unter Windows ist es beispielsweise genauso): Die Ein- und Ausgabeumleitung basiert auf einer Verknüpfung von stdin, stdout beziehungsweise stderr mit anderen Dateien oder Geräten.
Der Befehl ls dient beispielsweise dazu, den Inhalt des aktuellen Verzeichnisses auszugeben. Möchten Sie diesen Inhalt lieber in eine andere Datei schreiben, können Sie folgendermaßen vorgehen:
$ ls >inhalt.txt
In diesem einfachen Beispiel wird der Inhalt des aktuellen Verzeichnisses nicht auf den Bildschirm geschrieben, sondern in die Datei inhalt.txt. Diese Datei wird automatisch neu angelegt, falls sie noch nicht existiert, ansonsten wird sie überschrieben. Wenn Sie die Ausgabe eines Befehls lieber an eine bestehende Datei anhängen möchten, können Sie statt des einen >-Zeichens zwei verwenden (sollte die Datei noch nicht existieren, wird sie dadurch dennoch angelegt):
$ ls >>inhalt.txt
Auf ähnliche Weise können Sie die Eingabe für einen Befehl aus einer Datei lesen. Zum Beispiel gibt der Befehl grep alle Zeilen eines eingegebenen Textes zurück, in dem ein Suchmuster vorkommt. Falls Sie alle Zeilen der Datei inhalt.txt suchen möchten, die mindestens ein a enthalten, funktioniert das folgendermaßen:
$ grep a <inhalt.txt
Für den Befehl grep ist diese Schreibweise eigentlich überflüssig, da auch grep Muster Dateiname unterstützt wird – im vorliegenden Beispiel also:
$ grep a inhalt.txt
Eine interessante Variante der Eingabeumleitung ist das HIER-Dokument. Diese Art der Eingabe stammt nicht aus einer Datei, sondern nimmt alle eingegebenen Zeilen bis zu einer speziellen Markierung entgegen. Das folgende Beispiel sucht mithilfe von grep nach allen Zeilen in der Eingabe, die mindestens ein a enthalten:
% grep a <<ENDE
> Hallo
> liebe
> Welt
> ENDE
Die Ausgabe dieser eingegebenen Sequenz lautet folgendermaßen:
HalloDie Markierung ENDE bildet das Ende der Eingabe. Die grep-Suchmuster werden im nächsten Abschnitt behandelt.
Eine weitere Variante der Ein- und Ausgabeumleitung ist die sogenannte Pipe (»Röhre«). Es geht darum, die Ausgabe eines Befehls als Eingabe für den nächsten zu verwenden. Eine der gängigsten Kombinationen ist die Weiterleitung der umfangreichen Ausgabe bestimmter Befehle an einen Pager – ein Programm, das Inhalte seitenweise ausgibt. Der ursprüngliche Unix-Pager wird more genannt, die erheblich mächtigere Open-Source-Alternative heißt less (Anspielung auf »less is more«, »weniger ist mehr«).
Angenommen, der Inhalt des aktuellen Verzeichnisses ist länger als die Anzahl der Zeilen Ihres Terminals. In diesem Fall können Sie diesen Inhalt an less weiterleiten:
$ ls |less
Das Pipe-Zeichen | wird auf einer deutschen PC-Tastatur mit der Tastenkombination  +
+  erzeugt; auf dem Mac ist es die Tastenkombination +
erzeugt; auf dem Mac ist es die Tastenkombination +  .
.
Das Programm less kann auch den Inhalt einer Datei anzeigen und ist auf diese Weise ein komfortabler Ersatz für cat, das der Anzeige einer oder mehrerer Dateien im Terminal dient. Im Grunde ist ls |less also eine Kurzfassung für die beiden folgenden Einzelbefehle:
$ ls >temp.txt
$ less temp.txt
Auf ähnliche Weise lässt sich jede Pipe durch zwei Einzelbefehle ersetzen, wobei der zweite Befehl oft nicht direkt mit einem Dateinamen als Argument aufgerufen wird, sondern mit einer Eingabeumleitung.
Eine Pipe hat allerdings zwei bedeutende Vorteile gegenüber der Verwendung von einzelnen Befehlen: Erstens muss keine Zwischendatei erzeugt werden, und zweitens beginnt der zweite Befehl einer Pipe bereits zu arbeiten, wenn er die erste Zeile aus der Ausgabe des ersten Befehls erhält.
Eine weitere verbreitete Anwendung für Pipes besteht in der unmittelbaren Filterung einer Ausgabe mithilfe von grep. Das folgende Beispiel gibt nur diejenigen Dateien im aktuellen Verzeichnis aus, die die Zeichenfolge txt enthalten:
$ ls |grep txt
Hier noch ein Beispiel: Es reicht die Ausgabe von ls an das Kommando wc (Wortzähler) weiter; die Option -l sorgt dafür, dass nur Zeilen gezählt werden. Das Ergebnis ist somit die Anzahl der Einträge im aktuellen Verzeichnis:
$ ls |wc -l
Sie können mehrere Kommandos auch durch ein Semikolon getrennt hintereinanderschreiben. Dadurch werden sie einfach nacheinander ausgeführt. Das folgende Beispiel kommt sehr häufig vor. Die meisten Programme, die Sie selbst aus dem Sourcecode kompilieren können, verwenden diese Sequenz dafür:
# ./configure [Optionen]; make; make install
Ein Nachteil des Semikolons besteht darin, dass auch dann versucht wird, den nächsten Befehl auszuführen, wenn der vorherige fehlschlägt. Abhilfe schafft hier die Verknüpfung mithilfe von && (logisches Und) – der zweite Befehl wird dann nur bei Erfolg des ersten ausgeführt. Schreiben Sie die Sequenz also am besten wie folgt, um ein Programm unbeaufsichtigt zu kompilieren:
# ./configure [Optionen] && make && make install
Das Gegenteil besorgt die Verknüpfung durch || (logisches Oder) – hier wird der zweite Befehl nur dann ausgeführt, wenn der erste fehlschlägt.
Eine letzte Möglichkeit besteht darin, ein Kommando in Backticks (``) einzuschließen, um seine Ausgabe in einem anderen Zusammenhang zu verwenden. Hier ein Beispiel, das die Ausgabe von whoami (Name des aktuell angemeldeten Benutzers) in einen ganzen Satz integriert:
$ echo "Zurzeit ist `whoami` angemeldet."
Zurzeit ist sascha angemeldet.
7.1.6 Die wichtigsten Systembefehle
In Linux und andere Unix-Varianten wurden Unmengen von Systemprogrammen eingebaut. Es ist vollkommen aussichtslos, an dieser Stelle auch nur die Hälfte hiervon zu behandeln. In diesem Abschnitt lernen Sie stattdessen die wichtigsten Kommandos mit ihren gängigsten Optionen kennen. Weitere Linux- beziehungsweise Unix-Befehle werden in reinen Linux- oder Unix-Büchern behandelt; einige empfehlenswerte Titel zu diesem Thema werden in Anhang C, »Kommentiertes Literaturverzeichnis«, genannt.
Bevor es losgeht, sollten Sie sich einige wichtige Fakten über die meisten Unix-Systemprogramme merken:
- Im Erfolgsfall erhalten Sie keinerlei Rückmeldung, sondern nur den nächsten Prompt.
- Dateien werden standardmäßig gelöscht oder überschrieben, ohne zuvor nachzufragen.
- Die meisten Kommandos können mit einer Vielzahl von Optionen aufgerufen werden, die in der Regel aus einem Minuszeichen und einem Buchstaben (mit Unterscheidung von Groß- und Kleinschreibung) bestehen. Die GNU-Versionen der Tools kennen auch Optionen im Langformat – zwei Minuszeichen, gefolgt von einem ganzen Wort (oder mehreren durch weitere Minuszeichen getrennten Wörtern).
Arbeiten mit Dateien und Verzeichnissen
Einige der grundlegenden Befehle in einem Betriebssystem dienen der Manipulation von Dateien und Verzeichnissen. Wenn Sie eine Übersicht über die Grundbegriffe eines Linux-Dateisystems benötigen, lesen Sie bitte den Abschnitt »Das virtuelle Unix-Dateisystem« in Kapitel 5, »Betriebssystemgrundlagen«.
Alle Unix-Shells bieten die Möglichkeit, Datei- und Verzeichnisnamen in vielen Befehlen durch Muster anzugeben, die auf mehrere Dateien passen. In diesen Mustern gibt es die folgenden wichtigen Sonderzeichen (die in Dateinamen verboten oder zumindest problematisch sind):
- Das * ersetzt beliebig viele Zeichen. h*o steht beispielsweise für »hallo«, »hello« oder »ho«.
- Das ? steht für genau ein Zeichen. Zum Beispiel bezeichnet te?t sowohl »test« als auch »text«.
- Mehrere Zeichen in eckigen Klammern, wie [abc], bedeuten, dass genau eines dieser Zeichen gemeint ist. Durch einen Bindestrich können Bereiche wie a-z gebildet werden; mehrere Listen werden einfach hintereinandergeschrieben. Beispielsweise bedeutet die Liste [a-zA-Z0-9], dass alle Kleinbuchstaben, alle Großbuchstaben und alle Ziffern zulässig sind.
- Ein Ausrufezeichen vor der Liste in den eckigen Klammern bedeutet, dass jedes Zeichen außer den nachfolgenden Zeichen in dieser Liste zulässig ist. [!Bb] bedeutet etwa, dass auf keinen Fall ein B erlaubt ist – weder ein groß- noch ein kleingeschriebenes.
- Eine durch Kommata getrennte Liste von Zeichenketten in geschweiften Klammern bedeutet, dass eine dieser Zeichenketten erwartet wird. Zum Beispiel bedeutet {info,hinweis,hilfe}.txt, dass eine der drei Dateien info.txt, hilfe.txt oder hinweis.txt gesucht wird.
- Durch ein Pipe-Zeichen (|) können Sie schließlich mehrere Muster angeben, die durch »Oder« verknüpft werden. Trifft eines dieser Muster auf eine Datei zu, passt sie zum Gesamtmuster. Der Ausdruck b*|info* bedeutet beispielsweise: alle Dateien, die mit »b« oder mit »info« beginnen.
Beachten Sie bitte, dass die »Dateierweiterung« (die Abkürzung hinter dem letzten Punkt wie etwa txt) unter Unix ein normaler Bestandteil des Dateinamens ist, falls Sie die Dateimuster unter Windows kennen sollten. In einem Unix-Befehl steht * für alle Dateien. Unter Windows ist ein * dagegen nur der Platzhalter für Dateien ohne Erweiterung, während *.* dort für alle Dateien steht (außer in der im vorigen Kapitel beschriebenen Windows PowerShell).
Diese einfachen Suchmuster für Dateien werden übrigens nicht mit dem bereits erwähnten Befehl grep verwendet. Die dort zulässigen Muster bieten noch erheblich mehr Möglichkeiten.
Die folgende Übersicht zeigt die gängigsten Linux-Datei- und Verzeichnisbefehle mit ihren wichtigsten Optionen:
- cp (steht für copy) kopiert eine oder mehrere Dateien an den angegebenen Ort. Die Syntax ist grundsätzlich
folgende:
cp Quelle Ziel
Die Quelle kann eine einzelne Datei oder ein Muster sein; Sie können alternativ auch einen Pfad angeben. Das Ziel ist entweder ein einzelner Dateiname (falls Sie nur eine Datei kopieren) oder ein Verzeichnis, falls im Zielordner bereits ein Verzeichnis mit diesem Namen existiert oder falls Sie als Quelle keine einzelne Datei, sondern ein Muster angegeben haben. Das folgende Beispiel kopiert die Datei hallo.txt in eine neue Datei namens hi.txt:
$ cp hallo.txt hi.txt
Das nächste Beispiel kopiert alle Dateien aus dem Verzeichnis briefe in das Verzeichnis dokumente, das im gleichen Verzeichnis liegt wie briefe:
$ cp briefe/* dokumente
- mv (move) dient dazu, Dateien umzubenennen oder in ein anderes Verzeichnis zu verschieben.
Die Syntax lautet folgendermaßen:
mv Quelle Ziel
Die Quelle ist wieder eine einzelne Datei oder ein Muster, das Ziel ist ein völlig neuer Name oder der Name eines bestehenden Verzeichnisses.
Die folgende Anweisung benennt die Datei vorher.txt in nachher.txt um:
$ mv vorher.txt nachher.txt
Wenn Sie als Quelle ein Muster statt einer einzelnen Datei angeben, muss das Ziel ein bestehendes Verzeichnis sein. Sie können mehrere Dateien auf einmal nicht umbenennen, sondern nur verschieben.
- rm (remove) löscht die angegebene Datei, und zwar endgültig. Eine Einrichtung wie der Windows-
oder Mac-Papierkorb ist nicht vorgesehen – lediglich einzelne Desktop-Manager wie
KDE oder GNOME sind damit ausgestattet.
Das folgende Beispiel löscht alle Dateien aus dem aktuellen Verzeichnis, deren Name nicht mit a beginnt:
$ rm [!a]*
rm löscht Dateien nur im aktuellen Verzeichnis, aber nicht in dessen Unterverzeichnissen. Wenn Sie auch die Inhalte der Unterverzeichnisse löschen möchten, müssen Sie die Option -r (recurse) einsetzen. Noch effizienter (und gefährlicher!) ist die zusätzliche Option -f (force), die das Löschen schreibgeschützter Dateien erzwingt. Der folgende Befehl löscht alle Dateien im aktuellen Verzeichnis und alle Unterverzeichnisse und sollte nur mit äußerster Vorsicht eingesetzt werden:
$ rm -rf *
Wie hier können Sie übrigens auch bei den meisten anderen Befehlen mehrere Optionen hinter einem einzelnen Minuszeichen platzieren.
Beachten Sie, dass es sich beim Löschen, Umbenennen oder Verschieben um Schreibzugriffe handelt, die Sie nur ausführen dürfen, wenn Sie Schreibrechte für die jeweiligen Verzeichnisse und Dateien besitzen.
- ls (list) zeigt den Inhalt des aktuellen oder des angegebenen Verzeichnisses an, das
heißt alle enthaltenen Dateien und Unterverzeichnisse. Wenn Sie ein Muster angeben,
wird es als Filter verwendet. Existieren Dateien, deren Namen zu diesem Muster passen,
dann werden nur diese angezeigt. Andernfalls werden zusätzlich zum aktuellen Verzeichnis
auch die Inhalte der Unterverzeichnisse angezeigt, auf deren Namen das Muster passt.
Die folgende Anweisung zeigt beispielsweise alle Dateien an, die mit b beginnen. Falls es keine gibt, werden alternativ die Inhalte aller Verzeichnisse angezeigt, die mit b anfangen:
$ ls b*
Eine wichtige Option dieses Befehls ist -l (long), die statt der einfachen Namen ausführliche Informationen über jeden Verzeichniseintrag ausgibt. Auch -a (all) wird relativ häufig verwendet, weil es versteckte Dateien und Verzeichnisse einblendet, das heißt diejenigen, deren Namen mit einem Punkt beginnen.
- pwd (print working directory) gibt den vollständigen Pfad des aktuellen Arbeitsverzeichnisses an. Dies ist beispielsweise nützlich, um den tatsächlichen Pfad des eigenen Home-Verzeichnisses zu ermitteln, der im Prompt durch ~ abgekürzt wird.
- cd (change directory) wechselt in das angegebene Arbeitsverzeichnis. Sie können den gewünschten Pfad entweder
relativ zum aktuellen Arbeitsverzeichnis oder absolut durch einen vorangestellten
Slash (/) angeben. Die folgende Anweisung wechselt beispielsweise aus /home/user/dokumente in das Verzeichnis /home/user/briefe:
user@rechner: ~/dokumente $ cd ../briefe
user@rechner: ~/briefe $Das folgende Beispiel wechselt dagegen mithilfe einer absoluten Angabe von /home/user/dokumente nach /etc:
user@rechner: ~/dokumente $ cd /etc
user@rechner: /etc $ - mkdir legt ein neues Verzeichnis mit dem angegebenen Pfad an. So richtet etwa die folgende
Anweisung unterhalb des aktuellen Verzeichnisses das neue Verzeichnis test ein:
$ mkdir test
Beachten Sie, dass bei der Angabe eines mehrgliedrigen Pfads alle Verzeichnisse außer dem hintersten bereits existieren müssen. Die Option -p (parents) erzeugt dagegen auch verschachtelte Pfade. Das folgende Beispiel legt im aktuellen Verzeichnis die ineinander verschachtelten Verzeichnisse neu, texte, briefe an:
$ mkdir -p neu/texte/briefe
- rmdir (remove directory) löscht Verzeichnisse, allerdings nur leere. Zum Löschen verschachtelter Verzeichnisbäume wird rm mit der Option -r verwendet.
- chmod (change mode) ändert die Zugriffsrechte für Dateien und Verzeichnisse. Das Konzept der Dateizugriffsrechte
wurde in diesem Kapitel bereits angesprochen. Es gibt grundsätzlich zwei Möglichkeiten,
Rechte für die gewünschten Dateien oder Verzeichnisse anzugeben: symbolisch oder numerisch.
Die symbolische Schreibweise verwendet zunächst einen Buchstaben für die Benutzerart, für die ein Recht geändert werden soll: u für den Eigentümer (user), g für die Gruppe (group), o für andere Benutzer (others) und a für alle genannten auf einmal. Darauf folgt ein +, um ein bestimmtes Recht einzuräumen, ein -, um es zu entfernen, oder ein =, um die angegebenen Rechte zu setzen und die anderen zu entfernen. Zum Schluss werden die eigentlichen Rechte selbst angegeben: r für Lesen (read), w für Schreiben (write) und x für Ausführen (execute).
Die folgende Anweisung erlaubt beispielsweise allen Benutzern das Lesen der Datei inhalt.txt:
$ chmod a+r inhalt.txt
Numerische Angaben setzen dagegen den gesamten Rechteblock für die Datei auf einmal: Die Stellen einer dreistelligen Oktalzahl (gekennzeichnet durch eine vorangestellte Null) geben von links nach rechts die Zugriffsrechte für den Besitzer, die Gruppe und alle anderen an. Der Wert jeder Stelle ist dabei die Summe der Rechte, die gewährt werden: 4 für Lesen, 2 für Schreiben und 1 für Ausführen.
Das folgende Beispiel erlaubt dem Eigentümer das Lesen, Schreiben und Ausführen, allen anderen nur das Lesen und Ausführen des Verzeichnisses test:
$ chmod 0755 test
Die Option -R (großgeschrieben!) führt die gewünschte Änderung nicht nur im aktuellen Verzeichnis durch, sondern auch in allen Unterverzeichnissen.
- chown (change owner) weist der angegebenen Datei einen neuen Eigentümer zu. Die Syntax des Befehls ist
folgende:
chown User Datei(-muster)
Der User muss ein existierender Benutzer sein; außerdem können Sie diese Änderung nur durchführen, wenn Sie selbst Schreibrechte an dieser Datei haben. Das folgende Beispiel teilt die Datei info dem Benutzer user zu:
$ chown user info
- chgrp (change group) ändert die Gruppe, zu der eine Datei gehört, und funktioniert genau wie chown.
Textanzeige und Textmanipulation
Viele der Arbeiten, die Sie im Betriebssystem durchführen, haben in irgendeiner Weise mit der Manipulation von Textdateien zu tun. In diesem Abschnitt werden einige der wichtigsten Befehle vorgestellt, die Ihnen die Arbeit mit solchen Dateien ermöglichen.
- Der bereits erwähnte Befehl echo gibt sämtlichen folgenden Text auf der Konsole aus. Sie können den gesamten Text
oder einen Teil davon in Anführungszeichen setzen, müssen es aber nicht. Wenn Sie
doppelte ("") oder gar keine Anführungszeichen verwenden, werden Variablen mit führendem Dollarzeichen
durch ihren aktuellen Wert substituiert oder Befehle in Backticks ausgeführt. Beispiele:
$ echo Hallo, $USER!
Hallo, sascha!
$ echo Dateien im aktuellen Verzeichnis: `ls -m`
Dateien im aktuellen Verzeichnis: test.txt, hallo.sh, ...Die ls-Option -m gibt übrigens nur die Dateinamen durch Komma getrennt hintereinander aus.
Einfache Anführungszeichen verhindern dagegen die Substitution:
$ echo '`Backticks` liefern die Befehlsausgabe'
`Backticks` liefern die Befehlsausgabe
$ echo '$USER' ist zurzeit $USER
$USER ist zurzeit saschaDie Option -n verhindert den Zeilenumbruch nach der Ausgabe:
$ echo -n "Hier kommt der Prompt: "
Hier kommt der Prompt: $ - cat (catalog) ist der wichtigste aller Textdatei-Befehle: Er zeigt einfach den Inhalt der Datei
an. Wenn Sie durch Leerzeichen getrennt eine Liste von Dateien angeben (oder ein Muster),
werden die Inhalte aller genannten Dateien hintereinander angezeigt. Dies ist übrigens
eine einfache Möglichkeit, mehrere Textdateien in eine einzige zusammenzufassen. Die
folgende Anweisung schreibt die Dateien teil1 und teil2 in eine neue Datei namens kapitel:
$ cat teil1 teil2 >kapitel
Sie können cat mithilfe der Ausgabeumleitung und mit einem HIER-Dokument sogar als einfachen Editor für eine neue Textdatei verwenden. Allerdings können Sie die einzelnen Zeilen nach dem Abschluss durch
nicht mehr ändern. Die folgende Anweisung startet die Eingabe der Datei neu.txt, der Befehl ENDE schließt sie ab:
$ cat > neu.txt << ENDE
> Neuer Text
> Noch mehr Text
> ENDE - Der Befehl head Textdatei zeigt nur den Beginn einer Datei an; standardmäßig die ersten zehn Zeilen. Mit der
Option -Anzahl können Sie die Zeilenzahl auch wählen. Das folgende Beispiel gibt die ersten sieben
Zeilen der Datei test.txt aus:
$ head –7 test.txt
- Das Kommando tail zeigt umgekehrt das Ende einer Datei an. Dies ist ideal, um in einer Log-Datei nach
einem kürzlich aufgetretenen Fehler zu suchen. Hier ein Beispiel, das die letzten
20 Zeilen der Haupt-Log-Datei /var/log/messages ausgibt:
$ tail –20 /var/log/messages
Die Option -f zeigt die letzten zehn Zeilen an und hält danach die Ausgabe offen, um jede neu hinzukommende Zeile automatisch auszugeben.
- less ist die erweiterte GNU-Version des Unix-Pagers more. Das Programm gibt seine Eingabedaten bildschirmseitenweise aus. Das folgende Beispiel
gibt die Datei roman auf diese Weise aus:
$ less roman
Wenn das untere Ende des Bildschirms beziehungsweise des Terminalfensters erreicht ist, erscheint ein entsprechender Hinweis. An dieser Stelle haben Sie verschiedene Möglichkeiten, unter anderem folgende:
- Die Leertaste blättert eine ganze Bildschirmseite weiter.
- blättert nur eine einzelne Zeile weiter.
- blättert eine Bildschirmseite zurück.
- beendet less.
Weitere Optionen finden Sie zuvor in der Beschreibung zu man, da es die Manpages mithilfe von less anzeigt.
Statt eine oder mehrere Dateien als Parameter anzugeben, wird less auch häufig über eine Pipe zur seitenweisen Ausgabe der Ergebnisse anderer Befehle eingesetzt. Das folgende Beispiel gibt den Inhalt der ausführlichen Verzeichnisanzeige ls-l seitenweise aus:
$ ls -l |less
- grep (General Regular Expression Print) sucht in Dateien oder in seiner Eingabe nach Mustern und gibt nur diejenigen Zeilen
aus, die das entsprechende Muster enthalten. Bei den verwendeten Mustern handelt es
sich um sogenannte reguläre Ausdrücke (Regular Expressions, RegExp). Diese mächtige Syntax für die Formulierung von Suchmustern
wird in zahlreichen Programmiersprachen, Editoren und Tools verwendet. In Kapitel 10, »Konzepte der Programmierung«, werden die RegExp-Optionen der Programmiersprachen
Perl und Ruby ausführlich vorgestellt.
Wenn Sie beispielsweise in der Datei test nach Zeilen suchen möchten, die das Wort »hallo« enthalten, funktioniert dies folgendermaßen:
$ grep hallo test
Die Option -r erlaubt die rekursive Suche im aktuellen Verzeichnis und allen Unterverzeichnissen. Dabei wird jeweils der Pfad der Datei angezeigt, in der das gesuchte Muster gefunden wird. Das folgende Beispiel sucht in allen Dateien des aktuellen Verzeichnisbaums nach dem Wort »Linux«:
$ grep -r Linux *
Mit der Option -i sorgen Sie dafür, dass bei der Suche nicht zwischen Groß- und Kleinschreibung unterschieden wird; der vorige Befehl lautet in diesem Fall so:
$ grep -ri linux *
Alternativ wird grep häufig über eine Pipe als Filter eingesetzt. Möchten Sie zum Beispiel alle Dateien im aktuellen Verzeichnis angezeigt haben, deren Name mit a beginnt, können Sie Folgendes eingeben:
$ ls |grep ^a
Beachten Sie, dass es bei den Mustern größere Unterschiede zu den Dateimustern der meisten Befehle gibt; RegExp-Muster sind erheblich vielseitiger als Letztere. Tabelle 7.2 zeigt eine Übersicht der wichtigsten.
Wenn Sie irgendeins der Zeichen aus der Tabelle als Literal benötigen, also als tatsächliches Zeichen in einem Text, müssen Sie ihm einen Backslash (\) voranstellen. \+ steht beispielsweise für ein Pluszeichen. Derartige Konstrukte werden in der Shell und in vielen Programmiersprachen als Escape-Sequenzen bezeichnet.
Angenommen, Sie suchen in einem Text nach deutschen Postleitzahlen. Das passende Muster lautet [0-9]{5}, weil genau fünf Ziffern (Zahlen zwischen 0 und 9) benötigt werden. Wenn Sie sicher sind, dass die Postleitzahl jeweils am Anfang der Zeile steht, können Sie präziser ^[0-9]{5} schreiben.
Wichtig ist, dass * und ? nicht dasselbe bedeuten wie bei den Dateimustern: Sie beziehen sich stets auf das links daneben stehende Zeichen oder Teilmuster und geben an, wie oft es vorkommen darf.
Das folgende Beispiel zeigt, wie Sie in der Datei adressen.txt nach Personen suchen können, die »Meier« heißen, und zwar in allen erdenklichen Schreibweisen:
grep M[ae][iy]e?r adressen.txt
Der reguläre Ausdruck bedeutet: Zuerst kommt ein M, dann ein a oder e, anschließend ein i oder y, dann ein e oder auch nicht und zum Schluss ein r. Dieses Suchmuster findet die Varianten »Maier«, »Mayer«, »Mayr«, »Meier« und »Meyer« sowie drei weitere, die aber wohl nicht häufig in einer Adressliste auftauchen (»Mair«, »Meir« und »Meyr«).
- diff vergleicht die Inhalte zweier Textinhalte miteinander. Als Argumente werden die Namen der beiden Dateien genannt; die Ausgabe besteht aus denjenigen Zeilen, die in den beiden Dateien unterschiedlich sind. Dies ermöglicht die Analyse der Unterschiede zwischen verschiedenen Versionen eines Dokuments. Außerdem können Sie eine diff-Datei als Update für eine Datei auf eine neuere Version (einen sogenannten Patch) verbreiten. Mit dem Kommando patch kann ein Benutzer sie dann auf die alte Datei anwenden.
- wc (word count) zählt die Zeichen, Wörter und Zeilen in einer Textdatei. Standardmäßig werden alle drei Werte angezeigt; alternativ kann die Ausgabe mithilfe der Optionen -c (characters), -w (words) oder -l (lines) auf einen von ihnen beschränkt werden. Sie können den Befehl auch über eine Pipe auf eine beliebige Ausgabe anwenden.
Befehle zur Systemverwaltung
Die Befehle in diesem Abschnitt sind wichtig für die Wartung und Verwaltung des Betriebssystems.
- mount wurde in Kapitel 5, »Betriebssystemgrundlagen«, bereits angesprochen. Der Befehl hängt einen Datenträger
in den Verzeichnisbaum ein. Anders können Datenträger nicht verwendet werden. Die
grundlegende Syntax lautet folgendermaßen:
mount [Dateisystemtyp] Gerätedatei Verzeichnis
Das angegebene Verzeichnis muss existieren und leer sein – notfalls müssen Sie mithilfe von mkdir ein neues erzeugen. Die wichtigsten Gerätedateien – alle im Verzeichnis /dev – sind folgende:
- hda bis hdd sind die vier EIDE-Geräte in der Reihenfolge Primary Master, Primary Slave, Secondary Master und Secondary Slave. Falls es sich um Festplatten handelt, muss zusätzlich die Nummer der gewünschten Partition angegeben werden (hda1 ist beispielsweise die erste Partition der ersten Festplatte).
- cdrom ist eine alternative Methode, das CD-ROM-Laufwerk anzusprechen.
- sda, sdb und so weiter sind die entsprechenden SCSI-Festplatten in der Reihenfolge ihrer SCSI-IDs. Auch USB-Sticks und externe Festplatten besitzen meist sd*-Gerätenamen.
- fd0 ist das Diskettenlaufwerk. Theoretisch steht fd1 für das zweite Laufwerk, allerdings benutzt kaum noch jemand zwei Diskettenlaufwerke (die meisten aktuellen Rechner haben gar keines mehr).
Das folgende Beispiel bindet die aktuell im Diskettenlaufwerk befindliche Diskette als Verzeichnis /disk in das Dateisystem ein:
$ mount /dev/fd0 /disk
Die Datei /etc/fstab enthält übrigens eine Liste derjenigen Laufwerke, die beim Systemstart automatisch gemountet werden. Moderne Linux-Distributionen mounten übrigens auch CDs, DVDs, USB-Sticks oder externe Festplatten beim Einlegen oder Anschließen automatisch, oft unter dem Pfad /media/Datenträgername.
- umount entfernt die Verknüpfung mit einem bestimmten Laufwerk wieder. Vorher wird noch dafür
gesorgt, dass alle Daten geschrieben werden, die eigentlich auf dieses Laufwerk gehören,
sich aber zurzeit im RAM-Cache befinden. Vor dem Entfernen von Wechseldatenträgern
sollten Sie umount auf jeden Fall aufrufen.
Als Argument für den Befehl kann sowohl das Verzeichnis angegeben werden, in dem der gewünschte Datenträger gemountet ist, als auch die Gerätedatei selbst.
- du (disk usage) gibt in Kilobyte an, wie viel Speicher in den angegebenen Verzeichnissen belegt
ist.
Die Option -c gibt zusätzlich eine Gesamtsumme für die verschiedenen Verzeichnisse aus, während -h (human-readable) das Ganze in angenehmerer Form darstellt.
- fsck (file system check) überprüft den angegebenen Datenträger auf Fehler. Als Argument muss eine Gerätedatei
angegeben werden. Vor jedem Reparaturversuch wird nachgefragt.
Beim Systemstart wird fsck in regelmäßigen Abständen (zum Beispiel jedes zwanzigste Mal) aufgerufen, um eine gelegentliche Prüfung zu gewährleisten. Außerdem wird es auf jeden Fall nach einem Systemabsturz gestartet.
Moderne Linux-Dateisysteme wie ext4 (das Extended File System 4) besitzen eine sogenannte Journaling-Funktionalität: Es wird ständig über Änderungen an Dateien und Verzeichnissen Buch geführt. Nach einem Absturz kann daraus der letzte Zustand des Dateisystems rekonstruiert werden.
- mkfs (make file system) dient dem Formatieren eines Datenträgers mit einem bestimmten Dateisystem. Der gewünschte
Typ des Dateisystems kann mithilfe der Option -t angegeben werden. Beispiele sind etwa das traditionelle Linux-Dateisystem ext2 sowie die neueren Typen ext3 oder ext4. Der Datenträger wird als Gerätedatei oder über sein Mount-Verzeichnis angegeben.
Im Grunde handelt es sich um einen Starter für die konkreten Formatierprogramme der einzelnen Dateisysteme wie mke2fs, mke3fs, mke4s oder mkisofs (Letzteres erzeugt ISO-9660-Images, die zum Brennen auf CD verwendet werden).
- date dient der Ausgabe und der Änderung von Systemdatum und Systemuhrzeit. Wie Sie in
Kapitel 3, »Hardware«, erfahren haben, enthalten PC-Mainboards eine batteriegepufferte Uhr.
Wenn Sie Datum und Uhrzeit einfach lesen möchten, genügt die Eingabe von date. Alternativ geben Sie hinter einem Pluszeichen ein Format an, in dem eine Reihe von Formatangaben für die einzelnen Komponenten von Datum und Uhrzeit steht. Alle diese Angaben beginnen mit einem Prozentzeichen. Die wichtigsten sind in Tabelle 7.3 aufgelistet.
Sehen Sie sich als Beispiel den folgenden Befehl an:
$ date +"Es ist jetzt %H:%M:%S Uhr."
Die Ausgabe sieht etwa folgendermaßen aus:
Es ist jetzt 17:52:31 Uhr.
Sie können die Bestandteile von Datum und Uhrzeit also in einem beliebigen Ausgabetext verwenden.
Falls Sie Datum und Uhrzeit ändern möchten, müssen Sie statt des Formats eine Zeitangabe hinzufügen. Eine solche Angabe hat das folgende Format:
MMDDhhmm[YY]YY[.ss]
Es werden also nacheinander der zweistellige Monat, der zweistellige Tag, die zweistellige Stunde im 24-Stunden-Format, die zweistellige Minute, das zwei- oder vierstellige Jahr und optional die durch einen Punkt abgetrennten zweistelligen Sekunden angegeben. Das folgende Beispiel setzt Datum und Uhrzeit auf den 09. April 2013, 16:40 Uhr:
$ date 040916402013
- useradd erstellt ein neues Benutzerkonto unter Linux. Auf den meisten anderen Unix-Systemen
gibt es sehr ähnliche Kommandos, die manchmal anders heißen. Standardmäßig ist das
Home-Verzeichnis dieses Benutzers /home/Username. Mithilfe der Option -d Pfad können Sie ein anderes Verzeichnis angeben. In jedem Fall sorgt die Option -m dafür, dass das Home-Verzeichnis neu angelegt wird, falls es noch nicht existiert.
Die numerische User-ID wird standardmäßig automatisch eingestellt; es wird der erste freie Wert größer oder gleich 100 gewählt. UIDs unter 100 sind für Systemkonten vorgesehen, das heißt für Benutzerkonten, die für die Ausführung von System- und Serverdiensten verwendet werden; die 0 steht für root. Wenn Sie die UID manuell angeben möchten, funktioniert das mithilfe von -u UID. Falls die angegebene User-ID bereits existiert, erscheint eine Fehlermeldung, es sei denn, Sie geben zusätzlich die Option -o an, die den bisherigen User mit dieser UID überschreibt.
Mithilfe der Option -g Gruppe wird die Gruppe angegeben, der der Benutzer standardmäßig angehören soll – ohne Angabe wird automatisch users eingestellt. Mithilfe von-G Gruppe1, Gruppe2,... können Sie eine durch Kommata getrennte Liste weiterer Gruppen angeben, denen der Benutzer zusätzlich angehören soll. Diese Liste darf keine Leerzeichen enthalten.
Die Option -s Pfad gibt die Shell an, die dem User präsentiert werden soll; der Standardwert ist /bin/bash.
Das folgende Beispiel zeigt, wie das Verzeichnis /home/neuer angelegt wird und wie Sie anschließend den Benutzer neuer mit der Log-in-Shell /bin/tcsh einrichten können:
# mkdir /home/neuer
# useradd -g users -s /bin/tcsh neuer - userdel Benutzername entfernt den angegebenen Benutzer.
- groupadd fügt unter Linux eine neue Gruppe hinzu. Die einzige Option ist -g GID, mit deren Hilfe Sie die (ansonsten automatisch vergebene) Group-ID manuell einstellen können. Wie bei useradd dient in diesem Zusammenhang die Option -o dazu, eine eventuell bestehende Gruppe mit derselben Group-ID zu überschreiben.
- passwd dient zum Ändern von Passwörtern. Wenn Sie den Befehl ohne Argument aufrufen, dient
er zum Ändern Ihres eigenen Passworts: Sie müssen zunächst Ihr altes und anschließend
zweimal hintereinander das neue Passwort eingeben. Die Eingabe wird jeweils nicht
angezeigt.
Eine weitere Möglichkeit, die dem User root vorbehalten ist, besteht darin, passwdUsername aufzurufen, um das Passwort eines anderen Benutzers zu ändern. Sie müssen das alte Passwort dieses Users nicht kennen, sondern werden nur aufgefordert, zweimal ein neues einzugeben. Beachten Sie die in diesem Kapitel bereits gegebenen Informationen über sichere Passwörter. Der Befehl passwd gibt zwar bei vielen zu einfachen Passwörtern die Warnmeldung »Bad Password. Too simple« aus, akzeptiert das Passwort aber dennoch.
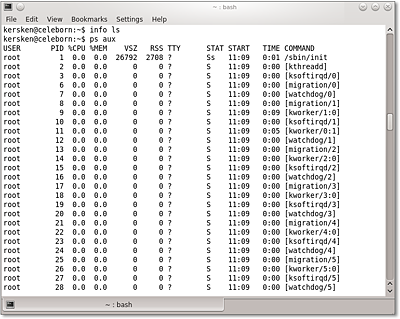
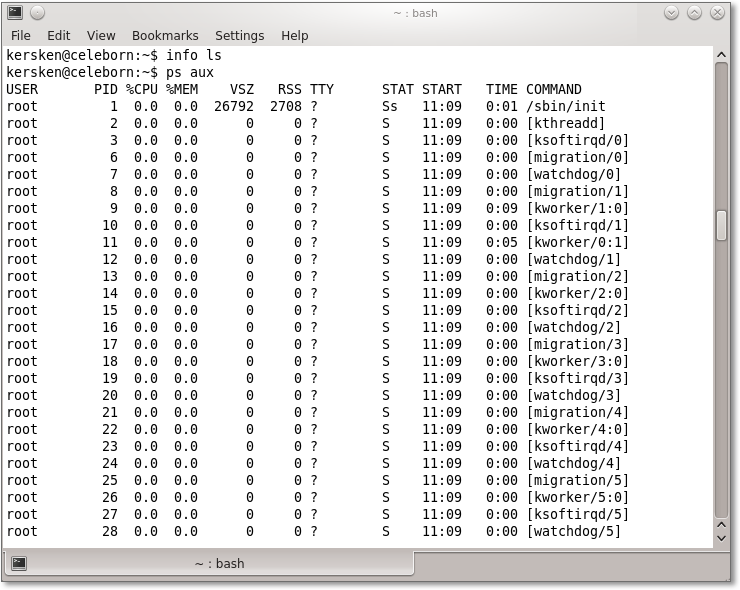
- ps gibt eine Tabelle aller laufenden Prozesse aus. Falls Sie keine Parameter angeben,
werden nur die Prozesse des aktuellen Terminals angezeigt. Für eine vollständige Liste
aller Prozesse müssen Sie ps aux verwenden. Abbildung 7.6 zeigt ein Beispiel für die Ausgabe dieses Befehls.
Die wichtigste Information, die Sie der Tabelle entnehmen können, sind die PIDs der einzelnen Prozesse, weil Sie sie verwenden können, um einem Prozess mithilfe des Befehls kill ein Signal zu senden.
Die meisten Prozesse, die Sie in der Liste sehen, sind keine Programme, die Sie manuell gestartet haben. Viele von ihnen laufen unbemerkt im Hintergrund und stellen ihre Dienste bestimmten Anwendungen zur Verfügung. Diese Prozesse werden Daemons genannt, ihre Dateinamen enden meist auf d: Beispielsweise ist syslogd der im weiteren Verlauf des Kapitels beschriebene Protokoll-Daemon, der über die wichtigsten Ereignisse Buch führt.
- Eine interessante Variante von ps ist pstree: Statt ausführlicher Informationen über die einzelnen Prozesse werden nur deren Namen angezeigt, dafür aber in einem Baumdiagramm. Auf diese Weise können Sie die Hierarchie von Elternprozessen und ihren Kindern ermitteln.
- Wenn Sie den Eindruck haben, dass der Rechner besonders langsam läuft, können Sie
das Kommando top eingeben – es zeigt eine Live-Statistik der laufenden Prozesse an, geordnet nach
ihrem prozentualen CPU-Verbrauch. Mit wird das Programm wieder beendet.
- kill dient dazu, einem Prozess ein Signal zu senden. Das gewünschte Signal wird dabei
hinter der Option -s angegeben; entweder numerisch oder mit seinem Namen. Wichtige Signale sind beispielsweise
TERM zum regulären Beenden, KILL für einen erzwungenen Abbruch oder INT für eine Unterbrechung (Interrupt). Wenn Sie kein Signal angeben, wird automatisch
TERM gesendet. Der Befehl kill-l gibt eine Liste sämtlicher Signale aus, die Ihre Version von kill unterstützt.
Der Prozess wird durch seine numerische PID angegeben, wie sie von ps zurückgegeben wurde. Viele Anwendungen, besonders Daemons, schreiben ihre aktuelle PID in eine PID-Datei, entweder unter /var/run/Programmname.pid oder in einem anwendungsspezifischen Verzeichnis wie /usr/local/Programmname/logs. Diese Datei können Sie auslesen und ihren Inhalt in Backticks (``) an kill weiterreichen. Das folgende Beispiel beendet auf diese Weise einen unter /usr/local/apache2 installierten Apache-Webserver:
# kill -TERM `cat /usr/local/apache2/logs/httpd.pid`
Als gewöhnlicher Benutzer können Sie nur Prozesse beenden, die unter Ihrer User-ID laufen, für alle anderen benötigen Sie root-Rechte.
- shutdown fährt das Betriebssystem herunter oder startet es neu. Für das Herunterfahren wird die Option -h (halt) verwendet, für einen Neustart -r (restart). Dahinter wird angegeben, wann die Aktion durchgeführt werden soll. Dafür stehen
drei mögliche Optionen zur Verfügung:
- als Uhrzeit im Format hh:mm, zum Beispiel 13:45
- als Anzahl von Minuten in der Schreibweise +m, etwa +5
- now (jetzt sofort)
Für den Befehl benötigen Sie root-Rechte. Das folgende Beispiel fährt den Rechner sofort herunter:
$ shutdown -h now
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen




