


16.17 Blockweise lesen und schreiben – »fread()« und »fwrite()« 

Diese beiden Funktionen lassen sich nicht so recht in ein Thema der Datei-E/A einordnen – weder in den höheren Standardfunktionen (High Level) noch in den niedrigeren Funktionen (Low-Level). Mit fread() und fwrite() wird eine Datei nicht als strukturierte Textdatei und auch nicht als unformatierter Bytestrom betrachtet. Die Dateien werden im Binärmodus bearbeitet und haben eine feste Satzstruktur. Das heißt, die Funktionen fread() und fwrite() tun nichts anderes, als ganze Blöcke binär zu lesen und zu schreiben.
| Hinweis |
|
Die Bezeichnungen Textmodus und Binärmodus können hierbei recht verwirrend sein. ANSI C erlaubt beide Möglichkeiten, eine Datei zu öffnen. Informationen können somit im Binärmodus oder Textmodus geschrieben oder gelesen werden. Eine Textdatei beispielsweise können Sie also im Binärmodus öffnen. Ebenso lässt sich ein Text im Binärmodus abspeichern. Sie können auch die Funktion fgetc() oder getc() verwenden, um eine Datei mit binären Daten zu kopieren. |
Das Gute an diesen beiden Funktionen ist ihre einfache Anwendung. Der Nachteil ist aber, dass die Daten der Datei, die fwrite() schreibt, nicht portabel, sondern plattformabhängig sind. Wollen Sie zum Beispiel mit diesen Funktionen Hauptspeicherinhalte direkt in eine Datei schreiben, könnten aufgrund eines anderen Alignments Probleme auftreten. Dies kommt daher, weil ein Member-Alignment in anderen Strukturen eine andere Byte-Reihenfolge bei Ganzzahlen oder eine unterschiedliche interne Darstellung von Fließkommazahlen haben könnte. Dieses Problem kann schon bei unterschiedlichen Compilern auftreten! Ist es also wichtig, dass die Daten auch auf anderen Systemen gelesen werden können, haben Sie folgende zwei Möglichkeiten:
- Die bessere Lösung wäre es, eine einfache ASCII-Textdatei zu verwenden, die mit fprintf() geschrieben und mit fscanf() gelesen wird. Ähnlich wird übrigens auch bei Netzwerkprotokollen vorgegangen. Zwar sind Textdateien meistens größer, und die Ein-/Ausgabe läuft ein wenig langsamer ab, aber der Vorteil, die einfachere Handhabung der Daten, macht diese Nachteile wieder wett.
- Sie überprüfen, ob es sich dabei um eine Big-Endian- oder Little-Endian-Maschine handelt.
Diese Funktionen ergänzen das Sortiment der Lese- und Schreibfunktionen hervorragend. Denn mit fgets() und fputs() lassen sich, wegen der besonderen Bedeutung der Zeichen '\0' und '\n' in ihnen, schlecht ganze Blöcke von Daten lesen bzw. schreiben. Ebenso ist es nicht sinnvoll, Daten Zeichen für Zeichen zu verarbeiten, wie dies bei den Funktionen fputc() und fgetc() geschieht. Außerdem ist es naheliegend, dass sich diese beiden Funktionen hervorragend zum Lesen und Schreiben von Strukturen eignen.
| Hinweis |
|
Da fread() und fwrite() nicht mit Zeichen bzw. Strings arbeiten, gibt es keine Funktion für breite Zeichen zu ihnen. |
16.17.1 Blockweise lesen – »fread()«
Die Syntax der Funktion lautet wie folgt:
size_t fread(void *puffer, size_t blockgroesse, size_t blockzahl, FILE *datei);
fread() liest blockzahl-Speicherobjekte, von denen jedes die Größe von blockgroesse Bytes hat, aus dem Stream datei, der zuvor geöffnet wurde, in die Adresse von puffer. Für puffer muss dementsprechend viel Platz zur Verfügung stehen. Der Rückgabewert ist die Anzahl der gelesenen Speicherobjekte. Ist die Anzahl kleiner als blockzahl, wurde entweder das Dateiende erreicht, oder es trat ein Fehler auf.
| Hinweis |
|
size_t ist ein primitiver Systemdatentyp, der in der Headerdatei <stddef.h> definiert ist. Der maximale Wert des Typ ist implementierungsabhängig. Meistens ist dieser Typ allerdings als unsigned int implementiert). |
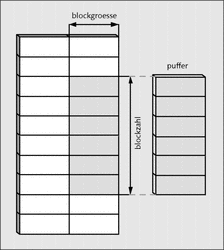
Abbildung 16.6 Blockweises Lesen mit »fread()«
Nehmen wir an, wir haben eine Datei namens wert.dat, deren Inhalte aus Integerwerten bestehen. Werden z. B. die ersten zehn Werte benötigt, sieht der Quellcode folgendermaßen aus:
/* fread.c */ #include <stdio.h> #include <stdlib.h> int main(void) { int puffer[10]; FILE *quelle; int i; quelle = fopen("wert.dat", "r+b"); if(quelle != NULL) fread(&puffer, sizeof(int), 10, quelle); for(i = 0; i < 10; i++) printf("Wert %d = %d\n", i, puffer[i]); return EXIT_SUCCESS; }
Folgende Zeile soll wie oben interpretiert werden:
fread(&puffer, sizeof(int), 10, quelle);
fread() liest 10 Datenobjekte mit der Größe von je sizeof(int) Bytes aus dem Stream quelle in die Adresse von puffer.
Ein wenig undurchsichtig dürfte der Parameter void *puffer bei fread() und fwrite() erscheinen. Mit dem void-Zeiger haben Sie den Vorteil, dass diesem Parameter ein Zeiger beliebigen Datentyps übergeben werden kann. In Kapitel 12, »Zeiger (Pointer)«, haben wir dies bereits durchgenommen.
16.17.2 Blockweise schreiben – »fwrite()«
Kommen wir jetzt zur Funktion fwrite():
size_t fwrite(const void *puffer,size_t blockgroesse, size_t blockzahl, FILE *datei);
Mit fwrite() werden blockzahl-Speicherobjekte, von denen jedes blockgroesse Bytes groß ist, von der Adresse puffer in den Ausgabe-Stream datei geschrieben. Der Rückgabewert ist auch hier die Anzahl der geschriebenen Speicherobjekte. Ist die Anzahl kleiner als blockzahl, dann ist ein Fehler aufgetreten.
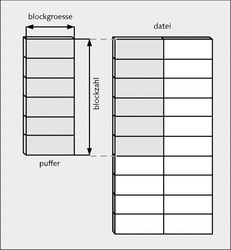
Abbildung 16.7 Blockweise schreiben mit »fwrite()«
Wieder ein Beispiel:
struct { char name[20]; char vornam[20]; char wohnort[30]; int alter; int plz; char Strasse[30]; } adressen; FILE *quelle; strcpy(adressen.name, "Barack"); strcpy(adressen.vornam, "Obama"); strcpy(adressen.wohnort, "Washington D.C"); adressen.alter = 55; adressen.plz = 23223; ... if((quelle=fopen("adres.dat", "w+b")) == NULL) ... fwrite(&adressen, sizeof(struct adressen), 1, quelle);
Hier wird mit fwrite() aus der Adresse adressen ein Speicherobjekt mit der Größe von sizeof(struct adressen) Bytes in den Stream quelle geschrieben.
Als Beispiel zu den Funktionen fread() und fwrite() folgt ein kleines Adressenverwaltungsprogramm ohne irgendwelche besonderen Funktionen, um nicht vom eigentlichen Thema abzulenken:
/* fread_fwrite.c */ #include <stdio.h> #include <stdlib.h> struct { char vorname[20]; char nachname[30]; char strasse[30]; char hausnummer[5]; char plz[7]; char ort[30]; char sternzeichen[30]; char alter[3]; } adressen; void speichern(void) { FILE *save = fopen("adressen.dat","r+b"); if( NULL == save ) { save = fopen("adressen.dat","w+b"); if( NULL == save ) { fprintf(stderr,"Kann \"adressen.dat\" nicht öffnen!\n"); return; } } /* FILE-Zeiger save auf das Ende der Datei setzen */ fseek(save, 0, SEEK_END); /* Wir schreiben eine Adresse ans Ende von "adressen.dat". */ if(fwrite(&adressen, sizeof(adressen), 1, save) != 1) { fprintf(stderr, "Fehler bei fwrite...!!!\n"); return; } /* Wir geben unseren FILE-Zeiger wieder frei. */ fclose(save); } void ausgabe(void) { FILE *output = fopen("adressen.dat","r+b"); if( NULL == output ) { fprintf(stderr,"Kann \"adressen.dat\" nicht öffnen!\n"); return; } /* Wir lesen alle Adressen aus "adressen.dat". */ while(fread(&adressen, sizeof(adressen), 1, output) == 1) { printf("Vorname...........: %s",adressen.vorname); printf("Nachname..........: %s",adressen.nachname); printf("Strasse...........: %s",adressen.strasse); printf("Hausnummer........: %s",adressen.hausnummer); printf("Postleitzahl......: %s",adressen.plz); printf("Ort...............: %s",adressen.ort); printf("Sternzeichen......: %s",adressen.sternzeichen); printf("Alter.............: %s",adressen.alter); printf("\n\n"); } fclose(output); } void eingabe(void) { printf("Vorname...........:"); fgets(adressen.vorname, sizeof(adressen.vorname), stdin); printf("Nachname..........:"); fgets(adressen.nachname, sizeof(adressen.nachname),stdin); printf("Strasse...........:"); fgets(adressen.strasse, sizeof(adressen.strasse), stdin); printf("Hausnummer........:"); fgets(adressen.hausnummer,sizeof(adressen.hausnummer),stdin); printf("Postleitzahl......:"); fgets(adressen.plz, sizeof(adressen.plz), stdin); printf("Ort...............:"); fgets(adressen.ort, sizeof(adressen.ort), stdin); printf("Sternzeichen......:"); fgets(adressen.sternzeichen,sizeof(adressen.sternzeichen), stdin ); printf("Alter.............:"); fgets(adressen.alter, sizeof(adressen.alter), stdin); speichern(); } int main(void) { int wahl; do { printf("Was wollen Sie machen:\n\n"); printf("-1- Neuen Datensatz hinzufuegen\n"); printf("-2- Alle Datensaetze ausgeben\n"); printf("-3- Programm beenden\n\n"); printf("Ihre Auswahl : "); do { scanf("%d",&wahl); } while(getchar() != '\n'); switch(wahl) { case 1 : eingabe(); break; case 2 : ausgabe(); break; case 3 : printf("...Programm wird beendet\n"); break; default: printf(">>%d<< ???\n",wahl); } } while(wahl != 3); return; }
Zuerst wurde eine Struktur mit dem Namen adressen deklariert. In der Funktion speichern() wird, falls vorhanden, die Datei adressen.dat geöffnet. Ansonsten wird diese Datei erstellt:
FILE *save = fopen("adressen.dat","r+b"); if( NULL == save ) { save = fopen("adressen.dat","w+b"); if( NULL == save ) {
Gleich darauf wird der Stream save an das Ende der Datei adressen.dat positioniert:
fseek(save, 0, SEEK_END);
Jetzt kann der Adressensatz in die Datei geschrieben werden:
if(fwrite(&adressen, sizeof(adressen), 1, save) != 1)
Nochmals eine Erklärung von fwrite():
- &adressen – Anfangsadresse der Struktur adressen, welche am Programmbeginn deklariert und in der Funktion eingabe() mit Werten initialisiert wurde
- sizeof(struct adressen) – Größe (Blockgröße) in Byte, die vorgibt, wie viel auf einmal in den Stream save geschrieben werden soll
- 1 – Anzahl der Blöcke von der Größe sizeof(adressen), die in den Stream save geschrieben werden
- save – Stream, der zuvor geöffnet wurde, und in den geschrieben wird
Diese Anweisung wurde in eine if-Bedingung gepackt, die eine Fehlerausgabe vornimmt, falls weniger als ein Block geschrieben wird. Mit der Funktion ausgabe() wird diese Datei jetzt über fread() blockweise ausgelesen und der Inhalt auf dem Bildschirm ausgegeben:
while(fread(&adressen, sizeof(adressen), 1, output) == 1)
Es wird so lange ausgelesen, bis kein ganzer Block der Größe sizeof(adressen) mehr vorhanden ist. Auch hierzu bekommen Sie eine genauere Erläuterung von fread():
- &adressen – Hierhin wird der Block der Größe sizeof(adressen), auf die der FILE-Zeiger output zeigt, »geschoben«. Natürlich handelt es sich auch hier um die Struktur adressen, die durch den Aufruf von fread() mit dementsprechenden Werten initialisiert wird.
- sizeof(adressen) – Größe des Blocks, der gelesen werden soll
- 1 – Anzahl der Blöcke, die gelesen werden
- output – Stream, aus dem gelesen wird
16.17.3 Big Endian und Little Endian
Ich habe bereits erwähnt, dass die Funktionen fread() und fwrite() nicht portabel und somit plattformabhängig sind. Sollten Sie also Programme schreiben wollen, die auf den verschiedensten Systemen laufen sollen, bleibt Ihnen nur die Wahl, diese Funktionen nicht zu verwenden, oder Sie finden heraus, auf welchem System genau sie laufen sollen. Unterschieden werden die Systeme dabei nach Little Endian und Big Endian. Little Endian und Big Endian sind zwei Methoden, wie die einzelnen Bytes im Speicher angeordnet sind. Little Endian und Big Endian unterscheiden sich durch die Anordnung des most significant byte und des least significant byte. Bei einer Word-Größe der CPU von vier Bytes wird das rechte Ende als least significant byte und das linke Ende als most significant byte bezeichnet. Das least significant byte stellt dabei die niedrigeren Werte und das most significant byte die größeren Werte in einem Word dar. Als Beispiel dient jetzt folgende Hex-Zahl:
22CCDDEEAuf den unterschiedlichen Systemen wird diese Hex-Zahl im Speicher folgendermaßen abgelegt:
| Adresse | 0x12345 | 0x12346 | 0x12347 | 0x12348 |
|
Big Endian |
22 |
CC |
DD |
EE |
|
Little Endian |
EE |
DD |
CC |
22 |
Um jetzt herauszufinden, auf was für einem System das Programm ausgeführt wird, müssen Sie diese Hex-Zahl in einen Speicher schreiben, der Platz für eine Wortbreite bietet und das erste Byte mithilfe von Bit-Operationen überprüfen. Hier sehen Sie das Listing dazu:
/* endian.c */ #include <stdio.h> #include <stdlib.h> typedef unsigned int WORD; typedef unsigned char BYTE; int main(void) { /* Word in den Speicher schreiben */ WORD Word = 0x22CCDDEE; /* Zeiger auf ein Byte */ BYTE *Byte; /* Word-Zeiger auf Byte-Zeiger casten */ Byte = (BYTE *) &Word; /* Speicherinhalt nach Adressen von links nach rechts * ausgeben. * byte[0]byte[1]byte[2]byte[3] * 22 CC DD EE Speicherinhalt bei Little Endian * EE DD CC 22 Speicherinhalt bei Big Endian */ /* Ist Byte[0] == 11 */ if(Byte[0] == ((Word >> 0) & 0xFF)) printf("Little Endian Architecture\n"); /* oder ist Byte[0] == CC */ if(Byte[0] == ((Word >> 24) & 0xFF)) printf("Big Endian Architecture\n"); return EXIT_SUCCESS; }
Mit
if(Byte[0] == ((Word >> 0) & 0xFF))
werden die ersten acht Bits (ein Byte) mithilfe einer Maske (FF == 256 == 1 Byte) gezielt getestet. Werden bei dem Ausdruck ((Word >> 0) & 0xFF)) praktisch keine Bits auf 0 gesetzt und stimmt danach der ausgewertete Ausdruck mit Byte[0] überein, haben Sie ein Little-Endian-System. Bei der zweiten Bedingung ist es dasselbe, nur wird dabei das vierte Byte (d. h. das 24. bis 32. Bit) verwendet. Zu den Little-Endian-Systemen gehören z. B.:
- Intel-CPUs
- DEC Alpha
- VAX
Big-Endian-Systeme sind zum Beispiel:
- Motorola MC68000 (Amiga, Atari)
- SPARC CPUs (SUN)
- IBM PowerPC
Einen faden Nachgeschmack hat diese Methode allerdings dann doch. Jetzt wissen Sie zwar, ob es sich um ein Little- oder Big-Endian-System handelt, aber nun müssen Sie sich dennoch selbst darum kümmern, dass die einzelnen Bytes richtig gelesen und geschrieben werden. Damit ist gemeint, dass Sie die Bits selbst verschieben müssen. Aber dies ist ein Thema, das den Rahmen dieses Buchs sprengen würde.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



