


In diesem Kapitel werden zwei Themen angesprochen, die vielleicht auf den ersten Blick nicht allzu interessant erscheinen: Buffer Overflows und Memory Leaks. Da diese beiden Probleme jedoch leider häufiger in Erscheinung treten, sollte sich jeder ernsthafte Programmierer mit ihnen auseinandersetzen.
27 Sicheres Programmieren
Ein Aspekt, der oft übersehen wird, ist die sicherheitsbezogene Programmierung. Programmierer setzen oft Funktionen ein, von denen sie zwar wissen, dass diese nicht ganz sicher sind, aber sie wissen nicht, was diese unsicheren Funktionen bewirken können.
Sie haben nach langjähriger Programmiererfahrung zwar jeden Algorithmus im Kopf und ihnen kann keiner etwas vormachen, sie verwenden aber trotzdem weiter diese Funktionen, weil sie sie eben immer verwenden und nicht so genau wissen, was daran schlimm sein soll. Denn das Programm läuft doch. Richtig? – Nein, falsch!
Auch wenn der Konkurrenzkampf und der Zeitdruck bei der Fertigstellung eines Projekts heutzutage enorm sind, sollten Sie diese Einstellung überdenken und sich ernsthaft mit diesem Thema befassen.
Diese zunächst unscheinbaren Unsicherheiten von Beginn an zu berücksichtigen, ist ein Bestandteil von vorausschauender Programmentwicklung und trägt wesentlich zur Qualitätssicherung Ihrer Programme bei. Auf diese Weise begegnen Sie schon im Vorfeld unvorhersehbarem Ärger, und nachträglich entstehen hohe Kosten.
Ein Szenario: Sie haben für eine Firma ein Programm zur Verwaltung von Daten geschrieben. In der Firma haben einige gewiefte Mitarbeiter einen Weg gefunden, mithilfe Ihres Programms aus dem Verwaltungsprogramm zu springen, wodurch sie ins System gelangen und allerlei Unfug anrichten. Der Kunde wird mit Sicherheit kein Programm mehr von Ihnen entwickeln lassen. Also haben Sie auf jeden Fall schon einen Imageschaden. Da Sie aber versprochen haben, sich um das Problem zu kümmern, müssen Sie alles andere erst einmal stehen und liegen lassen. Damit haben Sie schon kostbare Zeit verloren, die Sie für andere Projekte hätten nutzen können. Da noch weitere Kunden dieses Produkt verwenden, müssen Sie auch diese informieren.
Jetzt ist es an der Zeit, ein Bugfix (Patch) zu schreiben, den der Kunde einspielen muss, um den Fehler zu beheben. Wenn Sie Glück haben, kann der Kunde das Programm unterbrechen und den Patch einspielen. Sollte der Kunde aber rund um die Uhr auf das Programm angewiesen sein, entstehen ihm Ausfallkosten.
Nachdem Sie den Patch aufgespielt haben, treten andere unerwartete Probleme mit dem Programm auf. Somit folgt dem Patch ein weiterer, womit wieder Zeit, Geld und Image verloren gehen. Ich denke, dass jedem schon einmal ein ähnliches Szenario mit einem Programm widerfahren ist.
Die meisten solcher Sicherheitsprobleme treten mit Programmen auf, die in C geschrieben wurden. Dies heißt allerdings nicht, dass C eine unsichere Sprache ist, sondern es bedeutet nur, dass sie eine der am häufigsten eingesetzten Sprachen ist. Viele Systemtools, Server, Datenbanken, aber auch grafische Oberflächen sind in C geschrieben.
Sie sehen also, dass es sich durchaus lohnt, diese Themen aufzugreifen und bei der Entwicklung von Programmen zu berücksichtigen.
27.1 Buffer-Overflow (Speicherüberlauf) 

Eines der bekanntesten und am häufigsten auftretenden Sicherheitsprobleme ist der Buffer-Overflow (dt.: Speicherüberlauf, Pufferüberlauf), häufig auch als Buffer Overrun bezeichnet. Geben Sie einmal in einer Internet-Suchmaschine den Begriff »Buffer-Overflow« ein, und Sie werden angesichts der enormen Anzahl von Ergebnissen überrascht sein. Es gibt unzählige Programme, die für einen Buffer-Overflow anfällig sind. Das Ziel des Angreifers ist es dabei, den Buffer-Overflow auszunutzen, um in das System einzubrechen.
Die Aufgabe dieses Abschnitts ist es nicht, Ihnen beizubringen, wie Sie Programme hacken können, sondern zu erklären, was ein Buffer-Overflow ist, wie dieser ausgelöst wird und was Sie als Programmierer beachten müssen, damit Ihr Programm nicht anfällig dafür ist.
Für den Buffer-Overflow ist immer der Programmierer selbst verantwortlich. Der Overflow kann überall dort auftreten, wo Daten von der Tastatur, dem Netzwerk oder einer anderen Quelle aus in einen Speicherbereich mit statischer Größe ohne eine Längenüberprüfung geschrieben werden. Hier sehen Sie ein solches Negativbeispiel:
/* bufferoverflow1.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void) {
char *str = "0123456789012";
char buf[10];
strcpy(buf, str);
printf("%s",buf);
return EXIT_SUCCESS;
}Hier wurde ein Buffer-Overflow mit der Funktion strcpy() erzeugt. Es wird dabei versucht, in den char-Vektor, der Platz für 10 Zeichen reserviert hat, mehr als diese 10 Zeichen zu kopieren.
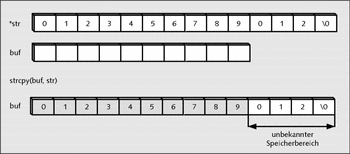
Abbildung 27.1 Pufferüberlauf mit der Funktion »strcpy()«
Die Auswirkungen eines Buffer Overflows sind stark vom Betriebssystem abhängig. Häufig stürzt dabei das Programm ab, weil Variablen mit irgendwelchen Werten überschrieben wurden. Manches Mal bekommen Sie aber auch nach Beendigung des Programms eine Fehlermeldung zurück, etwa Speicherzugriffsfehler. Dies wird ausgegeben, wenn z. B. die Rücksprungadresse des Programms überschrieben wurde und das Programm irgendwo in eine unerlaubte Speicheradresse springt.
Wird aber bewusst diese Rücksprungadresse manipuliert und auf einen speziell von Ihnen erstellten Speicherbereich verwiesen bzw. gesprungen, der echten Code enthält, haben Sie einen sogenannten Exploit erstellt.
27.1.1 Speicherverwaltung von Programmen
Ein Programm besteht aus drei Speichersegmenten, die im Arbeitsspeicher liegen. Der Prozessor (CPU) holt sich die Daten und Anweisungen aus diesem Arbeitsspeicher. Damit der Prozessor unterscheiden kann, ob es sich bei den Daten um Maschinenbefehle oder den Datenteil mit den Variablen handelt, werden diese Speicherbereiche in einzelne Segmente aufgeteilt. In Abbildung 27.2 sind die einzelnen Segmente schematisch dargestellt.
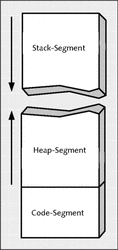
Abbildung 27.2 Speicherverwaltung – die einzelnen Segmente
- Code-Segment (Text-Segment) – Hier befinden sich die Maschinenbefehle, die vom Prozessor beim HOLEN-Zyklus eingelesen werden – oder einfacher gesagt: der Programmcode selbst. Das Code-Segment lässt sich nicht manipulieren, hat eine feste Größe und ist gegen Überschreiben geschützt.
- Heap-Segment (Daten-Segment) – Hier liegen die Variablen (extern, static), Felder (Arrays) und Tabellen des Programms. Der Maschinenbefehl, der diese Daten benötigt, greift auf dieses Segment zu.
- Stack-Segment – Hier befinden sich dynamische Variablen und Rücksprungadressen von Funktionen. Dieser Bereich dient auch dem schnellen Zwischenspeichern von Daten und Parameterübergaben.
Es sei hierbei noch erwähnt, dass der Stack-Bereich nach unten und der Heap nach oben anwächst. Der Stack ist auch das Angriffsziel für einen Buffer-Overflow.
27.1.2 Der Stack-Frame
Für jede Funktion steht ein sogenannter Stack-Frame im Stack zur Verfügung, in dem die lokalen Variablen gespeichert werden. Wichtiger noch: Im Stack befinden sich Registerinhalte des Prozessors, die vor dem Funktionsaufruf gesichert wurden. Sie sind nötig, um bei Beendigung der Funktion auf die aufrufende Funktion zurückspringen zu können.
Beispielsweise wird in der main()-Funktion die Funktion mit den Parametern my_func(wert1, wert2) aufgerufen:
/* stackframe.c */
#include <stdio.h>
#include <stdlib.h>
void my_func(int wert1, int wert2) {
int summe;
summe = wert1+wert2;
printf("Summe: %d \n",summe);
}
int main(void) {
my_func(10,29);
return 0;
}Dies geschieht jetzt – ohne zu sehr ins Detail zu gehen – in folgenden Schritten auf dem Stack:
| 1. | Mit dem Assembler-Befehl PUSH werden die Parameter wert1 und wert2 auf den Stack geschrieben. |
| 2. | Mit dem Assembler-Befehl CALL wird die Position des Maschinencodes gesichert, damit bei Beendigung der Funktion my_func() wieder in die main()-Funktion zurückgesprungen werden kann. Dies wird mithilfe des Befehlszeigers (Instruction Pointer, kurz: IP) realisiert. Genau genommen wird diese Adresse mithilfe des Befehlszeigers, des Code-Segments (CS) (CS:IP) und des Basis-Pointers (BP) erzeugt. Dies ist die Rücksprungadresse, die mit CS:IP und BP dargestellt wird. |
| 3. | Jetzt werden die lokalen Variablen der Funktion my_func() eingerichtet, und die Funktion arbeitet die einzelnen Befehle ab. |
| 4. | Am Schluss, wenn diese Funktion beendet ist, springt sie wieder zur main()-Funktion zurück. Dies geschieht mit dem Assembler-Befehl RET, der auf die vom Stack gesicherte Adresse zurückspringt, die aus CS:IP und BP gebildet wird. |
27.1.3 Rücksprungadresse manipulieren
In diesem Abschnitt folgt ein Beispiel, das zeigt, wie die Rücksprungadresse manipuliert werden kann.
Es ist hierbei nicht Ziel und Zweck, Ihnen eine Schritt-für-Schritt-Anleitung zur Programmierung eines Exploits an die Hand zu geben und bewusst einen Buffer-Overflow zu erzeugen, sondern Ihnen soll vor Augen geführt werden, wie schnell und unbewusst kleine Unstimmigkeiten im Quellcode Hackern Tür und Tor öffnen können – einige Kenntnisse der Funktionsweise von Assemblern vorausgesetzt.
Zur Demonstration des folgenden Beispiels werden der Compiler gcc und der Diassembler objdump verwendet. Das Funktionieren dieses Beispiels ist nicht auf allen Systemen garantiert, da bei den verschiedenen Betriebssystemen zum Teil unterschiedlich auf den Stack zugegriffen wird.
Folgendes Listing sei gegeben:
/* bufferoverflow2.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void overflow(void) {
char zeichen[5];
strcpy(zeichen, "1234567"); /*Überlauf*/
}
int main(void) {
printf("Mein 1.Buffer Overflow\n");
overflow();
return EXIT_SUCCESS;
}Übersetzen Sie das Programm, und verwenden Sie anschließend den Diassembler, um sich den Maschinencode und den Assembler-Code des Programms anzusehen. Hierfür wird der Diassembler objdump verwendet, der auf fast jedem System vorhanden sein dürfte. Rufen Sie den Diassembler mit folgender Option in der Kommandozeile auf:
objdump -d bufferoverflow2
Jetzt sollte in etwa folgende Ausgabe auf dem Bildschirm erscheinen (gekürzt):
... 08048490 <overflow>: 8048490: 55 push %ebp 8048491: 89 e5 mov %esp,%ebp 8048493: 83 ec 18 sub $0x18,%esp 8048496: 83 ec 08 sub $0x8,%esp 8048499: 68 44 85 04 08 push $0x8048544 804849e: 8d 45 e8 lea 0xffffffe8(%ebp),%eax 80484a1: 50 push %eax 80484a2: e8 d9 fe ff ff call 8048380 <_init+0x78> 80484a7: 83 c4 10 add $0x10,%esp 80484aa: 89 ec mov %ebp,%esp 80484ac: 5d pop %ebp 80484ad: c3 ret 80484ae: 89 f6 mov %esi,%esi ...
In der linken Spalte befindet sich der Adressspeicher. An der Adresse »08048490« fängt in diesem Beispiel die Funktion overflow() an. Diese Adresse wurde zuvor etwa von der main()-Funktion mit
80484c6: e8 c5 ff ff ff call 8048490 <overflow>
aufgerufen. In der zweiten Spalte befindet sich der Maschinencode (Opcode). Dieser Code ist schwer für den Menschen nachvollziehbar. Aber alle Zahlen haben ihre Bedeutung. So steht z. B. die Zahl »55« für push %ebp, was den Basis-Pointer auf dem Stack sichert, und »5d« entfernt den Basis-Pointer wieder vom Stack. »c3« bedeutet ret, also return. Mit »c3« wird also wieder an die Rücksprungadresse gesprungen, die in der main()-Funktion ebenfalls auf den Stack gepusht wurde. Häufig finden Sie den Maschinencode »90« (nop), der nichts anderes macht, als Zeit des Prozessors zu vertrödeln. In der dritten Spalte befindet sich der Assembler-Code, beispielsweise:
add $0x10,%esp mov %ebp,%esp
Es ist wichtig, dass Sie verstehen, woraus ein Programm eigentlich besteht. Ein einfaches C-Konstrukt wie die for-Schleife wird z. B. in Hunderte kleine Maschinencodes (Opcodes) zerlegt. Vielleicht wissen Sie nun, wenn Sie das nächste Mal mit einem Hexeditor ein Programm öffnen, ein bisschen mehr darüber, was diese Zahlen (Maschinencode) und Zeilen (Adressen) bedeuten.
Um es gleich vorwegzunehmen: Dies hier wird kein Assembler-Kurs oder Ähnliches. Das Thema ist recht komplex.
Übersetzen Sie das Programm von eben nochmals mit:
gcc -S -o bufferoverflow2.s bufferoverflow2.c
Jetzt befindet sich im Verzeichnis eine Assembler-Datei (*.s oder *.asm) des Programms. Wir wollen uns diese in gekürzter Fassung ansehen:
main:
pushl %ebp ;Framepointer auf dem Stack
movl %esp, %ebp ;Stackpointer(esp) in Framepointer(ebp) kopieren
subl $8, %esp ;Stackpointer um 8 Bytes verringern
subl $12, %esp ;Stackpointer um 12 Bytes verringern für ausgabe printf
pushl $.LC1 ;Den String "Mein 1.Buffer Overflow\n"
call printf ;Funktion printf aufrufen
addl $16, %esp ;Stackpointer um 16 Bytes erhoehen
call overflow ;overflow aufrufen, Rücksprungadresse auf dem
;Stack
movl $0, %eax
movl %ebp, %esp
popl %ebp
ret
overflow:
pushl %ebp ;Wieder ein Framepointer auf dem Stack
movl %esp, %ebp ;Stackpointer(esp) in Framepointer(ebp)
;kopieren
subl $24, %esp ;Stackpointer-24Bytes
subl $8, %esp ;Stackpointer-8Bytes
pushl $.LC0 ;Den String "1234567" auf dem Stack
leal -24(%ebp), %eax ;Laden des Offsets zu eax
pushl %eax ;eax auf dem Stack
call strcpy ;Funktion strcpy aufrufen
addl $16, %esp ;16 Bytes vom Stack freigeben
movl %ebp, %esp ;Stackpointer in Framepointer kopieren
popl %ebp ;Framepointer wieder vom Stack
ret ;Zurueck zur main-FunktionDies ist ein kleiner Überblick über die Assembler-Schreibweise des Programms. Hier ist ja nur die Rücksprungadresse des Aufrufs call overflow von Interesse.
Da Sie jetzt wissen, wie Sie an die Rücksprungadresse eines Programms herankommen, können Sie nun ein Programm schreiben, bei dem der Buffer-Overflow, der ja hier durch die Funktion strcpy() ausgelöst wird, zum Ändern der Rücksprungadresse genutzt wird. Es wird dabei im Fachjargon von Buffer-Overflow Exploit gesprochen. Bei dem folgenden Beispiel soll die Rücksprungadresse manipuliert werden:
/* bufferoverflow3.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void funktion(int temp,char *array) {
char puffer[5];
strcpy(puffer, array);
printf("%s\n",puffer);
}
int main(void) {
int wert;
wert=0;
funktion(7,"hallo");
wert=1;
printf("%d\n",wert);
}Das Ziel soll es nun sein, die Funktion funktion() aufzurufen und die Rücksprungadresse zu wert=1; zu überspringen, sodass printf() als Wert 0 anstatt 1 ausgibt. Nach dem Funktionsaufruf sieht der Stack so aus:
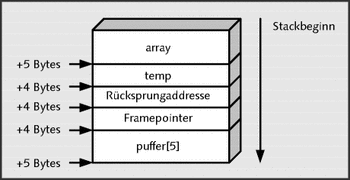
Abbildung 27.3 Der aktuelle Zustand des Stacks
Wie kommen Sie nun am einfachsten zur Rücksprungadresse? Mit einem Zeiger. Also benötigen Sie zuerst einen Zeiger, der auf diese Rücksprungadresse verweist. Anschließend manipulieren Sie die Adresse der Rücksprungadresse, auf die der Pointer zeigt, und zwar so, dass die Wertzuweisung wert=1 übersprungen wird:
/* bufferoverflow4.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void funktion(int tmp,char *array) {
char puffer[5];
int *pointer;
strcpy(puffer, array);
printf("%s\n",puffer);
/* Pointer auf dem Stack um 4 Bytes zurücksetzen.
Sollte jetzt auf die Rücksprungadresse zeigen. */
pointer=&tmp-1;
/*Rücksprungadresse, auf die Pointer zeigt, 10 Bytes weiter*/
*pointer=*pointer+10;
}
int main(void) {
int a;
a=0;
funktion(7,"hallo");
a=1;
printf("wert = %d\n",a);
return EXIT_SUCCESS;
}Die einfachste Möglichkeit, auf die Rücksprungadresse zurückzugreifen, besteht darin, um die Speichergröße der Variablen temp in der Funktion rückwärts zu springen.
pointer=&tmp-1;
Jetzt können Sie die Rücksprungadresse manipulieren, auf die der pointer zeigt:
*pointer=*pointer+10;
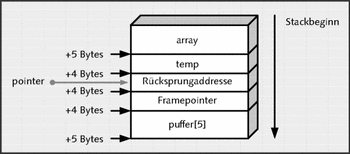
Abbildung 27.4 Der Zeiger verweist auf die Rücksprungadresse.
Warum habe ich hier die Rücksprungadresse um 10 Bytes erhöht? Dazu müssen Sie wieder objdump einsetzen (ohne Opcodes im Beispiel):
objdump -d bufferoverflow4 080484e0 <main>: ... 80484f7: call 8048490 <funktion> ;Aufruf funktion 80484fc: add $0x10,%esp ;Stack wieder freigeben 80484ff: movl $0x1,0xfffffffc(%ebp) ;wert=1 8048506: sub $0x8,%esp 8048509: pushl 0xfffffffc(%ebp) ;printf vorbereiten 804850c: push $0x804859e 8048511: call 8048360 <_init+0x58> ;printf aufrufen ...
Die zu überspringende Adresse liegt in diesem Fall ja zwischen »80484ff« und »8048509«. Somit ergibt sich folgende Rechnung:
8048509 - 80484ff = A
A ist der hexdezimale Wert für 10. Hiermit haben Sie die Rücksprungadresse Ihres eigenen Programms manipuliert. Das Ziel dieser Manipulation ist es aber selten (wie hier dargestellt), die Rücksprungadresse zu ändern, um den Programmcode an einer beliebigen Stelle weiter auszuführen, sondern meistens wird dabei die CPU mit einem eigenen Maschinencode gefüttert. Dabei wird der Maschinencode in einer Variablen auf dem Stack geschrieben und die Rücksprungadresse auf die Startadresse eines fremden Programmcodes gesetzt. Hat der fremde Maschinencode keinen Platz in der Variablen, kann auch der Heap verwendet werden.
Beendet sich hierbei die Funktion, wird durch RET auf die Rücksprungadresse gesprungen, die Sie bereits manipuliert haben, und der Hacker kann nun bestimmte Codesequenzen ausführen.
Ihnen dies jetzt zu demonstrieren, würde zum einen den Umfang des Kapitels bei Weitem sprengen und vor allem am Thema vorbeigehen. Zum anderen würde dies neben der gründlichen Kenntnis von C auch gute Kenntnisse im Assembler-Bereich (und unter Linux u. a. auch der Shell-Programmierung) erfordern.
Zusammengefasst lassen sich Buffer Overflows für folgende Manipulationen ausnutzen:
- Inhalte von Variablen, die auf dem Stack liegen, können verändert werden. Stellen Sie sich das einmal bei einer Funktion vor, die ein Passwort vom Anwender abfragt.
- Die Rücksprungadresse wird manipuliert, sodass das Programm an einer beliebigen Stelle im Speicher mit der Maschinencodeausführung fortfährt. Meistens ist dies die Ausführung des vom Angreifer präparierten Codes. Für die Ausführung von fremdem Code werden wiederum die Variablen auf dem Stack, eventuell auch auf dem Heap verwendet.
- Dasselbe Schema lässt sich auch mit Zeigern auf Funktionen anwenden. Dabei ist theoretisch nicht einmal ein Buffer-Overflow erforderlich, sondern es reicht die Speicheradresse, an der sich diese Funktion befindet. Die Daten, die für die Ausführung von fremdem Code nötig sind, werden vorzugsweise wieder in einer Variablen gespeichert.
27.1.4 Gegenmaßnahmen zum Buffer-Overflow während der Programmerstellung
Steht Ihr Projekt in den Startlöchern, haben Sie Glück. Wenn Sie diesen Abschnitt durchgelesen haben, ist die Gefahr recht gering, dass Sie während der Programmerstellung eine unsichere Funktion implementieren.
Die meisten Buffer Overflows werden mit den Funktionen der Standard-Bibliothek erzeugt. Das Hauptproblem dieser unsicheren Funktionen ist, dass keine Längenüberprüfung der Ein- bzw. Ausgabe vorhanden ist. Daher wird empfohlen, sofern diese Funktionen auf dem System vorhanden sind, alternative Funktionen zu verwenden, die diese Längenüberprüfung durchführen. Falls es in Ihrem Programm auf Performance ankommt, muss jedoch erwähnt werden, dass die Funktionen mit der n-Alternative (etwa strcpy -> strncpy) langsamer sind als die ohne.
Hierzu folgt ein Überblick zu anfälligen Funktionen und geeigneten Gegenmaßnahmen, die getroffen werden können.
Unsicheres Einlesen von Eingabestreams
| Unsichere Funktion | Gegenmaßnahme |
gets(puffer); |
fgets(puffer, MAX_PUFFER, stdin); |
|
Bemerkung: Auf Linux-Systemen gibt der Compiler bereits eine Warnmeldung aus, wenn die Funktion gets() verwendet wird. Mit gets() lesen Sie von der Standardeingabe bis zum nächsten ENTER einen String in einen statischen Puffer ein. Als Gegenmaßnahme wird die Funktion fgets() empfohlen, da diese nicht mehr als den bzw. das im zweiten Argument angegebenen Wert bzw. Zeichen einliest. |
|
| Unsichere Funktion | Gegenmaßnahme |
scanf("%s",str); |
scanf("%10s",str); |
|
Bemerkung: Auch scanf() nimmt bei der Eingabe keine Längenprüfung vor. Die Gegenmaßnahme dazu ist recht simpel. Sie verwenden einfach eine Größenbegrenzung bei der Formatangabe (%|SIZE|s). Selbiges gilt natürlich auch für fscanf(). |
|
Unsichere Funktionen zur Stringbearbeitung
| Unsichere Funktion | Gegenmaßnahme |
strcpy(buf1, buf2); |
strncpy(buf1, buf2, SIZE); |
|
Bemerkung: Bei strcpy() wird nicht auf die Größe des Zielpuffers geachtet, mit strncpy() hingegen schon. Trotzdem kann mit strncpy() bei falscher Verwendung ebenfalls ein Buffer-Overflow ausgelöst werden: char buf1[100]=’\0’; char buf2[50]; fgets(buf1, 100, stdin); /* buf2 hat nur Platz für 50 Zeichen */ strncpy(buf2, buf1, sizeof(buf1)); |
|
| Unsichere Funktion | Gegenmaßnahme |
strcat(buf1 , buf2); |
strncat(buf1, buf2, SIZE); |
|
Bemerkung: Bei strcat() wird nicht auf die Größe des Zielpuffers geachtet, mit strncat() hingegen schon. Trotzdem kann mit strncat() bei falscher Verwendung wie schon bei strncpy() ein Buffer-Overflow ausgelöst werden. |
|
| Unsichere Funktion | Gegenmaßnahme |
sprintf(buf, "%s", temp); |
snprintf(buf, 100, "%s", temp); |
|
Bemerkung: Mit sprintf() ist es nicht möglich, die Größe des Zielpuffers anzugeben, daher empfiehlt sich auch hier die n-Variante snprintf(). Gleiches gilt übrigens auch für die Funktion vsprintf(). Auch hier können Sie sich zwischen der Größenbegrenzung und vsnprintf() entscheiden. |
|
Unsichere Funktionen zur Bildschirmausgabe
| Unsichere Funktion | Gegenmaßnahme |
printf("%s", argv[1]); |
printf("%100s",argv[1]); |
|
Bemerkung: Die Länge der Ausgabe von printf() ist nicht unbegrenzt. Auch hier würde sich eine Größenbegrenzung gut eignen. Gleiches gilt auch für fprintf(). |
|
Weitere unsichere Funktionen im Überblick
| Unsichere Funktion | Bemerkung |
getenv() |
Diese Funktion lässt sich ebenfalls für einen Buffer-Overflow verwenden. |
system() |
Diese Funktion sollte möglichst vermieden werden – insbesondere dann, wenn der Anwender den String selbst festlegen darf. |
Abhängig von Betriebssystem und Compiler gibt es noch eine Menge mehr solcher unsicherer Funktionen. Die wichtigsten wurden aber hier erwähnt.
Generell sollte man immer alle printf()- und scanf()-Funktionen mit Vorsicht und Bedacht verwenden. Häufig lässt es sich hier beispielsweise wesentlich sicherer mit fwrite() oder fread() arbeiten, und die Konversion kann man dabei auch selbst machen. Wenigstens sollte man aber ein Frame um die »unsichereren« Funktionen bauen, die entsprechende Längenüberprüfungen durchführen, wie beispielsweise folgendes Listing zeigen soll:
/* check_before_sprintf.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX 10
void check_bevore_sprintf(char *quelle, int max) {
if(strlen(quelle) < MAX)
return;
else
abort(); /* abort zum Debugger */
}
int main(void) {
char *ptr1 = "123456789";
char *ptr2 = "1234567890";
char string[MAX];
check_bevore_sprintf(ptr1, MAX);
sprintf(string, "%s", ptr1);
printf("string: %s\n", string);
/* Boom!!! */
check_bevore_sprintf(ptr2, MAX);
sprintf(string, "%s", ptr2);
printf("string: %s\n", string);
return EXIT_SUCCESS;
}Einige Programmierer gehen sogar so weit, dass sie alle printf- und scanf-Funktionen aus ihren fertigen Programmen verbannen. Diese Entwickler scheuen auch nicht die Arbeit, hierzu eigene Funktionen (bzw. eine Bibliothek) zu schreiben, die die Benutzereingaben oder Eingabedatei scannen.
27.1.5 Gegenmaßnahmen zum Buffer-Overflow, wenn das Programm fertig ist
Wenn das Programm bereits fertig ist, und Sie es noch nicht der Öffentlichkeit zugänglich gemacht haben, können Sie sich die Suchen-Funktion des Compilers zunutze machen oder eine eigene Funktion schreiben. Im Folgenden sehen Sie einen solchen Ansatz. Das Listing gibt alle gefährlichen Funktionen, die in der Stringtabelle danger eingetragen sind, auf dem Bildschirm aus.
/* danger.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX 255
char *danger[] = {
"scanf", "sscanf", "fscanf",
"gets", "strcat", "strcpy",
"printf", "fprintf", "sprintf",
"vsprintf", "system", NULL
/* usw. */
};
int main(int argc, char **argv) {
FILE *fp;
char puffer[MAX];
int i, line=1;
if(argc < 2) {
printf("Anwendung: %s <datei.c>\n\n", argv[0]);
return EXIT_FAILURE;
}
if ( (fp=fopen(argv[1], "r+")) == NULL) {
printf("Konnte Datei nicht zum Lesen oeffnen\n");
return EXIT_FAILURE;
}
while( (fgets(puffer, MAX, fp)) != NULL) {
i=0;
while(danger[i] != NULL) {
if( (strstr(puffer,danger[i])) !=0 )
printf("%s gefunden in Zeile %d\n",
danger[i],line);
i++;
}
line++;
}
fclose(fp);
return EXIT_SUCCESS;
}Eine weitere Möglichkeit ist es, eine sogenannte Wrapper-Funktion zu schreiben. Eine Wrapper-Funktion können Sie sich als Strumpf vorstellen, den Sie einer anfälligen Funktion überziehen. Als Beispiel dient hier die Funktion gets():
/* wrap_gets.c */
#include <stdio.h>
#include <stdlib.h>
#define MAX 10
/* Damit es keine Kollision mit gets aus stdio.h gibt. */
#define gets(c) Gets(c)
void Gets(char *z) {
int ch;
int counter=0;
while((ch=getchar()) != '\n') {
z[counter++]=ch;
if(counter >= MAX)
break;
}
z[counter] = '\0'; /* Terminieren */
}
int main(int argc, char **argv) {
char puffer[MAX];
printf("Eingabe : ");
gets(puffer);
printf("puffer = %s\n",puffer);
return EXIT_SUCCESS;
}Zuerst musste vor dem Compiler-Lauf die Funktion gets() mit
#define gets(c) Gets(c)
ausgeschaltet werden. Jetzt kann statt der echten gets()-Version die Wrapper-Funktion Gets() verwendet werden. Genauso kann dies bei den anderen gefährlichen Funktionen gemacht werden – beispielsweise mit der Funktion strcpy():
/* wrap_strcpy.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX 10
/* Damit es keine Kollision mit strcpy in string.h gibt */
#define strcpy Strcpy
#define DEBUG
/* #undef DEBUG */
void Strcpy(char *ziel, char *quelle) {
int counter;
#ifdef DEBUG
/* DEBUG-INFO */
size_t size = strlen(quelle)+1;
if( size > MAX )
printf("DEBUG-INFO: Pufferueberlaufversuch\n");
/* DEBUG-INFO Ende */
#endif
for(counter=0; quelle[counter] != '\0' && counter < MAX-1;
counter++)
ziel[counter]=quelle[counter];
/* terminieren */
ziel[counter] = '\0';
}
int main(int argc, char **argv) {
char puffer[MAX];
strcpy(puffer, "0123456789012345678");
printf("puffer = %s\n",puffer);
return EXIT_SUCCESS;
}Hier wird zum Beispiel noch eine DEBUG-Info mit ausgegeben, falls dies erwünscht ist. Ansonsten muss einfach die Direktive undef auskommentiert werden.
27.1.6 Programme und Tools zum Buffer-Overflow
Es gibt z. B. auf dem Linux-Sektor zwei gute Bibliotheken, StackShield und StackGuard. Beide Bibliotheken arbeiten etwa nach demselben Prinzip. Beim Aufruf einer Funktion greifen diese Bibliotheken ein und sichern die Rücksprungadresse. Dafür wird natürlich ein extra Code am Anfang und Ende des Funktionsaufrufs eingefügt. Wird hierbei versucht, die Rücksprungadresse zu manipulieren, schreibt das Programm eine Warnung in das Syslog des Systems und beendet sich.
Die Voraussetzung dafür, dass Sie eine der beiden Bibliotheken verwenden können, ist, dass Sie im Besitz des Quellcodes des Programms sind, das Sie vor einem Buffer-Overflow schützen wollen. Denn das Programm muss mit den Bibliotheken von StackShield und StackGuard neu übersetzt werden.
Einen anderen Weg geht die Bibliothek libsafe. Sie entfernt gefährliche Funktionsaufrufe und ersetzt sie durch sichere Versionen. Diese besitzen zusätzlich noch einen Schutz vor dem Überschreiben des Stack-Frames.
Firmen mit einem etwas größeren Geldbeutel sei das Programm Insure++ von Parasoft ans Herz gelegt. Das Programm lässt sich als Testversion einige Zeit kostenlos ausprobieren. Der Anschaffungspreis rechnet sich im Laufe der Zeit allemal. Das Programm ist für alle gängigen Systeme erhältlich und kann außer dem Buffer-Overflow noch eine Menge weiterer Fehler aufdecken. Einige davon sind:
- Speicherfehler
- Speicherlecks
- Speicherreservierungsfehler
- Verwendung uninitialisierter Variablen
- falsche Variablendefinitionen
- Zeigerfehler
- Bibliothekenfehler
- logische Fehler
27.1.7 Ausblick
Buffer Overflows werden wohl in Zukunft noch vielen Programmierern Probleme bereiten und noch länger eines der häufigsten Angriffsziele von Hackern darstellen. Daher lohnt es, sich mit diesem Thema zu befassen.
Es wird wohl noch eine Generation dauern, bis Betriebssysteme auf den Markt kommen, die solche Probleme von selbst erkennen und ausgrenzen. Erste Ansätze dazu gibt es zwar schon (Solaris), aber clevere Programmierer haben bereits einen Weg gefunden, auch diese auszuhebeln.
| Hinweis |
|
Um es richtigzustellen: Der Hacker findet Fehler in einem System heraus und meldet diese dem Hersteller des Programms. Entgegen der in den Medien verbreiteten Meinung ist ein Hacker kein Bösewicht. Die Bösewichte werden Cracker genannt. |
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



