


7.4 Objekte in Aktion und in Interaktion 

Wenn wir Objekte lediglich erzeugen und danach wieder zerstören würden, wären wir mit unseren Programmen schnell am Ende. Zwar ist vor allem die Art der Objekterzeugung sehr relevant für die Flexibilität unserer Programme. Anschließend sollen die erzeugten Objekte aber natürlich die ihnen zugedachten Aufgaben wahrnehmen. Dabei agieren und interagieren die Objekte.
Aufbau des Abschnitts
In Abschnitt 7.4.1 stellen wir zunächst die wichtigsten Sichtweisen auf die verschiedenen Formen von Aktionen und Interaktionen vor. Wir verwenden dabei die von der UML zur Verfügung gestellten Beschreibungsmöglichkeiten.
Anschließend gehen wir in den Abschnitten 7.4.2 und 7.4.3 auf ausgewählte und wichtige Arten der Interaktion zwischen Objekten genauer ein. Wir beschreiben, wie Iteratoren und Generatoren dafür sorgen, dass Sie mit Sammlungen von Objekten effizient umgehen können.
In Abschnitt 7.4.4 lernen Sie die Funktionsweise von Ereignissen und Delegaten kennen, die verwendet werden, um Aktionen mit Objekten zu verknüpfen.
Schließlich beantwortet Abschnitt 7.4.5 die Frage, in welchen Fällen Sie Kopien von Objekten erstellen müssen und wie Sie diese Kopien korrekt herstellen.
7.4.1 UML: Diagramme zur Beschreibung von Abläufen
Um das Ablaufverhalten von Systemen zu beschreiben, bietet die UML eine ganze Reihe von Diagrammtypen an.
Diagrammtypen
- Aktivitätsdiagramme beschreiben die einzelnen Schritte, mit denen ein System eine bestimmte Anforderung umsetzt.
- Anwendungsfalldiagramme werden in der Analysephase eingesetzt und beschreiben die Beziehungen zwischen Akteuren, Anwendungsfällen des Systems und dem System selbst.
- Zustandsdiagramme (Zustandsautomaten) beschreiben die Übergänge zwischen Zuständen in einem System in Form von endlichen Automaten. Zustandsdiagramme können als Beschreibungsmittel für den Lebenszyklus eines Objekts eingesetzt werden.
- Sequenzdiagramme beschreiben die Interaktionen und den Nachrichtenaustauch zwischen Objekten. Sie stellen vor allem den zeitlichen Ablauf dieser Nachrichten (deren Sequenz) dar.
- Kommunikationsdiagramme (vor UML 2.0 Kollaborationsdiagramm) beschreiben ebenfalls Interaktionen, bieten aber eine etwas andere Sicht auf diese. Dabei liegt der Fokus auf der Zusammenarbeit von mehreren Objekten, die eine gemeinsame Aufgabe erledigen.
- Timingdiagramme sind eine Neuerung der UML 2.0. Sie beschreiben die Zustandswechsel von Kommunikationspartnern aufgrund von Nachrichten. Timingdiagramme sind als Detailsicht bei zeitkritischen Zustandsübergängen sinnvoll.
- Interaktionsübersichtsdiagramme sind ebenfalls eine Neuerung der UML 2.0. Sie bieten die Möglichkeit, Sequenzdiagramme, Kommunikationsdiagramme und Timingdiagramme (also alle Interaktionsdiagramme) in eine gemeinsame Übersicht zu bringen.
Von den gelisteten Diagrammtypen werden Aktivitätsdiagramme, Zustandsdiagramme und Sequenzdiagramme in der Regel am häufigsten genutzt. Diese stellen wir deshalb an dieser Stelle jeweils anhand eines kurzen Beispiels vor. Die ebenfalls häufig verwendeten Anwendungsfalldiagramme werden wir dagegen nicht genauer vorstellen, da sie hauptsächlich in der Analysephase benötigt werden. Detaillierte Informationen zu den Diagrammen der UML 2.0 finden Sie in UML 2.0, Das umfassende Handbuch von Christoph Kecher [Kecher 2009] oder in UML 2 Glasklar von Chris Rupp und anderen [Rupp 2007].
Aktivitätsdiagramm
Eine häufig genutzte Sichtweise auf das Verhalten von Programmen ist es, diese als eine Abfolge von Aktivitäten zu betrachten. Diese Sichtweise wird durch die Aktivitätsdiagramme der UML unterstützt. In Abbildung 7.31 ist ein Ausschnitt der Aktivitäten dargestellt, die beim Einschalten und Auslösen einer Alarmanlage durchlaufen werden.
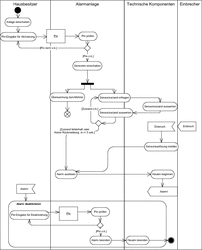
Abbildung 7.31 Aktivitäten einer Alarmanlage
Zunächst einmal haben wir verschiedene Aktivitätsbereiche vorliegen. Wir haben unsere Aktivitäten auf die Bereiche Hausbesitzer, Alarmanlage, technische Komponenten und einen Einbrecher verteilt. Der Name des Einbrechers bleibt im Dunkeln, da er aber direkt die Alarmanlage auslöst, wird es sich wohl nicht um Arsčne Lupin handeln.
Darstellung eines Einsatzfalls
Wir haben in unserem Aktivitätsdiagramm also einen Einsatzfall dargestellt, bei dem die Anlage tatsächlich ausgelöst wird. Beginnend mit dem obligatorischen Startzustand ist es die erste Aktion, die von unserem Hausbesitzer durchgeführt wird, die Alarmanlage einzuschalten. Nach der PIN-Eingabe wird die PIN über einen Objektknoten, der Objekte der Klasse Pin enthalten kann, an die Alarmanlage zur Prüfung übergeben. Die Pfeile, welche die Aktivitäten verbinden, repräsentieren den Kontrollfluss zwischen Aktivitäten, im Fall von Objektübergaben sprechen wir auch vom Objektfluss. Hier findet eine Prüfung statt, und über den nachfolgenden Entscheidungsknoten wird das Ergebnis der Prüfung ausgewertet.
Nur im Fall einer positiven Prüfung werden nun die Sensoren eingeschaltet und mit der folgenden Gabelung zwei parallele Abläufe angestoßen. Während die Anlage nun regelmäßig die Sensoren auf Funktionsfähigkeit abfragt und parallel dazu auf eingehende Meldungen wartet, macht sich unser Anfänger-Einbrecher an einem Fenster zu schaffen und löst damit eine Signal-Sende-Aktion (engl. Signal Send Action) Einbruch! aus. Der entsprechende Sensor wartet geradezu auf ein solches Signal, über die entsprechende Ereignis-Empfangs-Aktion (engl. Accept Event Action) nimmt er das Signal entgegen und führt dann die Aktion Sensorauslösung melden durch. Die notwendigen Aktionen, um den Alarm zu deaktivieren, haben wir zu einer eigenen Aktivität zusammengefasst. Damit können wir diese in anderen Diagrammen als zusammengesetzte Aktion verwenden.
Aktivitäten einer Alarmanlage
Aktivitätsdiagramme bieten neben den dargestellten Komponenten noch eine ganze Reihe weiterer Modellierungsmittel. Wichtig ist an dieser Stelle noch die Möglichkeit, Schleifen und Auswahlbedingungen explizit über Schleifen- und Bedingungsknoten darzustellen. Außerdem lassen sich sowohl für Aktionen als auch für Aktivitäten Vor- und Nachbedingungen angeben.
Zustandsdiagramm
Kurz und bündig: Zustandsdiagramm
Einer der großen Vorteile von objektorientierten Systemen ist es, dass die Zustände des Systems in klar definierten Komponenten, den Objekten, verwaltet werden. Dadurch können wir den Objekten einen klaren Lebenszyklus und definierte Zustände zuordnen.
Über die Sicht auf Zustände können wir ein System unter einem anderen Blickwinkel betrachten, als es bei den Aktivitäten der Fall ist. Zwar spielen bei der aktivitätszentrierten Sicht durchaus auch Zustandsinformationen eine Rolle, bei den Zustandsdiagrammen stehen die Zustände aber im Fokus.
Die in der UML definierten Zustandsdiagramme helfen uns, die verschiedenen Zustände, die ein Objekt oder eine Gruppe von Objekten durchlaufen, darzustellen und zu verstehen. In Abbildung 7.32 ist eine typische Anwendung eines UML-Zustandsdiagramms dargestellt. Wir beschreiben damit die verschiedenen Zustände einer Alarmanlage.
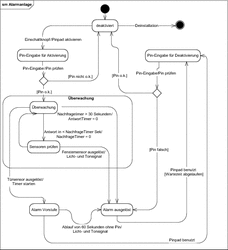
Abbildung 7.32 Zustandsübergänge einer Alarmanlage
Die Alarmanlage kennt in diesem Szenario die Zustände deaktiviert, Pin-Eingabe für Aktivierung, Pin-Eingabe für Deaktivierung, Überwachung, Sensoren prüfen, Alarm Vorstufe, Alarm ausgelöst. Bei dem Zustand Überwachung handelt es sich allerdings um einen zusammengesetzten Zustand, der intern aus weiteren Zuständen aufgebaut ist.
Zustände einer Alarmanlage
Im ersten Zustand, den wir vom Startzustand unseres Diagramms erreichen, ist die Alarmanlage deaktiviert. Die weiteren Übergänge zwischen den Zuständen, die durch gerichtete Verbindungen dargestellt werden, sind mit zusätzlichen Informationen angereichert.
Ereignis Bedingung Aktion
Nehmen wir als Beispiel den Übergang vom Zustand Alarm Vorstufe zum Zustand Alarm ausgelöst. Dem Diagramm lässt sich entnehmen, dass der Zustandsübergang durch das Ereignis Ablauf von 60 Sekunden ohne Pin ausgelöst wird. Nach Auslösen des Türsensors beim Öffnen der Eingangstür haben wir 60 Sekunden Zeit, um den Alarm zu deaktivieren. Läuft diese Zeit ab, ohne dass eine Pin-Eingabe stattfindet, wird die Aktion Licht- und Tonsignal durchgeführt, und die Anlage begibt sich in den Zustand Alarm ausgelöst. Dieser Übergang wird in jedem Fall so stattfinden, wenn das angegebene Ereignis eintritt.
Wir haben aber auch einen Übergang aus dem Zustand Pin-Eingabe für Aktivierung, bei dem erst aufgrund des Ergebnisses der erfolgten Aktion Pin prüfen entschieden werden kann, welcher Folgezustand resultiert. Die zugehörige Entscheidung basiert auf zwei Bedingungen: Ist die Bedingung [Pin ok] erfüllt, erfolgt der Übergang in den Zustand Überwachung. Ist die eingegebene PIN dagegen falsch, landen wir wieder im Zustand deaktiviert.
Explizite Modellierung von Zuständen
Eine explizite Modellierung von verschiedenen Zuständen ist aber nicht nur bei technischen Abläufen sinnvoll, wie sie bei einer Alarmanlage, einer Zapfsäule oder einem Bankautomaten auftreten. Gerade bei Anwendungen, bei denen die Zustände nicht so offensichtlich zu greifen sind, macht es Sinn, diese Zustände explizit zu machen. In Abbildung 7.33 sind die verschiedenen Zustände eines Vertrags dargestellt, der zwischen einem Kunden und dem Anbieter einer Dienstleistung geschlossen wird. Der Vertrag durchläuft dabei die Zustände in Planung, in Prüfung, aktiv, zur Kündigung vorgesehen und gekündigt.
Nehmen wir hier einmal als Beispiel den Übergang von einem bestehenden Vertrag zu einem Vertrag mit vorgesehener Kündigung heraus.
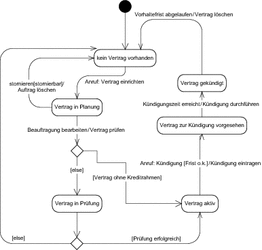
Abbildung 7.33 Beispiel für verschiedene Zustände eines Vertrags
Elemente des Diagramms
Im Diagramm lässt sich entnehmen, dass der Zustandsübergang durch das Ereignis Anruf: Kündigung ausgelöst wird, das den Anruf eines Kunden repräsentiert, der den Vertrag partout nicht mehr haben will. Allerdings gilt eine Bedingung Frist ok: Nur wenn die vereinbarten Fristen eingehalten wurden, wird die resultierende Aktion Kündigung durchführen auch wirklich durchgeführt und die Kündigung eingetragen. Wenn unser Kunde einen Vertrag mit zehnjähriger Laufzeit über eine wöchentliche Lieferung von schwarzen Socken abgeschlossen hat, diese jedoch nicht mehr benötigt, weil ihm beide Beine amputiert wurden: Sein Pech, unser Zustandsdiagramm sieht Ausnahmen nicht vor. Wenn der Kunde dann nach Ablauf der zehn Jahre wieder anruft, werden wir aber die Kündigung durchführen und den Vertrag in den Zustand gekündigt überführen. Löschen werden wir ihn allerdings erst nach Ablauf einer definierten Frist, weil wir immer noch damit rechnen, dass unser Kunde wieder anruft, um die Kündigung rückgängig zu machen und den Vertrag um weitere zehn Jahre zu verlängern.
Sequenzdiagramm
Eine andere Sicht auf die Interaktion von Objekten nehmen wir ein, wenn wir den Nachrichtenaustausch zwischen diesen Objekten beobachten oder modellieren.
Die Sequenzdiagramme der UML nehmen genau diese Sicht ein. Wir haben in Abbildung 7.34 unser Beispiel einer Alarmanlage wieder aufgegriffen und dabei einen möglichen Ablauf bei Aktivierung und Auslösung der Anlage aufgezeichnet. Die UML bietet auch Möglichkeiten, alternative Ablaufpfade in einem Sequenzdiagramm zu beschreiben. Allerdings führt dies zu zusätzlicher Komplexität der Diagramme, weshalb in der Praxis häufig die Darstellung genau eines konkreten Ablaufszenarios in Sequenzdiagrammen modelliert wird.
Sequenz beim Auslösen der Anlage
In unserem Beispieldiagramm von Abbildung 7.34 sehen wir die wichtigsten Bestandteile von Sequenzdiagrammen versammelt. Objekte und Akteure werden am Beginn ihrer jeweiligen Lebenslinien dargestellt. Die Lebenslinie unseres Akteurs Hugo (ein Hausbewohner) umfasst (glücklicherweise) den gesamten Ablauf. Dagegen wird ein Objekt vom Typ PinPrüfer während des Ablaufs zweimal erstellt und auch wieder zerstört, was sich an der entsprechenden Lebenslinie erkennen lässt, die jedes Mal durch ein terminierendes Kreuz beendet wird.
Unsere beteiligten Objekte und Akteure tauschen nun Nachrichten aus. Dabei markieren wir über sogenannte Aktivierungsbalken auf der Lebenslinie, ob ein Objekt gerade aktiv ist. Aktiv heißt hier, dass unser Objekt in irgendeiner Weise noch aktiv an der Sequenz beteiligt ist. Dies ist dann der Fall, wenn es gerade selbst eine Nachricht abarbeitet oder auf die Rückmeldung eines anderen Objekts wartet, dem gerade eine Nachricht geschickt wurde. Für unsere Alarmanlage endet zum Beispiel der Aktivierungsbalken zunächst, nachdem die Anlage Tür- und Fenstersensoren aktiviert hat. Danach ist sie in einem passiven Zustand, der erst durch die Auslösung eines Sensors und die entsprechende Benachrichtigung wieder unterbrochen wird.
Bei den Nachrichten wird unterschieden zwischen synchronen und asynchronen Nachrichten. Synchrone Nachrichten erfordern eine Rückmeldung, asynchrone nicht. Die Aufforderung der Alarmanlage zur PIN-Eingabe an unseren Hausbesitzer erfordert in unserem Beispiel die PIN als Rückgabe. Die Nachricht der Alarmanlage wird als durchgezogener Pfeil dargestellt, die Rückmeldung an die Alarmanlage unter Angabe der PIN durch einen gestrichelten Pfeil.
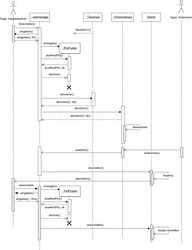
Abbildung 7.34 Ablaufsequenz beim Auslösen einer Alarmanlage
7.4.2 Nachrichten an Objekte
Wenn ein Objekt auf irgendeine Weise aufgefordert wird, eine Aktion auszuführen, sprechen wir davon, dass eine Nachricht an dieses Objekt gesendet wurde. Ganz konkret heißt das normalerweise, dass ein Objekt eine Operation auf einem anderen Objekt aufruft. Wenn das Objekt, das die Nachricht erhält, diese Operation unterstützt, wird es die Nachricht verarbeiten. Zur Verarbeitung wird eine Methode genutzt, die für dieses spezifische Objekt diese Operation umsetzt.
Allerdings: Völlig einfach läuft auch das nicht ab. Welche Methode denn nun genau aufgerufen wird, hängt aufgrund der möglichen Polymorphie, nun ja, von den Umständen ab. Dabei kommt die sogenannte Tabelle für virtuelle Methoden zum Einsatz. Das damit verbundene Thema ist »späte Bindung«. Welche komplexen Szenarien dabei ablaufen können, haben wir in Abschnitt 5.2.5, »Die Tabelle für virtuelle Methoden«, gesehen.
Eine Stärke der objektorientierten Systeme liegt darin, dass Sender und Empfänger der Nachricht nur sehr locker verbunden sein müssen. Durch verschiedene Möglichkeiten der Entkopplung können wir die Verbindung zwischen beiden Beteiligten lockern. Zum einen muss der Sender einer Nachricht nur minimale Information über den Empfänger haben. Er muss lediglich wissen, dass der Empfänger die betreffende Nachricht versteht.
Eine weitere Entkopplung ist über das Beobachter-Muster möglich, das wir in Abschnitt 5.4.1, »Mehrfachvererbung: Möglichkeiten und Probleme«, vorgestellt haben.
Durch den Mechanismus von Ereignissen können Nachrichten auch asynchron zugestellt werden. Dabei kennt der Sender die Empfänger der Nachricht überhaupt nicht. Ein von Sender und Empfänger unabhängiges Modul sorgt dafür, dass Ereignisse den Empfängern zugestellt werden, die sich für diese interessieren. In Abschnitt 7.4.4, »Funktionsobjekte und ihr Einsatz als Eventhandler«, gehen wir auf die Behandlung von Ereignissen genauer ein.
7.4.3 Iteratoren und Generatoren
Eine sehr häufige Aufgabenstellung in objektorientierten Anwendungen ist es, dass wir uns mit Sammlungen von Objekten beschäftigen müssen. Deshalb werden in der Regel große Teile unseres Codes damit zu tun haben, Objekte in Sammlungen einzufügen, sie dort wieder zu suchen oder einfach eine bestimmte Aktion auf allen Elementen der Sammlung auszuführen.
Für die Aufgabe, nacheinander die Elemente einer Sammlung zu durchlaufen, werden in der Regel die sogenannten Iteratoren eingesetzt. Diese bieten uns die Möglichkeit, die Elemente von Sammlungen schrittweise durchzugehen.
Richtig interessant wird die Arbeit mit Sammlungen allerdings dann, wenn eine Sammlung gar nicht komplett vorliegt, sondern erst nach und nach aufgebaut werden kann oder soll. In diesem Fall kommen wir mit Iteratoren nicht weiter. Wir müssen unseren Iterator zu einem Generator umbauen.
Wir werden in diesem Abschnitt zunächst auf Iteratoren und deren Funktionsweise eingehen. Dann folgt eine Bauanleitung für Generatoren. Am Beispiel eines Generators für die Zahlenreihe der Fibonacci-Zahlen werden wir die Funktionsweise von Generatoren vorstellen.
Diskussion: Wozu Generatoren?
Gregor: Wie kann es denn sein, dass wir eine Sammlung nicht komplett vorliegen haben? Sammlungen von Objekten haben doch immer eine klar feststellbare Zahl von Elementen, also habe ich diese doch immer komplett vorliegen. Zum Beispiel lade ich einfach eine bestimmte Anzahl von Objekten aus der Datenbank, füge alle in eine Sammlung ein und fertig.Bernhard: Es gibt mehrere Situationen, in denen du möglicherweise eine Sammlung nicht komplett vorliegen hast. Zum Beispiel gibt es Zahlenreihen wie die Fibonacci-Zahlen, die eine unendliche Folge von Zahlen liefern. Wenn wir also die Sammlung aller Fibonacci-Zahlen erstellen wollten, müssten wir ganz schön viel Zeit einkalkulieren.
Gregor: O.k., aber das ist ja nun keine echte Sammlung von Objekten. Die Sammlung der Fibonacci-Zahlen enthält doch höchstens Wertobjekte. In normalen Geschäftsanwendungen werden wir auch eher selten die Fibonacci-Reihe benötigen.
Bernhard: Auch wenn wir Daten aus einer Datenbank laden, kann es sein, dass wir eine Sammlung nicht von Anfang an komplett füllen wollen oder können. Wenn eine Übersicht mehrere tausend Datensätze umfasst, macht es wenig Sinn, diese alle auf einmal in eine Sammlung einzufügen, da wir sicher nicht alle auf einmal anzeigen oder bearbeiten werden. Hier kann ein Generator von Vorteil sein, der bei Bedarf einen oder mehrere Datensätze zur Sammlung hinzufügt.
Da wir uns das Beispiel der Fibonacci-Zahlen vorgenommen haben, werden wir uns auch mit dem zugehörigen Algorithmus zu deren Berechnung beschäftigen. Wir stellen deshalb zunächst einige Vorüberlegungen dazu an, wie wir Algorithmen und andere Ablaufbeschreibungen in objektorientierten Systemen am besten repräsentieren.
Algorithmen als Routinen oder Objekte
Objekte und Routinen
Ein Objekt ist eine Einheit gekoppelter Daten und Prozesse. Darin unterscheiden sich die Objekte aber nicht wesentlich von Routinen. Diese haben auch Daten in der Form von Parametern und lokalen Variablen, und sie haben auch Verhalten – den programmierten Ablauf des Unterprogramms.
Unterschied Objekt und Routine
Wir finden aber auch relevante Unterschiede zwischen Objekten und Routinen.
- Die Lebensdauer Bei den Objekten ist sie selten vom Objekt selbst gesteuert, das Objekt wird durch andere Teile der Anwendung erzeugt und vernichtet. Eine Routine wird zwar durch andere Teile der Anwendung aufgerufen, wann sie beendet wird, steuert sie aber selbst.
- Die Funktionalität Ein Objekt kann mehrere Operationen unterstützen, die in beliebiger Reihenfolge oder sogar parallel aufgerufen werden können. Dagegen läuft eine Routine einfach sequenziell durch.
- Die Änderungen und der Auswertbarkeit des Zustandes Der Zustand eines Objekts kann im Laufe der Lebensdauer durch äußere Einflüsse geändert und kann zwischendurch abgefragt werden. Dagegen hängt der Zustand einer Routine ausschließlich von ihren Parametern, den Daten, auf welche die Routine selbst zugreift, und den internen Abläufen der Routine ab. Auf den Zustand einer Subroutine kann man von außen nicht zugreifen, erst wenn sie beendet ist, kann man ihr Ergebnis und die eventuell modifizierten Parameter abfragen. Die lokalen Variablen sind von außen nicht zugreifbar. Dabei kann das Ergebnis einer Routine eine ganze Liste von Daten sein, die während des Laufes der Routine aufbereitet wird.
Algorithmen als Routinen
Bestimmte Konzepte lassen sich allerdings viel einfacher in der Form eines Prozesses als eines Objekts darstellen. Solche Konzepte sind meistens Algorithmen mit einem fest vorgegebenen Ablauf, deren Zustand nur von den Parametern und den Daten, auf die der Algorithmus selbst zugreift, abhängig ist und wobei nur das Ergebnis des Algorithmus für den Rest der Anwendung relevant ist.
Die Form einer Routine ist für die Realisierung solcher Algorithmen gut geeignet. Problematisch ist diese Vorgehensweise, wenn das für den Rest der Anwendung relevante Ergebnis eines solchen Algorithmus nicht ein Wert (beziehungsweise ein Objekt), sondern eine ganze Reihe von Werten ist.
Sammlungen als Resultat von Routinen
In einem solchen Fall muss die Routine das Ergebnis zuerst komplett aufbereiten und es dann als eine Sammlung (engl. Collection) seinem Aufrufer bereitstellen. Dies ist dann unproblematisch, wenn der Aufrufer das komplette Ergebnis tatsächlich auf einmal braucht – es ist aber weniger als optimal, wenn der Aufrufer nur die einzelnen Elemente des Ergebnisses nacheinander bearbeiten möchte.
Beschränkte Zahl von Ergebniselementen
Und Routinen sind ganz und gar ungeeignet, wenn der Aufrufer nicht alle Elemente der Ergebnisliste braucht, sondern nur eine beschränkte Zahl der Elemente vom Anfang der Liste. Dies ist ein häufiges Szenario, wenn es zum Beispiel um die Anzeige von Listen, die aus einer Datenbank befüllt werden, geht. Eine Datenbankabfrage kann keine, wenige, aber auch sehr viele Einträge zurückgeben. Wenn auf dem Bildschirm nur hundert angezeigt werden können, hat es wenig Sinn, mit der Anzeige erst zu beginnen, nachdem wir alle zehntausend Ergebniszeilen einer Datenbankabfrage übertragen haben.
Ein erster Ansatz: Iteratoren
In solchen Fällen können wir von den Mechanismen für Kapselung und Polymorphie der objektorientierten Sprachen profitieren. Der Aufrufer soll nicht von der konkreten Implementierung einer gelieferten Sammlung abhängig sein, sondern nur von deren Schnittstelle. Eine Sammlung kann verschiedene Operationen anbieten. Es können Elemente eingefügt werden, diese können wieder entfernt werden, wir können überprüfen, ob ein Element in der Sammlung enthalten ist oder wie viele Elemente die Sammlung enthält.
Aber: In unserem Falle brauchen wir das eigentlich gar nicht. Wir brauchen nur die Fähigkeit der Sammlung, ihre Elemente nacheinander zu liefern – sie abzählen zu lassen. Der Nutzer der Sammlung muss also nur imstande sein, eine Abzählung der Elemente der Sammlung zu starten, nacheinander nach dem nächsten Eintrag zu fragen und am Ende festzustellen, dass alle Elemente abgezählt worden sind.
Methode next()
Also bräuchten wir nur eine Methode next(), die am Anfang das erste und danach immer das nächste Element liefert. Und eine Methode hasNext(), die false zurückgibt, wenn alle Elemente abgezählt worden sind.
Nun, es kann mehrere Benutzer der Sammlung geben, die ihre Elemente unabhängig voneinander abzählen möchten. Daher kann der Zustand der jeweiligen Abzählung nicht der Sammlung selbst zugeordnet werden, sondern einem neuen Objekt – einem Iterator. [In der Sprache PHP werden die Elemente eines Arrays mit der Funktion each abgezählt. Der Zustand der Abzählung wird nicht in einem externen Iterator, sondern in dem Array selbst verwaltet. Daher kann ein Array in PHP nicht gleichzeitig von mehreren Benutzern abgezählt werden. Ein unschönes Element einer sehr nützlichen Programmiersprache. ]
|
Ein Iterator ist ein Objekt, das den Zustand einer Abzählung auf einer Sammlung verwaltet. Da sich der Zustand des Iterators unabhängig von der Sammlung verändern kann, werden solche Iteratoren auch externe Iteratoren genannt, um sie von ihren internen Kollegen, über die wir später sprechen werden, zu unterscheiden. In diesem Abschnitt werden wir auf das Wort »extern« der Einfachheit halber jedoch verzichten. |
Es ist der Iterator, der die Operationen next() und hasNext() anbietet. [Die Operationen next() und hasNext() sind nur eine Möglichkeit, wie man die Schnittstelle eines Iterators gestalten kann. Eine andere Möglichkeit wäre, auf die Methode hasNext() zu verzichten und am Ende einer Abzählung von next() den Wert NULL zurückgeben zu lassen oder eine Exception zu werfen. Wieder eine andere Möglichkeit wäre, dass die Methode next() nicht den nächsten Eintrag liefert, sondern true, wenn es einen nächsten Eintrag gibt, und false, wenn die Abzählung beendet ist. Auf den aktuellen Eintrag könnte man dann mit einer anderen Operation zugreifen. Auch wenn das Konzept eines Iterators ziemlich einfach ist, sind die Designmöglichkeiten vielfältig. ] Die Sammlung selbst muss aber eine Operation anbieten, die einen neuen Iterator erstellt und zurückgibt. Sie muss aber nicht, und das ist die Tatsache, die wir uns zunutze machen, alle Werte tatsächlich enthalten. Der gelieferte Iterator kann die Einträge erst bei Bedarf bereitstellen.
Ein Schritt weiter: Generatoren
Generatoren liefern Werte bei Bedarf
Ein Iterator, der die gelieferten Werte dynamisch bei Bedarf bereitstellt, wird Generator genannt.
Schauen wir uns nun unser bereits angekündigtes Beispiel an, die Berechnung der Fibonacci-Zahlenreihe. Die Fibonacci-Zahlen sind eine mathematische Folge von nichtnegativen ganzen Zahlen. Der Mathematiker Leonardo Fibonacci entwickelte sie 1202, um das Wachstum einer Population von Kaninchen zu beschreiben.
Die Fibonacci-Zahlen werden folgendermaßen definiert:
F1 = 1; F2 = 1; Fi; i>2 = Fi-2 + Fi-1
Das bedeutet in Worten: Für die beiden ersten Zahlen wird jeweils der Wert Eins vorgegeben. Jede weitere Zahl ist die Summe ihrer beiden Vorgänger. Daraus ergibt sich die Folge zu 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, ...
Berechnung der Fibonacci-Zahlen
Der Algorithmus zur Berechnung der Fibonacci-Zahlen könnte folgendermaßen aussehen:
a := 1;
b := 1;
wiederhole:
füge a zum Ergebnis hinzu;
c := a;
a := b;
b := a + b;
Umsetzung mit Python
Was hier bereits auffällt: Die Wiederholung hat keine Abbruchbedingung. Wir können die Reihe unendlich lange fortsetzen.
Nun sollen wir diesen Algorithmus in ein Programm umwandeln, das eine bestimmte Anzahl der Fibonacci-Zahlen ausgibt. In Listing 7.27 ist eine erste Version zu sehen, diesmal umgesetzt in der Sprache Python.
def printFibonacci(count):
a = 1
b = 1
while (count > 0):
print a,
c = a
a = b
b = a + c
count -= 1
Listing 7.27 Berechnung der Fibonacci-Zahlen mit Python
Problem 1: Berechnung und Ausgabe vermischt
Die Version ist schon ganz in Ordnung, allerdings hat sie einen Makel: Sie vermischt die Beschaffung der Ergebnisse, in unserem Falle die Berechnung der Fibonacci-Zahlen, mit deren Bearbeitung, in unserem Falle deren Ausgabe. Wir sehen hier einen Fall der Kopplung, die wir ja zu minimieren versuchen. Was wäre, wenn wir mit den Ergebnissen des Algorithmus andere Pläne hätten, zum Beispiel einen anderen Algorithmus sukzessive damit aufzurufen?
Versuchen wir also, die Berechnung der Zahlen von deren Ausgabe zu trennen. In Listing 7.28 sehen Sie eine angepasste Version unseres kleinen Programms, die zwei separate Routinen verwendet.
def computeFibonacci(count):
a = 1
b = 1
result = []
while (count > len(result)):
result.append(a)
c = a
a = b
b = a + c
return result
def printFibonacci(count):
for f in computeFibonacci(count):
print f,
Listing 7.28 Berechnung und Ausgabe getrennt
Problem 2: Speicherbedarf abhängig von Anzahl
Das sieht schon etwas besser aus. Wir haben den Makel der Kopplung beseitigt und den Algorithmus in der Methode computeFibonacci von der Ausgabemethode entkoppelt. Allerdings haben wir uns ein anderes Problem eingehandelt: Das Ergebnis wird zuerst in einer dynamisch wachsenden Liste gespeichert und erst nach der Berechnung ausgegeben. Das ist unangenehm, wenn die Anzahl der Fibonacci-Zahlen, die wir ausgeben möchten, sehr groß ist. Das ursprüngliche Programm hatte konstanten Speicherbedarf, der Speicherbedarf unserer aktuellen Version ist von der Anzahl der auszugebenden Zahlen linear abhängig.
Lösung: Generator für Fibonacci-Zahlen
Das können wir besser! Wir schreiben uns einfach einen Generator.
class FibonacciGenerator:
def __init__(self, count):
self.__count = count
self.__a = 1
self.__b = 1
def next(self):
if (self.__count <= 0):
raise StopIteration
self.__count -= 1;
c = self.__a
self.__a = self.__b
self.__b = self.__a + c
return c
def printFibonacci(count):
generator = FibonacciGenerator(count)
for i in range(count):
print generator.next(),
Listing 7.29 Generator für Fibonacci-Zahlen
Wir haben die Funktion computeFibonacci in eine Klasse FibonacciGenerator umgewandelt (Zeile ). Exemplare der Klasse werden in Zeile mit dem Parameter count der ursprünglichen Funktion initialisiert. Außerdem besitzt die Klasse Objektvariablen a, b und c, die in den mit markierten Zeilen verwendet werden. Diese entsprechen den lokalen Variablen der Funktion. In Zeile sehen Sie die Methode next(), die nacheinander die Fibonacci-Zahlen zurückgibt. Wir haben damit den Algorithmus zur Erzeugung der Zahlenreihe als Objekt implementiert. In den Zeilen und wird der Generator konstruiert und verwendet.
Entkopplung erfolgreich
Um die Zahlen ähnlich wie die Liste, die von der ursprüngliche Funktion zurückgegeben wurde, in einer for-Schleife benutzen zu können, brauchen wir nur eine kleine Erweiterung. Wir müssen eine Sammlung programmieren, die den Generator als ihren Iterator zurückgibt. [Iteratoren sind Bestandteile der Sprache Python seit der Version 2.2. ] Unser endgültiger Quelltext ist in Listing 7.30 dargestellt.
class FibonacciNumbers:
def __init__(self, count):
self.__count = count
class FibonacciGenerator:
def __init__(self, count):
self.__count = count
self.__a = 1
self.__b = 1
def next(self):
if (self.__count <= 0):
raise StopIteration
self.__count -= 1;
c = self.__a
self.__a = self.__b
self.__b = self.__a + c
return c
def __iter__(self):
return FibonacciNumbers.FibonacciGenerator(
self.__count)
def printFibonacci(count):
for f in FibonacciNumbers(count):
print f,
Listing 7.30 Ein Generator wird von einer Sammlung geliefert.
Nun liefert ein Exemplar der Klasse FibonacciNumbers ein Exemplar der Klasse FibonacciGenerator, wenn es nach seinem Iterator befragt wird. Dies wird in Zeile so deklariert. In der for-Schleife von Zeile verwendet Python dann automatisch den Iterator, um die jeweils nächsten Elemente abzuholen.
Eine schöne Sache, nicht wahr? Wir haben die Berechnung der Fibonacci-Zahlen von deren Verarbeitung entkoppelt, und der Speicherverbrauch ist konstant wie bei der ursprünglichen Prozedur.
Diskussion: Weitere Abhängigkeiten
Bernhard: Sieht ja zunächst recht gut aus. Aber so völlig entkoppelt ist das Ganze dann doch noch nicht.Gregor: Was meinst du damit? Unser Generator hat doch nun mit der Ausgabe der von ihm generierten Zahlen überhaupt nichts mehr zu tun.
Bernhard: Das ist schon richtig, aus Sicht des Generators haben wir keine Abhängigkeit mehr. Aber wenn wir unsere Methode zur Ausgabe der Zahlen anschauen, ist diese umgekehrt auf den Generator angewiesen. Sie kann nicht verwendet werden, um die Ergebnisse einer anderen Funktion aufzubereiten. Wenn wir die Ergebnisse eines Generators für die Ackermann-Funktion ausgeben wollen, müssen wir dafür eine eigene Methode schreiben.
Gregor: Da hast du allerdings Recht. In unserem Fall ist das zwar kein großes Problem, weil unsere Ausgabemethode so einfach ist und ihre Mehrfachverwendung uns nicht sehr viel an Code einsparen wird. Aber wenn die Ausgabe komplexer wäre, zum Beispiel die Ergebnisse als kleines Feuerwerk auf den Bildschirm zaubern, dann hätten wir durchaus ein Problem, diese Ausgabe erneut zu verwenden. Eine mögliche Lösung ist die Verwendung von Funktionen als Parameter für andere Funktionen. In Abschnitt 7.4.4 werden wir Beispiele für die Behandlung von Funktionen als Objekte kennen lernen.
Wir haben im obigen Beispiel gesehen, wie wir einen Generator für Fibonacci-Zahlen umsetzen können. Dadurch haben wir elegant eine Umsetzung der Berechnung erreicht und erhalten außerdem die Elemente der Reihe eins nach dem anderen geliefert.
Zusatzaufwand für Generatoren
Aber nichts auf dieser Welt gibt es völlig kostenlos. Wir haben auch gesehen, dass wir mehr Quelltext für die Implementierung des Algorithmus brauchen. Außerdem ist der Ablauf der ursprünglich prozeduralen Beschreibung des Algorithmus durch die Struktur der Klasse nicht mehr so klar wie vorher. Bei unserem Beispiel mit den Fibonacci-Zahlen mag dieser Nachteil klein erscheinen. Bei komplizierten Abläufen kann es allerdings ein recht großer Aufwand sein, eine Funktion in einen Generator umzuwandeln.
Es hängt sehr stark von der Unterstützung durch die Programmiersprache ab, ob sich der Aufwand, einen Generator zu schreiben, rechnet. Betrachten wir zunächst die Möglichkeiten, Generatoren in Java umzusetzen.
Generatoren für Java
In Java ist der Aufwand, einen Generator zu programmieren, höher als der Aufwand, den man für eine entsprechende Methode braucht. Daher werden Generatoren in Java kaum verwendet. Eine wichtige Ausnahme sind Objekte, die für Datenübertragung zuständig sind, bei der die Beschaffung der kompletten Liste der Ergebnisse viel zu viel Zeit und/oder Speicher in Anspruch nehmen würde. Die JDBC-Recordsets oder die in Java allgegenwärtigen Streams und Readers kann man als etwas abgewandelte Generatoren betrachten.
Doch wir können Generatoren auch in Java in Form einer Methode programmieren. Ein Generator hat zwei Zuständigkeiten. Einerseits stellt er seinen Benutzern den Zugriff auf die gelieferten Werte zur Verfügung, andererseits beschafft er die Einträge.
Die Beschaffung der Werte können wir als eine Methode umsetzen, die in einem nebenläufigen Thread läuft und die beschafften Einträge in eine nur ein Element umfassende Queue abstellt, von wo diese vom Benutzer des Iterators abgefragt werden können.
Und genauso können wir eine Basisklasse für Generatoren implementieren. Die abstrakte Basisklasse übernimmt die Verantwortung für die Synchronisation mit dem nebenläufigen Thread und die Iteratorenfunktionalität. Die konkreten Implementierungen müssen nur den Algorithmus umsetzen.
Doch einen Nachteil hat diese Implementierung: Wenn nicht alle Werte des Generators ausgelesen werden, bleibt der nebenläufige Berechnungsthread in einem suspendierten Zustand und belegt Ressourcen, auch wenn der Generator nicht mehr gebraucht wird. Speicher- und Threadleck ante portas. [Wir haben die beschriebene Umsetzung eines Generators in Java hier nicht im Source-Code gelistet. Durch die mangelnde Unterstützung von Java für Generatoren ist die Lösung alles andere als elegant. Wer die Umsetzung trotz dieser Warnung sehen möchte, findet sie auf der Webseite zum Buch (www.objektorientierte-programmierung.de). ]
Aber es gibt auch Sprachen, die Generatoren direkt unterstützen und deren Implementierung sehr einfach machen. Python ab der Version 2.2 oder C# ab der Version 2 gehören in diese lobenswerte Kategorie.
Generatoren: einfach in Python oder C#
In diesen Sprachen entspricht der Aufwand, eine Funktion zu schreiben, genau dem Aufwand, einen Generator zu schreiben. Und die Form des Generator-Quelltextes entspricht auch dem Quelltext der entsprechenden Funktion. Denn die Verantwortung, die Ergebnisse abzählbar zu machen, übernimmt die Programmiersprache selbst. Unser Beispiel würde bei der Verwendung der Generator-Syntax in Python folgendermaßen aussehen:
def computeFibonacci(count):
a = 1
b = 1
while (count > 0):
yield a
c = a
a = b
b = a + c
count -= 1
Listing 7.31 Verwendung eines Sprachkonstrukts von Python als Generator
Generator als vollwertiges Objekt
Ja, der Quelltext ähnelt sehr einem Quelltext einer Funktion und unterscheidet sich von einer Funktion nur durch die Verwendung der Befehls yield, der dem Befehl return entspricht, aber statt einen Ergebniswert zurückzugeben und die Ausführung der Funktion zu beenden, bereitet er einfach einen Rückgabewert für den nächsten Aufruf der Methode next() des Generators vor. Der Generator ist dabei ein vollwertiges Objekt mit eigenem Zustand und eigener Lebensdauer, Objektvariablen und Methoden.
Eine Subroutine wird gestartet, und erst wenn sie fertig ist, kann sie ein Ergebnis liefern. Die aufrufende Routine wartet während der Ausführung der Subroutine, bis sie fertig mit ihrer Arbeit ist.
Generatoren sind Coroutinen.
Ein Generator dagegen kann als eine Routine betrachtet werden, die parallel zu der aufrufenden Routine läuft und immer bei Bedarf und auch wiederholt ein Ergebnis liefert. Aus diesem Grunde werden Generatoren auch Koroutinen genannt. Dabei kommt es nicht darauf an, ob die Koroutinen tatsächlich in einem separaten Thread wirklich parallel ausgeführt werden – dies wäre sogar, wenn es um die Übersichtlichkeit und Einfachheit der Abläufe geht, eher kontraproduktiv.
Vorteil: Ergebnismenge muss nicht begrenzt werden.
In unserem Beispiel hat der Generator immer eine endliche Liste von Ergebnissen geliefert. Bei einer dem Generator entsprechenden Funktion ist dies eine zwingende Anforderung, es sei denn, Ihr Rechner hat unbegrenzten Speicher und Sie haben unendlich viel Zeit. Bei einem Generator besteht keine Notwendigkeit, die Anzahl der gelieferten Ergebnisse zu begrenzen. [Diese Behauptung gilt nicht für unsere Implementierung in Java – es sei denn, Sie können den nebenläufigen Thread für die gesamte Restdauer der Anwendungslaufzeit tolerieren. ] Der Konsument der Werte kann selbst bestimmen, wie viele Werte er von dem Generator abfragt. [Wenn Sie einen unbegrenzten Generator in einer for–Schleife verwenden, denken Sie immer daran, dass Sie die Schleife durch ein break- oder ein return-Statement beenden sollten. ] Hier unser Beispiel mit einem unbegrenzten Fibonacci-Zahlen-Generator:
![]() Unbegrenzter Fibonacci-
Generator
Unbegrenzter Fibonacci-
Generator
def computeFibonacci():
a = 1
b = 1
while (True):
yield a
c = a
a = b
b = a + c
def printFibonacciTo(limit):
for f in computeFibonacci():
if (f > limit):
break
print f,
Listing 7.32 Unbegrenzter Generator für Fibonacci-Zahlen
Diese Version des Generators beschreibt nun nachvollziehbar unseren Algorithmus und erstellt doch die Elemente der Reihe erst auf explizite Anfrage.
Im folgenden Abschnitt werden Sie sehen, wie in objektorientierten Systemen Routinen als Objekte abgebildet werden können. Dadurch können andere Objekte mit diesen Routinen parametrisiert werden.
7.4.4 Funktionsobjekte und ihr Einsatz als Eventhandler
Ziele dieses Abschnitts
In diesem Abschnitt werden Sie Objekte und Klassen kennen lernen, die auf Ereignisse in einer interaktiven Anwendung reagieren können. Diese sogenannten Eventhandler ermöglichen es, dass ganz unterschiedliche Oberflächenelemente die gleiche Aktion zugeordnet bekommen.
![]() Elemente einer Oberfläche
Elemente einer Oberfläche
Die meisten der heutzutage entwickelten Anwendungen sind interaktiv. Sie reagieren auf äußere Ereignisse: Eine grafische Benutzerschnittstelle reagiert zum Beispiel auf das Anklicken einer Maustaste, ein Webserver reagiert auf das Abrufen einer Webseite, die Software einer Alarmanlage muss auf die Meldungen der Bewegungssensoren reagieren.
Schauen wir uns die Strukturen und Abläufe der interaktiven Anwendungen etwas genauer an.
Nehmen wir an, Sie möchten in Ihrer grafischen Anwendung eine Schaltfläche haben, die einen Ausdruck des im Fenster dargestellten Dokuments auslösen kann, wenn ein Anwender darauf klickt. Ihnen stehen die nötigen Klassen zur Verfügung, die Schaltflächen auf dem Bildschirm implementieren. Sie können den Text und das Symbol der Schaltfläche darstellen, und die Schaltfläche wird bei Mausklicks und Tastatureingaben benachrichtigt. Aber noch keine dieser Klassen kann einen Ausdruck starten.
Eine Möglichkeit, die benötigte Umsetzung der gewünschten Drucktaste zu erhalten, ist, eine Ableitung der Klasse Schaltfläche zu erstellen und die Methode click so zu überschreiben, dass sie zusätzlich zur Änderung der Darstellung der Taste auch den Ausdruck startet. Diese Variante, dargestellt in Abbildung 7.35, führt aber dazu, dass Sie die Druckfunktionalität in jeder der Unterklassen genau gleich umsetzen müssten.
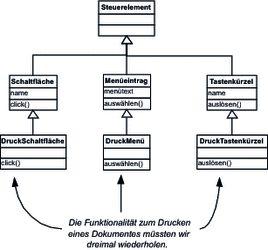
Abbildung 7.35 Nicht empfehlenswert: druckfähige Unterklassen
Hier hilft die Vererbung bei der Vermeidung der Redundanz nicht.
Die Verwendung der Vererbung an dieser Stelle ist also nicht ideal. Zwar würde die abgeleitete Klasse DruckSchaltfläche den Kontrakte der Klasse Schaltfläche erfüllen und so dem Prinzip der Ersetzbarkeit folgen, aber die Regel Wiederholungen vermeiden würden Sie dabei verletzen.
Das Ausdrucken eines Dokuments sollte nicht ausschließlich durch das Anklicken der Schaltfläche möglich sein. Sie möchten dem Benutzer auch einen Menüeintrag und ein Tastenkürzel anbieten. Dadurch müssten Sie in den Klassen DruckMenü und DruckTastenkürzel genau die gleiche Methode noch einmal implementieren.
Die Delegation ist hier die Lösung.
In den Abschnitten 5.4.2, »Delegation statt Mehrfachvererbung«, und 5.5.2, »Entwurfsmuster ›Strategie‹ statt dynamischer Klassifizierung«, haben Sie eine Designmöglichkeit kennen gelernt, die es Ihnen erlaubt, Objekten bestimmte Funktionalität zuzuordnen, ohne dass diese Objekte selbst Methoden für die gewünschte Funktionalität implementieren müssten: Lassen Sie die Objekte ihre Aufgabe an speziell zu diesem Zweck erstellte Hilfsobjekte delegieren.
Bei der Verwendung der Delegation anstatt der Vererbung leitet das Hauptobjekt Teile seiner Aufgaben an eine ihm bekannte Komponente weiter.
Wenden wir dieses Vorgehen auf unser Beispiel an, sieht die Situation bereits anders aus: Das Hilfsobjekt, das ein Dokument ausdruckt, wird sowohl einer Schaltfläche, einem Menüeintrag und auch einem Tastenkürzel, und vielleicht noch anderen Steuerelementen, zugeordnet. In Abbildung 7.36 ist die Modellierung so angepasst, dass die Aktion zum Drucken eines Dokuments nur noch einmal in der Klasse Ausdruck umgesetzt werden muss.
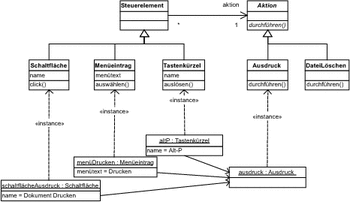
Abbildung 7.36 Verwendung von separaten Objekten zur Bearbeitung von Ereignissen
Die Schaltfläche für das Drucken gehört zu derselben Klasse Schaltfläche wie die Schaltfläche, die das Löschen eines Dokuments auslöst. Die Schaltflächen unterscheiden sich nur in ihren Eigenschaften und Beziehungen, sie gehören aber alle zur selben konkreten Klasse.
Die Ausführung der Aktionen Drucken, die durch ein Ereignis wie zum Beispiel einen Klick auf die Schaltfläche Drucken ausgelöst werden, ist an separate Objekte delegiert. Diese sind alle Exemplare der Klasse Ausdruck. Die Aufgabe dieser separaten Objekte ist es also, auf Ereignisse zu reagieren. Sie werden deshalb auch Eventhandler (Ereignisverarbeiter) genannt.
|
Ereignisverarbeiter sind Routinen, die aufgrund eines Ereignisses aufgerufen werden und die Aktion durchführen, die durch das Ereignis ausgelöst werden soll. In objektorientierten Systemen können diese Routinen als Objekte repräsentiert werden. Als Reaktion auf ein Ereignis wird in diesem Fall eine Operation dieses Objekts aufgerufen. |
Wir haben Eventhandler also als Routinen definiert. Wenn Sie sich das Beispiel in Abbildung 7.36 genauer anschauen, stellen Sie fest, dass die Exemplare der Klasse Aktion eine sehr einfache Schnittstelle haben. Sie bieten lediglich eine einzige Operation durchführen() an. Sie sind nur dazu da, um eine Methode bereitzustellen, die von verschiedenen Objekten zu verschiedenen Zeiten aufgerufen werden kann. Damit kapseln diese Objekte lediglich die Routine durchführen().
Daher wäre es eigentlich praktisch, wenn Sie gar keine eigene Klasse für diese Aktionen erstellen, sondern lediglich Routinen definieren müssten, die dann in verschiedenen Kontexten verwendet werden. Diese Möglichkeit bieten die sogenannten Funktionsobjekte.
|
Manche Programmiersprachen ermöglichen es, Routinen direkt als Objekte zu behandeln. Diese Objekte werden als Funktionsobjekte bezeichnet. In Programmiersprachen, die dieses Konzept unterstützen, müssen Sie also keine Klasse Aktion oder Ausdruck selbst programmieren, es reicht, wenn Sie eine Routine ausdruck() erstellen. Diese Routine wird dann als ein Objekt behandelt. Zu solchen Programmiersprachen gehören zum Beispiel Python, Ruby oder JavaScript. In ihnen sind die Routinen (Prozeduren, Funktionen, Methoden oder Blöcke) selbst Objekte. C# bietet unter dem Namen Delegaten (Delegates) ein Sprachmittel, das es ermöglicht, Objekte mit Funktionen zu parametrisieren. |
In Sprachen, die Funktionsobjekte direkt unterstützen, lässt sich unser Anwendungsbeispiel zur Druckfunktion umsetzen, ohne dass Sie eine eigene Klasse für die Aktion Drucken (und möglicherweise jede Menge anderer Aktionen) einführen müssen.
Drei Umsetzungsvarianten
In den folgenden Abschnitten stellen wir drei verschiedene Umsetzungsvarianten für unser Beispiel aus Abbildung 7.36 vor; eine davon in der Sprache Ruby, die Funktionsobjekte direkt unterstützt, in der also Routinen echte Objekte sind. Das zweite Beispiel stellen wir in Java vor. In Java sind Routinen nicht direkt als Objekte behandelbar. Schließlich stellen wir eine weitere Variante in C# vor. C# bietet ein spezielles Konstrukt, die Delegaten, mit denen sich Funktionsobjekte nachbauen lassen. [In C++ ist mit den sogenannten Funktionszeigern ein Konstrukt verfügbar, mit dem eine vergleichbare Funktionalität wie mit Funktionsobjekten umgesetzt werden kann. ]
Ein Beispiel in Ruby
![]() Routinen sind echte Objekte.
Routinen sind echte Objekte.
Als Erstes stellen wir eine Umsetzung unseres Beispiels in einer Sprache vor, die Routinen als echte Objekte behandelt. Die Umsetzung unserer Anforderung lässt sich in so einer Sprache direkt vornehmen.
In Listing 7.33 sehen Sie also eine Umsetzung in Ruby, bei der die Aktionen als anonyme Funktionen umgesetzt werden. [Anonyme Klassen und Methoden haben Sie bereits in Abschnitt 5.2.3 kennengelernt. ]
# Eine Taste, die eine Bezeichnung und eine Aktion verwaltet
class Schaltflaeche
def initialize(name, &aktion)
@name = name
@aktion = aktion
end
def click
@aktion.call
end
end
# Im Code des Dokumentfenstersclass DokumentFenster
...
def initialize
schaltflaecheAusdruck = Schaltflaeche.new("Drucken"){
@document.print
}
schalteflaecheLoeschen = Button.new("Löschen") {
@document.loeschen
}
}
Listing 7.33 Verwendung von Funktionsobjekten in Ruby
Exemplare der Klasse Schaltfläche werden in Zeile mit einer Aktion parametrisiert. [Die Eigenschaft aktion ist vom Ruby-Typ Proc. Procs sind Objekte, die eine Routine referenzieren können, die erst durch den Aufruf der Operation call ausgeführt wird. ] Bei Aufruf der Operation click, deren Umsetzung in Zeile zu sehen ist, wird die bei der Konstruktion übergebene Aktion über den Aufruf von call ausgeführt (Zeile ). Wenn nun ein Exemplar der Klasse DokumentFenster erzeugt wird, so werden dort zwei Exemplare von Schaltfläche erstellt. Das erste Exemplar erhält den Namen Drucken und bekommt außerdem eine anonyme Funktion übergeben, die selbst @document.print aufruft. Die zweite Schaltfläche wird in Zeile mit dem Namen Löschen und einer anderen anonymen Funktion parametrisiert, die wiederum @document.loeschen aufruft.
In unserem Beispiel bleiben die Funktionen zum Drucken und Löschen eines Dokuments anonym. Genauso gut könnten Sie diese aber auch einer Variablen zuweisen.
Routinen sind keine Objekte: Ein Beispiel in Java
Proc-Objekte in Ruby Python Java
In Java kann man die Methoden der Klassen nicht als Objekte behandeln. Um zum Beispiel einer Schaltfläche eine spezielle Aktion zuzuordnen, müssen Sie tatsächlich eine Klasse Ausdruck programmieren, wie im Beispiel aus Abbildung 7.36.
Da Sie in Java für die Umsetzung der Routinen also eine komplette eigene Klasse erstellen müssen, können Sie natürlich der Klasse Aktion auch mehr Verantwortung zuweisen, als nur eine Routine zu kapseln. Man kann ihr zum Beispiel den im Menü oder auf der Taste dargestellten Text oder das in einer Tastenleiste dargestellte Symbol zuordnen.
Java bietet eine Basisklasse für solche Aktionsklassen unter dem Namen AbstractAction an. Aber auch in Java lässt es sich vermeiden, eine komplett sichtbare eigenständige Klasse für eine solche Aktion umzusetzen. Dafür können Sie wieder die anonymen Klassen verwenden. [Siehe auch Abschnitt 5.2.3, »Anonyme Klassen«. ]
In Abbildung 7.37 sind die verwendeten Klassen dargestellt. Da UML sich mit anonymen Klassen etwas schwer tut, haben wir stellvertretend die Klasse AnonymousAction und ihr Exemplar ausdrucken aufgeführt.
Anonyme Klassen können innerhalb einer Methode deklariert werden, sie können dabei als eine Unterklasse einer benannten Klasse oder als eine Implementierung einer Schnittstelle erzeugt werden.
In Listing 7.34 ist die Implementierung aufgeführt. In Zeile wird dabei eine anonyme Unterklasse von AbstractAction deklariert und auch gleich ein Exemplar ausdrucken davon erstellt.
Die anonyme Klasse implementiert die Operation actionPerformed() in Zeile so, dass beim Erhalt eines Ereignisses das aktuelle Dokument gedruckt wird.
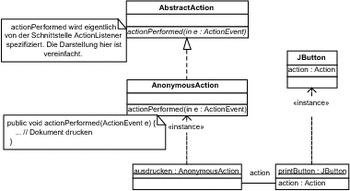
Abbildung 7.37 Aktion unter Verwendung einer anonymen Klasse
private void initComponents() {
Action ausdrucken = new AbstractAction("Drucken") {
public void actionPerformed(ActionEvent e) {
... // Dokument drucken
}
};
JButton printButton = new JButton();
printButton.setAction(ausdrucken);
...
}
Listing 7.34 Verwendung einer anonymen Unterklasse von »AbstractAction«
In Zeile wird die Aktion ausdrucken der neu erstellten Schaltfläche printButton (ein Exemplar von JButton) zugeordnet. So werden über printButton eintreffende Ereignisse die Aktion ausdrucken auslösen.
![]() Routinen können zu Objekten gemacht werden.
Routinen können zu Objekten gemacht werden.
Ein Beispiel in C#
C# verwendet zur Behandlung von Ereignissen sogenannte Delegaten-Klassen.
|
Delegaten-Klassen sind eine Spezialität von C#. Exemplare von Delegaten-Klassen erhalten bei ihrer Konstruktion eine Methode übergeben, die sie auf Anforderung ausführen. Die Signatur der Methode wird dabei durch die Klassendefinition festgelegt. Delegaten-Objekte sind damit also direkt durch die Übergabe von Methoden parametrisierbar. |
Die Verwendung der Delegaten-Klassen ist deshalb notwendig, weil C# als eine statisch typisierte Programmiersprache die Signatur für die verwendeten Funktionen deklarieren muss. Dies geschieht über die Klassendefinition.
Die Delegaten-Klassen, deren Exemplaren man entsprechende Methoden zuordnen kann, sind ziemlich speziell. Sie haben alle die gleiche Struktur und nur einen Zweck: Methoden zu kapseln. Sie sind so speziell, dass C# für die Deklaration dieser Klassen eine spezielle Syntax und das Schlüsselwort delegate vorgesehen hat.
![]() Schaltflächen
in C#
Schaltflächen
in C#
Betrachten wir zunächst unser Beispiel mit den Schaltflächen in einer Variante, die eine Delegaten-Klasse verwendet. In Abbildung 7.38 ist die Verwendung der in C# vordefinierten Klasse EventHandler dargestellt. Diese ist eine Delegaten-Klasse, so dass Sie Exemplaren dieser Klasse Methoden mit der deklarierten Signatur zuordnen können.
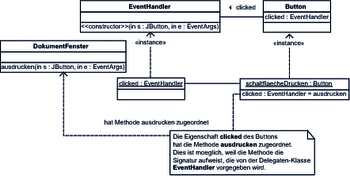
Abbildung 7.38 Verwendung der Delegaten-Klasse »Eventhandler«
Die Klasse EventHandler legt dabei fest, dass die ihr zugeordneten Methoden die Parameterleiste (object sender, EventArgs e) aufweisen müssen. Die Methode ausdrucken entspricht dieser Festlegung und kann so einem Exemplar der Klasse EventHandler zugeordnet werden. Das Objekt clicked, das in schaltflaecheDrucken enthalten ist, ist ein solches Exemplar.
In Listing 7.35 ist die Umsetzung zu sehen.
class Button {
public event EventHandler clicked;
// ...
}
class DokumentFenster {
// Die Methode zum Ausdrucken des Dokuments
public void ausdrucken(object sender, EventArgs e) {
// ... Ausdruck der Datei ...
}
Button schaltflaecheDrucken = new Button("Drucken");
schaltflaecheDrucken.clicked += ausdrucken;
}
Listing 7.35 Verwendung der Delegaten-Klasse EventHandler in C#
In Zeile ist zu sehen, dass die Klasse Button ein Exemplar der Klasse EventHandler besitzt. Wird nun wie in Zeile ein Exemplar von Button erstellt, so kann diesem eine Methode zugeordnet werden, die mit der Signatur von EventHandler kompatibel ist. In Zeile wird die Methode ausdrucken zugewiesen. Allgemein werden solche Delegaten-Klassen in C# und der ganzen .NET-Familie verwendet, um Beobachter über interessante Ereignisse zu informieren.
![]() Konverter als Delegaten
Konverter als Delegaten
Betrachten wir noch ein weiteres Beispiel, bei dem eine eigene Delegaten-Klasse verwendet wird. Um eine Klasse zur Kapselung einer Methode mit der Signatur (String str) und dem Rückgabetyp int zu deklarieren, reicht eine Zeile:
delegate int Converter(String str);
Der Konstruktor der Delegaten-Klasse Converter enthält als Parameter den Namen einer Methode, die bei der Verwendung eines Konverters aufgerufen werden soll. Listing 7.36 zeigt die Delegaten-Klasse im Einsatz.
public static int DecimalConversion(String str)
{
return Int32.Parse(str);
}
public static int HexadecimalConversion(String str)
{
return Int32.Parse(str,
System.Globalization.NumberStyles.HexNumber);
}
static void Main(string[] args)
{
Converter converter =
new Converter(HexadecimalConversion);
Console.Out.WriteLine(converter("100"));
}
Listing 7.36 Verwendung der Delegaten-Klasse Converter
In diesem Beispiel sind die zwei Methoden in Zeile und mit der vorher deklarierten Klasse Converter kompatibel. In Zeile wird der Konverter mit einer der beiden Methoden initialisiert. Beim folgenden Aufruf in Zeile wird dann auch die angegebene Konvertierungsmethode verwendet.
In C# können Sie einer Delegatenvariablen nicht nur ein Delegaten-Exemplar zuordnen, sondern gleich mehrere. So können Sie der Variablen converter noch ein anderes Exemplar der Klasse Converter hinzufügen:
converter += new Converter(DecimalConversion);
Jetzt würde C# bei dem Aufruf converter("100") beide Konvertierungsfunktionen aufrufen. Nun, in unserem Beispiel würde das kaum Sinn machen, da wir nur einen Rückgabewert bekommen: den, der von der zuletzt aufgerufenen Methode zurückgegeben wird.
Wenn es aber um die Signalisierung von Ereignissen an mehrere potenzielle Beobachter geht, kann die Zuordnung mehrerer Delegaten-Exemplare mit dem Rückgabetyp void sinnvoll sein.
7.4.5 Kopien von Objekten
Wir schicken in diesem Abschnitt zunächst einmal eine Frage vorweg: Wozu benötigen wir eigentlich Kopien von unseren Objekten?
Häufig werden Objekte als Vorlagen verwendet. Dabei wird auf der Grundlage eines bestehenden Objekts ein weiteres, zunächst genau gleiches Objekt erzeugt. Dieses wird dann in der Folge angepasst. So kann zum Beispiel eine Überweisung beim Online-Banking als Vorlage für weitere Überweisungen verwendet werden.
Auf einer technischen Ebene können Sie dagegen Kopien zum Beispiel verwenden, um sich Zustände von Objekten zu merken, die Sie später wiederherstellen wollen oder mit denen ein Abgleich stattfinden soll.
Vorlagen für Überweisungen
Ein Beispiel von Kopien, die von Vorlagen gemacht werden, sind die Überweisungsvorlagen, die Sie zum Beispiel beim Online-Banking verwenden. Dort können Sie eine einmal ausgeführte Überweisung an das Finanzamt als Vorlage speichern. Da Sie wissen, dass diese Überweisung leider nicht die letzte sein wird, können Sie alle Daten des Überweisungsobjekts speichern.
Wenn Sie die nächste Überweisung an das Finanzamt vornehmen, machen Sie auf Basis dieses Objekts eine Kopie, bei der Adressat, Bankleitzahl, Kontonummer und auch Betrag zunächst übernommen werden. In der Regel werden Sie dann aber den Betrag anpassen müssen. Das System wird bei Ausführung dann weitere Attribute wie zum Beispiel das Ausführungsdatum für Sie anpassen.
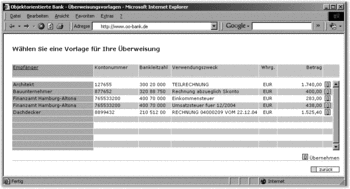
Abbildung 7.39 Vorlagen für Überweisungen
Nach Auswahl einer Überweisung wird zunächst eine exakte Kopie angelegt, bei der sich anschließend die einzelnen Attribute anpassen lassen (siehe Abbildung 7.40).
Kopie als Prototyp
Diese Art von Kopie agiert als Prototyp und sollte auch entsprechend verwaltet werden. Wir haben das entsprechende Entwurfsmuster in Abschnitt 7.1 bereits kurz vorgestellt. Sie erstellen dabei auf der Grundlage bereits vorhandener Daten ein neues Objekt und prägen dieses dann konkret aus. Dabei können natürlich auch Kopien von Sammlungen (Collections) angefertigt werden. Andere Arten von Kopien sollten auf einer fachlichen Betrachtungsebene nicht notwendig sein. Müssen Sie sich auf dieser Ebene doch auch mit anderen Arten von Kopien beschäftigen, fehlt oft eine Abstraktionsebene.
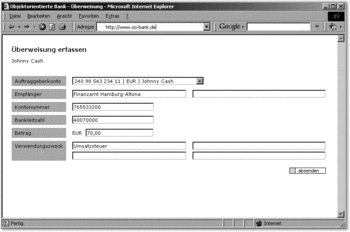
Abbildung 7.40 Kopie des Überweisungsobjekts
Copy-Konstruktor
Wie erstellen Sie nun eine solche Kopie von Objekten? Sie haben bisher zwei technische Möglichkeiten dafür kennen gelernt. In Abschnitt 7.1 haben wir die sogenannten Copy-Konstruktoren beschrieben, ebenso die Erstellung von neuen Objekten auf der Grundlage von Prototypen. Ein Copy-Konstruktor erhält bei der Konstruktion ein existierendes Exemplar einer Klasse übergeben und erstellt davon eine Kopie.
Um Kopien von Objekten herzustellen, hat der Copy-Konstruktor allerdings einen Nachteil: Der Aufruf eines Konstruktors kann nicht polymorph erfolgen, ist also nicht abhängig vom konkreten Typ des zu kopierenden Objekts. Es ist also durchaus ein Unterschied, ob Sie
MeinObjekt kopie = original.clone();
oder
MeinObjekt kopie = new MeinObjekt(original);
aufrufen. Auf den ersten Blick sieht es zwar so aus, als würden beide Aufrufe genau das Gleiche machen, nämlich eine exakte Kopie erstellen. Aufgrund der fehlenden dynamischen Polymorphie bei Konstruktoren ist das Verhalten der beiden Varianten aber unterschiedlich.
Copy-Konstruktor in Java
Wir betrachten zunächst einmal das Verhalten von Copy-Konstruktoren für diesen Fall. Nehmen Sie an, Sie haben eine Klasse Kunde vorliegen, außerdem eine Unterklasse für Geschäftskunden. Beide Klassen haben jeweils einen Copy-Konstruktor. In Abbildung 7.41 sind die Klassen mit ihren Konstruktoren dargestellt.
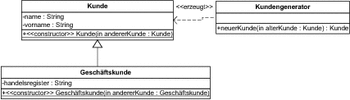
Abbildung 7.41 Copy-Konstruktoren für Kunde und Geschäftskunde
Aufgerufen wird der Konstruktor der Klasse Kunde in einer Methode neuerKunde der Klasse KundenGenerator. Diese erhält ein Exemplar der Klasse Kunde als Wert für den Parameter alterKunde übergeben. Da Geschäftskunde eine Unterklasse von Kunde ist, kann natürlich auch ein Exemplar der Klasse Geschäftskunde übergeben werden.
In Listing 7.37 ist die Java-Umsetzung der Operation neuerKunde und deren Verwendung gezeigt.
class KundenGenerator {
Kunde neuerKunde (Kunde alterKunde) {
return new Kunde(alterKunde);
}
public static void main(String[] args) {
KundenGenerator generator = new KundenGenerator();
Kunde kunde1 = new Kunde("Zuiop","Qwert");
Geschäftskunde kunde2 =
new Geschäftskunde("Zuiop","Qwert","HRB 112244");
Kunde neuerKunde1 = generator.neuerKunde (kunde1);
Kunde neuerKunde2 = generator.neuerKunde(kunde2);
}
Listing 7.37 Kopien durch Copy-Konstruktor
Die Methode neuerKunde in Zeile erstellt eine Kopie eines Exemplars der Klasse Kunde, indem sie den Copy-Konstruktor aufruft. In den Zeilen und wird dann jeweils ein Exemplar der Klasse Kunde und eines der Klasse Geschäftskunde erstellt. Beide werden nacheinander in den mit markierten Zeilen als Parameterwert an neuerKunde übergeben.
Nur Exemplar der Basisklasse
Wenn Sie danach die Klassenzugehörigkeit der beiden neu erstellten Objekte erfragen, erhalten Sie folgende Antwort:
Klasse des neuen Kunden kunde1: Kunde
Klasse des neuen Kunden kunde2: Kunde
Auch die Kopie des Geschäftskunden hat lediglich ein Exemplar der Klasse Kunde erzeugt, da unser Copy-Konstruktor nicht polymorph auf der Grundlage des übergebenen Objekts agiert.
Clone-Operation
Ein anderes Verhalten zeigt sich, wenn für die Kopien eine eigene Operation verwendet wird, um auf Basis eines existierenden Objekts eine Kopie davon zu erzeugen. Eine solche Operation wird als Clone-Operation bezeichnet. In Abbildung 7.42 sind die modifizierten Klassen dargestellt.
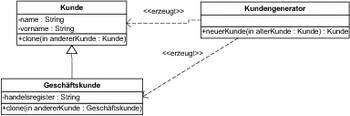
Abbildung 7.42 Kopien durch Clone-Operation
Wenn Kopien über die Clone-Operation erzeugt werden, ändert sich das Verhalten im Vergleich zu den Copy-Konstruktoren. Nun haben also sowohl die Klasse Kunde als auch die Klasse Geschäftskunde eine Operation clone zugeordnet. Exemplare der Klassen können damit also Kopien von sich selbst erzeugen.
Die Methode neuerKunde in der Klasse KundenGenerator ruft in dieser Variante keinen Copy-Konstruktor mehr auf, sondern die Operation clone auf dem übergebenen Exemplar der Klasse Kunde:
Kunde neuerKunde(Kunde alterKunde) {
return alterKunde.clone();
}
Wird mit dieser veränderten Variante erneut der Code von Listing 7.37 durchlaufen, weisen die kopierten Objekte die korrekte Klassenzugehörigkeit auf:
Klasse des neuen Kunden kunde1: Kunde
Klasse des neuen Kunden kunde2: Geschäftskunde
Durch das Erstellen einer Kopie über die Operation clone erhalten Sie also eine korrekte Kopie unserer Kundenobjekte, auch wenn es sich um Exemplare von Unterklassen handelt.
Die Operation clone in Java
| Die Operation clone in Java |
|
Die Behandlung der Clone-Operation in Java ist nicht völlig geradlinig. Die von der Klasse Object zur Verfügung gestellte Methode clone ist als protected deklariert. Sie kann damit von abgeleiteten Klassen, die eine öffentliche Operation für das Kopieren ihrer Exemplare zur Verfügung stellen, genutzt werden, um flache Kopien von Objekten zu erzeugen. Erst wenn abgeleitete Klassen eine Operation für das Erstellen von Kopien bereitstellen, kann diese auch genutzt werden. So weit, so verständlich. Allerdings gibt es nun zwei weitere Randbedingungen. Damit ein Objekt die Methode clone der Klasse Object nutzen darf, muss die zugehörige Klasse die Schnittstelle Cloneable implementieren. Die Dokumentation zu dieser Schnittstelle enthält die folgende Beschreibung: Bitte beachten Sie, dass diese Schnittstelle die Methode clone nicht enthält. Deshalb ist es nicht möglich, ein Objekt nur auf Grundlage der Tatsache, dass es die Schnittstelle implementiert, mittels clone zu kopieren. Auch wenn die clone-Methode über Reflection aufgerufen wird, besteht keine Garantie, dass dies erfolgreich sein wird. Objekte, welche die Schnittstelle Cloneable implementieren, weisen die Gemeinsamkeit auf, dass sie eine Kopie von sich anfertigen können. Sie können diese Eigenschaft aber nicht nutzen, weil in der Schnittstelle die entsprechende Operation nicht festgelegt wird. Eine Klasse könnte ihre Methode zur Erstellung einer Kopie also durchaus zum Beispiel reproduce nennen. Dies schränkt zum Beispiel sehr stark die Möglichkeiten ein, Sammlungen von Objekten über einen generischen Mechanismus zu kopieren. Für eigene Klassen gibt es natürlich die Möglichkeit, eine Erweiterung der Schnittstelle Cloneable zu definieren, die dann auch die clone-Methode spezifiziert. |
Formale Eigenschaften von Kopien
Betrachten wir jetzt auch einmal die formalen Eigenschaften, die wir einer Kopie zuschreiben:
- Die Kopie ist nicht identisch mit dem Original.
- Die Kopie gehört zur selben Klasse wie das Original.
- Die Kopie ist gleich dem Original, sofern wir keine Änderungen daran vorgenommen haben.
- Änderungen an der Kopie ändern nicht die Daten, die dem Original gehören.
Tiefe einer Kopie
Letztere Forderung bezieht sich auf die Unterscheidung einer Kopie des Inhalts gegenüber einer Kopie der Referenz. Wenn etwas als Bestandteil eines Objekts betrachtet wird, dann sollte auch nur dieses Objekt selbst die Möglichkeit haben, diesen Bestandteil zu ändern. Ob ein referenziertes Objekt nun in diesem Sinn Bestandteil eines anderen Objekts ist, kann aus der entsprechenden Klassendefinition nicht entnommen werden. Diese Einordnung gehört zur Metainformation, also zur Information über die entsprechende Klasse.
Wir müssen diese Information beim Erstellen von Kopien aber berücksichtigen und entscheiden, ob wir von einem referenzierten Objekt wiederum eine Kopie erstellen oder die Referenz einfach auf dasselbe Objekt setzen können.
Greifen wir unser Beispiel der Überweisungen, die als Vorlagen für andere Überweisungen dienen, nun wieder auf. Die Überweisung referenziert dabei eine Bankverbindung. Diese wiederum verweist auf eine Bank. In Abbildung 7.43 sind diese Beziehungen dargestellt.
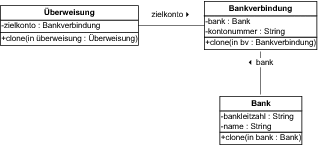
Abbildung 7.43 Von Überweisung referenzierte Objekte
Wenn Sie nun eine Kopie anlegen, dann wollen Sie sicherlich die Bankverbindung komplett kopieren. Wenn Sie hier einfach nur den Verweis auf das Objekt Bankverbindung übernehmen, würden mysteriöserweise in unserer Vorlage Änderungen an der Kontonummer auftauchen. In diesem Fall soll eine sogenannte tiefe Kopie der Bankverbindung erstellt werden. Gilt das aber auch für die über die Bankverbindung referenzierte Bank? Wenn Sie diese auch kopieren würden, wäre der Effekt doch eher merkwürdig. Es gäbe dann zum Beispiel die Kreissparkasse Stormarn mehrfach in Ihrem System. In diesem Fall würden Sie also beim Kopieren der Bankverbindung nur den Verweis auf die referenzierte Bank kopieren. Sie legen eine flache Kopie des Objekts an.
|
Beim Anlegen einer flachen Kopie eines Objekts werdem alle Datenelemente, die Basisdatentypen enthalten, kopiert. Weitere Objekte, die referenziert werden, werden aber nicht mitkopiert, sondern lediglich die Referenz auf diese Objekte. Beim Anlegen einer tiefen Kopie eines Objekts werden alle Datenelemente und alle referenzierten Objekte kopiert. Damit entstehen auch von den referenzierten Objekten Kopien, die anschließend verändert werden können, ohne dass diese dabei das Original modifizieren. Ob ein Objekt flach oder tief kopiert werden muss, ist meist eine fachliche Entscheidung. Wenn die Kopie modifiziert werden muss, ohne das Original zu verändern, so muss eine tiefe Kopie erstellt werden. |
Zyklische Referenzen
Ein Problem, das uns beim Kopieren plagen kann, ist das Auftreten von zyklischen Referenzen. Es kann niemand ausschließen, dass unsere Kopiermethode über eine Referenz auf ein Objekt trifft, das sie bereits einmal kopiert hat. Nur: Woher soll sie das wissen? Wenn Sie an dieser Stelle einfach weitermachen, haben Sie eine klare Endlosschleife vorliegen, unser Kopiervorgang wird zu keinem Ende kommen.
In manchen Anwendungen können Sie Annahme machen, dass es fachlich nicht notwendig ist, potenziell zyklische Beziehungen zu kopieren.
Nehmen Sie als Beispiel den Fall, dass ein Auftrag eine Liste von Positionen enthält, die jeweiligen Positionen wiederum eine Referenz auf den Auftrag. In diesem Fall ist es klar, dass das die erste Beziehung eine Kompositionsbeziehung ist. Ein Auftrag setzt sich aus den Positionen zusammen. Bei der Position wäre aber der referenzierte Auftrag nicht Bestandteil, so dass ein Kopieren nicht zulässig wäre.
Zyklen durch fehlerhafte Modellierung
Aber auch wenn Sie diese Annahme machen, so können zumindest durch fehlerhafte Modellierungen Zyklen auftreten. Sie würden diese Fehler aber nur sehr schwer finden können, da Ihr Programm sich in so einem Fall einfach nicht beendet. Um Zyklen erkennen zu können, müssen Sie beim Aufruf der Methode mitführen, welche Objekte Sie auf dem Weg zur aktuellen Aufrufstelle bereits kopiert haben. Dies können Sie zum Beispiel tun, indem Sie bei einem rekursiven Aufruf der Kopiermethode eine Liste mitgeben, in die das aktuelle Objekt mit aufgenommen wird. Mit der Methode clone(), die wir bereits diskutiert haben, ist das allerdings nicht möglich, da diese keine Parameter hat.
Betrachten wir nun ein einfaches Beispiel, bei dem Sie zyklische Verweise zwischen Objekten vorliegen haben. Nehmen Sie an, sie haben die Klassen A, B und C aus Abbildung 7.44 vorliegen, die sich gegenseitig referenzieren. Die Methode clone kopiert dabei jeweils das referenzierte Objekt mit.
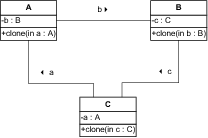
Abbildung 7.44 Zyklische Referenzen zwischen Objekten
In Listing 7.38 ist die Umsetzung der Operation für die drei Klassen aufgeführt.
class A implements Cloneable {
B b;
public A clone() throws CloneNotSupportedException {
A a = (A)super.clone();
b = b.clone();
return a;
}
}
class B implements Cloneable {
C c;
public B clone() throws CloneNotSupportedException {
B b = (B)super.clone();
c = c.clone();
return b;
}
}
class C implements Cloneable {
A a;
public C clone() throws CloneNotSupportedException {
C c = (C)super.clone();
a = a.clone();
return c;
}
}
Listing 7.38 Umsetzung der Operation »clone« für A, B und C
Die verschiedenen clone-Methoden rufen sich also wechselseitig auf, die Methode der Klasse A ruft zum Beispiel die Operation clone auf dem referenzierten Exemplar von B auf.
Endlosschleife
Wenn Sie nun versuchen, eine Kopie eines Exemplars von A zu erstellen, landen Sie in einer Endlosschleife:
C c = new C();
B b = new B();
A a = new A();
a.b = b;
b.c = c;
c.a = a;
A another = a.clone();
Mitführen von kopierten Objekten
Der Aufruf von a.clone wird nämlich auch b.clone aufrufen, dieses wiederum a.clone und so weiter. Der Aufruf wird also zu keinem Ende kommen. Diese Situation kann zum Beispiel durch eine Prüfung gegen eine mitgeführte Liste von Objekten korrigiert werden.
public A safeclone(LinkedList list)
throws CloneNotSupportedException {
if (list.contains(this)) return this;
LinkedList newlist = (LinkedList)list.clone();
newlist.add(this);
A a = (A)super.clone();
b = b.safeclone(newlist);
return a;
}
Listing 7.39 Prüfung auf zyklische Referenzen bei Kopien
In Listing 7.39 wird an die Methode safeclone() eine Liste übergeben, in der alle Objekte, die Sie gerade kopieren, enthalten sind. Wenn das aktuelle Objekt hier bereits auftaucht, was Sie über die Prüfung mit list.contains(this) feststellen, ist ein Kopieren nicht mehr notwendig, und Sie können direkt die Referenz zurückgeben. Im anderen Fall müssen Sie die Liste lokal um das aktuelle Objekt erweitern und übergeben diese dann in modifizierter Form an die weiteren Aufrufe der Kopiermethoden. [Die vorgestellte Methode soll nur das generelle Prinzip illustrieren. Durch das jeweils vorgenommene Kopieren der kompletten Liste mit bereits behandelten Objekten arbeitet diese Version nicht sonderlich effizient. ]
7.4.6 Sortierung von Objekten
Eine Aufgabenstellung, die neben dem Kopieren häufig auftaucht, ist das Sortieren von Objekten nach einem bestimmten Kriterium. Möglicherweise wollen Sie eine Liste von Objekten sortiert anzeigen oder einfach den Zugriff auf eine Sammlung von Objekten effizienter gestalten. Eine Suche in sortierten Sammlungen ist wesentlich effizienter als eine Suche in unsortierten Sammlungen. Ein anderer Grund kann es sein, eine Abarbeitungsreihenfolge für eine Sammlung von Objekten festzulegen.
Verantwortung für Vergleich
In der Praxis gibt es zwei gängige Möglichkeiten, um einen Vergleich bezüglich der Sortierung zweier Objekte durchzuführen:
- Sie können die Verantwortung für den Vergleich einem der beiden Objekte zuordnen.
- Sie bringen ein weiteres Objekt ins Spiel bringen, das den Vergleich durchführt (einen Vergleicher oder Komparator [Vergleicher ist zwar auch ein schöner deutscher Begriff, wir rechnen uns aber durch die Verwendung des Begriffs Komparator höhere Chancen dafür aus, dass wir die Filmrechte dieses Buchs nach Hollywood verkaufen können. ] ).
Beide Varianten haben ihre Vor- und Nachteile.
Schauen wir uns dazu jeweils Beispiele in der Programmiersprache Java an.
Java
Wir haben dabei eine Klasse Kunde vorliegen, die eine Eigenschaft prio (für die Priorität des Kunden) und eine Eigenschaft name deklariert.
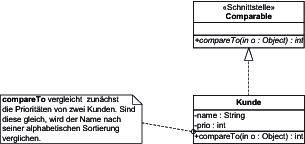
Abbildung 7.45 Sortierung von Kunden nach deren Priorität
Dadurch, dass die Klasse die Schnittstelle Comparable implementiert, ist sie in vielen Kontexten einsetzbar, die eine Sortierung erfordern. In Listing 7.40 Umsetzung einer Vergleichsoperation für Kunden dargestellt.
class Kunde implements Comparable {
Prioritaet prio;
String name;
public int compareTo(Object obj) throws ClassCastException
{
Kunde andererKunde = (Kunde)obj;
if (prio.value < andererKunde.prio.value) return –1;
if (prio.value > andererKunde.prio.value) return 1;
return name.compareTo(andererKunde.name);
}
}
Listing 7.40 Umsetzung einer Vergleichsoperation für Kunden
Ein Vergleich unter Verwendung der Methode compareTo() wird Ihre Kunden nun nach Priorität sortieren. Nur wenn die Prioritäten gleich sind, wird weiter nach dem Namen sortiert. Sind auch die Namen gleich, dann erfolgt keine weitere Sortierung mehr.
Es ist meistens vernünftig, die Methode, die eine Sortierung unterstützt, so zu implementieren, dass sie 0 zurückgibt, wenn der Vergleich der zwei Objekte mit der Methode equals() den Wert true zurückgibt, also dann, wenn die Objekte vollständig gleich sind. In unserem Beispiel ist das gegeben, denn bei vollständiger Gleichheit wird die Methode compareTo() der Klasse String das Resultat 0 liefern, wenn sie für das Attribut name aufgerufen wird.
Verschiedene Sortierkriterien
Nehmen Sie nun aber an, sie wollen Ihre Kunden in einer anderen Situation nicht nach Priorität, sondern einfach nach alphabetischer Reihenfolge des Nachnamens sortieren. Es gibt ja nicht nur die Vertriebssicht auf die Kunden.
Die bereits umgesetzte Methode compareTo() können Sie in diesem Fall nicht mehr verwenden.
Besser fahren Sie mit der Anwendung einer Vergleichsstrategie, einem Komparator-Objekt, das die Vergleiche zwischen zwei Objekten durchführt. [Dies ist ein weiterer Anwendungsfall für das Entwurfsmuster »Strategie«, das wir in Abschnitt 5.5.2, »Entwurfsmuster ›Strategie‹ statt dynamischer Klassifizierung «, vorgestellt haben. ] Java zum Beispiel bietet uns dafür bereits die Schnittstelle Comparator an, die von einer Komparator-Klasse implementiert werden kann. Damit verlagern Sie die Verantwortung für den Vergleich vom zu vergleichenden Objekt auf einen eigenständigen Komparator.
Der Komparator benötigt allerdings Zugriff auf die für einen Vergleich relevanten Daten der beiden betroffenen Objekte. In Abbildung 7.46 ist eine Variante unseres Beispiels dargestellt, die einen Komparator verwendet, anstatt die Vergleichsoperation der Klasse Kunde zuzuordnen.
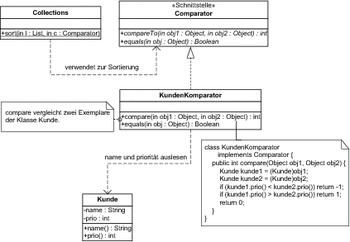
Abbildung 7.46 Verwendung einer Komparator-Klasse
In der Abbildung ist neben der Umsetzung der compare-Methode auch eine Verwendung des Komparators angegeben. Die Klasse Collections bietet eine statische Methode an, die eine übergebene Liste mit Hilfe eines ebenfalls übergebenen Komparators sortiert. In der Übersicht sehen Sie auch, dass über einen Komparator nicht nur eine Sortierung über compare() vorgenommen werden kann, sondern dass auch die Prüfung auf Gleichheit über die Methode equals() an ihn delegiert werden kann.
Komparator ist flexibler.
Diese Modellierung ist nun wesentlich flexibler, weil Sie das Sortierkriterium austauschen können, ohne in die Klasse Kunde eingreifen zu müssen. Sie hat allerdings auch einen Nachteil: Sie müssen dem Komparator Zugriff auf die vergleichsrelevanten Daten der Klasse Kunde ermöglichen. Im Fall der Priorität ist das kein Problem, da diese wahrscheinlich ohnehin zur Schnittstelle eines Kunden-Objekts gehört. In anderen Fällen kann es aber notwendig sein, dass eigentlich interne Daten für den Komparator offen gelegt werden.
Komparator oder Vergleichsmethode
| Sortierung und Vergleich über Komparator |
|
Bei der Abwägung, ob Sie eine Vergleichsoperation einem Objekt selbst oder einem Komparator zuordnen, sollten Sie zunächst darauf achten, ob es eine klare vorgegebene Reihenfolge für die Sortierung gibt. Bei der Klasse Datum gibt es beispielsweise eine intuitiv gültige Sortierung, die Datumsobjekte in eine Reihenfolge bringt. In solchen Fällen ist es sinnvoll, die Operationen für Vergleich und Sortierung dem Objekt selbst zuzuordnen. Wenn es allerdings ein solches eindeutiges Kriterium nicht gibt, sollten Sie eine Komparator-Klasse verwenden. Dadurch können Sie auch später weitere Sortierkriterien hinzufügen, ohne die Klasse der zu sortierenden Objekte anpassen zu müssen. |
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



