


7.2 Fabriken als Abstraktionsebene für die Objekterzeugung 

Bei der Erzeugung von Objekten über Konstruktoren müssen Sie bereits exakt wissen, von welcher Klasse ein Exemplar erzeugt werden soll. Damit haben Sie aber ein mögliches Problem in Ihre Module eingebaut, das Sie daran hindern könnte, das Verhalten eines Moduls zu erweitern oder eine Variante des Moduls einzuführen.
Nun hat sich ein Entwickler eines Moduls, der ein neues Objekt über einen Konstruktor erzeugt, zunächst einmal überlegt, warum er gerade den Konstruktor dieser Klasse aufruft. Was ist denn dann eigentlich das Problem?
Offen für Erweiterung, geschlossen für Änderung
Wie in anderen Fällen müssen Sie auch hier das Prinzip Offen für Erweiterung, geschlossen für Änderung im Blick behalten. Wenn Sie den Quellcode eines Moduls zu jedem Zeitpunkt beliebig ändern können und den Aufwand nicht scheuen, können Sie natürlich auch die Art der Objekterzeugung immer an Ort und Stelle anpassen.
Aber in vielen Fällen können Sie den Quellcode gar nicht modifizieren, z. B. weil er Ihnen gar nicht für Änderungen zur Verfügung steht. Selbst wenn Sie es können, sollte ein Modul nur dann geändert werden, wenn es unbedingt notwendig ist. Das Modul soll für Änderungen geschlossen sein. Es muss einen anderen Weg geben, um Varianten der Verwendung zu ermöglichen.
Und hier kommen die sogenannten Fabriken ins Spiel.
|
Eine Fabrik in der objektorientierten Programmierung ist ein Objekt, das andere Objekte erzeugt. Bei diesem Objekt kann es sich auch um die Repräsentation einer Klasse handeln. Je nach verwendeter Umsetzung einer Fabrik sprechen wir von einer statischen Fabrik, von Fabrikmethoden oder abstrakten Fabriken. |
Ein Vorgehen
Da Fabrik im Bereich der Objektorientierung ein sehr schillernder Begriff ist, haben wir mit der obigen Definition den kleinsten gemeinsamen Nenner gewählt. Eine Fabrik ist zunächst einmal kein Entwurfsmuster, sondern einfach ein bestimmtes Vorgehen bei der Objekterzeugung. Die zugehörigen Muster Statische Fabrik, Abstrakte Fabrik und Fabrikmethode werden wir in der Folge noch vorstellen. Es ist aber immer Vorsicht geboten, wenn jemand vom Entwurfsmuster »Fabrik« (oder vom Factory Pattern) spricht. Dann ist meist eine Nachfrage angebracht, welches Vorgehen denn nun genau mit diesem Begriff gemeint ist.
Diskussion: Erweiterungspunkte durch Fabriken
Bernhard: Fabriken können Programme aber auch komplexer machen. Sie sollten nur dort zum Einsatz kommen, wo spätere Erweiterungen zu erwarten sind.Gregor: Da muss ich sagen: Das hört sich ein bisschen danach an, als würdest du prophetische Fähigkeiten voraussetzen. Wenn wir vorher genau wüssten, wo unser Programm später erweitert werden soll, wären wir alle glückliche Softwareentwickler.
Bernhard: Der Hinweis bedeutet auch nur, dass wir nun nicht all unsere Objekterzeugungen in Fabriken kapseln sollen. Oft werden wir erst bei der ersten Änderungsanforderung feststellen, wo Änderungen durchgeführt werden müssen. Dann sollten wir nicht zögern und in diesem Zug unseren Code ändern und möglicherweise eine der Fabrikvarianten verwenden. Oft sind es auch Schwierigkeiten mit der Erstellung von Unit-Tests, die darauf hinweisen, an welchen Stellen noch Erweiterungspunkte notwendig sind.
Gregor: Stimmt, und immerhin gibt es ja Indizien, die darauf hindeuten, dass bestimmte Klassen zu einer Menge gehören, die sich laufend verändern wird. Wenn sich eine fachliche Klassenhierarchie schon zur Entwicklungszeit laufend weiter auffächert, ist dies zum Beispiel ein guter Hinweis darauf, dass das auch später noch so sein wird.
Der Einsatz von Fabriken unterstützt Sie bei der Einhaltung des Prinzips Offen für Erweiterung, geschlossen für Änderung und führt dazu, dass Ihre Programme besser erweiterbar bleiben.
![]() Webbrowser-Anwendung
Webbrowser-Anwendung
Nehmen Sie als Beispiel an, Sie möchten eine einfache Webbrowser-Anwendung umsetzen, die mit verschiedenen Kommunikationsprotokollen umgehen können soll. Dabei gibt es eine ganze Reihe von möglichen Protokollen, die Ihr Browser unterstützen soll. Neben den gängigen Protokollen wie http und ftp soll Ihre Anwendung auch für neue Protokolle erweiterbar sein.
Schauen Sie sich zunächst an, was passiert, wenn Sie in solchen Fällen keine Variante der Fabriken verwenden. In Abbildung 7.7 sind zwei verschiedene Handler für Kommunikationsprotokolle dargestellt, nämlich die Klassen HttpHandler und FtpHandler.
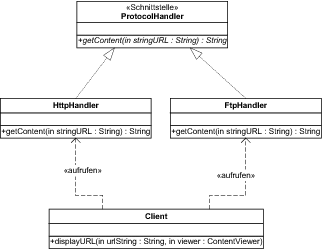
Abbildung 7.7 Verschiedene Handler für Protokolle
Beide implementieren die Schnittstelle ProtocolHandler und damit die Operation getContent, die zu einer URL den dahinter liegenden Inhalt in Form eines Strings liefern soll. [Wir gehen hier von der vereinfachenden Annahme aus, dass sich unter den verwendeten URLs immer Inhalt befindet, der sich als Text repräsentieren lässt. ] Der nutzende Klient entscheidet selbst, von welcher der beiden Klassen er ein Exemplar erstellen möchte. Wenn er den Inhalt anzeigen möchte, muss er außerdem dafür weitere Objekte heranziehen. Ein ProtocolHandler ist nur dafür zuständig, den Inhalt abzuholen und dabei das übergebene Protokoll zu berücksichtigen.
| Kleiner Exkurs: Protokolle und URLs in Java |
|
In den Bibliotheken von Java sind bereits Mechanismen enthalten, um mit verschiedenen URL-Typen und deren Protokollen umgehen zu können. Dabei wird über die Schnittstelle URLConnection eine Abstraktion verwendet, mit der ein einheitlicher Zugriff auf die verschiedenen Typen von URLs möglich ist. Das dabei verwendete Klassendesign ermöglicht es auch, eigene Handler zu implementieren und zu verwenden, indem Fabrikmechanismen eingesetzt werden. In den folgenden Abschnitten werden wir aber die von Java bereitgestellten Klassen nicht benutzen, sondern mit eigenen Umsetzungen die verschiedenen Varianten von Fabriken Schritt für Schritt illustrieren. |
Die Methode displayURL, innerhalb der ein ProtocolHandler ausgewählt wird, ist in Listing 7.5 dargestellt.
public void displayURL(String urlString,
ContentViewer viewer) {
URL url = new URL(urlString);
String sProtocol = url.getProtocol();
ProtocolHandler handler = null;
if (sProtocol.equalsIgnoreCase("HTTP") ) {
handler = new HttpHandler();
} else if (sProtocol.equalsIgnoreCase("FTP")) {
handler = new FtpHandler();
} else {
throw new RuntimeException("kein Bearbeiter für
die URL " + url + " gefunden ");
}
String content = handler.getContent(stringURL);
...
viewer.showContent(content);
}
Listing 7.5 Auswahl eines ProtocolHandlers
Dabei wird auf der Grundlage der übergebenen URL entschieden (), dann ein Exemplar angelegt und im Erfolgsfall darüber der Inhalt der betreffenden Webseite abgeholt .
Sieht zunächst einmal so aus, als würde das funktionieren. Wo liegt aber das Problem? Wir schauen uns das Problem und eine erste Lösung im nächsten Abschnitt genauer an.
7.2.1 Statische Fabriken
In der Regel werden Sie Exemplare der Klasse ProtocolHandler noch an anderen Stellen im Code benötigen. Bei der Anzeige einer kurzen Vorschau in einem anderen Browserfenster wäre zum Beispiel ein Einsatz ebenfalls notwendig. An diesen Stellen werden Sie also den Code zur Auswahl des korrekten Bearbeiters noch einmal schreiben müssen. Dies steht aber unserem Prinzip Wiederholungen vermeiden entgegen. Wenn es nun erforderlich wird, dass Ihre Anwendung ein weiteres Protokoll, zum Beispiel das Secure-Http-Protokoll, unterstützen soll, werden Sie Änderungen an mehreren Stellen im Code vornehmen müssen.
Dieses erste Problem können Sie durch den Einsatz einer statischen Fabrik lösen.
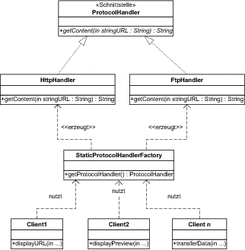
Abbildung 7.8 Statische Fabrik für »ProtocolHandler«
|
Der Einsatz einer statischen Fabrik kapselt die Erstellung von Objekten an einer zentralen Stelle im Code. Dabei wird meistens eine klassenbezogene Methode (statische Methode) verwendet. Diese wird statische Fabrikmethode genannt. Ist die konkrete Klassenzugehörigkeit des erzeugten Objekts vom Wert eines Parameters abhängig, handelt es sich um eine parametrisierte statische Fabrik. |
In Abbildung 7.8 ist das Beispiel der ProtocolHandler unter Verwendung einer statischen Fabrik StaticProtocolHandlerFactory dargestellt. Code-Redundanzen werden dabei vermieden, indem die Erzeugung von Exemplaren von ProtocolHandler an genau einer Stelle im Code, nämlich in der klassenbezogenen Methode getProtocolHandler, erfolgt.
Der Code, der vorher direkt vom nutzenden Client umgesetzt werden musste, ist nun in der statischen Fabrik gekapselt, deren Methode getProtocolHandler von verschiedenen Clients aufgerufen wird.
In unserem Beispiel würde die Nutzung der statischen Fabrik durch Client1 dann so aussehen:
ProtocolHandler handler =
StaticProtocolFactory.getProtocolHandler(stringURL);
String content = handler.getContent(stringURL);
...
viewer.showContent(content);
Zentrale Erzeugung von Exemplaren
Der Code zur Erstellung eines konkreten Exemplars wird dabei einfach in eine statische Methode einer eigenen Klasse ausgelagert. In Listing 7.6 ist die Umsetzung der statischen Fabrik dargestellt. Die statische Fabrikmethode getProtocolHandler übernimmt nun die Aufgabe, die korrekte Klasse auszuwählen, und liefert das erstellte Exemplar zurück.
class StaticProtocolFactory
{
static ProtocolHandler getProtocolHandler(
String stringURL) throws MalformedURLException
{
URL url = new URL(stringURL);
String sProtocol = url.getProtocol();
ProtocolHandler handler = null;
if (sProtocol.equalsIgnoreCase("HTTP") )
{
handler = new HttpHandler();
}
else if (sProtocol.equalsIgnoreCase("FTP"))
{
handler = new FtpHandler();
}
else
{
throw new RuntimeException(
"kein ProtocolHandler für die URL "
+ url + " vorhanden ");
}
return handler;
}
}
Listing 7.6 Umsetzung einer statischen Fabrik
Parametrisierte statische Fabrik
Mit dem Einsatz einer statischen Fabrik haben Sie eine zentrale Stelle geschaffen, an der alle Exemplare der Klasse ProtocolHandler erzeugt werden. Da die statische Fabrikmethode der Fabrik noch einen Parameter nimmt, anhand dessen erst der zu erstellende konkrete ProtocolHandler bestimmt wird, handelt es sich um eine parametrisierte statische Fabrik.
Diskussion: Wo bleibt die Flexibilität?
Gregor: Hm, so richtig beeindruckt bin ich noch nicht. Damit haben wir das Problem doch nur verlagert. Wenn wir ein neues Protokoll hinzufügen wollen, müssen wir die Fabrik wieder anpacken und den entsprechenden Bearbeiter dort konstruieren. Außerdem: Wenn ich nun auf die Idee komme, dass ich ganz andere Umsetzungen meiner Protokollbearbeiter brauche, dann muss ich direkt wieder in den Source-Code eingreifen, um hier eine andere statische Fabrik anzugeben.Erweiterbarkeit Austauschbarkeit
Bernhard: Das ist natürlich richtig. Was wir gemacht haben, ist einfach eine Vermeidung von Code-Redundanzen, außerdem haben wir eine definierte Stelle im Code geschaffen, an der bestimmte Objekte konstruiert werden. Den Nutzen einer solchen Kapselung sollten wir nicht unterschätzen.Aber du hast da gleich zwei Probleme auf einmal erwähnt: Zum einen ist es schwierig, ein neues Protokoll (zum Beispiel WAP) hinzuzufügen. Zum anderen können wir nicht einfach hingehen und unsere Protokollbearbeiter komplett austauschen (zum Beispiel um zum Testen immer simulierte Daten zu liefern).Probleme bei Erweiterbarkeit
Die Verwendung einer statischen Fabrik vermeidet zwar Code-Redundanzen, sie ist aber keine Lösung für zwei Problemfelder, die sich ergeben, wenn wir unser Modul erweitern wollen:
- Um ein neues Protokoll behandeln zu können, müssen Sie die statische Fabrik selbst anpassen.
- Ein Austausch der konkreten Realisierungen von ProtocolHandlern in verschiedenen Einsatzszenarien ist aufwändig. Zum Beispiel ist es nicht auf einfache Art möglich, Simulationen in Testszenarien zu verwenden.
Im folgenden Abschnitt stellen wir zunächst eine Lösungsmöglichkeit für das zweite Problem vor: die abstrakte Fabrik.
7.2.2 Abstrakte Fabriken
Abstrakte Fabriken ergeben sich als Erweiterung der bereits vorgestellten statischen Fabriken. Statische Fabriken haben den Nachteil, dass sie nicht austauschbar sind, weil statische Methoden nicht der dynamischen Polymorphie unterliegen.
Greifen wir zur Illustration unser Beispiel mit den verschiedenen Protokollen und deren Bearbeiterklassen wieder auf. Wären Sie nicht flexibler, wenn Sie hier die dynamische Polymorphie nutzen und auch die verwendete Fabrik austauschen könnten? Vielleicht wollen Sie Tests in Szenarien durchführen, in denen Sie gar nicht wirklich auf URLs zugreifen können. In diesem Fall wäre es wünschenswert, auf eine einfache Weise die entsprechenden Implementierungen der ProtocolHandler austauschen zu können.
Fabriken implementieren eine Schnittstelle.
Versuchen wir also, Nutzen aus der dynamischen Polymorphie zu ziehen. Wir lassen verschiedene Fabriken dieselbe Schnittstelle implementieren und verwenden nur diese Schnittstelle, wenn wir eine Fabrik benötigen. In Abbildung 7.9 sind die beteiligten Klassen aufgeführt.
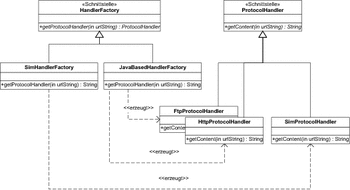
Abbildung 7.9 Abstrakte Fabrik für »ProtocolHandler«
Sie sehen dort, dass für die verschiedenen Varianten der Fabrik eine Schnittstelle HandlerFactory eingeführt wurde, welche die Operation getProtocolHandler spezifiziert. Die Schnittstelle wird realisiert von den beiden konkreten Klassen SimHandlerFactory und JavaBasedHandlerFactory. Dabei ist die SimHandlerFactory für Szenarien gedacht, in denen keine realen Daten verwendet werden können, zum Beispiel in einem Unit-Test. Deshalb wird diese in der Methode getProtocolHandler ein Exemplar von SimProtocolHandler erzeugen.
Die JavaBasedHandlerFactory dagegen wird das bereits bekannte Verfahren verwenden und abhängig vom jeweiligen Protokoll ein Exemplar von HttpProtocolHandler, FtpProtocolHandler oder einer anderen Realisierung zurückliefern.
Die Schnittstelle HandlerFactory wird als abstrakte Fabrik bezeichnet.
|
Eine abstrakte Fabrik stellt eine Schnittstelle für verschiedene konkrete Fabriken dar. Die abstrakte Fabrik definiert dabei eine oder mehrere Operationen, durch die wiederum abstrakte Produkte erstellt werden. Die Realisierungen einer abstrakten Fabrik, die konkreten Fabriken, setzen die vorgegebenen Operationen so um, dass sie Exemplare von konkreten Produktklassen erstellen. Durch die Nutzung einer abstrakten Fabrik ist es möglich, die erzeugten Produkte zu variieren, indem ein Austauch der konkreten verwendeten Fabrik erfolgt. |
Verwendung von abstrakten Fabriken
Um die Verwendung von abstrakten Fabriken zu illustrieren, nehmen wir das Beispiel aus Abbildung 7.9 wieder auf. In Listing 7.7 sind die beiden unterschiedlichen Realisierungen der Operation getProtocolHandler aufgeführt.
class JavaBasedProtocolFactory implements ProtocolFactory
{
...
ProtocolHandler getProtocolHandler(String urlString) {
ProtocolHandler handler = null;
if (sProtocol.equalsIgnoreCase("HTTP") )
{
handler = new HttpHandler();
}
...
}
}
class SimHandlerFactory implements HandlerFactory
{
ProtocolHandler getProtocolHandler(String urlString)
{
ProtocolHandler handler = new ProtocolHandlerSim ();
return handler;
}
}
Listing 7.7 Verschiedene Umsetzungen der Operation »getProtocolHandler«
Für den Fall der SimHandlerFactory wird für alle angeforderten Protokolle einfach ein Simulator zurückgegeben. Diese Fabrik können Sie also für Tests verwenden, wenn die eigentlich über eine URL referenzierten Daten nicht relevant sind.
Nutzung der Fabrik-Schnittstelle
Als Nutzer der Fabrik kommt eine Klasse BrowserView in Frage, die den gelieferten Inhalt in einem Browser anzeigen soll. Wird ein Exemplar der Klasse BrowserView erzeugt, bekommt es die zu verwendende Fabrik im Konstruktor übergeben. Anschließend verwendet die Klasse BrowserView die abstrakte Fabrik, um sich deren Produkt (ein Exemplar von ProtocolHandler) erstellen zu lassen. In Abbildung 7.10 sind die Nutzungsbeziehungen der beteiligten Klassen aufgeführt.
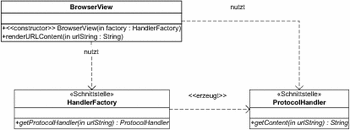
Abbildung 7.10 Anwendung der abstrakten Fabrik für »ProtocolHandler«
Abhängig davon, zu welcher konkreten Klasse die im Konstruktor übergebene Fabrik gehört, ergibt sich nun unterschiedliches Verhalten. Wird ein Exemplar von SimHandlerFactory bei der Konstruktion übergeben, wird BrowserView intern lediglich simulierte Daten verwenden. Wird ein Exemplar von JavaBasedHandlerFactory übergeben, wird auf die übergebene URL zugegriffen, und die Daten werden dort abgeholt. In Listing 7.8 ist die Umsetzung der Klasse BrowserView aufgeführt.
public class BrowserView {
private ProtocolFactory factory;
BrowserView(ProtocolFactory factory)
{
this.factory = factory;
}
void renderUrlContents(String stringURL) {
ProtocolHandler handler =
factory.getProtocolHandler(stringURL);
String content = handler.getContent(stringURL);
renderContent(content);
}
// ...
}
Listing 7.8 Umsetzung der Klasse »BrowserView«
Fabrik als Parameter
Nun können Sie den BrowserView mit einer Fabrik für Protokollbearbeiter parametrisieren. Abhängig von der übergebenen Fabrik wird er sich unterschiedlich verhalten.
Offen für Erweiterung
Sie haben dadurch die Möglichkeit, das Verhalten der konstruierten Exemplare der Klasse BrowserView zu beeinflussen, indem Sie die Fabrik Exemplare von konkreten Produkten konstruieren lassen. Damit haben Sie einen Erweiterungspunkt geschaffen, mit dem Sie das Verhalten von BrowserView beeinflussen können, ohne dass Sie die existierenden Klassen anpassen müssen. Dies unterstützt das Prinzip Offen für Erweiterung, geschlossen für Änderung.
In Listing 7.9 sehen Sie, wie zwei verschiedene konkrete Fabriken verwendet werden, um das interne Verhalten eines BrowserViews anzupassen.
JavaBasedProtocolFactory javaFactory =
new JavaBasedProtocolFactory();
SimProtocolFactory simFactory = new SimProtocolFactory();
BrowserView productionview = new BrowserView(javaFactory);
BrowserView testview = new BrowserView(simFactory);
productionview.renderUrlContents("http://www.mopo.de");
testview.renderUrlContents("http://www.mopo.de");
Listing 7.9 Verwendung von zwei verschiedenen konkreten Fabriken
Die beiden angelegten BrowserViews werden sich nun unterschiedlich verhalten. Der eine wird versuchen, die Webseite www.mopo.de zu erreichen, der andere wird einfachen simulierten Inhalt anzeigen.
Diskussion: Anpassungsaufwand in Fabriken
Gregor: O.k., wir können nun also die Art unserer Protokollbearbeiter austauschen. Das ist natürlich ganz nett, wenn uns die bisherigen zum Beispiel zu ineffizient werden und wir sie aus diesem Grund austauschen möchten. Aber wenn wir nun ein neues Protokoll hinzufügen wollen, sagen wir einmal für das WAP-Protokoll, dann müssen wir in diesem Fall ja sogar in alle vorhandenen Fabrik-Klassen eingreifen.Bernhard: An irgendeiner Stelle muss letztendlich entschieden werden, welche konkrete Klasse verwendet werden soll. Es kann immer nur darum gehen, diese Entscheidung an einer Stelle vorzunehmen, an der Änderungen möglichst selten zu erwarten und dann möglichst einfach vorzunehmen sind. Wenn wir unser Switch-Statement aber komplett loswerden wollen, müssen wir die Entscheidung, welche Protokollbearbeiter-Klasse angelegt wird, an eine komplett andere Stelle verlagern.
Gregor: Wohin können wir diese Entscheidung denn verlagern?
Bernhard: Wir können diese Entscheidung auch außerhalb des Programmcodes treffen lassen, indem wir die konkrete zu verwendende Klasse in einer Konfigurationsdatei festlegen. Eine andere Möglichkeit ist es, dass sich neue Klassen, die für ein bestimmtes Protokoll zuständig sind, mit einem spezifischen Exemplar bei einer Fabrik registrieren.
Erweiterung um neues Protokoll
Auch mit der eingeführten abstrakten Fabrik existiert in unserem Beispiel immer noch eine Einschränkung, die bei der Erweiterung um neue Protokolle hinderlich sein kann: Wenn Sie ein neues Protokoll unterstützen wollen, müssen Sie die betroffenen konkreten Fabriken wieder öffnen, um den neuen Protokolltyp hinzuzufügen. Das muss nicht unbedingt ein Problem sein. In vielen Fällen sind die Mechanismen der abstrakten Fabrik ausreichend, und eine Erweiterung um neue Produkte ist unwahrscheinlich oder kann im Quellcode vorgenommen werden.
Entscheidung verlagern
Wenn aber mit hoher Wahrscheinlichkeit neue Produkte hinzukommen, kann es sinnvoll sein, die Entscheidung über die konkreten Produkte weiter zu verlagern.
Hier haben Sie zwei praktikable Möglichkeiten:
- Sie lagern die Entscheidung in eine externe Konfiguration aus.
- Sie erstellen einfach von allen Protokollbearbeiter-Klassen Exemplare und lassen diese selbst entscheiden, ob sie ein Protokoll bearbeiten können.
Im folgenden Abschnitt lernen Sie die erste Variante kennen. Die zweite Variante stellen wir in Abschnitt 7.2.4, »Registraturen für Objekte«, vor.
7.2.3 Konfigurierbare Fabriken
Bei der Verwendung von Fabriken ist der entscheidende Punkt, an welcher Stelle im Programmcode die Entscheidung stattfindet, von welcher konkreten Klasse ein Exemplar erzeugt werden soll. Diese Entscheidung kann auch außerhalb des Programmcodes liegen, indem sie über eine externe Konfiguration vorgenommen wird. In diesem Fall liegt dann eine konfigurierbare Fabrik vor.
|
Eine konfigurierbare Fabrik verlagert die Entscheidung darüber, von welcher Klasse ein Exemplar erzeugt werden soll, in eine Konfiguration, die außerhalb des Programms liegt. Voraussetzung für den Einsatz einer konfigurierbaren Fabrik ist es, dass die verwendete Programmiersprache es erlaubt, erst zur Laufzeit zu entscheiden, zu welcher konkreten Klasse ein zu erstellendes Objekt gehört. |
Umsetzung in Java
Die Sprache Java bietet zum Beispiel die geforderten Möglichkeiten. Es ist möglich, über den Namen einer Klasse ein Exemplar dieser Klasse zu konstruieren. [Die Fähigkeit, Information über Klassen und andere Strukturen eines Programms zur Laufzeit auszuwerten und zu nutzen, wird Reflexion genannt. Wir stellen Reflexion in Kapitel 9, »Aspekte und Objektorientierung«, noch im Detail vor. ] Wir stellen im Folgenden an einem Beispiel in Java vor, wie eine statische Fabrik so modifiziert werden kann, dass sie über eine Datei konfigurierbar wird. In Abbildung 7.11 sind die erweiterten Nutzungsbeziehungen der statischen Fabrik dargestellt.
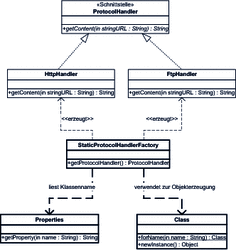
Abbildung 7.11 Umsetzung einer konfigurierbaren Fabrik
Die statische Fabrik nutzt zum einen die Klasse Properties, um aus einer Konfigurationsdatei den Namen der Klasse auszulesen, die für ein bestimmtes Protokoll zuständig ist. Zum anderen wird die Klasse Class verwendet, um neue Exemplare der ProtocolHandler zu erzeugen.
Wie genau das Erzeugen von neuen Exemplaren stattfindet, lässt sich am besten anhand der entsprechenden Umsetzung in Java erläutern. In Listing 7.10 ist eine konfigurierbare Fabrik aufgeführt. Die Fehlerbehandlung haben wir in diesem Beispiel aus Gründen der Übersicht weggelassen.
Entscheidung per Konfiguration
class StaticProtocolHandlerFactory {
public ProtocolHandler getProtocolHandler(
String protocol)
{
Properties properties = new Properties();
properties.load(new FileInputStream(
"factory.properties"));
String handler = properties
.getProperty(protocol);
Class classOfProtocolHandler =
Class.forName(handler);
ProtocolHandler protocolHandler =
(ProtocolHandler) classOfProtocolHandler
.newInstance();
return protocolHandler;
}
}
Listing 7.10 Umsetzung einer konfigurierbaren Fabrik in Java
Im Folgenden beschreiben wir Schritt für Schritt, was in diesem Stück Quellcode passiert.
Zunächst wird in Zeile ein Exemplar der Klasse Properties erzeugt. Über dieses Objekt können Werte zu Attributen aus einer Datei gelesen werden. In wird die verwendete Datei angegeben und eingelesen.
Klassenname aus Datei
Im Beispiel wird die Datei factory.properties genutzt, um eine Zuordnung zwischen dem Protokoll und der dafür verantwortlichen Klasse vorzunehmen. Die Einträge in dieser Datei enthalten in unserem Beispiel Zuordnungen für die Protokolle http und ftp:
http=de.galileocomputing.oobook.abstractfactory.HttpHandler
ftp=de.galileocomputing.oobook.abstractfactory.FtpHandler
In Zeile wird der zum übergebenen Protokoll gehörende Klassenname ausgelesen. Für den Fall des http-Protokolls erhalten Sie also de. galileocomputing.oobook.abstractfactory.HttpHandler als Name der Klasse, von der ein Exemplar erzeugt werden soll. In Zeile wird über die statische Methode forName über den Namen das Objekt gesucht, das die Klasse HttpHandler repräsentiert. Dieses Objekt enthält Informationen über die Struktur der Klasse, es kann aber auch verwendet werden, um Exemplare der Klasse zu erzeugen. Genau dies geschieht in Zeile : Ein Exemplar der Klasse HttpHandler (oder einer anderen konkreten Unterklasse von ProtocolHandler) wird erzeugt und der Variablen protocolHandler zugewiesen.
Damit liegt die Entscheidung, welche konkrete Klasse verwendet wird, nicht mehr im Quellcode, sondern in der verwendeten Konfigurationsdatei. Soll ein neues Protokoll unterstützt oder ein existierendes Protokoll durch eine andere Klasse bearbeitet werden, ist neben der Umsetzung der neuen Unterklasse von ProtocolHandler lediglich eine Änderung in der Konfigurationsdatei notwendig.
Im vorgestellten Beispiel haben wir eine statische Fabrik um Konfigurationsmöglichkeiten erweitert. Es wäre aber genauso möglich, die abstrakte Fabrik aus Abschnitt 7.2.2 mit diesen Möglichkeiten zu erweitern, so dass Sie mehrere Varianten einer konfigurierbaren Fabrik verwenden könnten.
Konfiguration in Sprachen ohne Reflexion
| Konfigurierbare Fabriken in Sprachen ohne Reflexion |
|
Das vorgestellte Beispiel in Java nutzt die Fähigkeit von Java, zur Laufzeit zu bestimmen, von welcher konkreten Klasse ein Exemplar erzeugt werden soll. Was ist aber in Sprachen wie C++, die diese Fähigkeiten nicht haben? Betrachten wir, welche Möglichkeiten Sie in C++ haben, so einen Mechanismus nachzubauen. In C++-Programmen ist es möglich, dass Bibliotheken nicht schon beim Start des Programms geladen werden, sondern erst später im Programmablauf aufgrund einer expliziten Ladeanweisung. Dadurch lässt sich ein ähnlicher Effekt erreichen wie durch die beschriebenen Konfigurationsmöglichkeiten in Java, allerdings mit wesentlich mehr Aufwand. Sie können dabei in einer Konfigurationsdatei festlegen, welche Bibliothek aus einer Reihe von Bibliotheken geladen werden soll. Liegen nun unterschiedliche Bibliotheken mit unterschiedlichen Realisierungen für die gleiche Schnittstellen-Klasse vor, so werden abhängig von der geladenen Bibliothek unterschiedliche Realisierungen dieser Schnittstelle im Programm verwendet. Wenn die geladenen Klassen jeweils ein Exemplar in eine Registratur eintragen, kann der Zugriff darauf über diese Registratur vermittelt und das für einen konkreten Fall (in unserem Beispiel ein bestimmtes Protokoll) registrierte Exemplar geliefert werden. Damit ändert sich das Verhalten des Programms abhängig davon, welche Bibliotheken dynamisch geladen werden. Da nun in einer Konfigurationsdatei entschieden wird, welche dieser Bibliotheken geladen werden, so haben Sie für diesen Fall das Verhalten einer konfigurierbaren Fabrik vorliegen. |
7.2.4 Registraturen für Objekte
In Abschnitt 7.2.2 hatten wir die Frage gestellt, wie denn die Entscheidung über die Klassenzugehörigkeit von erstellten Objekten weiter verlagert werden kann, so dass auch eine Fabrik selbst nicht mehr im Quellcode entscheiden muss, welche konkrete Klasse verwendet wird. Im vorigen Abschnitt haben Sie gesehen, dass diese Entscheidung in eine Konfigurationsdatei ausgelagert werden kann.
Was wir noch nicht betrachtet haben, ist die Möglichkeit, diese Entscheidung den Produkten der Fabrik selbst zu überlassen. Warum sollten Sie nicht einfach einmal eine ganze Reihe von Produkten auf Vorrat produzieren und diese dann bei Bedarf prüfen, ob sie für Ihre aktuelle Anforderung geeignet sind?
In Abbildung 7.12 greifen wir unser Beispiel mit unterschiedlichen Realisierungen der Schnittstelle ProtocolHandler wieder auf. Dort sehen Sie aber diesmal eine zusätzliche Klasse ProtocolHandlerRegistry, die als Registratur für Exemplare aller Unterklassen von ProtocolHandler dient.
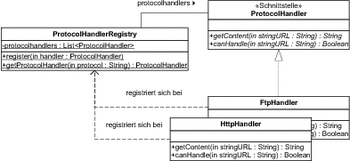
Abbildung 7.12 Registratur für »ProtocolHandler«
Die Schnittstelle ProtocolHandler verlangt nun, dass eine Klasse, welche die Schnittstelle implementiert, auch eine Methode canHandle implementiert, die Auskunft darüber gibt, ob ein Exemplar der Klasse ein angegebenes Protokoll bearbeiten kann.
Eine zentrale Rolle nimmt in diesem Szenario aber die Klasse ProtocolHandlerRegistry ein, deren Umsetzung in Listing 7.11 dargestellt ist.
public class ProtocolHandlerRegistry {
static List<ProtocolHandler> protocolHandlers =
new ArrayList<ProtocolHandler>();
static void register(ProtocolHandler handler) {
protocolHandlers.add(handler);
}
static ProtocolHandler getProtocolHandler(
String protocol) {
ListIterator<ProtocolHandler> iter =
protocolHandlers.listIterator();
while (iter.hasNext()) {
ProtocolHandler handler = iter.next();
if (handler.canHandle(protocol)) {
return handler;
}
}
// Fehlerbehandlung weggelassen
}
Listing 7.11 Umsetzung der Klasse »ProtocolHandlerRegistry« in Java
Betrachten wir deren Funktion im Folgenden etwas genauer. ProtocolHandlerRegistry definiert ausschließlich klassenbezogene Datenelemente und Methoden. Zunächst ist da eine Liste von Exemplaren von ProtocolHandler, die in Zeile definiert wird. In dieser werden mögliche Bearbeiter für Protokolle abgelegt. Zum Einfügen in diese Liste dient die Operation register in Zeile .
Wenn nun über die Operation getProtocolHandler in Zeile ein Protokollbearbeiter für eine bestimmte URL angefordert wird, wird die Liste der registrierten Bearbeiter durchlaufen und jedes Element davon mittels der Operation canHandle befragt (Zeile ). Das erste Element der Liste, das hier mit true antwortet, wird dann zurückgeliefert (Zeile ).
Für das Http-Protokoll wird hier ein Exemplar der Klasse HttpHandler zurückgegeben. Durch die Umsetzung der Operation canHandle erklärt sich diese Klasse für die Bearbeitung aller URLs zuständig, die mit http beginnen.
class HttpHandler {
// ...
public Boolean canHandle(String protocol) {
return protocol.equalsIgnoreCase("HTTP");
}
// ...
}
Damit die konkreten Unterklassen von ProtocolHandler weitgehend automatisch jeweils ein Exemplar bei der Klasse ProtocolHandlerRegistry registrieren, ist es notwendig, dass möglichst beim Laden der Klasse in die Laufzeitumgebung ein Exemplar der Klasse erstellt und bei der Klasse ProtocolHandler registriert wird. In Listing 7.12 ist dargestellt, wie das in Java möglich ist.
public class HttpHandler implements ProtocolHandler {
static {
ProtocolHandlerRegistry.register(new HttpHandler());
}
// ...
}
Listing 7.12 Registrierung beim Laden einer Klasse in Java
Der mit static gekennzeichnete Code wird beim Laden der Klasse in die Laufzeitumgebung ausgeführt. Damit wäre also nach dem Laden der Klasse HttpHandler ein Exemplar der Klasse für die Bearbeitung des Http-Protokolls registriert. Allerdings müssen Sie dabei die technischen Randbedingungen der verwendeten Programmiersprache, in unserem Beispiel von Java, beachten. Eine Klasse wird in Java erst dann geladen, wenn sie zum ersten Mal angesprochen wird. Deshalb muss bei der Initialisierung unserer Applikation mindestens ein Zugriff auf die Klasse erfolgen. Dies geschieht typischerweise durch einen Aufruf von Class.forName mit dem Namen der benötigten Klasse. In Listing 7.13 ist aufgeführt, wie zwei Bearbeiterklassen geladen werden und sich damit bei der Registratur eintragen.
Class.forName("de.galileocomputing.oobook.HttpHandler");
Class.forName("de.galileocomputing.oobook.FtpHandler");
ProtocolHandler handler =
ProtocolHandlerRegistry.getProtocolHandler("http");
String content = handler.getContent("http://www.mopo.de");
System.out.println(content);
Listing 7.13 Laden von Klassen und Verwendung eines Protokollbearbeiters
Wenn Sie nun ein weiteres Protokoll unterstützen wollen, so genügt es, wenn Sie eine Klasse umsetzen, welche die Schnittstelle ProtocolHandler implementiert. Diese wird sich dann mit einem Exemplar in der Registratur eintragen. Dies geschieht analog zum Bearbeiter für das Http-Protokoll. Sie können die Registrierung natürlich auch über eine Konfigurationsdatei steuern, die dann von einer Initialisierungsroutine ausgewertet wird, so dass die neue Klasse im existierenden Code überhaupt nicht mehr angesprochen werden muss.
Das vorgestellte Vorgehen kombiniert zwei eigenständige Bestandteile. Zum einen wird eine Registratur ProtocolHandlerRegistry verwendet, die für die konkrete Auswahl eines Protokollbearbeiters zuständig ist. Intern verwendet die Registratur dann eine Variante des Musters der Zuständigkeitskette, um eine Anfrage an verschiedene Objekte weiterzuleiten, von denen dann eines sich selbst für die angefragte Aufgabe zuständig erklärt.
|
Eine Reihe von Objekten erhält die Möglichkeit, eine Aufgabe zu erledigen. Dabei werden die Objekte der Reihe nach befragt, ob sie die Aufgabe erledigen können. Beantwortet ein Objekt diese Frage positiv, so wird diesem die Aufgabe zur Erledigung zugewiesen. Im anderen Fall wird die Anfrage an das nächste Objekt in der Kette weitergereicht. |
Vorsicht: doppelte Produkte
Bei der Verwendung einer Variante der Zuständigkeitskette machen wir die Annahme, dass die Registrierung von verschiedenen Produkten durch den nutzenden Client in einer konsistenten Art und Weise erfolgt und dass Doppelregistrierungen entweder verhindert werden oder keine negativen Konsequenzen haben. In den meisten praktischen Fällen wird es aber sinnvoll sein, Doppelregistrierungen in so einem Fall zu vermeiden und bei der zweiten Registrierung für die gleiche Aufgabe einen Fehler zu melden.
Alternativ kann auch die Registratur erweitert werden, so dass für die Auswahl eines konkreten Bearbeiters nicht ausschließlich diese selbst verantwortlich sind, sondern bei mehreren möglichen Bearbeitern ein weiteres Auswahlkriterium greift.
7.2.5 Fabrikmethoden
Fabrikmethoden haben in der Regel einen anderen Anwendungskontext, als das bei abstrakten Fabriken der Fall ist. Allerdings werden abstrakte Fabriken und Fabrikmethoden häufig unter dem Begriff Fabrik zusammengefasst. Dabei haben beide durchaus unterschiedliche Ausgangsbedingungen.
|
Fabrikmethoden sind Methoden, die innerhalb einer Klassenhierarchie dafür zuständig sind, klassenspezifische Objekte (Produkte) zu erstellen, die dann von der betreffenden Klasse genutzt werden. Die Produkte werden dabei ebenfalls in einer Hierarchie organisiert. |
Abbildung 7.13 zeigt den grundsätzlichen Aufbau der beteiligten Klassen bei der Verwendung einer Fabrikmethode.
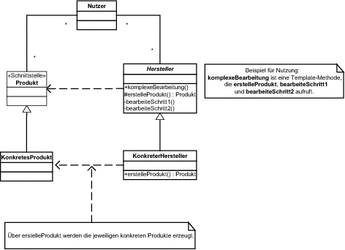
Abbildung 7.13 Fabrikmethode zur Erstellung konkreter Klassen
Kovariante Rückgabetypen
In der Abbildung ist die Fabrikmethode erstelleProdukt zu sehen. In den konkreten Unterklassen der abstrakten Klasse Hersteller werden diese so implementiert, dass sie das jeweils benötigte konkrete Produkt zurückgibt.
Wenn es die Programmiersprache erlaubt, können Sie dabei auch die Möglichkeit von kovarianten Rückgabetypen ausnutzen. Wir haben kovariante Rückgabetypen bereits in Abschnitt 5.4.4, »Die Problemstellungen der Mehrfachvererbung«, vorgestellt. Wenn Sie diesen Mechanismus ausnutzen, kann die Methode erstelleProdukt in der Klasse KonkreterHersteller so überschrieben werden, dass sie nicht mehr das abstrakte Produkt Rückgabe spezifiziert, sondern die Klasse KonkretesProdukt.
Fabrikmethoden am Beispiel
Die Arbeitsweise von Fabrikmethoden lässt sich gut an einem Beispiel illustrieren. Betrachten wir dazu die Verwaltung von JDBC-Treibern in den Java-Bibliotheken. Diese verwenden nämlich Fabrikmethoden, um die Beziehungen zwischen Verbindungen und Statements konsistent zu gestalten. [JDBC war früher tatsächlich die Abkürzung für Java Database Connectivity. Heutzutage ist JDBC keine Abkürzung mehr, sondern einfach ein Name einer Spezifikation und einer Bibliothek, die es Java ermöglicht, mit den Datenbanken zu kommunizieren. Wenn Sie sich jetzt fragen, was das soll, sind Sie bestimmt kein Marketingmensch. ]
Kurzüberblick: JDBC
| JDBC (Java Database Connectivity) |
|
JDBC7 ist ein standardisierter Mechanismus, um von Java-Programmen aus auf (vorwiegend relationale) Datenbanken zuzugreifen. JDBC-Treiber sind Module, die diesen Mechanismus für konkrete Typen von Datenquellen umsetzen. So gibt es zum Beispiel JDBC-Treiber, die diesen Mechanismus speziell für Oracle-Datenbanken umsetzen, andere, die über ODBC-Mechanismen (Open Database Connectivity) auf eine Datenbank zugreifen. |
JDBC basiert darauf, dass für die Umsetzung von Treibern für spezielle Datenquellen vor allem zwei Schnittstellen realisiert werden: Connection und Statement.
In Abbildung 7.14 sind die Beziehungen zwischen den beiden Schnittstellen und den sie realisierenden Klassen am Beispiel von JDBC-Treibern für eine Oracle-Datenbank und für ODBC aufgeführt.
In der Abbildung wird bereits deutlich, dass eine Klassenstruktur vorliegt, die Abbildung 7.13 ähnlich ist: Die Schnittstelle Connection entspricht der Schnittstelle Hersteller, Statement entspricht der Schnittstelle Produkt. Die Fabrikmethode heißt in diesem Fall createStatement.
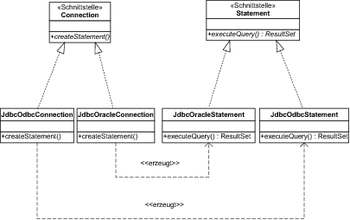
Abbildung 7.14 Fabrikmethode bei JDBC-Verbindungen
Die konkreten Realisierungen, wie zum Beispiel JdbcOracleConnection, setzen die Fabrikmethode so um, dass die jeweils korrespondierenden konkreten Statement-Klassen darüber erstellt werden.
In Listing 7.14 ist die Verwendung der Fabrikmethode in Zeile zu sehen.
Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );
Connection connection = DriverManager.getConnection(
"jdbc:odbc:mydb", "User", "Password" );
Statement statement = connection.createStatement();
ResultSet result =
statement.executeQuery("SELECT * FROM mytable;");
Listing 7.14 Verwendung eines JDBC-Treibers
Der Aufruf von DriverManager.getConnection in Zeile hat dabei ein Exemplar von JdbcOdbcDriver geliefert, die entsprechende Klasse ist in Zeile geladen worden. [Das Laden und Registrieren des JDBC-Treibers erfolgt nach dem Muster, das wir im vorigen Abschnitt, Registraturen für Objekte, vorgestellt haben. Dabei wird ein Exemplar der Klasse beim DriverManager registriert, sobald die Klasse geladen wird. ] Der Aufruf von createStatement wird nun in diesem Fall auch ein Exemplar von JdbcOdbcStatement liefern. Bei der Verwendung von Connection und Statement wissen Sie allerdings nichts über diese konkreten Klassen, sondern arbeiten alleine mit den Schnittstellen.
Wenn Sie einen neuen JDBC-Treiber für ein eigenes Datenformat zur Verfügung stellen wollen, müssen Sie Implementierungen sowohl für die Connection als auch für ein neues Statement bereitstellen. [Falls Sie tatsächlich einen eigenen JDBC-Treiber schreiben wollen, finden Sie im Online-Magazin JavaPro eine Schritt-für-Schritt-Anleitung dazu: http://www.ftponline.com/javapro/2001_12/magazine/features/jodonahue/default.aspx ] Die Erweiterungsmöglichkeit wird in diesem Fall über die Fabrikmethode createStatement sichergestellt. Die konkreten Klassen der Statements können direkt den konkreten Klassen der Connections zugeordnet werden.
Zwei Hierarchien
Auffallend ist die Struktur des Klassendiagramms: Sie haben zwei Hierarchien vorliegen, die miteinander in Beziehung stehen. Dabei verwenden die Exemplare der einen Hierarchie die Exemplare der anderen Hierarchie. In unserem JDBC-Szenario haben wir allerdings den Spezialfall, dass das von der Fabrikmethode erstellte Objekt in der Regel nicht intern von den Realisierungen von Connection genutzt wird. In anderen Szenarien, in denen Fabrikmethoden eingesetzt werden, ist die Methode möglicherweise gar nicht Teil der nach außen sichtbaren Schnittstelle, sondern wird nur intern genutzt.
Unterschied zu abstrakter Fabrik
Aber was ist denn nun eigentlich der Unterschied zwischen Fabrikmethode und abstrakter Fabrik? Relevant für die Fabrikmethode sind folgende Eigenschaften:
- Die Fabrikmethode existiert nicht an einer eigens dafür erstellten Klasse, sondern sie ist eine zusätzliche Methode in einer bereits existierenden Klassenhierarchie.
- Die erzeugenden Klassen haben in der Regel eine konkrete technische oder fachliche Aufgabenstellung. Im Rahmen dieser Aufgabenstellung benötigen sie Exemplare von Klassen, die in einer dazu korrespondierenden parallelen Hierarchie aufgebaut sind.
- Die konkreten abgeleiteten Klassen der Erzeuger nutzen nun die Fabrikmethode, um Exemplare der jeweils benötigten konkreten Produktklassen zu erstellen.
Auch abstrakte Fabriken nutzen in der Regel Fabrikmethoden, um ihre Produkte zu erzeugen. Der entscheidende Unterschied ist aber: Die Klassenhierarchie, die für die abstrakte Fabrik aufgebaut wird, hat ausschließlich den Zweck, diese Produkte zu erzeugen.
Anwendung der Fabrikmethode
Voraussetzung für eine sinnvolle Anwendung der Fabrikmethode außerhalb von abstrakten Fabriken ist dagegen immer, dass Sie bereits zwei Klassenhierarchien vorliegen haben, die in einer Nutzungsbeziehung stehen. Im Gegensatz zum Vorgehen bei der abstrakten Fabrik wird also keine neue Hierarchie von Klassen eingeführt, sondern lediglich eine existierende Hierarchie um eine Operation erweitert.
Wenn Sie Klassen nur einführen, damit sie eine Fabrikmethode umsetzen, dann haben Sie eher eine einfache Variante der abstrakten Fabrik vorliegen.
Anwendungsfälle für Fabrikmethoden finden sich häufig in den technischen Bereichen von Bibliotheken und Frameworks. Parallele Hierarchien, die direkt aufeinander abbilden, deuten auf mögliche Einsatzszenarien von Fabrikmethoden.
Allerdings kann es auch vorkommen, dass Sie technisch die Erstellung von Objekten über Fabrikmethoden durchführen könnten, sich dies aber aus Gründen der Modularisierung verbietet.
Objekte sorgen für ihre Darstellung.
So kann es zum Beispiel für bestimmte Objekte sinnvoll sein, eine Standarddarstellung in einer Benutzeroberfläche zu definieren. Diese Darstellung wird sich in der Regel aus der Klassenzuordnung eines Objekts direkt ergeben. Zum Beispiel könnten wir festlegen, dass ein Exemplar einer Klasse TextDocument immer über ein Exemplar von TextView dargestellt wird, solange nichts anderes angegeben wird. Das Einfachste wäre es nun, wenn Sie eine Fabrikmethode verwenden könnten, welche die entsprechende Darstellung in einer graphischen Benutzeroberfläche erzeugt. In Abbildung 7.15 sind die resultierenden Beziehungen dargestellt.
In der Abbildung wird auch bereits das Problem deutlich. Nach dem Prinzip einer einzigen Verantwortung soll sich ein Modul möglichst nur mit einer klar definierten Aufgabe beschäftigen. Im vorliegenden Beispiel schaffen Sie nun aber eine Abhängigkeit vom Bereich (Domäne) der Fachobjekte zum Bereich der Darstellung. Damit wird die Aufgabe der Darstellung teilweise mit in den Bereich der Fachobjekte verlagert. Die Klasse TextDocument muss nun die Klasse TextView kennen und ist damit eng an den Darstellungsbereich gekoppelt. In einer Java-Anwendung würden zum Beispiel auf einmal Swing-Klassen im Bereich unserer Geschäftslogik auftauchen. Im aufgeführten Beispiel entstehen außerdem zyklische Abhängigkeiten, da wiederum die Klassen aus dem Bereich Darstellung die Klassen aus dem Bereich der Fachobjekte benötigen.
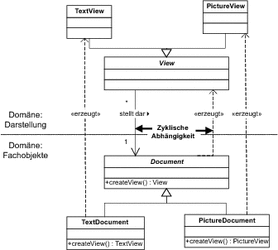
Abbildung 7.15 Eine Fabrikmethode, die zyklische Abhängigkeiten verursacht
Separate Fabrik
Um diese Abhängigkeiten zu vermeiden, sollten Sie also in solch einem Fall die Erstellung der zugehörigen Darstellungsobjekte in eine separate Klasse auslagern, die dann wiederum mit den Mechanismen der statischen oder der abstrakten Fabrik arbeitet. Abbildung 7.16 illustriert diese modifizierte Variante, bei der die unerwünschten Abhängigkeiten nicht vorliegen.
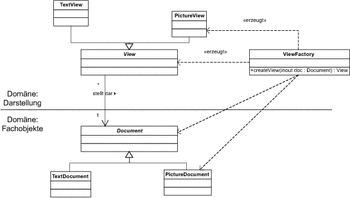
Abbildung 7.16 Fabrikmethode durch eine Fabrik ersetzt
Bereiche entkoppeln
Durch den Einsatz einer Klasse ViewFactory, die dem Bereich der Darstellung zugeordnet ist, wird die Abhängigkeit der Fachobjekte von ihrer Darstellung aufgehoben. Die Klasse ViewFactory ist nun dafür zuständig, zu einem Dokument ein Objekt zu erstellen, welches das Dokument darstellen kann. Damit bestehen die Abhängigkeiten wieder ausschließlich in der zulässigen Richtung.
Es gibt allerdings noch eine andere Möglichkeit, die unerwünschte Kopplung aufzuheben: Sie können die Methoden der Klassen aus dem Bereich der Fachobjekte unterteilen in solche, die sich mit der Fachlichkeit beschäftigen, und solche, die sich mit der Darstellung beschäftigen. Dann können Sie die eine Gruppe in einem Quellcode-Modul realisieren, die andere Gruppe von Methoden in einem separaten Modul. So können Sie den fachlichen Teil der Klasse Document und ihrer Unterklassen im Quelltextmodul »Fachobjekte« definieren und den darstellungsspezifischen Teil (die typspezifischen Fabrikmethoden für die Ansichtsobjekte) im Quelltextmodul »Darstellung«. Damit bestehen zwar die zyklischen Abhängigkeiten zwischen den Klassen weiter, sie bestehen aber nicht zwischen den Quellcode-Modulen.
Verfahren in Ruby
Dieses Verfahren setzt allerdings voraus, dass es von der verwendeten Programmiersprache unterstützt wird. Beispiele für Programmiersprachen, die eine solche Möglichkeit bieten, sind Ruby und C#. In Abbildung 7.17 ist dargestellt, wie die Klasse TextDocument auf zwei unterschiedliche Ruby-Module aufgeteilt werden kann.
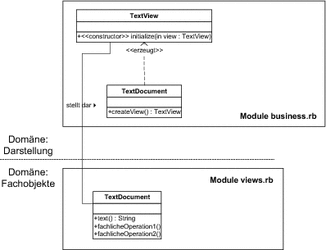
Abbildung 7.17 Umsetzung einer Klasse in zwei Modulen
Die Klasse TextDocument ist hier in zwei Bestandteile zerlegt, die jeweils in eigenen Modulen liegen und sich mit unterschiedlichen Bereichen der Funktionalität beschäftigen. Listing 7.15 zeigt die Umsetzung des Beispiels im Ruby-Quellcode. [Der Mechanismus der Klassenergänzung (Introductions) erlaubt generell eine Erweiterung von Klassen über verschiedene Quellcode-Module. Introductions stellen wir in Abschnitt 9.3.5 im Detail vor. ]
Keine zyklischen Abhängigkeiten
Datei: business.rb – die fachliche Funktionalität
class TextDocument
# verschiedene fachliche Methoden
def fachlicheOperation1()
return "fachliche Operation wird ausgeführt..."
end
def fachlicheOperation2()
return "fachliche Operation wird ausgeführt..."
end
# und so weiter
end
Datei: views.rb – hier geht es um die Darstellbarkeit
class TextDocument
def createView()
return TextView.new(self)
end
end
class TextView
def initialize(textDocument)
# Implementierung des Konstruktors der Ansichtsklasse
end
end
Verwendung:
require "business.rb"
require "views.rb"
...
# document referenziert ein Exemplar der Klasse TextDocument
# Aufruf einer fachlichen Methode
print document.text
# Nutzung der Fabrikmethode aus views.rb
view = document.createView
Listing 7.15 Eine Klasse in mehreren Modulen (Ruby)
Partielle Klassen
Im Quelltext des Moduls business.rb werden die fachlichen Operationen umgesetzt (Zeilen ). Im Modul views.rb findet sich die Fabrikmethode an Zeile , die ein Exemplar von TextView konstruiert und dabei das Dokument selbst übergibt (). Die Klasse TextView selbst wird im gleichen Quelltextmodul umgesetzt (). Wird nun in einer Anwendung eine Darstellung der Dokumente benötigt, kann das Modul views.rb eingebunden werden wie in Zeile . Damit kann ein Aufruf der Fabrikmethode in Zeile erfolgen.
Der fachliche Teil der Dokumentenklassen ist dabei nicht vom darstellenden Teil abhängig. Diese Vorgehensweise verursacht also keine zyklischen Abhängigkeiten zwischen den Quelltextmodulen business.rb (Fachlogik) und views.rb (Darstellung). In einer Anwendung, in der die Fachobjekte nicht dargestellt werden müssen, wird das Quelltextmodul views.rb nicht eingebunden. In diesem Fall haben die Dokumentenklassen keine Fabrikmethode für ihre Ansichtsobjekte zugeordnet. Nur wenn die Darstellung zum Funktionsumfang Ihrer Anwendung gehört, fügen Sie das Quelltextmodul views.rb hinzu und ergänzen die Dokumentenklassen damit um die Fähigkeit, ein Ansichtsobjekt zu konstruieren.
Verfahren in C#
Eine ähnliche Vorgehensweise wie in Ruby ist bei C# und verwandten Programmiersprachen aus der .NET-Familie ab der Version 2 möglich. Die sogenannten partiellen Klassen bieten die Möglichkeit, den Quelltext einer Klasse in verschiedene Quelltextmodule zu verteilen. Die komplette Klasse wird zur Übersetzungszeit aus den verschiedenen partiellen Klassen zusammengesetzt. Schließen Sie bestimmte Klassenpartitionen von der Übersetzung aus, wird Ihre Anwendung die in diesen Partitionen enthaltene Funktionalität nicht enthalten. Selbstverständlich ist die Anwendung nur dann übersetzbar, wenn die restlichen Quelltexte eine vollständige Klasse bilden.
Der Unterschied zwischen C# und Ruby besteht darin, dass C# die Ergänzung der Klassen, beziehungsweise das Zusammenführen der partiellen Klassen, nur zur Übersetzungszeit zulässt, Ruby dagegen auch zur Laufzeit die Struktur der Klasse anpassen kann.
Java bietet keine Möglichkeit der Ergänzung der Klassen, doch verschiedene aspektorientierte Erweiterungen wie zum Beispiel AspectJ oder JBoss-AOP bieten diese Funktionalität auch in der Welt von Java an. Wir werden in Abschnitt 9.3.5, »Introductions«, genauer auf diese Möglichkeiten eingehen.
7.2.6 Erzeugung von Objekten als Singletons
Exemplare von Singleton-Klassen sind die einsamsten Objekte, die sich in Programmen finden.
Diskussion: Bitte kein Roman
Gregor: Ich glaube, du hast dich da gerade im Genre dieses Buchs vertan. Man könnte ja denken, da schreibt Rosamunde Pilcher.Bernhard: O.k., o.k. Werde ich halt diese Formulierungen für den großen Roman aufheben, den ich immer schon einmal schreiben wollte. Ich komme ja gleich wieder zu einer sachlichen Darstellung zurück.
Singletons als Entwurfsmuster?
Also noch einmal. Singleton-Klassen sind Klassen, die aufgrund ihrer Methoden sicherstellen, dass in jeder Anwendung höchstens ein Exemplar dieser Klasse existieren kann.
Die besondere Eigenschaft von Singletons ist es, dass von ihnen genau ein Exemplar existiert. Dies ist in manchen Kontexten eine geforderte Eigenschaft. Wenn Sie innerhalb einer Applikation Fehlermeldungen auf ein einheitliches Ausgabemedium, zum Beispiel eine Datei, ausgeben wollen, macht es Sinn, dass der Zugriff applikationsweit über ein einziges Objekt koordiniert wird. Wenn mehrere Objekte den Zugriff auf das Ausgabemedium durchführen würden, würde das Schreiben der Fehlermeldungen möglicherweise nicht synchronisiert, und die Meldungen würden sich möglicherweise wechselseitig überschreiben.
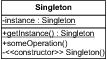
Abbildung 7.18 Singleton mit zugehörigen Operationen
So weit, so einfach. Es stellen sich aber bei genauerem Hinsehen zwei Fragen, eine sehr technische und eine konzeptionelle.
- Eine technische Frage: Wie können wir den Zugriff auch bei nebenläufigen Programmen sicher und effizient gestalten?
- Eine konzeptionelle Frage: In welchen Fällen sollen wir ein Singleton einsetzen?
Technisch korrekte Umsetzung von Singletons
Technische Fragen sind in der Regel leichter zu beantworten als konzeptionelle, deshalb fangen wir einmal mit der technischen Frage als Lockerungsübung an. Betrachten wir deshalb in Listing 7.16 eine Umsetzung eines Singletons in Java, die unsere technischen Anforderungen erfüllt: Sie arbeitet effizient und auch in nebenläufigen Programmen korrekt.
public class OneAndOnlyOne {
// Privater Konstruktor
private OneAndOnlyOne () {}
// Geschachtelte Klasse Inner
private static class Inner {
private static OneAndOnlyOne INSTANCE =
new OneAndOnlyOne ();
}
// Zugriff auf das einzige Exemplar
public static OneAndOnlyOne getInstance() {
return Inner.INSTANCE;
}
// Fachliche Methoden des Singletons
// ...
}
Listing 7.16 Korrekte Umsetzung eines Singletons in Java
Die vorgestellte Umsetzung arbeitet korrekt und effizient:
- Es gibt keine Möglichkeit, dass mehr als ein Exemplar von OneAndOnlyOne erzeugt wird.
- Der Zugriff auf dieses einzige Exemplar wird immer ein komplett konstruiertes Exemplar liefern und nicht einen möglicherweise inkonsistenten Zwischenzustand.
- Das Exemplar wird erst dann erstellt, wenn es tatsächlich benötigt wird. Die Lösung geht also effizient mit Ressourcen um.
Problematische Implementierungen
In der Praxis finden sich allerdings häufig auch andere Implementierungen von Singletons, die auf den ersten Blick einfacher und effizienter zu sein scheinen. Wir stellen im Folgenden einige davon vor und werden auf der Grundlage der bestehenden Probleme die Lösung von Listing 7.16 herleiten und vorstellen, warum diese korrekt arbeitet. Diese Lösung sollten Sie im praktischen Einsatz vorziehen, weil die im Folgenden vorgestellten Alternativen nicht in allen Fällen korrekt und effizient arbeiten.
Alternative Umsetzungen von Singletons: mögliche Probleme
Beginnen wir als mit der ersten problematischen Variante, aufgeführt in Listing 7.17.
public class OneAndOnlyOne {
private static OneAndOnlyOne instance = null;
// Privater Konstruktor verhindert Aufruf von außen
private OneAndOnlyOne() {}
//! Zugriff auf das einzige Exemplar
public static OneAndOnlyOne getInstance()
{
if (instance == null)
{
instance = new OneAndOnlyOne();
}
return instance;
}
}
Listing 7.17 Singleton in Java: Probleme durch fehlende Synchronisation
Die Klasse hat ein klassenbezogenes Datenelement instance (Zeile ). In Zeile ist der Konstruktor der Klasse als private deklariert. Dadurch wird sichergestellt, dass keine Exemplare der Klasse konstruiert werden können außer durch den Aufruf des Konstruktors in der klassenbezogenen Methode getInstance() in Zeile . Dabei wird in Zeile zunächst überprüft, ob das Exemplar schon angelegt wurde. Nur wenn dies nicht der Fall ist, wird der private Konstruktor aufgerufen und das neue Exemplar angelegt. Dadurch, dass ein Exemplar erst beim Zugriff über getInstance angelegt wird, geht diese Umsetzung effizient mit Ressourcen um: Erfolgt kein solcher Zugriff, wird auch kein Exemplar konstruiert. Dieses Verfahren wird später Initialisierung (Lazy Initialization) genannt.
Problem bei nebenläufiger Ausführung
Die in Listing 7.17 aufgeführte Lösung hat aber einen offensichtlichen Mangel: Sie wird nicht in Programmen funktionieren, in denen nebenläufige Ausführungspfade erlaubt sind. In Java wird diese Nebenläufigkeit über sogenannte Threads umgesetzt. Dass Java-Programme Nebenläufigkeit aufweisen, ist eher die Regel als die Ausnahme.
Wenn wir das erwähnte Listung genau so umsetzen, kann es passieren, dass zwei dieser Threads gleichzeitig die Operation getInstance aufrufen. Wenn zu diesem Zeitpunkt das Exemplar von OneAndOnlyOne noch nicht angelegt ist, wird die Prüfung aus Zeile für beide das Ergebnis liefern: »noch kein Exemplar angelegt«. Und schon sind beide Aufrufe munter dabei, jeweils ein neues Exemplar zu konstruieren, und vorbei ist es mit der Einzigartigkeit von OneAndOnlyOne. Die Umsetzung aus Listing 7.17 arbeitet also in Programmen, in denen Threads eingesetzt werden, nicht korrekt.
Synchronisation der Zugriffsmethode
Gut, das sollte sich leicht beheben lassen, denn Java bietet Sprachmittel, mit denen sich eine Synchronisation von Methodenaufrufen erreichen lässt. In Listing 7.18 ist eine angepasste Methode getInstance gezeigt.
public static synchronized OneAndOnlyOne getInstance()
{
if (instance == null)
{
instance = new OneAndOnlyOne();
}
return instance;
}
Listing 7.18 Synchronisierte Methode »getInstance«
Über das Schlüsselwort synchronized wird der in Java vorhandene Mechanismus zur Synchronisation einer Methode verwendet. Dadurch wird sichergestellt, dass immer nur ein Thread gleichzeitig diese Methode ausführen kann. Damit ist auch sichergestellt, dass es nur genau ein Exemplar von OneAndOnlyOne geben wird, weil ein Folgeaufruf bereits ein Exemplar vorfinden und deshalb kein neues konstruieren wird.
Synchronisation ist teuer.
Aber die Sache hat einen anderen Haken: Die Synchronisation von Methoden ist teuer. Wenn mehrere Threads parallel die Methode nutzen, entstehen unnötige Wartezeiten. Es ist nicht ungewöhnlich, dass die Ausführungszeit einer Methode durch das Schlüsselwort synchronized einfach einmal um das 50- bis 100fache ansteigt. Und irgendwie erscheint das unverhältnismäßig: Sie erwarten, dass das Exemplar genau einmal konstruiert wird; dann ist es aber möglich, dass darauf tausendfach oder vielleicht sogar millionenfach Zugriffe über getInstance erfolgen. Die von Singletons gekapselten Ressourcen sind in einer Anwendung oft recht populär. Und nur wegen des einen Aufrufs, der das Exemplar einmal konstruiert, sollen wir danach immer noch alle Threads in eine Warteschlange packen?
Sperre mit zweifacher Prüfung
Diese Fragen legen eine neue Variante der Lösung nahe, die das Problem zu lösen scheint. Diese Variante wird in der Regel als Sperre mit zweifacher Prüfung (englisch double-checked Locking) bezeichnet. Die Umsetzung ist in Listing 7.19 dargestellt.
public class OneAndOnlyOne {
private static OneAndOnlyOne instance = null;
private static Object justForSync = new Object();
private OneAndOnlyOne() {}
//! Zugriff auf das einzige Exemplar
public static OneAndOnlyOne getInstance() {
if (instance == null) {
synchronized(justForSync) {
if (instance == null) {
instance = new OneAndOnlyOne();
}
}
}
return instance;
}
}
Listing 7.19 Sperre mit doppelter Prüfung: nicht korrekt vor Java 5
Problem scheinbar gelöst
Es scheint, dass dieser Code Ihr Problem löst. Sie prüfen erst einmal in Zeile ohne die teure Synchronisation, ob das Exemplar bereits erstellt wurde. Wenn ja (und das wird fast immer der Fall sein), geben Sie es einfach zurück, keine Wartezeiten, kein Problem. Wenn nein, wird in Zeile doch ein synchronisierter Abschnitt betreten. Dort wird in Zeile noch einmal geprüft, ob das Exemplar immer noch nicht erstellt ist, denn das könnte ja seit der Prüfung eine Zeile vorher passiert sein. Erst nach dieser Prüfung wird das Exemplar dann konstruiert.
Bis Java 1.4 funktioniert die Sperre mit doppelter Prüfung nicht korrekt.
Allerdings führt ein sehr technisches Problem dazu, dass diese Umsetzung in Java vor der Version 5 nicht in allen Fällen korrekt arbeitet. Das Problem liegt darin, dass die Konstruktion des Exemplars von OneAndOnlyOne in diesem Szenario in den Java-Versionen vor der Version 5 keine atomare Operation ist, deren Auswirkungen auf einen Schlag sichtbar werden. So ist es möglich, dass ein Thread beim Zugriff über getInstance ein Exemplar vorfindet, das zwar bereits grundsätzlich angelegt, aber noch nicht komplett initialisiert ist. Das Speichermodell von Java bis zur Version 1.4 erlaubt jedenfalls solche Situationen. [Falls Sie sich für die technischen Hintergründe interessieren, finden Sie diese in einem Artikel der Javaworld unter http://www.javaworld.com/javaworld/ jw–02-2001/jw-0209-double.html. ] In so einer Situation könnte getInstance also inkonsistente Daten liefern. Ab Java 5 arbeitet die Sperre mit doppelter Prüfung korrekt, sofern unsere Variable mit dem Schlüsselwort volatile markiert wird. [Das Schlüsselwort volatile ist auch in den früheren Java-Versionen verfügbar und soll eine Variable so markieren, dass ihre Initialisierung vor dem nächsten folgenden Zugriff abgeschlossen sein soll. Nur funktioniert das eben vor Java 5 nicht so, wie das für die Sperre mit doppelter Prüfung notwendig wäre. ] Allerdings haben Sie auch hier einen Performance-Nachteil, da der Zugriff auf Variablen, die mit diesem Schlüsselwort markiert sind, gesondert abgesichert wird.
Späte Initialisierung
Die bisher diskutierten problematischen Varianten haben alle das Prinzip der späten Initialisierung (engl. Lazy Initialization) verfolgt. Das Exemplar der Klasse wurde dabei erst dann explizit angelegt, wenn auch tatsächlich darauf zugegriffen wurde.
Statische Initialisierung
Als bessere Alternative steht aber die Variante der statischen Initialisierung zur Verfügung. Diese bringt uns so langsam wieder in die Nähe unserer präferierten Lösung aus Listing 7.16.
public class OneAndOnlyOne {
private static OneAndOnlyOne instance =
new OneAndOnlyOne();
// ...
//! Zugriff auf das einzige Exemplar
public static OneAndOnlyOne getInstance()
{
return instance();
}
}
Listing 7.20 Statische Initialisierung eines Singletons
In Listing 7.20 wird unser Exemplar direkt konstruiert, wenn die Klasse OneAndOnlyOne initialisiert wird. Damit sorgt also die Laufzeitumgebung der Programmiersprache (in diesem Fall die virtuelle Maschine von Java) dafür, dass vor einem Zugriff das Exemplar von OneAndOnlyOne auf jeden Fall bereits erzeugt ist, bevor darauf zugegriffen wird. Im Fall von Java haben Sie sogar den Vorteil, dass die Klasse erst geladen wird, wenn der erste Zugriff erfolgt. Damit liegt praktisch ein Verhalten vor, das mit der späten Initialisierung vergleichbar ist.
Allerdings: Falls außer der statischen Variablen für das Exemplar des Singletons noch weitere Klassenvariablen existieren, wird dieses Exemplar auch initialisiert, sobald auf eine der anderen Variablen zugegriffen wird. Durch eine kleine Modifikation unserer Lösung lässt sich das aber lösen. Wenn Sie das Exemplar des Singletons in eine geschachtelte Klasse auslagern, wird diese erst geladen, wenn sie wirklich benötigt wird. Wir greifen deshalb in Listing 7.21 die Umsetzung aus Listing 7.16 wieder auf und stellen deren Bestandteile vor.
public class OneAndOnlyOne {
public static String TEST = "Test";
private static class Inner {
private static OneAndOnlyOne INSTANCE =
new OneAndOnlyOne();
}
public static OneAndOnlyOne getInstance() {
return Inner.INSTANCE;
}
private OneAndOnlyOne() { };
public void test() {
System.out.println("Testing");
}
public static void main(String[] args) {
System.out.println(TEST);
getInstance().test();
}
}
Listing 7.21 Korrekte Umsetzung eines Singletons (ausführlich)
In Zeile ist das klassenbezogene Datenelement TEST definiert. Damit beim Zugriff auf dieses Element unser Exemplar des Singletons noch nicht konstruiert wird, ist in Zeile eine geschachtelte Klasse Inner definiert. Bei der Initialisierung dieser Klasse wird in Zeile das Exemplar unseres Singletons konstruiert. Die Zugriffsmethode getInstance in Zeile liefert dann auch das über die geschachtelte Klasse referenzierte Exemplar. Der Konstruktor in Zeile ist weiterhin privat. Wird nun, wie in Zeile , auf das klassenbezogene Datenelement TEST zugegriffen, so wird zwar die Klasse OneAndOnlyOne geladen, nicht aber die geschachtelte Klasse Inner. Noch ist also unser Exemplar nicht konstruiert. Erst beim Zugriff über getInstance() in Zeile kommt es auch zum Zugriff auf die Klasse Inner, die damit geladen wird und das Exemplar des Singletons erstellt.
Eine Restriktion dieser Lösung sollten wir allerdings nicht verschweigen: Der Konstruktor sollte bei dieser Lösung keine Exceptions werfen. Fehler, die beim Laden einer Klasse auftreten, sind nicht in einer definierten Weise behandelbar.
Welches Singleton soll es sein?
Wenn auf eine Behandlung von Fehlern bei der Konstruktion eines Singletons verzichtet werden kann, ist eine Umsetzung von Singletons unter Verwendung von statischer Initialisierung die beste Variante. In Sprachen wie Java, die eine dynamische Initialisierung von Klassen beim ersten Zugriff vornehmen, kann dabei des Exemplar des Singletons zusätzlich in eine geschachtelte Klasse ausgelagert werden, um die Initialisierung möglichst spät durchzuführen.
Nur falls eine Behandlung von Fehlern bei der Konstruktion notwendig ist, sollte ein anderes Verfahren zum Einsatz kommen. Die Sperre mit doppelter Prüfung ist eine Alternative. Sie muss aber vom Speichermodell der verwendeten Programmiersprache korrekt unterstützt werden. Dies ist für die Java-Version bis einschließlich 1.4 nicht der Fall.
Falls auch die Sperre mit doppelter Prüfung nicht anwendbar ist, sollte eine komplette Synchronisation der Zugriffsmethode erfolgen.
Wann sollen Singletons eingesetzt werden?
Das technische Problem lässt sich also klar beschreiben. Was war aber noch mal mit dem konzeptionellen Problem? In welchen Fällen sollten Singletons denn überhaupt zum Einsatz kommen?
Das Problem liegt darin, dass die Verwendung von Singletons in vielen Fällen verlockend erscheint, in denen ihre Anwendung nicht adäquat ist. Die Verwendung von Singletons führt zu einer engen Kopplung zwischen der Singleton-Klasse und den nutzenden Klassen. Die nutzenden Klassen müssen genaue Kenntnis davon haben, welche Klasse die Funktionalität des Singletons implementiert. Eine Variante davon nur für einen Teilbereich einer Applikation zu erzeugen, ist in der Regel nicht möglich.
Einzigartigkeit notwendig?
Außerdem müssen Sie sich die Frage stellen, ob Sie die zentrale Eigenschaft des Singletons wirklich benötigen. Diese zentrale Eigenschaft ist die Restriktion, dass es höchstens ein Objekt davon geben kann. Aber häufig wird das gar nicht Ihre Anforderung sein. Die Anforderung ist eher: Ich will konsistent und effizient auf eine bestimmte Ressource zugreifen. Als Nutzer eines Moduls zur Protokollierung ist es Ihnen meist ziemlich egal, ob es davon ein Exemplar gibt oder mehrere.
Diskussion: Sind Singletons nur globale Variablen?
Bernhard: Im schlechtesten Fall sind Singletons doch nur ein Ersatz für eine globale Variable. Ich habe ein Objekt, das von jeder Stelle im Programm zugreifbar und möglicherweise auch änderbar ist.Gregor: Ja, es ist richtig, dass man Singletons dazu verwenden kann. Aber fast alle Möglichkeiten der Objektorientierung kann ich missbrauchen. Wir müssen eben immer gut überlegen, ob eine Klasse wirklich alle Kriterien für ein Singleton erfüllt. Das Kriterium »ich brauch einmal was, was einfach von jeder Stelle des Programms aus zugreifbar ist« ist dabei natürlich bei weitem nicht ausreichend.
Bernhard: Auf einer Konferenz mit Schwerpunkt Java-Programmierung habe ich einmal zwei Vorträge hintereinander gehört, der erste davon von Erich Gamma, der zu Entwurfsmustern vortrug. Befragt, ob er nicht einiger der Muster schon überdrüssig sei, meinte er, das Singleton-Pattern sei dasjenige, das er für am problematischsten hielte. In vielen Anwendungen sei es mittlerweile so, dass man eben Singletons einsetze und dann darauf verweise, dass man ja Entwurfsmuster im Einsatz habe, also die neuesten Modellierungstechniken verwende. Gleich im Anschluss sprach dann ein Firmenvertreter über eine Anwendung und hatte dabei zehn Folien für die Erläuterung des dort zentralen Singleton-Entwurfsmusters reserviert. Er war offensichtlich recht konsterniert, da er den Vortrag von Erich Gamma auch gehört hatte, und ging diesen Teil seines eigenen Vortrags ziemlich hastig durch.
Gregor: Ja, sehr nette Geschichte das, hat aber mit unserem Thema doch nur am Rande zu tun?
Bernhard: Ja, nur am Rande. Aber ich denke schon, dass Singletons zu häufig verwendet werden, weil sie eben so einfach zu implementieren sind und man sich über die Verwendung dann weniger Gedanken machen muss als zum Beispiel über eine Delegationsbeziehung. Wenn wir zusätzlich den Mechanismus der Dependency Injection verwenden, können wir Singletons praktisch komplett aus unseren Programmen entfernen. Zumindest sind sie dann im Programm selbst nicht mehr als Singletons erkennbar.
Die Einzigartigkeit eines Singletons ist also in der Regel keine Anforderung, sondern eher eine Variante der Umsetzung von Konsistenzbedingungen. Ein Modul, das Singletons nutzt, benötigt in der Regel einfach einen bestimmten Dienst. Ob dieser als Singleton vorliegt, ist nicht entscheidend. Wenn jemand dem nutzenden Modul ein Objekt übergeben würde, das diesen Dienst erbringt, wäre das genauso akzeptabel wie die Nutzung eines Singletons. Im folgenden Abschnitt werden Sie den Mechanismus der Dependency Injection kennen lernen, der unter anderem auch die Verwendung von Singletons vor einem nutzenden Modul versteckt.
7.2.7 Dependency Injection
In Abschnitt 7.2 und in den folgenden Abschnitten haben Sie gesehen, wie Sie über Fabriken eine Entkopplung von konkreten Klassen erreichen können. Aber warum müssen wir uns überhaupt mit Fabriken beschäftigen?
Fabriken außer Sichtweite
Seien Sie doch einmal ehrlich: Im Idealfall wollen Sie Fabriken doch gar nicht sehen. Das Stahlwerk im Industriegebiet nebenan ist ja auch aus gutem Grund kein beliebtes Ausflugsziel. Mit den Fabriken für Objekte ist es wie mit realen Fabriken: Interessant sind nur die erstellten Produkte, die Fabrik selbst kann ruhig hinter dichtem Baumbestand versteckt sein.
Eine in der Praxis erprobte Möglichkeit, Fabriken für nutzende Module unsichtbar zu machen, ist die sogenannte Dependency Injection.
|
Dependency Injection ist eine spezielle Form der Umkehrung des Kontrollflusses. Dabei werden genutzte Module von außen an das nutzende Modul übergeben. Die Übergabe kann dabei über einen Konstruktor, eine Setter-Methode oder spezielle Schnittstellen erfolgen. Die Kontrolle über das Erzeugen oder Auffinden der genutzten Module wird dabei an ein weiteres Modul transferiert. Deshalb findet eine Umkehrung des Kontrollflusses statt. |
Der Begriff Dependency Injection wurde von Martin Fowler geprägt, um dieses Verfahren vom generellen Mechanismus der Umkehrung des Kontrollflusses abzugrenzen. [Der Artikel von Martin Fowler zu diesem Thema ist verfügbar unter http://www.martinfowler.com/articles/injection.html. ] Wir halten den Begriff allerdings für etwas unglücklich, da er in seiner wörtlichen Übersetzung Einspritzung von Abhängigkeiten durchaus missverständlich ist. Das gewählte Vorgehen soll nämlich Abhängigkeiten zwischen Modulen und Klassen gerade aufheben, indem diese von einer weiteren Komponente verwaltet werden.
Aber was ist nun genau eigentlich Dependency Injection? Mit welchen Abhängigkeiten beschäftigt sich das Verfahren? Es geht dabei um das Erstellen von Objekten, von denen ein Modul abhängt, oder das Verfahren, wie solche Objekte gefunden werden, falls sie bereits existieren. Am besten betrachten wir dazu einfach einmal die Abhängigkeiten, um die es hier konkret geht, an einem Beispiel.
![]() Kunden und
Risikoprüfung
Kunden und
Risikoprüfung
Nehmen wir an, Sie wollen Kunden, von denen Sie die Daten bereits erfasst haben, erst dann in Ihrem System endgültig einrichten, wenn eine entsprechende Risikoprüfung durchgeführt worden ist. Wir machen hier die leicht vereinfachende Annahme, dass diese Prüfung alleine aufgrund des Nachnamens durchgeführt wird. [Obwohl: Wer weiß schon wirklich, wie zum Beispiel die Schufa bei der Einstufung von Kreditwürdigkeit vorgeht. Möglicherweise führen hier wirklich bestimmte Nachnamen (wie zum Beispiel »Zuiop«) zur Abwertung. ] Für die Risikoprüfung haben Sie eine Schnittstelle definiert, die Ihnen einfach sagt, ob Sie den Kunden annehmen oder ablehnen sollen. In Abbildung 7.19 sind die Beziehungen zwischen den Klassen aufgeführt, unter der Annahme, dass die Klasse KundenVerwaltung immer eine Risikoprüfung verwendet, die eine Bewertung bei der Schufa einholt.
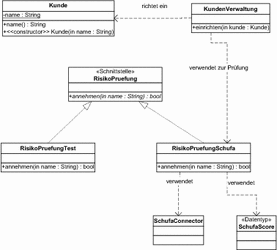
Abbildung 7.19 Beziehungen zwischen Kunden und der Schufa-Prüfung
Für das Einrichten eines Kunden führt die Klasse KundenVerwaltung zunächst eine Überprüfung durch, indem ein Exemplar der Klasse RisikoPruefungSchufa befragt wird, ob der betreffende Kunde auch angenommen werden kann.
Die Implementierung, die diese Prüfung an die Schufa weiterleitet, verursacht allerdings eine Reihe von Abhängigkeiten. Die Umsetzung könnte zum Beispiel wie in Listing 7.22 aussehen.
class RisikoPruefungSchufa implements RisikoPruefung {
public boolean annehmen(String name) {
SchufaConnector connector = getSchufaConnector();
connector.connect(getAuthentication());
SchufaScore score = connector.getSchufaScore(name);
return (score >= getScoreLimit());
}
}
Listing 7.22 Verbindung zur Schufa
Es ist also schon ersichtlich, dass Sie in diesem Fall eine direkte Verbindung zu einem Schufa-Server brauchen, um die Prüfung korrekt ausführen zu können, außerdem eine entsprechende Zugangskennung. Es lässt sich schon absehen, dass beides für Entwicklertests eher schwierig zu bekommen sein wird.
Die Kundenverwaltung nutzt dann die Schufa, um zuerst zu prüfen, ob das Risiko bezüglich eines Kunden überschaubar ist, bevor er im System eingerichtet wird.
class KundenVerwaltung {
// ...
void einrichten(Kunde kunde) {
RisikoPruefungSchufa pruefung =
new RisikoPruefungSchufa();
if (pruefung.annehmen(kunde.name())) {
// ... Kunde einrichten
}
}
}
Konstruktor im fachlichen Code
In Zeile sehen Sie, dass der Aufruf eines Konstruktors direkt in unserem Code stattfindet. Dieses Szenario ist doch auch im Kontext der Fabriken schon einmal aufgetaucht. Das resultierende Problem ist, dass Sie die Klasse KundenVerwaltung anpassen müssten, wenn Sie aus irgendeinem Grund die Art der Risikoprüfung austauschen wollen. Das wird aber sehr wahrscheinlich in mindestens einem Fall vorkommen: Beim Test Ihres Systems benötigen Sie ebenfalls eine Risikobewertung. Wenn Sie dabei zum Beispiel die Kreditwürdigkeit von Herr Zuiop prüfen wollen, werden Sie dazu sicherlich nicht eine Anfrage bei der Schufa auslösen wollen. Zum einen könnte das die ohnehin angeschlagene Kreditwürdigkeit Ihres Bekannten Qwert Zuiop weiter reduzieren. Zum anderen werden Sie für lokale Entwicklertests in der Regel keinen Zugriff auf die Schufa-Server haben. Für einen Test Ihrer eigenen Module wird es aber in der Regel ausreichen, wenn Sie ein Modul einsetzen können, das Ihnen simulierte Antworten auf die Anfragen zur Risikoprüfung liefert.
Diskussion: Abstrakte Fabrik als Lösung?
Gregor: Moment mal, das Problem hatten wir doch schon gelöst. Das ist doch ein klassischer Fall für eine abstrakte Fabrik. Soll doch unsere Kundenverwaltung einfach eine Fabrik verwenden, die ihr die konkrete Risikoprüfung zur Verfügung stellt.Bernhard: Du hast Recht, das würde die unmittelbare Abhängigkeit zwischen der Risikoprüfung und unserer Kundenverwaltung zunächst aufheben. Aber damit haben wir für diesen Fall das Problem erst einmal nur verlagert. Wir müssen nun die Fabrik im Code konkret benennen. Damit haben wir doch wieder ein Kopplung, zwar nicht zwischen konkretem Prüfungsverfahren und unserer Kundenverwaltung, aber zwischen der Fabrik für Prüfungsverfahren und der Kundenverwaltung. Auch wenn du die Fabrik als Singleton implementierst, musst du direkt im Code enscheiden, welche Fabrik denn nun verwendet werden soll.
Gregor: Aber diese Abhängigkeit kann ich doch auflösen, indem ich mich nicht auf eine konkrete Fabrik festlege, sondern der Klasse KundenVerwaltung nur die abstrakte Fabrik bekannt mache. Und die konkrete wird dann von außen übergeben.
Bernhard: Hier haben wir so ein bisschen ein Henne-Ei-Problem. Wer übergibt nun die Fabrik an unsere Kundenverwaltung? Und da sind wir genau an dem Punkt, an dem Frameworks für Dependency Injection ins Spiel kommen. Diese sorgen dafür, dass unser Code sich nicht darum kümmern muss, wie und wann dein konkretes Prüfungsverfahren an unser Kundenobjekt übergeben wird. Das übernimmt dann der Container für uns. Dieser agiert dabei auch als Fabrik für unsere Risikoprüfung.
Schauen Sie sich also einfach einmal eine auf Dependency Injection basierende Variante unseres Codes an. In Abbildung 7.20 sind die veränderten Beziehungen dargestellt.
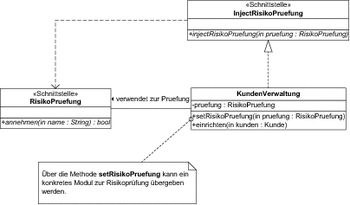
Abbildung 7.20 Dependency Injection: Übergabe über Setter-Methode
Die wichtigste Änderung ist, dass die Klasse KundenVerwaltung nun ein Datenelement pruefung enthält, das über die ebenfalls neue Methode setRisikoPruefung mit einem Wert belegt wird. Die Anpassungen sind auch in Listing 7.23 dargestellt. Die Änderungen sehen dabei zunächst nicht sehr spektakulär aus.
class KundenVerwaltung {
RisikoPruefung pruefung;
// ...
void setRisikoPruefung(RisikoPruefung pruefung) {
this.pruefung = pruefung;
}
void einrichten(Kunde kunde) {
if (pruefung.annehmen(kunde.name())) {
// ... Kunde einrichten
}
}
// ...
}
Listing 7.23 Klasse KundenVerwaltung mit Dependency Injection
In Zeile wird für die genutzte Risikoprüfung ein Datenelement definiert. Dazu haben wird die abstrakte Schnittstelle RisikoPruefung verwendet. In Zeile ist die Methode setRisikoPruefung definiert, mit der die konkrete Variante der Prüfung an die Kundenverwaltung übergeben wird. In Zeile wird dann diese Risikoprüfung verwendet, um einen Kunden vor dem Einrichten zu überprüfen.
Auf den ersten Blick sieht es so aus, als hätten Sie eine triviale Änderung vorgenommen: Sie haben einfach die Verantwortung dafür, welche Variante der Risikoprüfung verwendet und wie diese erstellt wird, von der Klasse KundenVerwaltung weggeschoben. Schließlich ist noch unklar, wer denn die Methode setRisikoPruefung aufrufen soll.
Umkehrung des Kontrollflusses
Die Änderung ist bei genauerer Betrachtung allerdings sehr relevant, und sie bietet Ihnen auch eine Reihe von neuen Möglichkeiten. Sie haben nämlich die Kontrolle darüber, welche konkrete Prüfung verwendet wird, an ein übergeordnetes Modul abgegeben. Sie haben den Kontrollfluss umgekehrt. Dabei wird die Kopplung zwischen nutzendem und genutztem Modul reduziert und das Zusammenspiel zwischen den beiden an ein drittes Modul delegiert.
Auf dieser Grundlage können Sie nun aufsetzen, um die Zusammenarbeit zwischen den Modulen per Konfiguration zu regeln. Dies bedeutet zunächst einmal einfach, dass Sie ein weiteres Modul haben, dem die Regeln bekannt sind, welche Objekte von welchen anderen genutzt werden. Diese Regeln können entweder im Code des Moduls stehen oder als Konfigurationsinformation ausgelagert sein, für das generelle Vorgehen spielt das keine Rolle. Die Entscheidung, ob Code oder separate Repräsentation (zum Beispiel in einer XML-Datei), sollte eher davon abhängen, ob Änderungen per Konfiguration wesentlich einfacher vorgenommen werden können.
Dependency Injection Framework
Ein sogenanntes Dependency Injection Framework kann die Aufgabe übernehmen, auf Basis der Konfigurationsinformation die Übergabe der genutzten Objekte an die nutzenden Objekte durchzuführen. Schauen wir uns das am Beispiel von Spring an. Spring ist ein sogenannter leichtgewichtiger (engl. lightweight) Container, dessen primäres Ziel es ist, die Komplexitäten, die bisher mit Containern (vor allem EJB-Containern) verbunden waren, abzubauen. Spring unterstützt das Verfahren der Dependency Injection in zwei Varianten. [Die Webseite zu Spring finden Sie unter der Adresse http://www.springframework.org. ]
In Listing 7.24 ist eine Konfiguration aufgeführt, die in Spring dazu führt, dass die Schufa-Risikoprüfung zusammen mit der Kundenverwaltung verwendet wird.
<beans>
<bean id="Verwaltung" class="KundenVerwaltung">
<property name="RisikoPruefung">
<ref local="RisikoPruefung"/>
</property>
</bean>
<bean id="RisikoPruefung" class="RisikoPruefungSchufa">
</bean>
</beans>
Listing 7.24 Konfiguration für Setter Injection in Spring
In Zeile wird festgelegt, dass das Objekt [In Spring wird der Begriff Bean für alle Objekte verwendet, die unter der Kontrolle des Spring-Frameworks erzeugt werden. ] mit der Identifikation Verwaltung zur Klasse KundenVerwaltung gehört. Wird dieses Objekt erstellt, so werden seine Eigenschaften so gesetzt, wie sie in den ab Zeile folgenden Properties beschrieben sind. In diesem Fall wird die Eigenschaft RisikoPruefung mit dem in Zeile beschriebenen Objekt verknüpft. Für diese wiederum ist festgelegt, dass sie durch die Klasse RisikoPruefungSchufa realisiert wird.
Die verwendete Klasse kann nun einfach per Konfiguration ausgetauscht werden. Soll in einem Testszenario die Simulation der Prüfung verwendet werden, so kann der Eintrag einfach geändert werden:
<bean id="RisikoPruefung" class="RisikoPruefungTest">
Damit diese Zuordnung automatisch funktionieren kann, muss der Lebenszyklus der betroffenen Objekte unter die Kontrolle des Containers gestellt werden. In Spring dürfen die Objekte deshalb nicht direkt konstruiert werden, sondern sie werden über den sogenannten Applikationskontext erzeugt. In Listing 7.25 ist ein einfaches Beispiel dafür aufgeführt.
void test(Kunden kunde) {
ApplicationContext context =
new FileSystemXmlApplicationContext("config.xml");
KundenVerwaltung verwaltung =
(KundenVerwaltung) context.getBean("KundenVerwaltung");
verwaltung.einrichten(kunde);
}
Listing 7.25 Verwendung eines Applikationskontextes
Dabei wird in Zeile ein Applikationskontext auf Basis einer XML-Konfigurationsdatei angelegt. Diese enthält unter anderem die Einträge aus Listing 7.24. In Zeile wird ein Exemplar der Klasse KundenVerwaltung unter Verwendung des Applikationskontexts konstruiert. Auf der Grundlage der Konfiguration wird diesem Objekt bereits ein Exemplar der Klasse RisikoPruefungSchufa übergeben. Die Operation einrichten in Zeile kann in der Folge aufgerufen werden und wird die Prüfung gegenüber der Schufa verwenden. In unserem Code ist die konkrete Klasse RisikoPruefungSchufa allerdings nirgendwo sichtbar.
Diskussion: Konfigurierbare Fabrik
Gregor: Jetzt mal langsam, hier muss ich noch einmal nachhaken. Wir hatten doch im Abschnitt über konfigurierbare Fabriken schon eine Möglichkeit beschrieben, wie wir die konkrete Objekterzeugung über Konfigurationseinstellungen und die Nutzung von Reflexion auslagern können.Bernhard: Dependency Injection geht hier noch einen Schritt weiter. Der konkrete Typ des erzeugten Objekts wird dabei ebenfalls per Konfiguration festgelegt, das ist schon richtig. Allerdings wird die Kontrolle über die Objekterzeugung und die Wahl des konkreten Typs komplett an ein anderes Modul, den sogenannten Container, abgegeben. In der Regel ist es auch so, dass der Container die Kontrolle über den Lebenszyklus der genutzten Objekte hat.
Drei Varianten von Dependency Injection
In den oben stehenden Beispielen wurde das genutzte Modul grundsätzlich über eine Setter-Methode übergeben. Dies ist aber nicht die einzige Möglichkeit der Übergabe. Es lassen sich drei unterschiedliche Arten von Dependency Injection unterscheiden:
- Setter Injection
- Constructor Injection
- Interface Injection
In Abbildung 7.21 ist die Klasse KundenVerwaltung so angepasst, dass sie alle drei Arten unterstützt.
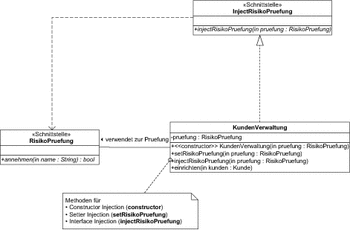
Abbildung 7.21 Verschiedene Arten von Dependency Injection
Setter Injection
Setter Injection haben Sie bereits im obigen Beispiel gesehen, da hier die Risikoprüfung über eine Setter-Methode an die Kundenverwaltung übergeben wird. Das benötigte Modul kann dann über das Framework, das die Kontrolle ausübt, mittels Aufruf der Setter-Methode (in unserem Beispiel setRisikoPruefung) eingebracht werden.
Constructor Injection
Constructor Injection sorgt dafür, dass die benötigten Module über den Konstruktor übergeben werden. Die abhängigen Klassen müssen Konstruktoren definieren, die als Argument ein Exemplar der benötigten Klasse nehmen. In unserem Beispiel würden Sie zu diesem Zweck einfach statt der zusätzlichen Setter-Methode einen Parameter zum Konstruktor hinzufügen.
class KundenVerwaltung {
RisikoPruefung pruefung;
KundenVerwaltung(RisikoPruefung pruefung) {
this.pruefung = pruefung;
}
Interface Injection
Interface Injection basiert darauf, dass eine explizite Schnittstelle zur Verfügung steht, mit der genutzte Module ihren Nutzern zugeordnet werden können. In unserem Beispiel würden Sie also eine Schnittstelle InjectRisikoPruefung einführen.
interface InjectRisikoPruefung {
void injectRisikoPruefung(RisikoPruefung pruefung);
}
Diese muss vom nutzenden Modul implementiert werden, in diesem Fall also von der Klasse KundenVerwaltung.
class KundenVerwaltung implements InjectRisikoPruefung {
RisikoPruefung pruefung;
public void injectRisikoPruefung(
RisikoPruefung pruefung) {
this.pruefung = pruefung;
}
Die Verwendung von Interface Injection hat aber den Nachteil, dass hier mehr Abhängigkeiten entstehen als bei der Verwendung von Constructor Injection oder Setter Injection. Dadurch, dass die konkreten Klassen alle spezifischen Schnittstellen implementieren müssen, sind sie natürlich auch von diesen abhängig. Bei Verwendung von Konstruktoren oder Setter-Methoden sind die Klassen dagegen von nichts abhängig, was sie nicht direkt benötigen. Bei Interface Injection muss für jede Art der Abhängigkeit eine Schnittstelle definiert werden. Diese Notwendigkeit entfällt bei den anderen Varianten ebenfalls.
Einsatz von Dependency Injection
Was kann Dependency Injection?
Dependency Injection eignet sich gut, um das Zusammenstellen von Anwendungen aus verschiedenen Modulen zu unterstützen. Damit erlaubt das Verfahren eine Verwaltung von verschiedenen Konfigurationen. Alle Module, die über das Framework eingeschoben werden, können Bestandteil einer Konfiguration sein. So können verschiedene Testkonfigurationen aufgebaut werden, oder möglicherweise kann auch für den Betrieb zwischen lokaler Umsetzung von Diensten oder eine Nutzung von Diensten auf einem Server umgeschaltet werden.
Allerdings ist Dependency Injection auch kein genereller Ersatz für Fabriken. Der Fokus bei Dependency Injection liegt auf der Zusammenstellung von verschiedenen Konfigurationen und der Entkopplung von Modulen, die sich nicht gegenseitig kennen müssen. Allerdings zahlen Sie, wie sollte es auch anders sein, einen Preis für die Entkopplung: In unserem Code ist nicht mehr direkt sichtbar, welches Modul nun verwendet wird. Die Anwendung kann nur im Zusammenhang mit ihrer Konfiguration komplett betrachtet werden.
Alternative: Service Locator
Dependency Injection ist auch nicht der einzige Weg, über eine Konfiguration festzulegen, welche konkrete Umsetzung eines Dienstes verwendet wird. Sie können eine Entkopplung auch darüber erreichen, dass Sie über einen Namen (zum Beispiel den der benötigten Schnittstelle) die zuständige Implementierung bei einem zentralen Modul erfragen. Durch die Indirektion über dieses sogenannte Diensteverzeichnis (engl. Service Locator) erreichen Sie auch, dass beide betroffenen Module keine Kenntnis mehr voneinander haben.
| Diensteverzeichnis (Service Locator) |
|
Ein Diensteverzeichnis ist ein Objekt, das für alle Dienste, die eine Applikation benötigt, eine Realisierung kennt und diese im Bedarfsfall liefern kann. Für die betroffenen Dienste muss eine abstrakte Schnittstelle zur Verfügung stehen. Auf Anfrage liefert das Diensteverzeichnis zu jeder Schnittstelle eine Realisierung. |
Der entscheidende Unterschied zwischen der Verwendung eines Service Locators und dem Mechanismus der Dependency Injection ist aber, dass beim Service Locator die Umkehrung des Kontrollflusses nicht stattfindet, weil unser nutzendes Modul immer noch aktiv nach dem zu nutzenden Modul fragen muss, indem es den Service Locator anspricht. Diese Abhängigkeit muss nicht in allen praktischen Fällen ein Problem darstellen. Wir müssen dann aber sicherstellen können, dass ein korrekt arbeitender Service Locator immer zusammen mit unserem Modul zur Verfügung steht.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

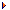 Jetzt Buch bestellen
Jetzt Buch bestellen



