


6.2 Speicherung in Datenbanken 

Diejenigen Objekte einer Anwendung, bei denen die zugehörigen Daten länger benötigt werden als nur bis zum Beenden des Programms, werden in der Regel in Datenbanken gespeichert. Der weitaus größte Teil von Anwendungen nutzt dabei die relationalen Datenbanken. Die Daten von Objekten werden dabei in Tabellen der relationalen Datenbank gespeichert und wieder ausgelesen, wenn das Objekt aus diesen Daten wieder hergestellt werden soll.
Wir gehen deshalb in den folgenden Abschnitten genauer auf die Zusammenarbeit von objektorientierten Systemen mit relationalen Datenbanken ein. Wir werden zunächst ab Abschnitt 6.2.1 einen kurzen Überblick über die Grundstrukturen von relationalen Datenbanken geben. Abschnitt 6.3 geht darauf ein, wie ein Objektmodell auf relationale Datenbanken abgebildet werden kann. Schließlich stellen wir in Abschnitt 6.4 den Prozess der Normalisierung einer relationalen Datenbank vor und zeigen für die verschiedenen Normalformen, dass unsere zuvor definierten Abbildungsregeln zur Einhaltung der Normalform führen.
6.2.1 Relationale Datenbanken
Relationale Datenbanken als Standard
Insbesondere für die Speicherung der Daten in Unternehmen haben sich die relationalen Datenbanksysteme durchgesetzt. In den relationalen Datenbanken werden keine Objekte, sondern Fakten und die Relationen dieser Fakten untereinander gespeichert. Wenn die Daten einer objektorientierten Anwendung in einer relationalen Datenbank gespeichert werden, müssen wir also eine Vorgehensweise definieren, nach der die Informationen über die gespeicherten Objekte auf die Fakten und Relationen in der Datenbank abgebildet werden. Diesem Thema werden wir uns in diesem Abschnitt widmen.
Was ist mit Objektdatenbanken?
Man kann sich die Frage stellen, warum die relationalen Datenbanken nicht von objektorientierten Datenbanken abgelöst worden sind. Immerhin gibt es das objektorientierte Programmieren seit mehreren Dekaden, und die ersten objektorientierten Datenbanken sind auch schon mehr als 15 Jahre alt.
Wir können hier keine Antwort auf diese Frage geben, nur eine Vermutung: Die Stärke der Objektorientierung ist es, die Komplexität der Programme zu verringern, indem sie den Programmablauf und die dazugehörigen Daten zu Objekten bündelt. Die Aufgabe einer Datenbank ist jedoch eine andere. Ihr Zweck besteht darin, Daten zu enthalten. Es ist nicht die primäre Aufgabe der Datenbank, die Abläufe und Prozesse, die mit diesen Daten arbeiten, zu verwalten. Ein Unternehmen benutzt eine Datenbank, um Daten zu speichern. Die Geschäftsprozesse ändern sich häufig, die Daten bleiben. Dies und die Reife der relationalen Datenbanksysteme gehören unserer Meinung nach zu den Hauptgründen, warum relationale Datenbanksysteme noch für lange Zeit die meistgenutzten Systeme für die Speicherung von Unternehmensdaten sein werden.
6.2.2 Struktur der relationalen Datenbanken
Widmen wir also den relationalen Datenbanksystemen und deren Verwendung in objektorientierten Anwendungen etwas Zeit.
Um Objekte aus einer relationalen Datenbank laden und sie dort wieder speichern zu können, müssen wir beschreiben, welche Daten eines Objekts in welchen Strukturen der Datenbank gespeichert werden. Diese Abbildung der Objektdaten auf die Datenbankstrukturen muss vor allem die folgenden Informationen beinhalten:
- Welche Attribute in der Datenbank stehen mit welchen Attributen von Klassen in Beziehung?
- Wie werden Vererbungsbeziehungen in der Datenbank abgebildet?
- Wie sind die Beziehungen zwischen den Objekten in der Datenbank abgebildet?
Objektrelationale Mapper
Die resultierenden Aufgaben werden in der Praxis in der Regel von verschiedenen Werkzeugen, den sogenannten objektrelationalen Mappern, gut erledigt. Beispiele für solche Mapper sind Toplink (Oracle) und Hibernate (freie Software). Eine weitere Form stellt auch das konfigurierbare Mapping für Entity Beans in J2EE dar.
Obwohl also in der Praxis Werkzeuge wie die oben genannten eine ganze Menge Arbeit bei der Abbildung abnehmen, ist es sinnvoll, die verschiedenen Möglichkeiten eines Mappings aus der relationalen Welt in die Welt der Objekte zu verstehen. Auch hier gilt wieder: Transparenz ist nur bis zu einem gewissen Grad möglich. Spätestens wenn die Abbildung in Bezug auf Performanz und Effizienz optimiert werden muss, ist ein Blick hinter die Kulissen notwendig.
6.2.3 Begriffsdefinitionen
Bevor wir uns der Abbildung von Objekten auf relationale Datenbanken widmen, sollten wir einige Begriffe definieren, die wir verwenden werden.
Funktionen
In der Mathematik ist eine Funktion eine eindeutige Abbildung der Elemente einer Menge auf die Elemente einer anderen Menge. Meistens wird eine Funktion als eine Berechnungsvorschrift definiert. So kann man zum Beispiel eine Funktion f(x) = sin(x) + 2x˛ definieren, die jedem x aus der Domäne der reellen Zahlen einen ebenfalls reellen Wert zuordnet.
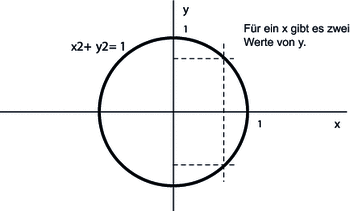
Abbildung 6.1 Relation »Kreis« zwischen den Koordinaten x und y
Doch es ist nicht nötig, dass es eine solche Vorschrift gibt, man kann eine Funktion auch durch das Aufzählen der Werte für die jeweiligen Argumente definieren. Und genau darum geht es bei den Datenbanken – die Fakten zu speichern, die sich nicht aus einer Formel berechnen lassen.
So können wir die Funktion Land(Stadt) definieren, die für jede (gespeicherte) Stadt das dazugehörige Land zurückgibt. Hier gibt es aber keine Möglichkeit, die Daten zu berechnen, wir müssen sie also speichern.
| Stadt | Land |
|
Berlin |
Deutschland |
|
Köln |
Deutschland |
|
London |
Vereinigtes Königreich |
|
Linz |
Österreich |
|
… |
… |
Eine Funktion kann durchaus auch mehrere Parameter haben. So kann zum Beispiel eine Funktion Film(Kinosaal, Uhrzeit) eindeutig bestimmen, welcher Film in welchem Saal eines Multiplexkinos zu welcher Uhrzeit läuft.
Funktion: eindeutige Beziehung
Eine Funktion ist also eine eindeutige Beziehung zwischen einem Argument, oder einem ganzen Tupel von Argumenten, und einem Wert der Funktion. Doch nicht alle interessanten Beziehungen zwischen Fakten lassen sich als eine Funktion formulieren. Denn manche Beziehungen sind nicht eindeutig.
Für die Beziehung der Koordinaten x und y einer Kreislinie mit dem Mittelpunkt (0,0) und dem Radius 1 gilt zum Beispiel die Formel x˛+y˛=1, nur für die Werte 1 und –1 von x lässt sich ein eindeutiger Wert von y bestimmen (0). Alle anderen Werte von x haben entweder gar keinem oder zwei zugehörige Werte von y. Man kann zwar im Allgemeinen keinen eindeutigen Wert y zu einem beliebigen x bestimmen, man kann aber immer eindeutig entscheiden, ob ein Paar (x, y) zu der Kreislinie gehört oder nicht.
Relation: Beziehung zwischen Mengen
Eine solche Beziehung zwischen Elementen mehrerer Mengen nennt man eine Relation. Für die Definition einer Relation ist die Eindeutigkeit nicht wichtig, ausschlaggebend ist nur, dass man bestimmen kann, ob ein Tupel der Elemente der Argumentmengen (der Domänen) zu der Relation gehört oder nicht. Die Relation definiert keine Reihenfolge der Tupel, sie bestimmt nur, ob ein Tupel zu ihr gehört oder nicht.
Aus der Sicht der Datenbanksysteme sind Relationen, für die es eine Berechnungsformel gibt, nicht besonders interessant. Die Datenbanksysteme gibt es, um Informationen über Relationen zu speichern, für die es eben keine solche Formel gibt.
RDBMS
Die relationalen Datenbanksysteme (RDBMS für Relational Database Management System) verwalten also Informationen über Relationen zwischen den Fakten aus verschiedenen Domänen.
Ein Element einer Relation ist ein Tupel, der aus Elementen der Domänen dieser Relation besteht. Bei den gespeicherten Daten spricht man auch von Datensätzen (engl. Record) einer Relation, die aus Feldern (engl. Field) bestehen. In einer relationalen Datenbank gibt es verschiedenartige Relationen. Gespeichert werden die Tabellen, von den Tabellen können andere Relationen abgeleitet werden – die Ansichten (engl. View) und die Abfragen (engl. Queries). Wenn wir uns die tabellarische Darstellung einer Relation ansehen, ist recht schnell klar, warum wir die Begriffe Zeile beziehungsweise Spalte als Synonyme für die Begriffe Datensatz und Feld verwenden. In Abbildung 6.2 ist eine Relation am Beispiel dargestellt.
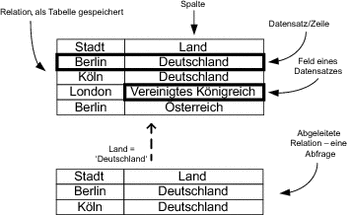
Abbildung 6.2 Relation Stadt-Land
Funktionale Abhängigkeit
Die Funktionen gehören auch zu den Relationen. Wenn man immer anhand einiger Felder die Werte anderer Felder in einem Datensatz eindeutig bestimmen kann, spricht man von einer funktionalen Abhängigkeit. So besteht in unseren Beispielen eine funktionale Abhängigkeit zwischen der Stadt und dem Land, in dem die Stadt liegt, nicht aber umgekehrt, denn in einem Land können mehrere Städte liegen. [Wir gehen hier von der vereinfachten Sichtweise aus, dass eine Stadt immer nur in einem Land liegt. ] Es besteht auch eine funktionale Abhängigkeit zwischen einem Kinosaal und einer Uhrzeit einerseits und einem Film andererseits, es besteht jedoch keine funktionale Abhängigkeit zwischen einem Kinosaal alleine und einem Film, denn um den Film eindeutig bestimmen zu können, brauchen wir auch die Uhrzeit.
Schlüssel
Wenn wir anhand der Werte einiger Spalten einer Relation den kompletten Datensatz eindeutig bestimmen können, bilden die Spalten einen Schlüssel der Relation. Man sollte hier nicht die Bedeutung des Wortes »bestimmen« mit der Bedeutung des Wortes »berechnen« verwechseln. Dass wir anhand der Werte der Spalten eines Schlüssels die Werte der anderen Spalten der Relation eindeutig bestimmen können, bedeutet nicht, dass man den Wert nach einer Formel berechnen kann, sondern dass es eine fachliche Regel gibt, die besagt, dass es zu einer Kombination der Werte der Schlüsselspalten nur einen einzigen Datensatz in der Relation geben kann.
Es besteht also immer eine funktionale Abhängigkeit zwischen einem Schlüssel einer Relation und allen anderen Spalten dieser Relation. Eine Relation kann auch mehrere Schlüssel haben. So kann man zum Beispiel einen Mitarbeiterdatensatz sowohl über die E-Mail-Adresse des Mitarbeiters als auch über seine Personalausweisnummer eindeutig identifizieren. Und offensichtlich, wenn einige Spalten einen Schlüssel bilden, entsteht so auch ein Schlüssel (ein Überschlüssel), wenn man weitere Spalten hinzufügt.
Tabellen ohne Schlüssel?
Obwohl die meisten relationalen Datenbanken es zulassen, dass man Tabellen ohne einen Schlüssel anlegt, ist dies sehr selten eine gute Idee. Denn wenn in einer Tabelle gleiche Datensätze vorkommen können, kann man sie nicht eindeutig identifizieren – zumindest nicht mit den Mitteln der relationalen Theorie. Ein Tupel kann nämlich zu einer Relation entweder gehören oder nicht gehören, es kann zu der Relation jedoch nicht »mehrfach« gehören. Eine derartige Information kann für die Anwendung zwar relevant sein, man sollte aber über eine alternative Speichermöglichkeit nachdenken – über eine, die sich als eine Relation abbilden lässt.
Schlüsselkandidat Primärschlüssel Alternativschlüssel
In der Praxis wählt man einen der Schlüssel einer Tabelle aus und deklariert ihn als den Primärschlüssel der Tabelle. Andere Schlüssel der Tabelle nennt man auch ihre Alternativschlüssel, alle zusammen nennt man auch Schlüsselkandidaten. Welcher der Schlüssel zum Primärschlüssel ausgewählt werden sollte, ist eine technische Entscheidung. Die Theorie befasst sich nicht mit der effizienten technischen Umsetzung der Datenbanken, dies wird dem jeweiligen Datenbankhersteller überlassen. Dem Anwender der Datenbank müssen die technischen Möglichkeiten der verwendeten Datenbank jedoch bekannt sein, damit er sie effektiv nutzen kann. Relationale Datenbanken verwenden verschiedene Hilfsmittel, um die gesuchten Datensätze effektiv zu finden.
Index
Zu den meistverwendeten solcher Hilfsmittel gehören die Indizes. Für welche Spaltengruppen ein Index angelegt werden sollte, ist aber keine Entscheidung, die relationale Theorie beantworten kann. Um eine solche Entscheidung zu treffen, müssen wir wissen, anhand welcher Spalten die Datensätze meistens gesucht werden. Und da man in den meisten Fällen einen Index für den Primärschlüssel anlegen wird, ist es oft eine gute Idee, den Schlüssel zum Primärschlüssel zu machen, nach dem häufiger gesucht wird. Da wir aber Indizes auch für andere Spalten anlegen können, ist dies lediglich ein Hinweis.
Fremdschlüssel
In einer relationalen Datenbank werden meistens mehrere Relationen verwaltet. Manche werden Spalten aus den gleichen Domänen haben. So kann man zum Beispiel eine Tabelle der Mitarbeiter mit der Spalte E–Mail-Adresse und eine andere Tabelle der E-Mails mit der Spalte Absender-Adresse aus der gleichen Domäne der E-Mail-Adressen haben. Eine Absenderadresse ist in der Tabelle der E-Mails kein Schlüssel, denn ein Mitarbeiter kann mehrere Mails verschickt haben, sie identifiziert aber eindeutig einen Datensatz in der Tabelle der Mitarbeiter.
Wenn eine Spaltengruppe einer Relation einen Datensatz einer anderen Relation eindeutig bestimmen kann, spricht man von einem Fremdschlüssel.
NULL-Werte
Bisher haben wir davon gesprochen, dass eine Relation aus Element-Tupeln besteht, die zu dieser Relation gehören. Eine solche Relation kann als eine Tabelle in einer relationalen Datenbank gespeichert werden. Wir könnten für das Speichern unserer Kontaktdaten eine Relation mit folgenden Feldern definieren: (Vorname, Nachname, Straße, Hausnummer, Postleitzahl, Stadt, Telefonnummer, Faxnummer, E-Mail). Nun, in einer solchen Relation könnten wir keine Daten von Leuten, die kein Faxgerät besitzen oder deren Adresse wir nicht kennen, speichern.
Mehrere Relationen
Stattdessen könnten wir mehrere Relationen definieren:
- (Vorname, Nachname, Straße, Hausnummer, Postleitzahl, Stadt)
- (Vorname, Nachname, Telefonnummer)
- (Vorname, Nachname, Faxnummer)
- (Vorname, Nachname, E-Mail)
Alle vier Relationen haben einen Schlüssel, der aus den Spalten (Vorname, Nachname) besteht – wir gehen jetzt vereinfacht davon aus, dass wir Menschen mit gleichen Namen durch einen Namenszusatz zum Beispiel in der Spalte Vorname eindeutig auseinander halten können.
In der Datenbank müssten wir für jeden Kontakt, den wir speichern möchten, also bis zu vier Einträge mit dem Vor- und dem Nachnamen erzeugen. Dies könnte wenig effizient sein, wenn wir für die meisten Kontakte tatsächlich alle vier Einträge speichern würden.
Eine Abhilfe bieten hier die NULL-Werte. Man kann in einer Tabelle bestimmen, welche Spalten einen Wert haben müssen und welche leer bleiben können. Auf diese Art kann man mehrere fachliche Relationen in einer Tabelle speichern und so den Speicherplatz effektiver nutzen. Die Schlüssel-Spalten können natürlich keinen NULL-Wert enthalten.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



