


5.4 Speichermanagement
Zur Wiederholung erläutern wir zunächst noch einmal das Prinzip des virtuellen Speichers: Dieses stellt sicher, dass jeder Task beziehungsweise jeder Prozess seinen eigenen Adressraum besitzt. Um dies zu erreichen, können Programme nicht direkt auf den Hauptspeicher, sondern nur auf virtuelle Adressen zugreifen, die erst in entsprechende reale Adressen übersetzt werden müssen.
[zB]Mit dem virtuellen Speicher ist es also möglich, dass ein Prozess A in der Speicheradresse 0x010010 den Wert 4 und Prozess B den Wert 10 speichert. Beide Prozesse merken nichts voneinander, da für Prozess A die virtuelle Adresse 0x010010 beispielsweise in die reale Adresse 0x111010 und für Prozess B in die reale Adresse 222010 übersetzt wird. Beide Prozesse wissen nichts voneinander und können sich auch nicht gegenseitig beeinflussen. Für jeden Prozess sieht es so aus, als ob er den gesamten Speicherbereich für sich allein hätte.
5.4.1 Paging
Verwaltung des Hauptspeichers
Ein sehr wichtiger Bestandteil des Speichermanagements ist das Paging. Hierzu wird der
verfügbare Speicher zur besseren Verwaltung in Seiten unterteilt, die zum Beispiel bei Intels x86-Architektur meist
in 4KB groß sind. Bei der Übersetzung von virtuellen in reale Adressen muss
also nicht mehr jede Adresse einzeln verwaltet, sondern es muss lediglich festgestellt werden:
- Zu welcher Seite eine bestimmte Adresse gehört und
- auf welche physische Seite diese virtuelle Seite übersetzt wird.
Eine »Seite« definiert sich also über die Adressen der entsprechenden 4-KB-Blöcke. Der Adressraum wird mit anderen Worten passend aufgeteilt, anstatt die Seiten dort willkürlich aufzuteilen. Dieses Vorgehen hat außerdem den Vorteil, dass die externe Fragmentierung des Hauptspeichers vermieden wird. Natürlich kann eine Seite noch intern fragmentieren, es kann also Platz verschenkt werden, wenn einzelne Seiten nicht ganz voll sind.
[zB]Man kann sich das so vorstellen, dass bei Adressen der Form 0x010010 beispielsweise die letzten drei Stellen der Adresse zu einer Seite zusammengefasst werden. In diesem Fall würden alle Adressen von 0x010000 bis 0x010FFF auf der entsprechenden Seite 0x010 liegen. Das Betriebssystem muss sich dann nur noch »merken«, dass die virtuelle Seite 0x010 des Prozesses A beispielsweise auf die physische Seite 0x111 gemappt ist, um den korrekten physischen Speicherort für eine konkrete Adresse (wie beispielsweise 0x010010) zu finden.
Swapping
Auslagern auf die Platte
Außerdem wird durch die Verwaltung von ganzen Seiten statt einzelner Adressen auch das bereits vorgestellte Swapping vereinfacht, bei dem ja bestimmte länger nicht benötigte Speicherbereiche auf die Festplatte ausgelagert werden. Praktischerweise kann man sich beim Paging auf Auslagerungs-Algorithmen für ganze Seiten konzentrieren.
Bei diesen Auslagerungs-Algorithmen geht es nun darum, eine Seite zu finden, die möglichst nicht so bald wieder gebraucht wird. Durch das Auslagern solcher alter Speicherseiten wird bei einer starken Auslastung des Hauptspeichers wieder Platz frei. Für die Ermittlung der zu ersetzenden Seiten gibt es nun unter anderem folgende Verfahren:
- First in – first out
Die Speicherseite, die zuerst angefordert wurde, wird zuerst ausgelagert. - Least recently used
Bei dieser Strategie wird die am längsten nicht genutzte Seite ausgelagert. - Not recently used
Seiten, die in einem bestimmten Zeitintervall nicht benutzt und nicht modifiziert wurden, werden bei dieser Strategie bevorzugt ausgelagert. Gibt es keine solche Seite, wird auf die anderen Seiten zurückgegriffen. - Not frequently used
Hier werden bevorzugt Seiten ausgelagert, auf die in letzter Zeit nicht häufig zugegriffen wurde.
Heutzutage wird Speicher immer billiger. Normale Mittelklasse-PCs haben schon mehrere Gigabyte RAM und Speicheraufrüstungen sind nicht teuer. Aus diesem Grund verliert das Swapping immer mehr an Bedeutung, auch wenn gleichzeitig der Speicherhunger der Applikationen immer größer wird.
Die Pagetable
Der virtuelle Speicher und somit auch das Paging wird vom Betriebssystem verwaltet. Der Kernel sorgt dafür, dass jeder Prozess seinen eigenen Speicherbereich besitzt und auch entsprechend Speicher anfordern kann. Irgendwo muss es also eine Tabelle geben, die jeder virtuellen Seite eines Prozesses eine physische zuordnet. In dieser Tabelle müsste dann auch entsprechend vermerkt sein, wenn eine Seite ausgelagert wurde.
Eigener Speicher für jeden Prozess
Die sogenannte Pagetable erfüllt genau diesen Zweck. Der Logik folgend muss also für jeden Prozess beziehungsweise Task eine eigene Pagetable existieren, während die Threads eines Tasks ja alle auf demselben Adressraum operieren und somit keine eigene Pagetable brauchen. Die Seitentabelle liegt dabei im Hauptspeicher und enthält auch diverse Statusinformationen:
- Wurde auf die Seite in letzter Zeit zugegriffen?
- Wurde die Seite verändert?
Interessant ist außerdem der Zusammenhang zwischen der Größe der Pagetable und der Seitengröße: Je größer eine Seite ist, desto höher ist die Möglichkeit zu interner Fragmentierung, aber umso kleiner wird die Pagetable. Schließlich lässt sich der Hauptspeicher bei einer höheren Seitengröße insgesamt in weniger Seiten zerlegen, was sich dann direkt auf die Anzahl der Elemente in der Seitentabelle niederschlägt.
5.4.2 Hardware
Das Umsetzen des Pagings kann natürlich nicht ohne entsprechenden Hardware-Support realisiert werden. Maschinenbefehle greifen nun einmal direkt auf den Hauptspeicher zu, ohne dass das Betriebssystem irgendeine Möglichkeit hätte, diese Übersetzung per Software zu bewerkstelligen.
Die MMU
Als Hardware-Element, das diese Übersetzung vornimmt, haben wir Ihnen bereits kurz die Memory Management Unit (MMU) vorgestellt. Nach der Einführung des Pagings können wir nun auch im Detail erklären, wie die Übersetzung der virtuellen in die physische Adresse von der Hardware vorgenommen wird:
- Aus der virtuellen Adresse wird die zugehörige virtuelle Seite berechnet.
- Die MMU schaut in der Pagetable nach, auf welche physische Seite diese virtuelle Seite abgebildet wird.
- Findet die MMU keine entsprechende physische Seite, wird dem Betriebssystem ein Page Fault (Seitenfehler) geschickt.
- Andernfalls wird aus dem Offset (also dem Abstand der abzufragenden virtuellen Adresse vom Seitenanfang) sowie dem Beginn der physischen Seite die physische Adresse berechnet.
- Der Wert, der an dieser physischen Adresse gespeichert ist, wird jetzt vom Hauptspeicher zum Prozessor kopiert.
Die MMU speichert also keine Kopie der Seitentabelle, sondern bei jedem Prozess- beziehungsweise Taskwechsel werden bestimmte Register neu gesetzt, die zum Beispiel die physische Adresse des Anfangs der Seitentabelle im Hauptspeicher enthalten. Das Verfahren bei einem Speicherzugriffsfehler haben wir ebenfalls kurz erläutert.
Page Fault
Der aktuell laufende und den Fehler verursachende Prozess wird durch einen Page Fault-Interrupt [Fn. Eigentlich handelt es sich bei einem Seitenfehler nicht um einen Interrupt, sondern vielmehr um eine Exception. Die Unterbrechung ist nämlich eine gewisse »Fehlermeldung« der MMU und tritt synchron, also immer direkt nach einem fehlerhaften Zugriff, auf. Da das ausgeführte Programm jedoch wirklich unterbrochen wird, wollen wir bei der Bezeichnung Interrupt für dieses Ereignis bleiben, auch wenn dies formell nicht ganz korrekt sein mag.] unterbrochen und das Betriebssystem mit der entsprechenden Behandlungsroutine gestartet, die nun dafür sorgt, dass die entsprechende Seite wieder eingelagert und die Seitentabelle aktualisiert wird. Dann kann die fehlgeschlagene Instruktion des abgebrochenen Programms wiederholt werden, da die MMU jetzt eine entsprechende physische Seite finden kann.
Natürlich kann ein Programm auch durch fehlerhafte Programmierung einen Seitenfehler verursachen, wie etwa das folgende Beispielprogramm:
Listing 5.21 Ein Programm, das einen Absturz durch einen Seitenfehler verursacht
#include <stdio.h>
int main()
{
char* text = "Hello, World!\n";
// Hier wird fälschlicherweise eine neue Adresse zugewiesen
text = 13423;
printf(text);
return 0;
}
Speicherzugriffsfehler
Die Variable text ist hier ein Zeiger auf den Text »Hello, World!«. Sie enthält also nicht den Text selbst, sondern nur die Adresse, wo dieser zu finden ist. [Fn. In C sind diese Zeiger oder auch Pointer genannten Variablen sehr mächtig, in anderen Programmiersprachen versteckt man diese Interna teilweise.] Diese Adresse wird nun im Folgenden »versehentlich« verändert. Beim Versuch, die Zeichenkette auf dem Bildschirm auszugeben, wird nun die MMU zu der betreffenden virtuellen Seite keine physische finden. Das Betriebssystem wird nun wiederum per Page Fault benachrichtigt, kann aber mit dem Fehler nichts anfangen – die betreffende Seite wurde nie ausgelagert. Daher wird der verursachende Prozess mit einem Speicherzugriffsfehler beendet.
Der TLB
Der MMU-Cache Der Translation Lookaside Buffer (TLB) ist dafür da, den Zugriff auf häufig genutzte Seiten zu beschleunigen. Der TLB funktioniert dabei als eine Art Cache für die Adressübersetzungen: Da Programme in begrenzten Codeabschnitten meist nur einige wenige Variablen nutzen, werden dort nur jeweils wenige Seiten wieder und wieder genutzt. Damit für diese Adressen der zeitraubende Zugriff auf die Seitentabelle entfallen kann, speichert der TLB die zuletzt übersetzten virtuellen Seiten.
Wird nun bei einem Zugriff festgestellt, dass die angeforderte virtuelle Adresse im TLB gepuffert wurde, kann man sich die komplizierte Übersetzung sparen. Sinnvollerweise ist der TLB dabei ein besonderer Teil der MMU, da hier der Hardware-Support für den virtuellen Speicher angesiedelt ist.
Natürlich wird bei einem Task-Wechsel mit der MMU auch der TLB geändert: Es werden nämlich alle gepufferten Übersetzungen gelöscht. Für die Dauer einer Zeitscheibe hat dies eine gewisse Auswirkung, da eine Mindestlänge nötig ist, um die Vorteile des TLB und anderer Puffer und Caches wirklich ausnutzen zu können.
5.4.3 Organisation des Adressraums
Wir haben bereits viele Details der Speicherverwaltung behandelt, aber noch nicht die genaue Organisation des Adressraums unter die Lupe genommen. Im Folgenden wollen wir noch einmal zusammenfassen, was wir bisher über den Adressraum – also den für einen Prozess sichtbaren Hauptspeicher – alles wissen:
- Virtualisierung
Der Speicher und damit natürlich auch der Adressraum sind virtualisiert. Jeder Prozess/Task hat seinen eigenen virtuellen Adressraum, auf den er über virtuelle Speicheradressen zugreift. - Code und Daten
Im Adressraum des Prozesses sind der auszuführende Programmcode sowie alle benutzten Daten gespeichert. - Stack
Der Stack besteht aus besonderen Daten, denn hier werden die Funktionsaufrufe verwaltet. Jeder neue Aufruf wird dabei oben auf dem Stack abgelegt, so dass beim Funktionsende die entsprechenden Daten gleich gefunden werden. - Das Betriebssystem
Wir haben erläutert, warum das Betriebssystem in jedem Adressraum einen bestimmten Bereich zugewiesen bekommt: Beim Auftreten von Interrupts kann vor dem Aufruf der Interrupt-Serviceroutine kein Wechsel des Adressraums erfolgen.
Platz für die Threads
- Threads
Alle Threads eines Tasks arbeiten im selben Adressraum. Das hat den Effekt, dass alle Threads auf die gemeinsamen globalen Daten zugreifen können und dass es auch mehrere Stacks im Adressraum gibt – für jeden Thread einen.
Bei einer 32-Bit-Architektur müssen also alle Daten mit 32 Adressbits adressiert werden können. Damit der Speicherbereich des Betriebssystems immer an derselben Stelle residiert, ist ein uniformes Layout des Adressraums für jeden Prozess gegeben (siehe Abbildung ).
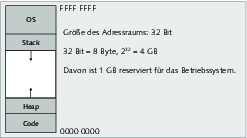
Unter Linux liegt das Speichersegment des Betriebssystems im obersten Gigabyte, was also drei Gigabyte Platz für die jeweilige Applikation lässt. [Fn. Windows beansprucht zum Beispiel die obersten zwei Gigabyte des Adressraums.] Der Stack wächst dabei nach unten und der Heap (der Speicherbereich für dynamischen Speicher – mehr dazu auf den nächsten Seiten) nach oben. So wird gewährleistet, dass beide genug Platz zum Wachsen haben.
Das Codesegment
Im untersten Teil des Adressraums ist dabei das Code- oder auch Textsegment eingelagert. Wenn das Befehlsregister des Prozessors nun immer auf den nächsten Befehl zeigt, so wird dessen Speicheradresse mit an Sicherheit grenzender Wahrscheinlichkeit in diesem Teil des Adressraums liegen. [Fn. Die Ausnahmefälle wie Buffer-Overflows, bei denen Hacker zum Beispiel Daten mittels Veränderung des Befehlsregisters zur Ausführung bringen, wollen wir hier nicht betrachten.]
ELF versus Maschinencode
Näher erläutern wollen wir in diesem Abschnitt noch den bereits angesprochenen Unterschied zwischen einer ausführbaren Datei und dem puren Maschinencode. Linux nutzt normalerweise [Fn. Es werden auch noch das veraltete a.out-Format sowie eventuell auch Java-Dateien direkt vom Kernel unterstützt.] das Executable and Linking Format – kurz ELF – für ausführbare Dateien.
Die Besonderheiten dieses Formats liegen in der Möglichkeit des dynamischen Linkens und Ladens, was bei der Nutzung dynamischer Bibliotheken [Fn. Unter Windows haben diese Dateien die charakteristische Endung .dll, unter Linux führen sie meist den Namensbestandteil .so.] von großer Bedeutung ist. Eine ELF-Datei ist dabei wie folgt aufgebaut:
- ELF-Header (mit Verweisen auf die anderen Teile der Datei)
- Programmkopf-Tabelle
- Sektionskopf-Tabelle
- Sektionen
- Segmente
Aufbau eines Programms
So ist zum Beispiel in der Sektionskopf-Tabelle verzeichnet, welche Sektionen wo im Speicher angelegt werden sollen, wie viel Platz diese benötigen und wo in der Datei die entsprechenden Daten gefunden werden können. Diese Daten können dann genutzt werden, um den Adressraum entsprechend zu initialisieren. Den genauen Aufbau einer solchen Datei kann man zum Beispiel mit dem Tool objdump auf der Kommandozeile studieren:
Listing 5.22 Ein Auszug des Sektionsheaders von /bin/ls
$ objdump -h /bin/ls
/bin/ls: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
...
9 .init 00000017 0804945c 0804945c 0000145c 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
...
11 .text 0000c880 08049a50 08049a50 00001a50 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
12 .fini 0000001b 080562d0 080562d0 0000e2d0 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .rodata 000039dc 08056300 08056300 0000e300 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
...
15 .data 000000e8 0805a000 0805a000 00012000 2**5
CONTENTS, ALLOC, LOAD, DATA
...
18 .ctors 00000008 0805a25c 0805a25c 0001225c 2**2
CONTENTS, ALLOC, LOAD, DATA
19 .dtors 00000008 0805a264 0805a264 00012264 2**2
CONTENTS, ALLOC, LOAD, DATA
...
22 .bss 000003b0 0805a400 0805a400 00012400 2**5
ALLOC
Wenn man sich den Aufbau eines vermeintlich einfachen Programms wie ls ansieht, bemerkt man die doch beachtliche Anzahl der vorhandenen Segmente. Außerdem sind offensichtlich nicht nur die Angaben über diverse Positionen im virtuellen Speicher oder in der Datei gesichert, sondern auch Informationen über Zugriffsrechte und andere Eigenschaften. Im Folgenden stellen wir kurz die wichtigsten Segmente der Datei noch einmal vor:
- .text
Im Textsegment finden sich die Maschinenbefehle, die später im untersten Teil des Adressraums abgelegt werden. Außerdem ist es wichtig zu erwähnen, dass für diese Seiten nur das Lesen (READONLY) erlaubt ist. Dies geschieht im Wesentlichen aus Sicherheitsgründen, da fehlerhafte Programme sonst durch einen entsprechend falsch gesetzten Pointer den Programmcode modifizieren könnten. Versucht aber ein Programm, nun auf die als nur lesbar markierten Speicherseiten schreibend zuzugreifen, wird das Programm in bekannter Weise mit einem Speicherzugriffsfehler abstürzen. - .data
In diesem Segment werden alle Daten und Variablen zusammengefasst, die bereits mit bestimmten Werten vorbelegt sind. Dieses Segment wird ebenfalls direkt in den Hauptspeicher eingelagert, ist jedoch mit Lese- und Schreibrechten ausgestattet. - .rodata
In diesem Segment stehen im Prinzip dieselben Daten wie im .data-Segment, diese sind jedoch schreibgeschützt. - .bss
In diesem Segment wird angegeben, wie viel Platz die uninitialisierten globalen Daten im Arbeitsspeicher benötigen werden. Uninitialisierte Daten haben keinen speziellen Wert, daher wird für sie auch kein Platz in der ausführbaren Datei und damit im Dateisystem belegt. Bei der Initialisierung des Adressraums werden die entsprechenden Felder dann mit Nullen gefüllt, daher reicht die Angabe des zu verbrauchenden Platzes in diesem Header vollkommen aus. - .ctors und .dtors
Wer objektorientiert programmiert, kennt Konstruktoren und je nach Sprache auch Destruktoren für seine Klassen. Diese speziellen Funktionen haben in ELF- Dateien auch ein eigenes Segment, das gegebenenfalls in den Codebereich des Adressraums eingelagert wird.
Die restlichen Segmente enthalten ähnliche Daten – teils Verweise auf real in der ausführbaren Datei vorliegende Daten und teils Metadaten. Betrachten wir aber nun die weiteren interessanten Teile des Adressraums.
Der Heap
Globale Daten
Den Heap haben wir bereits weitgehend erklärt: Er ist der Speicher für globale Daten. Fordert man per malloc() bzw. new neuen globalen Speicher an, werden die entsprechenden Bytes hier reserviert und später auch wieder freigegeben.
Da wir die wichtigsten Grundlagen bereits erläutert haben, wollen wir nun noch einmal kurz den Zusammenhang zum Paging darstellen. Der Kernel kann einem Prozess nur ganze Seiten zuweisen, was mitunter zur bereits angesprochenen internen Fragmentierung führt. Schließlich ist es unwahrscheinlich, dass man exakt so viel Platz angefordert hat, dass eine ganze Seite komplett gefüllt ist – selbst wenn man nur ein Byte braucht, muss im Extremfall dafür eine ganze 4-KB-Seite angefordert werden. Der verschenkte Platz ist dabei Verschnitt und wird als interne Fragmentierung bezeichnet. Würde man nun weitere Daten anfordern, würden diese natürlich auf der neuen, bisher nur mit einem Byte belegten Seite abgelegt werden – so lange, bis diese Seite voll ist.
Natürlich kann dieser reservierte Speicher auch im Prinzip beliebig wieder freigegeben werden, was wiederum Lücken in den dicht gepackten Speicher reißen und somit wieder zu interner Fragmentierung führen kann. Man braucht also eine Speicherverwaltung, die solche Lücken auch wieder füllt.
Entsprechend können Seiten auch ausgelagert werden, wenn ein Programm die angeforderten Speicherbereiche beziehungsweise die damit verknüpften Variablen längere Zeit nicht nutzt. In der Theorie unterscheidet man auch zwischen dem Working Set und dem Resident Set.
Das Working Set beschreibt alle in einem bestimmten Programmabschnitt benötigten Daten. Egal, ob ein Programm gerade in einer Schleife einen Zähler erhöht und im Schleifenrumpf ein Array bearbeitet, oder ob ein Grafikprogramm einen Filter auf ein bestimmtes Bild anwendet: immer wird ein Satz bestimmter Daten benötigt.
Working versus Resident Set
Die Seiten dieser Daten sollten natürlich im Hauptspeicher eingelagert sein; wäre dies nicht der Fall, hätte man mit vielen Page Faults zu kämpfen. Wenn das System so überlastet ist, dass es eigentlich nur noch mit dem Aus- und Einlagern von Speicherseiten beschäftigt ist, nennt man das Thrashing.
Die Menge aller aktuell im Hauptspeicher befindlichen Daten eines Prozesses bezeichnet man als Resident Set.
Um Thrashing zu vermeiden, sollte das Resident Set also zumindest immer das Working Set umfassen können. Dass möglichst keine Seiten aus dem aktuellen Working Set eines Prozesses auf die Festplatte ausgelagert werden, ist wiederum die Aufgabe des Swappers. [Fn. Natürlich könnte sich der vom Swapper verwendete Seitenalgorithmus auch richtig dämlich anstellen und immer die aktuellen Seiten des Working Sets zum Auslagern vorschlagen. Da ein Programm aber immer sein aktuelles Working Set im Hauptspeicher benötigt, um arbeiten zu können, würden daher viele Page Faults auftreten und das Betriebssystem zur Wiedereinlagerung der Seiten von der Festplatte in den Hauptspeicher veranlassen – von Performance könnte man also nicht mehr wirklich sprechen. Das Betriebssystem wäre vor allem mit sich selbst beschäftigt – eine Situation, die wir eigentlich vermeiden wollten.]
Der Stack
Der Stack speichert nun nicht die globalen, sondern mit den Funktionsaufrufen die jeweils lokalen Daten. Auch haben wir bereits erörtert, dass deswegen jeder Thread seinen eigenen Stack braucht. Anders gesagt: Diese Datenstruktur kann auch mehrfach im Adressraum vorkommen.
Stack und Prozessor
Im Normalfall eines Prozesses gibt es also erst einmal nur einen Stack, der an der oberen Grenze des für den Benutzer ansprechbaren Adressraums liegt und nach unten – dem Heap entgegen – wächst. Interessant ist weiterhin, inwieweit die Hardware, sprich der Prozessor, den Stack kennt und mit ihm arbeitet. Der Stack selbst liegt im virtuellen Speicherbereich des Prozesses und kann über Adressen angesprochen werden. Bei der Datenstruktur selbst interessiert dabei nur, was gerade aktuell, sprich »oben« [Fn. Da der Stack nach unten in die Richtung der kleiner werdenden Adressen wächst, müsste man eigentlich korrekterweise von »unten« sprechen. :-)], ist. Was liegt also näher, als ein spezielles Register des Prozessors immer zur aktuellen Spitze des Stacks zeigen zu lassen?
Dieser Stackpointer muss natürlich bei einem Kontextwechsel – also beim Umschalten zu einem anderen Task oder auch zu einem anderen Thread derselben Applikation – entsprechend gesetzt werden. Daher hat ein Prozess- beziehungsweise Thread-Kontrollblock auch immer einen Eintrag für den Stackpointer.
Des Weiteren gibt es auch noch einen im Prinzip eigentlich unnötigen Framepointer, also ein weiteres Prozessorregister, das das Ende des aktuellen Kontextes auf dem Stack anzeigt. Den Framepointer braucht man eigentlich nur zur Beschleunigung diverser Adressberechnungen, wenn eine Funktion zum Beispiel auf ihre Argumente zugreifen will. Aber schauen wir uns den Stack bei einem Funktionsaufruf einmal etwas genauer an.
In Abbildung finden wir alles wieder, was wir schon dem Stack zugeordnet haben: die Rücksprungadresse, lokale Variablen, die Parameter, mit denen die Funktion aufgerufen wurde, und außerdem noch Informationen zur Verwaltung der Datenstruktur selbst.
Diese Verwaltungsinformation ist, wie unschwer aus der Grafik zu erkennen ist, der alte Framepointer. Schließlich ist der Stackframe nicht immer gleich groß, denn Parameterzahl und lokale Variablen variieren von Funktion zu Funktion. Aus dem alten Framepointer kann schließlich der Zustand des Stacks vor dem Funktionsaufruf wiederhergestellt werden. Allerdings wird der Stack nie wirklich physisch gelöscht und mit Nullen überschrieben, was gewisse Auswirkungen auf die Sicherheit haben kann. Bösartige Programme könnten bestimmte Bibliotheksfunktionen aufrufen und hinterher den Inhalt der lokalen Variablen dieser Funktionen inspizieren – Daten, auf die sie eigentlich keinen Zugriff haben dürften.
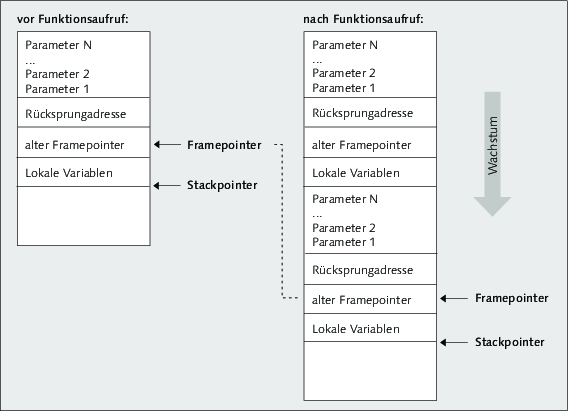
Abbildung 5.7 Der Stack vor und nach einem Funktionsaufruf
Einen interessanten Nebeneffekt hat der Stack auch bei bestimmten Thread-Implementierungen. Prinzipiell kann man Threads nämlich beim Scheduling anders behandeln als Prozesse oder Tasks, was bei puren Userlevel-Threads auch einleuchtet. Dort weiß der Kernel nichts von den Threads der Anwendung, da die Implementierung und die Umschaltung der Threads von einer besonderen Bibliothek im Userspace vorgenommen wird. Aber auch bei Kernellevel-Threads ist es angebracht, das Scheduling von dem der Prozesse und Tasks zu unterscheiden. Es ist nämlich nicht fair, wenn eine Anwendung mit zwei Threads doppelt so viel Rechenleistung bekommt wie ein vergleichbares Programm mit nur einem Thread.
Scheduling kooperativ
Da Anwendungsprogrammierer sowieso am besten wissen, wann ihre Threads laufen und nicht mehr laufen können, ist in vielen Thread-Bibliotheken ein sogenanntes kooperatives Scheduling implementiert. Im Gegensatz zum präemptiven Scheduling wird die Ausführung eines Threads dort nicht beim Ende einer Zeitscheibe unterbrochen. Im Gegenteil: Es gibt überhaupt keine Zeitscheiben. Ein Thread meldet sich einfach selbst, wenn er nicht mehr rechnen kann oder auf Ergebnisse eines anderen Threads warten muss. Dazu ruft er eine meist yield() genannte spezielle Funktion auf, die dann einen anderen Thread laufen lässt.
Der Thread ruft also eine Funktion auf und schreibt dabei verschiedenste Daten auf seinen Stack – unter anderem den Befehlszeiger. Der Thread merkt sich also mit anderen Worten selbst, wo er hinterher weitermachen muss. Das spart unserer yield()-Funktion viel Arbeit. Sie muss jetzt nur noch den nächsten zu bearbeitenden Thread auswählen und den Stack- und Framepointer des Prozessors auf dessen Stack zeigen lassen. Danach kann yield() einfach ein return ausführen und so zum Aufrufer zurückkehren. Der Rest geschieht quasi von allein, da nun der alte Framepointer zurückgesetzt und der Stack langsam abgebaut wird, wobei natürlich auch die Rücksprungadresse des neuen Threads ausgelesen wird. Der neue Thread macht also dort weiter, wo er beim letzten Mal aufgehört hat: nach einem Aufruf von yield(). Bei neuen Threads ist der Ablauf ebenso einfach: Hier muss die Thread-Bibliothek beziehungsweise der Kernel einfach nur den Stack so initialisieren, dass die Rücksprungadresse auf den ersten Befehl des neu zu startenden Threads zeigt – genial einfach und einfach genial.
Nur der Vollständigkeit halber sei an dieser Stelle noch erwähnt, dass kooperatives Scheduling von ganzen Applikationen – also von Prozessen und Tasks – so überhaupt nicht funktioniert: Jeder Programmierer würde nämlich sein Programm für das ultimativ wichtigste und die Offenbarung überhaupt halten; und warum sollte er dann freiwillig Rechenzeit freigeben? Außerdem könnte eine Endlosschleife in einer einzigen falsch programmierten Anwendung das ganze System zum Stillstand bringen. Fazit: Kooperatives Scheduling ist, obwohl für das Scheduling von Threads durchaus üblich und eine gute Lösung, für Prozesse und Tasks [Fn. Außer bei Echtzeitbetriebssystemen mit einer begrenzten Anzahl bestimmter Anwendungen.] ungeeignet.
Die in den letzten Abschnitten beschriebenen Komponenten der unteren 3 Gigabyte des Adressraums bilden den für das Benutzerprogramm theoretisch komplett nutzbaren Adressrahmen. Wenden wir uns nun dem letzten Gigabyte zu.
Das Betriebssystem
Immer erreichbar
Der Speicherbereich des Kernels befindet sich immer an der oberen Grenze des Adressraums und ist bei Linux ein Gigabyte groß. Der Kernel muss sich immer an derselben Stelle befinden, schließlich war die Interrupt-Behandlung der Grund dafür, einen besonderen Speicherbereich des Betriebssystems im Adressraum einer jeden Anwendung einzurichten. Tritt ein Interrupt auf, so geht der Kernel in den Ring 0 und will sofort zur Interrupt-Serviceroutine springen. Läge diese nun bei jedem Prozess an einer anderen Adresse, würde das ganze Prinzip nicht funktionieren.
Dieser Speicherbereich ist bekanntlich auch so geschützt, dass aus dem Usermode nicht auf die Kerndaten zugegriffen werden kann – ein Zugriff aus Ring 3 würde mit einem Speicherzugriffsfehler quittiert. Dabei ist nicht nur der Kernel-Code selbst schützenswert, sondern insbesondere auch dessen Daten. Der Kernel besitzt selbstverständlich eigene Datenstrukturen wie Prozess- oder Thread-Kontrollblöcke, ebenso wie einen eigenen Kernel-Stack.
Kernel- versus Prozess-Stack
Der Kernel-Stack wird vom Betriebssystem für die eigenen Funktionsaufrufe genutzt. Der Stack des Anwenderprogramms ist dafür aus mehreren Gründen nicht geeignet:
- Welcher Stack?
Bei einem Task mit mehreren Threads gibt es mehr als nur einen Stack im Adressrahmen des Prozesses. Das Betriebssystem müsste sich also auf einen Stack festlegen, was dann zu Problemen führen könnte, wenn zwischen den Threads umgeschaltet und somit der Stackpointer verändert wird. - Taskwechsel
Überhaupt ist das Problem des Taskwechsels nicht geklärt. Was passiert, wenn der Kernel zu einem neuen Task schalten will und daher den Adressraum umschaltet? Die Daten des alten Prozesses und damit der Stack wären nicht mehr adressierbar und damit einfach weg – und irgendwann vielleicht plötzlich wieder da. - Sicherheit
Der Benutzer hätte außerdem vollen Zugriff auf seinen Stack, da dieser in seinem Adressrahmen liegt. Mit etwas Glück könnte er vielleicht sensible Daten des Kernels auslesen, die als lokale Variablen einer Funktion auf dem Stack gespeichert waren und nicht explizit mit Nullen überschrieben wurden.
Das Betriebssystem braucht somit unbedingt seinen eigenen Stack. Beim Eintritt in den Kernel wird dann also unter anderem der Stackpointer so umgebogen, dass jetzt wirklich der Kernel-Stack benutzt werden kann.
Threads des Kernels
Obwohl ... einen Stack? Wir haben bereits Kernelmode-Threads vorgestellt, die Arbeiten des Kernels nebenläufig erledigen. Schließlich gibt es keinen Grund, streng einen Syscall nach dem anderen zu bearbeiten – stattdessen könnte man für jede Aktivität einen eigenen Kernelmode-Thread starten, der diese dann ausführt. Aber einzelne Threads brauchen eigentlich auch wieder jeder einen eigenen Stack.
Ein Wort noch zu den physischen Speicherseiten des Betriebssystems: Zwar ist in jedem Adressraum das oberste Gigabyte für den Kernel reserviert, aber die betreffenden virtuellen Seiten verweisen natürlich überall auf dieselben physischen Seiten, realisieren also eine Art Shared Memory.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.
 Ihre Meinung
Ihre Meinung




