


»Ach, der Mensch begnügt sich gern.
Nimmt die Schale für den Kern.«
– Albert Einstein (zugeschrieben)
5 Der Kernel
In diesem Kapitel wollen wir uns mit der Architektur eines Linux-Systems auseinandersetzen. Auch wenn das Kapitel »Der Kernel« [Fn. Die Bezeichnung Kernel steht für den Kern des Betriebssystems. Wenn man das Wort Betriebssystem streng definiert, also alle Anwenderprogramme etc. ausschließt, ist dieses gerade der Kernel. Das klingt kompliziert, wird aber bald klarer.] heißt, macht es wenig Sinn, hier jede einzelne Quelldatei des Linux-Kernels durchzusprechen. Stattdessen wollen wir Grundlagen der Systemarchitektur am Beispiel von Linux vorstellen, Probleme skizzieren und zentrale Zusammenhänge erläutern.
Dazu werden wir uns auf die Prinzipien konzentrieren, die Linux nutzt, um so zu funktionieren, wie es funktioniert. Natürlich wird dabei die eine oder andere konkrete Verbindung zum Quellcode hergestellt werden. Schließlich kann man bei Linux auf die Kernel-Quellen zugreifen und sich selbst von der Korrektheit der im Folgenden getroffenen Aussagen überzeugen.
Wider die Missverständnisse
Zum Aufbau und zur Ausrichtung dieses Kapitels hat uns folgende Erfahrung angeregt: Selbst Leute, die viel auf ihr Fachwissen halten, disqualifizieren sich regelmäßig durch Aussagen wie:
- »Warum programmiert man nicht endlich mal ein Betriebssystem in Java, das ist doch so genial objektorientiert?«
- »Benutzerprogramme haben keinen direkten Zugriff auf die Hardware; alles läuft über den Kernel.«
- »Benutzerprogramme können nicht auf den Kernel zugreifen, der ist geschützt.«
Solche Sätze sind entweder Halbwahrheiten oder sogar ausgemachter Unsinn. Nach diesem Kapitel sollten Sie diese und andere gängige Aussagen und Internet-Mythen in den richtigen Zusammenhang bringen können. Außerdem legt dieses Kapitel eine Grundlage für das Verständnis von Linux und damit für den Rest des Buches.
5.1 Grundlagen
Beginnen wir mit den wichtigsten Grundlagen, die Sie für das Verständnis des restlichen Kapitels benötigen werden. Viele dieser Informationen erscheinen Ihnen vielleicht selbstverständlich – und trotzdem empfehlen wir Ihnen, diesen Abschnitt sorgfältig zu lesen. Vielleicht wird doch noch der eine oder andere mutmaßlich bekannte Fakt etwas deutlicher oder lässt sich in den richtigen Kontext einordnen.
Fangen wir also beim Computer selbst an. Wenn man so davor sitzt, sieht man in erster Linie Dinge, die mit seiner Funktion herzlich wenig zu tun haben: Tastatur, Maus und Bildschirm. Diese Geräte braucht der Mensch, um irgendwie mit dem Rechner in Kontakt zu treten – das allgegenwärtige »Brain-Interface« ist ja schließlich noch Science-Fiction.
Der »Rechner«
Was in einem Computer rechnet (und nichts anderes tut das Ding, selbst wenn wir Texte schreiben oder im Netz surfen) [Fn. Jetzt dürfen Sie dreimal raten, wieso ein Computer auch oft Rechner genannt wird und was herauskommt, wenn man das englische Wort Computer ins Deutsche übersetzt.], ist der Prozessor.
5.1.1 Prozessor
Was gibt es über einen Prozessor zu sagen? In den meisten PCs steckt heutzutage ein zu Intels x86 kompatibler Prozessor. So ein auch CPU (Central Processing Unit) genannter Mikrochip hat im Wesentlichen drei Aufgaben:
- das Ausführen arithmetisch-logischer Operationen
- das Lesen und Schreiben von Daten im Arbeitsspeicher
- das Ausführen von Sprüngen im Programm
Der Maschinencode
Die letzte Aufgabe deutet schon an, dass ein Prozessor keine »gottgegebenen« Dinge tut. Vielmehr führt er ein in Maschinencode vorliegendes Programm aus.
Wie dieser Maschinencode nun aussieht, bestimmt der Befehlssatz des Prozessors. Mit anderen Worten gibt es nicht den Maschinencode, sondern viele Maschinencodes – so ziemlich für jeden Prozessor einen eigenen. Ausnahmen bilden nur Fabrikate wie die Prozessoren von AMD, die im Wesentlichen Intels x86-Befehlscode ausführen. Allerdings ist diese Einschränkung in Bezug auf die Kompatibilität nicht so erheblich, wie sie auf den ersten Blick scheint. Die meisten Hersteller moderner Prozessoren achten nämlich auf Abwärtskompatibilität, um mit den jeweiligen Vorgängermodellen noch kompatibel zu sein. [Fn. In letzter Konsequenz führte genau dieser Fakt – also die Abwärtskompatibilität der Befehlssätze neuer Prozessoren – zum unglaublichen Erfolg der Intel-Prozessoren.] Als klassisches Beispiel bietet sich hier der 16-Bit-Code des 80386-Prozessors von Intel an, der auch von aktuellen Quad-Core-Prozessoren noch unterstützt wird, obwohl diese intern völlig anders aufgebaut sind und demzufolge auch anders arbeiten.
Die meisten Benutzer stellen sich nun vor, dass ihre Programme in eine solche Maschinensprache übersetzt und vom Prozessor ausgeführt werden. Dies ist natürlich nur teilweise richtig: Das vom Prozessor ausgeführte Maschinencode-Programm, von dem eben gesprochen wurde, ist nur eine Folge von Maschinenbefehlen.
Das Multitasking
Damit man nun von mehreren »parallel« laufenden Programmen auf diese lose Folge von Befehlen abstrahieren kann, braucht man zum ersten Mal den Begriff des Betriebssystems – eine vertrauenswürdige Instanz, die die zu verarbeitenden Programme in kleine Häppchen aufteilt und diese dann nacheinander zur Ausführung bringt. Diese Multitasking genannte Vorgehensweise werden wir später noch ausführlich beleuchten; im Augenblick benötigen wir nur das Verständnis dieser für den Endbenutzer so wichtigen Aktionen.
5.1.2 Speicher
Bevor wir diesen Gedanken weiterdenken, soll kurz der Speicheraspekt betrachtet werden. Bisher haben wir nämlich nur gesagt, dass der Prozessor irgendwie rechnen und mit seiner Maschinensprache bezüglich dieser Berechnungen und der Flusskontrolle [Fn. Fluss bezeichnet hier den Ablauf des Programms. Dieser kann durch bedingte Sprünge variiert und kontrolliert werden.] gesteuert werden kann. Eine Frage ist aber noch offen: Woher kommen überhaupt die Ausgangswerte für die Berechnungen? Wir haben zwar bei der Beschreibung der Aufgaben eines Prozessors schon den ominösen Punkt »Das Lesen und Schreiben von Daten im Arbeitsspeicher« erwähnt, jedoch wollen wir diesen Fakt nun in den richtigen Zusammenhang setzen.
Die Register des Prozessors
Jeder Prozessor besitzt eine gewisse Anzahl von Registern, auf die im Maschinencode direkt zugegriffen werden kann. Diese Register sind hardwaremäßig auf dem Prozessorchip selbst integriert und können damit ohne Zeitverzug noch im selben Takt angesprochen werden.
Spezialregister
Der Platz auf dem Prozessor ist jedoch beschränkt und meistens werden einige Register auch für Spezialaufgaben gebraucht:
- Befehlsregister
Hierin ist die Adresse des nächsten auszuführenden Befehls gespeichert. Sprungbefehle können dieses Register verändern und so die Ausführung des Programms an einer anderen Stelle fortsetzen lassen. - Nullregister
Die meisten Prozessorarchitekturen besitzen ein spezielles schreibgeschütztes Register, aus dem man nur die Null lesen kann. Dies ist sehr praktisch, da man so diese wichtige Konstante direkt nutzen kann und nicht erst aus dem Speicher zu laden braucht. - Statusregister
Im Statusregister stehen bestimmte Bits für diverse Statusinformationen, beispielsweise dafür, ob das letzte Ergebnis null war oder ob bei der letzten Berechnung ein Über- oder Unterlauf stattgefunden hat.
Jedes dieser Register ist 32 Bit groß – und bei den neuen 64-Bit-Prozessoren natürlich entsprechend 64 Bit groß. Der Speicherplatz in den Registern ist also sehr stark begrenzt und höchstens für kleinste Programme ausreichend.
Der Hauptspeicher
Der Großteil des benötigten Platzes wird daher im Hauptspeicher zur Verfügung gestellt. Auch hier gab es früher aufgrund der damals noch üblichen Adressbreite von 32Bit eine Begrenzung, die dem Hauptspeicher eine maximale Größe von 4 Gigabyte auferlegte. Man greift ja auf die 1 Byte großen Speicherstellen über Adressen zu – und 232 Byte sind gerade 4 Gigabyte. Bei aktuellen 64-Bit-Betriebssystemen können dagegen theoretisch bis zu 264 Byte Speicher (entspricht 16 Exa-Byte RAM) adressiert werden.
Mit verschiedenen Maschinenbefehlen kann man nun auf diese Adressen zugreifen und die dort gespeicherten Bytes lesen oder schreiben. Ein interessanter Effekt bei der byteweisen Adressierung auf einem 32-Bit-basierten System sind die zustande kommenden Adressen: Beim Lesen ganzer Datenwörter [Fn. Ein »Wort« ist in diesem Zusammenhang 32 Bit lang.] wird man nämlich nur Vielfache von 4 als Adressen nutzen. Schließlich ist ein Byte 8 Bit lang, und 4 mal 8 Bit sind gerade 32 Bit.
Zugriff auf die Festplatte
Interessanterweise können Prozessor und damit indirekt auch Programme nicht direkt auf die Festplatte zugreifen. Stattdessen wird der DMA-Controller [Fn. DMA = Direct Memory Access] so programmiert, dass die betreffenden Datenblöcke in vorher festgelegte Bereiche des Hauptspeichers kopiert werden. Während der DMA-Controller die Daten von der sehr langsamen Festplatte in den im Vergleich zum Prozessor auch nicht gerade schnellen Hauptspeicher kopiert, kann die CPU nun weiterrechnen.
Da das eben noch ausgeführte Programm nun vielleicht vor dem Ende des Transfers nicht weiterlaufen kann, wird wahrscheinlich ein anderes Programm ausgeführt. Das Betriebssystem sollte also das nächste abzuarbeitende Programm heraussuchen und zur Ausführung bringen. Ist der Transfer dann abgeschlossen, kann der Prozessor die Daten von der Platte ganz normal aus dem Hauptspeicher lesen.
Im Übrigen wird so auch mit ausführbaren Programmen verfahren, die vor der Ausführung intern natürlich ebenfalls in den Hauptspeicher kopiert werden. Das Befehlsregister referenziert also den nächsten auszuführenden Befehl, indem es dessen Hauptspeicheradresse speichert.
Caches
Auch der Hauptspeicher ist also langsamer als der Prozessor. Konkret bedeutet das, dass der Takt ein anderer ist. In jedem Takt kann ein Arbeitsschritt erledigt werden, der beim Prozessor im Übrigen nicht unbedingt mit einem abgearbeiteten Befehl gleichzusetzen ist, sondern viel eher mit einem Arbeitsschritt beim Ausführen eines Befehls. [Fn. Tatsächlich nutzen fast alle aktuellen Prozessoren intern Pipelines oder andere Formen der Parallelisierung, um in einem Takt mehr als einen Befehl ausführen und so im Idealfall alle Komponenten des Chips auslasten zu können.] Um nun die Zugriffszeit auf häufig benutzte Datensätze und Variablen aus dem Hauptspeicher zu verkürzen, hat man Pufferspeicher, sogenannte Caches, eingeführt.
Transparenter Puffer
Diese Caches befinden sich entweder direkt auf dem Prozessor-Chip (L1-Cache) oder »direkt daneben«. Caches können je nach Bauart zwischen ein paar Kilobytes und wenigen Megabytes groß sein und werden bei meist vollem oder halbem Prozessortakt angesprochen. Die aus dem Hauptspeicher stammenden gepufferten Werte können so für den Prozessor transparent zwischengespeichert werden. Dieser nämlich greift weiterhin auf Adressen im Hauptspeicher zu – ob ein Cache dabei den Zugriff beschleunigt oder nicht, ist für den Prozessor nicht ersichtlich und auch unerheblich.
Zusammenfassung: Die Speicherhierarchie
Die Speicherpyramide
Der Computer besitzt also eine Speicherhierarchie, die absteigend mehr Speicherplatz bei längeren Zugriffszeiten bietet:
- Die Register des Prozessors
Die Register bieten einen direkten Zugriff bei vollem Prozessortakt. Neben speziellen Registern für festgelegte Aufgaben gibt es auch solche, die frei für den Programmierer benutzbar sind. - Der L1-Cache des Prozessors
Der Level-1-Cache sitzt direkt auf dem Prozessor und ist in der Regel 8 bis 256 Kilobyte groß. - Der L2-Cache
Je nach Modell kann der Level-2-Cache entweder auf dem Prozessor (on-die) oder direkt neben dem Prozessor auf einer anderen Platine untergebracht sein. Der L2-Cache ist normalerweise zwischen 512 und 2048 Kilobyte groß. - Der L3-Cache
Falls der L2-Cache auf dem Chip sitzt, kann durch einen zusätzlichen externen Level-3-Cache noch eine weitere Beschleunigung erreicht werden. - Der Hauptspeicher
Auf das RAM kann der Prozessor nur mit einer gewissen Zeitverzögerung zugreifen. Dafür kann dieser Speicher bei einer 32-Bit-Architektur bis zu 4 Gigabyte groß werden. - Die Festplatte oder anderer Hintergrundspeicher
Da Daten vom Hintergrundspeicher erst aufwendig magnetisch oder optisch gelesen werden müssen, bevor sie schließlich in den Hauptspeicher übertragen werden können, sind diese Speicher am langsamsten. Aber von einigen wenigen bis einigen Tausend Gigabyte sind hier die Speicherkapazitäten am größten. Zudem ist oft der Fall, dass zum Beispiel Festplatten noch eigene Caches im jeweiligen Controller besitzen, um auch selbst den Zugriff durch Zwischenspeicherung oder vorausschauendes Lesen etwas beschleunigen zu können. - Fehlende Daten
Es kann natürlich auch vorkommen, dass der Prozessor beziehungsweise ein Programm auf Daten wartet, die erst noch eingegeben werden müssen. Ob dies über die Tastatur, die Maus oder einen Scanner passiert, soll hier nicht weiter interessieren.

Abbildung 5.1 Die Speicherpyramide
Ein L1-Cache bietet also die kürzesten Zugriffszeiten und den geringsten Platz. Weiter unten bietet in der Regel die Festplatte den meisten Platz an, ist aber im Vergleich zum Cache oder auch zum Hauptspeicher extrem langsam.
5.1.3 Fairness und Schutz
Führen wir also nun unseren ersten Gedanken bezüglich der »parallelen« Ausführung mehrerer Programme logisch weiter. Wenn der Ablauf unterschiedlicher Programme quasiparallel, also abwechselnd in jeweils sehr kurzen Zeitabschnitten erfolgen soll, muss eine gewisse Fairness gewährleistet werden. Rein intuitiv denkt man da eigentlich sofort an zwei benötigte Zusicherungen:
- Gerechte Zeiteinteilung
Selbstverständlich darf jedes Programm nur einen kurzen Zeitabschnitt lang auf dem Prozessor rechnen. Mit anderen Worten: Es muss eine Möglichkeit für das Betriebssystem geben, ein laufendes Programm zu unterbrechen. Dies aber ist so nicht ohne Weiteres möglich: Schließlich läuft gerade das Programm und nicht das Betriebssystem. Es bleiben also zwei Möglichkeiten, um doch noch für das Scheduling, also das Umschalten zwischen zwei Benutzerprogrammen, zu sorgen: Entweder geben die Programme freiwillig wieder Rechenzeit ab, oder der Prozessor wird nach einer gewissen Zeitspanne in seiner aktuellen Berechnung unterbrochen. - Speicherschutz
Die einzelnen Programme sollen sich natürlich nicht gegenseitig beeinflussen. Das heißt vor allem, dass die Speicherbereiche der einzelnen Programme voreinander geschützt werden. Man erreicht dies durch das im Folgenden noch näher erläuterte Prinzip des virtuellen Speichers: Dies bedeutet für die Programme, dass sie nicht direkt auf die physischen Adressen des RAMs zugreifen können. Die Programme merken davon aber nichts – sie haben in ihren Augen den gesamten Speicherbereich für sich allein. In einer speziellen Hardwareeinheit, der MMU (Memory Management Unit), wird dann die virtuelle Adresse bei einem Speicherzugriff in die physische übersetzt.
Dieses Konzept hat auch den nützlichen Nebeneffekt, dass bei einer hohen Speicherauslastung – also wenn die gestarteten Programme zusammen mehr Speicher benötigen, als der PC RAM besitzt – einige Speicherbereiche auch auf die Festplatte ausgelagert werden können, ohne dass die betroffenen Programme davon etwas merken. Greifen diese dann auf die ausgelagerten Daten zu, wird der betroffene Speicherbereich von der Festplatte wieder ins RAM kopiert, und die MMU aktualisiert. Wird das vor dieser Aktion unterbrochene Programm des Benutzers schließlich fortgesetzt, kann es wieder ganz normal auf die Daten des angeforderten Speicherbereichs zugreifen.
Unterbrechen des Prozessors
Unterbrochen werden kann ein Prozessor dabei durch Interrupts. [Fn. Eigentlich kennt der Prozessor Interrupts und Exceptions. Die Literatur unterscheidet beide Begriffe gewöhnlich unter dem Aspekt, dass Interrupts asynchron auftreten und von anderen aktiven Elementen des Systems geschickt werden, während Exceptions schlichte Ausnahmen im Sinne eines aufgetretenen Fehlers sind und damit immer synchron auftreten. Für uns hier ist dieser feine Unterschied jedoch nicht relevant, daher möchten wir im Folgenden ausschließlich von Interrupts sprechen – auch wenn es sich bei manchen Ereignissen eigentlich um Exceptions handelt.] Über diese »Unterbrechungen« signalisieren zum Beispiel viele I/O-Geräte, dass sie angeforderte Daten nun bereitgestellt haben, oder ein Zeitgeber signalisiert den Ablauf einer bestimmten Zeitspanne. Wird solch ein Interrupt nun aktiv, unterbricht der Prozessor seine Ausführung und startet eine für diesen Interrupt spezielle Interrupt Service Routine. Diese Routine ist immer ein Teil des Betriebssystems und könnte nun zum Beispiel entscheiden, welches andere Programm als Nächstes laufen soll.
Virtueller Speicher
Außer dem Schutz des Speichers durch das Konzept des Virtual Memory gibt es noch die unter anderem vom x86-Standard unterstützten Berechtigungslevel (auch Ringe genannt). Diese vier Level oder Ringe schränken dabei den jeweils verfügbaren Befehlssatz für alle Programme ein, die im jeweiligen Ring beziehungsweise Berechtigungslevel laufen. Die gängigen Betriebssysteme wie Linux oder Windows nutzen dabei jeweils nur zwei der vier bei x86 verfügbaren Ringe: Im Ring 0 wird das Betriebssystem samt Treibern ausgeführt, während alle Benutzerprogramme im eingeschränktesten Ring 3 ablaufen. So schützt man das Betriebssystem vor den Anwenderprogrammen, während diese selbst durch virtuelle Adressräume voneinander getrennt sind.
5.1.4 Programmierung
So viel zu einer kurzen Einführung in den Prozessor und dessen Implikationen für unsere Systeme. Der nächste wichtige Punkt ist die Programmierung: Wie kann man einem Prozessor sagen, was er tun soll? Bisher haben wir nur über Maschinencode gesprochen, also über Befehle, die der Prozessor direkt versteht. Die binäre Codierung dieser Befehle wird dann mehr oder weniger direkt benutzt, um die Spannungswerte auf den entsprechenden Leitungen zu setzen.
Assembler
Nun möchte aber niemand mit Kolonnen von Nullen und Einsen hantieren, nicht einmal in der Betriebssystemprogrammierung. Aus diesem Grund wurde bereits in den Anfangsjahren der Informatik die Assembler-Sprache entworfen, in deren reinster Form ein Maschinenbefehl durch eine für einen Menschen lesbare Abkürzung – ein Mnemonic – repräsentiert wird.
Besser lesbar als Maschinencode
Neuere Assembler, also Programme, die einen in einer Assembler-Sprache geschriebenen Code in eine Maschinensprache übersetzen, bieten zusätzlich zu dieser 1:1-Übersetzung noch Makros als Zusammenfassung häufig benötigter Befehlskombinationen zur Vereinfachung an. Im Rahmen dieser 1:1-Zuordnung von Assembler zu Maschinencode ist natürlich auch die umgekehrte Richtung möglich, was man dann Disassemblieren nennt.
Betrachten wir das folgende Beispielprogramm, das auf einem MIPS-2000-System [Fn. Ja, es gibt mehr als nur Intel & Co ... ;-)] den Text »Hello World!« ausgeben würde:
Listing 5.1 »Hello World«-Beispielcode in MIPS-Assembler
.data # Datensegment
str: .asciiz "Hello World!\n" # String ablegen
.text # Codesegment
main: li $v0, 4 # 4 = Print_string
la $a0, str # Adresse des
# Strings übergeben
syscall # Systemfunktion
# aufrufen
li $v0, 10 # 10 = Quit
syscall # Programm beenden
Zunächst einmal legen wir nämlich die Zeichenfolge Hello World!, gefolgt von einem Zeichen für den Zeilenumbruch (n), im Hauptspeicher ab und bezeichnen diese Stelle für den späteren Gebrauch im Programm kurz mit str. Im Hauptprogramm (gekennzeichnet durch das Label main) laden wir eine bestimmte Nummer in ein Register des Prozessors und die Adresse der Zeichenkette in ein anderes Register.
Anschließend lösen wir durch den syscall-Befehl einen Interrupt aus, bei dessen Bearbeitung das Betriebssystem die im Register $v0 angegebene Nummer auswertet. Diese Nummer gibt nun an, was das Betriebssystem weiter tun soll: In unserem Fall soll es den Text auf dem Bildschirm ausgeben. Dazu holt es sich noch die Adresse der Zeichenkette aus dem zweiten Register und erledigt seine Arbeit. Zurück im Programm wollen wir dieses jetzt beenden, wozu die Nummer 10, gefolgt vom bekannten Interrupt, genügt.
Zugriff auf das Betriebssystem
In diesem Beispiel haben wir nun schon das große Mysterium gesehen: den Zugriff auf das Betriebssystem, den Kernel. Das Beispielprogramm tut nichts weiter, als diverse Register mit Werten zu füllen und ihm erlaubte Interrupts [Fn. Da Benutzerprogramme in einem eingeschränkten Berechtigungslevel laufen, können sie nicht wahllos alle Interrupts aufrufen.] aufzurufen.
Das Betriebssystem erledigt in diesem Beispiel die ganze Arbeit: Der Text wird aus dem Speicher ausgelesen, auf dem Bildschirm ausgegeben, und das Programm wird schließlich beendet. Diese Beendigung findet, wie leicht zu erkennen ist, nicht auf der Ebene des Prozessors statt, [Fn. Es gibt auch einen speziellen Befehl, um den Prozessor beim Herunterfahren des Systems richtig anzuhalten.] sondern es wird nur eine Nachricht an das Betriebssystem gesendet. Das System wusste unser Programm irgendwie zu starten, und es wird sich jetzt wohl auch um dessen Ende kümmern können.
Aber betrachten wir zunächst die definierten Einstiegspunkte in den Kernel: die Syscalls. In den meisten Büchern über Linux finden Sie bei der Erläuterung des Kernels ein Bild wie das folgende:
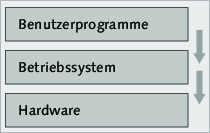
Abbildung 5.2 Ein nicht ganz korrektes Schema
Ein solches Bild soll verdeutlichen, dass Benutzerprogramme nicht direkt auf die Hardware zugreifen, sondern den Kernel für diese Aufgabe benutzen.
Diese Darstellung ist aber nicht vollkommen korrekt und lässt beim Leser ein falsches Bild entstehen. Im Assembler-Beispiel haben wir gesehen, dass ein Benutzerprogramm sehr wohl auf die Hardware zugreifen kann: Es kann zum Beispiel Daten aus dem Hauptspeicher in Register laden, alle möglichen arithmetischen und logischen Operationen ausführen sowie bestimmte Interrupts auslösen. Außerdem ist in der obigen Grafik der Zugriff auf den Kernel nicht visualisiert; man könnte also annehmen, dass dieser nach Belieben erfolgen kann. Jedoch ist das genaue Gegenteil der Fall.
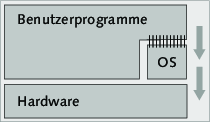
Abbildung 5.3 So sollte es sein.
Einstiegspunkte in den Kernel
In Abbildung wird schon eher deutlich, dass ein Benutzerprogramm nur über ausgewiesene Schnittstellen mit dem Kernel kommunizieren kann. Diese ausgewiesenen Systemaufrufe (engl. system calls, daher auch die Bezeichnung Syscalls) stellen einem Programm die Funktionalität des Betriebssystems zur Verfügung.
So kann man über Syscalls zum Beispiel, wie Sie gesehen haben, einen Text auf den Bildschirm schreiben oder das aktuelle Programm beenden. Entsprechend kann man natürlich Eingaben der Tastatur lesen und neue Programme starten. Außerdem kann man auf Dateien zugreifen, externe Geräte ansteuern oder die Rechte des Benutzers überprüfen.

Linux kennt knapp 300 Syscalls, die alle in der Datei include/asm-generic/unistd.h [Fn. Wenn Sie sich die Datei anschauen möchten, sollten Sie in Ihrer Distribution die Kernel"=Header"=Dateien installieren. Unter Ubuntu heisst das Paket bspw. linux-headers-VERSION, die Datei findet sich dann im Dateisystem unter /usr/src/linux-headers-VERSION-generic/ include/asm-generic/unistd. h.] Ihres Kernel-Sources verzeichnet sind.
Listing 5.2 Auszug aus der include/asm-generic/unistd.h von Linux
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
#define __NR_close 6
Dem exit-Call ist in diesem Fall die Nummer 1 und dem write-Call die Nummer 4 zugeordnet, also etwas andere Nummern als in unserem Beispiel für das MIPS-System. Auch muss unter Linux/x86 ein Syscall anders initialisiert werden als in unserem Beispiel. [Fn. Beim MIPS sehen Funktionsaufrufe anders aus als beim Intel/x86. Im Gegensatz zum MIPS müssen beim Intel-Prozessor nämlich alle Funktionsargumente auf den Stack geschoben werden, was aber für ein einführendes Beispiel nicht so übersichtlich gewesen wäre.] Das Prinzip ist jedoch gleich: Wir bereiten die Datenstruktur für den Syscall vor und bitten das Betriebssystem anschließend per Interrupt, unseren Wunsch zu bearbeiten.
Für ein Benutzerprogramm sind Syscalls die einzige Möglichkeit, direkt eine bestimmte Funktionalität des Kernels zu nutzen.
Natürlich lässt unsere Definition der Syscalls noch viele Fragen offen. Bisher wissen wir ja nur, dass wir die Daten irgendwie vorbereiten müssen, damit das Betriebssystem nach einem Interrupt diesen Systemaufruf verarbeiten kann. Was uns noch fehlt, ist die Verbindung zu den verschiedenen Hochsprachen, in denen ja fast alle Programme geschrieben werden.
Hochsprachen
Abstraktere Programmierung
Im Folgenden müssen wir zunächst klären, was eine Hochsprache überhaupt ist. Als Hochsprache bezeichnet man eine abstrakte höhere Programmiersprache, die es erlaubt, Programme problemorientierter und unabhängig von der Prozessorarchitektur zu schreiben. Bekannte und wichtige Hochsprachen sind zum Beispiel C/C++, Java oder auch PHP. Unser etwas kompliziert anmutendes MIPS-Beispiel sieht in C auch gleich viel einfacher aus:
Listing 5.3 »Hello, World« in C
#include <stdio.h>
main()
{
printf("Hello, World!\n");
}
In der ersten Zeile binden wir eine Datei ein, in der der einzige Befehl in unserem Programm definiert wird: printf(). Dieser Befehl gibt nun wie zu erwarten einen Text auf dem Bildschirm aus, in unserem Fall das bekannte »Hello, World!«.
Auch wenn dieses Beispiel schon einfacher zu lesen ist als der Assembler-Code, zeigt es doch noch nicht alle Möglichkeiten und Verbesserungen, die eine Hochsprache bietet. Abgesehen davon, dass Hochsprachen leicht zu lesen und zu erlernen sind, bieten sie nämlich komplexe Daten- und Kontrollstrukturen, die es so in Assembler nicht gibt. Außerdem ist eine automatische Syntax- und Typüberprüfung möglich.
Dumm ist nur, dass der Prozessor solch einen schön geschriebenen Text nicht versteht. Die Textdateien mit dem Quellcode, die man im Allgemeinen auch als Source bezeichnet, müssen erst in Assembler beziehungsweise gleich in Maschinensprache übersetzt werden. [Fn. Wie gesagt sind Maschinensprache und Assembler-Notation weitestgehend äquivalent. Eine Übersetzung in Assembler findet aber nur statt, wenn der Programmierer dies aus welchen Gründen auch immer explizit verlangt.] Eine solche Übersetzung (auch Kompilierung genannt) wird von einem Compiler vorgenommen. Wird ein Programm jedoch nicht nur einmal übersetzt, sondern während der Analyse der Quelldatei gleich Schritt für Schritt ausgeführt, so spricht man von interpretierten Sprachen und nennt das interpretierende Programm einen Interpreter. Die meisten Sprachen sind entweder pure Compiler- oder pure Interpreter-Sprachen (auch Skriptsprachen genannt).
Java!
Eine interessante Ausnahme von dieser Regel ist Java. Diese Sprache wurde von Sun Microsystems entwickelt, um möglichst portabel und objektorientiert Anwendungen schreiben zu können. Ganz davon abgesehen, dass jede Sprache portabel ist, sofern ein entsprechender Compiler/Interpreter und alle benötigten Bibliotheken – das sind Sammlungen von häufig benutztem Code, beispielsweise Funktionen, die den Zugriff auf eine Datenbank abstrahieren – auf der Zielplattform vorhanden sind, wollte Sun dies mit dem folgenden Konzept erreichen: Ein fertig geschriebenes Java-Programm wird zuerst von einem Compiler in einen Bytecode [Fn. Dieser Bytecode ist eine Art maschinenunabhängige Maschinensprache.] übersetzt, der schließlich zur Laufzeit interpretiert wird.
Mehr zur Programmierung unter Unix finden Sie in Kapitel 30.
[zB]Für unser kleines C-Beispiel reicht dagegen der einmalige Aufruf des GNU-C-Compilers, des gcc, aus:
Listing 5.4 Das Beispiel übersetzen und ausführen
$ gcc -o hello hello.c
$ ./hello
Hello, World!
$
In diesem Beispiel wird die Quelldatei hello.c mit unserem kleinen Beispielprogramm vom gcc in die ausführbare Datei hello übersetzt, die wir anschließend mit dem gewünschten Ergebnis ausführen. In diesem Beispiel haben Sie auch zum ersten Mal die Shell gesehen. Diese interaktive Kommandozeile wirkt auf viele Leute, die sich zum ersten Mal mit Unix auseinandersetzen, recht anachronistisch und überhaupt nicht komfortabel. Man möchte nur klicken müssen und am liebsten alles bunt haben. Sie werden jedoch spätestens nach unserem Shell-Kapitel dieses wertvolle und höchst effiziente Werkzeug nicht mehr missen wollen.
Mehr zur Shell finden Sie in den Kapiteln 7 bis 12.
Ausführbare Dateien
Die Datei hello ist zwar eine ausführbare Datei, enthält aber keinen reinen Maschinencode. Vielmehr wird unter Linux/BSD das ELF-Format für ausführbare Dateien genutzt. In diesem Format ist zum Beispiel noch angegeben, welche Bibliotheken benötigt oder welche Variablen im Speicher angelegt werden müssen. [Fn. Auch wenn Sie in Assembler programmieren, wird eine ausführbare Datei in einem solchen Format erzeugt – das Betriebssystem könnte sie sonst nicht starten.]
Doch zurück zu unseren Syscalls, die wir in den letzten Abschnitten etwas aus den Augen verloren haben. Die Frage, die wir uns zu Beginn stellten, war ja, ob und wie wir die Syscalls in unseren Hochsprachen nutzen können.
Libc: die Standardbibliothek
Unter C ist die Sache einfach: Die Standardbibliothek (libc) enthält entsprechende Funktionsdefinitionen. Nach außen hin kann man über die Datei unistd.h die von der Bibliothek exportierten Funktionssymbole einbinden und Syscalls auf diese Weise direkt nutzen. Intern werden die Syscalls wieder in Assembler geschrieben. Dies geschieht teils durch vollständig in Assembler geschriebene Quelldateien und teils auch durch Inline-Assembler. Die Programmiersprache C erlaubt es nämlich, zwischen den Anweisungen in der Hochsprache auch Assembler-Direktiven zu verwenden, die dann natürlich speziell gekennzeichnet werden.
Würde man das Beispielprogramm nicht mit printf schreiben, einem Befehl direkt aus dem C-Standard, sondern direkt mit dem Linux-Syscall write, so sähe es wie folgt aus:
Listing 5.5 Das C-Beispiel mit dem write-Syscall
#include <unistd.h>
int main() {
write(0, "Hello, World!\n", 13);
}
Hier nutzen wir den Syscall direkt statt indirekt wie über printf. Der Aufruf sieht auch schon etwas komplizierter aus, da mehr Argumente benötigt werden. Doch diese steigern nur die Flexibilität des Syscalls, der auch zum Schreiben in Dateien oder zum Senden von Daten über eine Netzwerkverbindung genutzt werden kann – wohlgemerkt: Im Endeffekt sind dies alles Aufgaben für den Kernel.
In welche Datei beziehungsweise auf welches Gerät geschrieben werden soll, gibt das erste Argument an. Dieser Deskriptor ist in unserem Fall die standardmäßig mit dem Wert »0« belegte normale Ausgabe: der Bildschirm. Danach folgen der zu schreibende Text sowie die letztendlich davon wirklich zu schreibende Anzahl Zeichen (eigentlich Bytes, aber ein Zeichen entspricht normalerweise einem Byte).
5.1.5 Benutzung
Nachdem wir bisher betrachtet haben, welche Implikationen sich aus der Hardware für das Betriebssystem ergeben, wollen wir im Folgenden die Eigenschaften des Systems aus Benutzersicht erläutern. Dazu betrachten wir zuerst ein beliebiges Betriebssystem beim Start.
Der Bootvorgang
Wenn man den PC anschaltet, bootet nach einer kurzen Initialisierung des BIOS das Betriebssystem. Für den Benutzer äußert sich dieser Vorgang vor allem in einer kurzen Wartezeit, bis er sich am System anmelden kann. In dieser Zeit werden alle Dienste initialisiert, die das System erbringen soll.
Die Initialisierung des Systems
Bei Arbeitsplatzrechnern gehört dazu in 90 % der Fälle eine grafische Oberfläche. Bei einer Vollinstallation eines Linux-Systems kann dazu auch schon einmal ein Webserver- oder Fileserver-Dienst gehören. Werden solche komplexen Dienste beim Booten gestartet, dauert ein Systemboot natürlich länger als bei puren Desktop-Systemen – insofern lässt sich ein Windows XP Home nicht mit einer Unix-Workstation vergleichen.
Für das System selbst heißt das, dass alle für die Arbeit benötigten Datenstrukturen zu initialisieren sind. Am Ende des Bootvorgangs wird dem Benutzer eine Schnittstelle angeboten, mit der er arbeiten kann.
Mehr zum Bootvorgang finden Sie in Kapitel 27, »Bootstrap und Shutdown«.
Im laufenden Betrieb
Im laufenden Betrieb möchten Benutzer ihre Programme starten, auf ein Netzwerk zugreifen oder spezielle Hardware wie Webcams nutzen. Das Betriebssystem hat nun die Aufgabe, diese Betriebsmittel zu verwalten. Der Zwiespalt ist dabei, dass den Benutzer so etwas nicht interessiert – schließlich sollen die Programme ausgeführt und auch die restlichen Wünsche des Anwenders möglichst mit der vollen Leistung des Systems erfüllt werden.
Würde der Kernel also zur Erfüllung dieser Aufgaben den halben Speicher oder 50 % der Rechenzeit benötigen, könnte er diesen indirekten Anforderungen nicht gerecht werden. Tatsächlich stellt es für jeden Betriebssystemprogrammierer die größte Herausforderung dar, den eigenen Ressourcenverbrauch möglichst gering zu halten und trotzdem alle Wünsche zu erfüllen.
Korrektheit
Ebenfalls zu diesem Themenkreis gehört die Korrektheit des Systems. Es soll seine Aufgabe nach Plan erfüllen – grundlose Abstürze, vollständige Systemausfälle beim Ausfall einzelner kleiner Komponenten oder nicht vorhersagbares Verhalten sind nicht zu akzeptieren. Daher wollen wir die Korrektheit im Folgenden als gegeben annehmen, auch wenn sie in der Realität nicht unbedingt selbstverständlich ist.
Das Herunterfahren
Das Herunterfahren dient zum Verlassen des Systems in einem korrekten Zustand, damit die Systemintegrität beim nächsten Start gewahrt bleibt. Vor allem beim Dateisystem zeigt sich die Wichtigkeit eines solchen Vorgehens: Puffer und Caches erhöhen die Performance beim Zugriff auf die Platte extrem, dreht man jedoch plötzlich den Strom ab, sind alle gepufferten und noch nicht auf die Platte zurückgeschriebenen Daten weg. Dabei wird das Dateisystem mit ziemlicher Sicherheit in einem inkonsistenten Zustand zurückgelassen, so dass es beim nächsten Zugriff sehr wahrscheinlich zu Problemen kommen wird.
Aber auch den Applikationen muss eine gewisse Zeit zum Beenden eingeräumt werden. Vielleicht sind temporäre Daten zu sichern oder andere Arbeiten noch korrekt zu beenden. Das Betriebssystem muss also eine Möglichkeit haben, den Anwendungen zu sagen: Jetzt beende dich bitte selbst – oder ich tue es.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.
 Ihre Meinung
Ihre Meinung




