

|
|
|
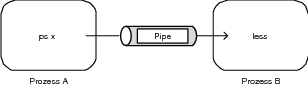
Intern (wenn man den Kernel betrachtet) ist ein FIFO (FIFO = First In First Out) tatsächlich nichts anderes als die Implementierung einer namenlosen Pipe. Der Systemaufruf mkfifo() bedeutet also nichts anderes, als dass eine Pipe als Filesystem-Objekt repräsentiert wird. Wer mittels pipe() eine Pipe erstellt, kreiert auch eine Datei wie mit mkfifo()! Diese sieht man zwar nicht, weil sie in einem Dateisystem versteckt ist, das man nicht mounten kann – aber wer in /proc/1234567/fd nachgesehen hat, sieht bei einigen »pipe:[1692]« mit pipe()-generierten Pipes. Ähnliches gilt übrigens auch für Sockets (TCP, auch PF_UNIX) (»socket:[456789]«). FIFOs werden wie erwartet mit z. B. /dev/initctl angezeigt (siehe /proc/1/fd/). PF_UNIX-Sockets werden ebenfalls als socket:[]-Objekt dargestellt, auch wenn diese eigentlich einen Dateinamen besitzen. Auf der Shell lässt sich ein FIFO folgendermaßen erstellen: $ mkfifo fifo1 Bei einem Blick ins aktuelle Arbeitsverzeichnis finden Sie das FIFO unter folgendem Eintrag: $ ls -l prw-r--r-- 1 tot users 0 2003–12–07 10:53 fifo1 Am p am Anfang erkennen Sie das FIFO. Sie könnten jetzt etwas in das FIFO schreiben: [tty1] $ echo Der erste Eintrag in das FIFO > fifo1 [tty2] $ echo Der zweite Eintrag in das FIFO > fifo1 Beide Dialogstationen blockieren im Augenblick und warten, bis die Daten im FIFO ausgelesen werden. Wir öffnen eine dritte Konsole und lesen ihn aus: [tty3] $ cat fifo1 Der zweite Eintrag in das FIFO Der erste Eintrag in das FIFO Natürlich müssen Sie auch die Zugriffsrechte für das FIFO vergeben, wer in dieses FIFO etwas schreiben und wer aus ihm lesen darf. FIFOs sind auch eine halbduplexe IPC, was bedeutet, dass auch bei FIFOs, wie schon bei namenlosen Pipes, kein mehrfaches Auslesen möglich ist. Benannte Pipes werden daher auch nur dort eingesetzt, wo eine »Einbahnstraße« gewünscht ist.
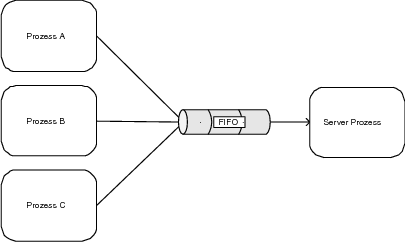
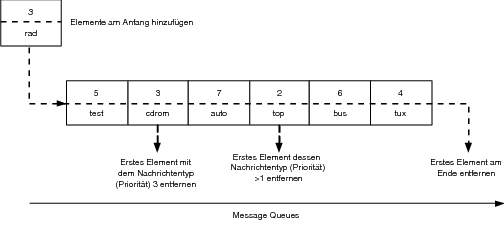
 9.1.3 Message Queue (Nachrichtenspeicher)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Abbildung 9.3 Prinzip der Message Queue |
Semaphore sind Zugriffsvariablen, auf die nur mit bestimmten Funktionen zugegriffen werden kann. Ein Semaphor kann mehrere Werte annehmen und ist nicht von binärer Natur. Mit den Prozessen können Sie ein Semaphor abfragen und überprüfen, ob dieses einen bestimmten Wert hat. Es ist auch möglich, dass mit einer Funktion auf mehrere Semaphore gleichzeitig zugegriffen wird. Gewöhnlich verwendet man Semaphore zur Synchronisation beim Zugriff auf kritische Betriebsmittel/Datenstrukturen oder einen kritischen Codeausschnitt. Wenn z. B. der gemeinsame Speicher (Shared Memory) von zwei oder mehreren Prozessen gleichzeitig verwendet wird, muss verhindert werden, dass diese gleichzeitig schreiben oder dass ein Prozess liest, während ein anderer zur gleichen Zeit schreibt.
Das Prinzip ist recht einfach. Will man mit einem Semaphor einen bestimmten Abschnitt schützen, wird ein vorhandener Zähler getestet, ob der Wert größer als 0 ist, und anschließend dekrementiert. Ist der Wert nicht größer als 0, wird der Prozess in einen Wartezustand versetzt, da sich scheinbar ein anderer Prozess gerade in diesem kritischen Codeausschnitt befindet. Wenn ein Prozess einen kritischen Codebereich verlassen will, muss dieser wiederum den Zähler inkrementieren, damit der kritische Bereich für andere Prozesse wieder zur Verfügung steht.
Mit dem Shared-Memory-Mechanismus können Sie mit mehreren Prozessen auf einen gemeinsamen Datenspeicherbereich zugreifen. Um dies zu realisieren, muss zuerst ein Prozess diesen gemeinsamen Datenspeicher anlegen. Anschließend müssen alle anderen Prozesse, die ebenfalls darauf zugreifen sollen, mit diesem Datenspeicher bekannt gemacht werden. Dies geschieht, indem der Speicherbereich im Adressraum der entsprechenden Prozesse eingefügt wird. Ebenfalls muss hierbei den Prozessen mitgeteilt werden, wie diese auf den Speicherbereich zugreifen können (lesend/schreibend). Wurde all dies erledigt, kann der Datenspeicherbereich wie ein gewöhnlicher Speicherbereich verwendet werden. Da die Struktur der Speicherverwaltungseinheit von der Kernelkonfiguration abhängig ist, so dass die Größe und Aufteilung variieren kann, sollte man vorsichtig sein, wenn man einen allzu großen gemeinsamen Speicher verwendet.
Leider wurde mit dem Shared Memory IPC keine explizite Synchronisation zur Verfügung gestellt, weshalb man diese Kontrolle selbst noch mit z. B. Sperren oder Semaphoren herstellen muss.
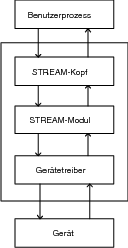
STREAMS (nicht zu verwechseln mit den Streams der Standard-E/A-Funktionen) wurden ursprünglich unter UNIX als Teil von als Network Support Services bezeichneten Funktionen eingeführt. Da sich STREAMS aber auch hervorragend zur Kommunikation zwischen Prozessen einsetzen lassen, sollten diese nicht unerwähnt bleiben. Ein Stream ist eine Art Treiber im Kernel, der allerdings keinem physikalischen Gerät zugeordnet wird. Es handelt sich dabei um eine Schnittstelle zwischen der Applikation und dem Betriebssystem zum Austausch von Daten. Die Datenströme stehen bei den Streams in beiden Richtungen zur Verfügung und sind somit Vollduplex. Auf STREAMS können neben den dafür implementierten Funktionen putmsg, getmsg und poll auch die Systemfunktionen open, close, read, write und ioctl verwendet werden. Ein STREAM-Mechanismus wird aus folgenden Komponenten aufgebaut:
| STREAM-Kopf – Hier werden die Systemaufrufe der Message bzw. der Messages in Byte-Streams und Returnwerte verarbeitet. Ein Message-STREAM kann Daten oder/und Statusinformationen enthalten. Der Kopf beinhaltet wie jede STREAM-Komponente eine Lese- und eine Schreib-Queue. |
| STREAM-Module – STREAM -Module sind optional. Es gibt eine Menge vorhandener Module, deren Aufgabe es u. a. sein kann, Transformationen der Nachrichten durchzuführen. Eingetragen werden die Module mit der Funktion ioctl(). Natürlich können (fast) beliebig viele Steuermodule eingetragen werden – wobei die Eintragung eines neuen Moduls nach dem Stack-Prinzip vorgeht. |
| STREAM-End – Besteht aus Gerätetreibern, was ein Gerätetreiber sein kann, ein Pseudotreiber, ein Terminalgerätetreiber oder ein Multiplexer. |
|
Abbildung 9.4 Kommunikationsmodell eines STREAMS |
Die STREAMS werden allerdings im Buch nicht behandelt.
Da die Netzwerkprogrammierung ein eigenes Kapitel erhält, sei das Socket hier nur kurz der Vollständigkeit halber erwähnt. Sockets wurden im Berkeley-UNIX-System (BSD) als Kommunikation zwischen verschiedenen Rechnern über ein Netzwerk eingeführt. Allerdings ist es mit den Sockets ebenso wie mit STREAMS möglich, eine Kommunikation zwischen Prozessen auf demselben Rechner auszuführen. Sockets können zur Kommunikation verschiedenste Protokolle benutzen, z. B. TCP/IP, UDP/IP oder UNIX Domain Sockets.
Eine recht primitive Form der IPC sind so genannte Lock Files (Sperrdateien), nicht zu verwechseln mit den Dateisperren (Record Locking). Dabei werden mehrere Prozesse mithilfe einer einfachen (Sperr-)Datei synchronisiert. Es wird praktisch eine Datei (meist im Verzeichnis /tmp) angelegt, worauf ein Prozess nur Schreibrechte hat. Die Synchronisation erfolgt jetzt durch einen anderen Prozess, der ebenfalls versucht, dieselbe Datei mit Schreibrechten anzulegen. Schlägt dieser Versuch fehl, existiert gerade eine entsprechende Datei. Dieses Fehlschlagen stellt praktisch die Sperre für den Prozess dar. Jetzt wartet der abgewiesene Prozess eine gewisse Zeit (meistens mit einem simplen sleep-Aufruf), bevor dieser erneut versucht, eine Datei mit entsprechenden Namen und mit Schreibrechten anzulegen. Die Freigabe dieser Sperre erfolgt dann durch den entsprechenden Prozess, der diese Datei erzeugt hat, über das Freigeben der Sperrdatei mit unlink().
So toll sich dies in der Theorie anhören mag, in der Praxis ist diese Form der IPC nur bedingt tauglich. Zum einen ist das Problem, sobald der Superuser hier mitspielen will, funktioniert die Synchronisation nicht mehr, da dieser immer schreiben darf. Und zum anderen wird hier mit dem aktiven Warten durch das Verschwenden von Prozessorzyklen (mit z. B. sleep()) nicht garantiert, welcher Prozess als nächster Zugriff auf die Sperrdatei hat. So kann es passieren, dass ein Prozess eventuell nie zum Zuge kommt.
Ebenso wie mit den eben vorgestellten Sperrdateien kann man auch mit den Dateisperren eine IPC einrichten. Auf die Dateisperren (Record Locking) wurde bereits eingegangen, weshalb das Thema hier nur kurz angerissen wird.
Man unterscheidet generell zwischen Pflichtsperren (Mandatory Locks) und Kooperationssperren (Advisory Locks). Bei den Pflichtsperren werden die Zugriffsrechte einer Datei so gesetzt, dass hierbei jeder read()- und write()-Systemaufruf prüfen muss, ob dieser unter den gegenwärtig gesetzten Sperren seinen lesenden oder schreibenden Zugriff durchführen kann. Dieser Vorgang verlangsamt logischerweise den Zugriff.
Mit den Kooperationssperren hingegen verwendet man eine Funktionsbibliothek mit Zugriffsfunktionen, die Ihnen z. B. Informationen zu einer Sperre liefern und/oder den Zugriff auf gemeinsame Datenbestände »regeln«. Im Wesentlichen werden diese Sperren mit dem Systemaufruf fcntl() oder der Bibliotheksfunktion lockf() geregelt. Beide Funktionen wurden bereits in Kapitel 2 erwähnt und z. T. verwendet.
Zwar ist diese Form der IPC immer noch besser als die Sperrdateien, aber auch hierbei gibt es einige Nachteile zu beklagen. Zum einen sind die Sperrarten wenig genormt – POSIX z. B. kennt keine Mandatory Locks. Des Weiteren funktionieren die Sperren nicht bei open()- und unlink()-Aufrufen. Und das Schlimmste: Ist ein Anwender nicht gut gelaunt, kann dieser mit Absicht durch Setzen und Halten einer Lesesperre auf die komplette Datei den schreibenden Zugriff aller anderen Anwender blockieren.
| << zurück |
|
||||||||||||
|
||||||||||||
|
||||||||||||
Copyright © Rheinwerk Verlag GmbH 2006
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich
ausdrucken. Ansonsten unterliegt das Openbook denselben Bestimmungen,
wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist
urheberrechtlich geschützt.
Alle Rechte vorbehalten einschließlich der
Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und
Verarbeitung in elektronischen Systemen.


 bestellen
bestellen



