


26.3 Vom Prozess zum Thread 
Ein Prozess ist das, was Sie bei den bisherigen Beispielen des Buches immer erstellt haben – also ein Programm bei seiner Ausführung. Diesem Programm steht zum Zeitpunkt seiner Ausführung die komplette Verwaltungseinheit des Betriebssystems zur Verfügung, als wäre es das einzige Programm, das ausgeführt wird.
Zum Zeitpunkt der Ausführung erhält ein Prozess somit die volle Aufmerksamkeit der CPU. Eine solche alleinige Verfügbarkeit ist natürlich bei einem Multitasking-Betriebssystem zeitlich begrenzt. Üblicherweise laufen auf einem Betriebssystem mehrere Prozesse »gleichzeitig« ab. Auch wenn Sie selbst noch kein Programm gestartet haben, laufen bereits viele Dienste im Hintergrund ab (unter Linux/Unix werden diese auch als Dämonprozesse bezeichnet). Egal welches Programm Sie nun ausführen, jede Anwendung bekommt eine gewisse Rechenzeit der CPU zur Verfügung gestellt, bevor die CPU die Rechenzeit einem anderen Prozess widmet (siehe Abbildung 26.1).
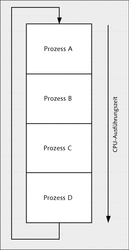
Abbildung 26.1 Prozesse werden Task für Task abgearbeitet.
Mit dieser Technik, dem Multitasking, hat es den Anschein, dass alle Prozesse quasi gleichzeitig ablaufen – was natürlich nicht möglich ist, da pro CPU immer nur ein Task ausgeführt werden kann.
Im ersten Moment besteht vorerst gar kein Unterschied zwischen einem Prozess und einem Thread, denn letztendlich besteht ein Prozess mindestens aus einem Thread. Ferner endet ein Prozess, wenn sich alle Threads beenden. Somit ist der eine Prozess (dieser eine Prozess ist der erste Thread, auch »Main Thread« bzw. »Haupt-Thread« genannt) verantwortlich für die gleichzeitige Ausführung mehrerer Threads – da doch Threads auch nur innerhalb eines Prozesses ausgeführt werden. Der gravierende Unterschied zwischen den Threads und den Prozessen besteht darin, dass Threads unabhängige Befehlsfolgen innerhalb eines Prozesses sind. Man könnte auch sagen, Threads sind in einem Prozess gefangen oder verkapselt – im goldenen Käfig eingeschlossen (siehe Abbildung 26.2).
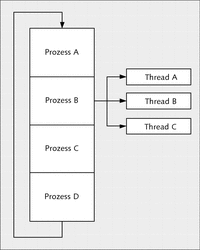
Abbildung 26.2 Ein Prozess (Main-Thread) startet mehrere (Unter-)Threads.
Prozesse werden gegenüber Threads immer als schwergewichtig dargestellt. Das kommt daher, dass bei der Erstellung eines Prozesses der komplette Namensraum dupliziert werden muss. Diesen Aufwand spart man bei der Verwendung von Threads, da diese in einem gemeinsamen Adressraum ablaufen. Somit stehen den einzelnen Threads dasselbe Codesegment, Datensegment, der Heap und alle anderen Zustandsdaten, die ein »gewöhnlicher« Prozess besitzt, zur Verfügung – was somit auch die Arbeit beim Austausch von Daten und bei der Kommunikation untereinander erheblich erleichtert. Weil aber kein Speicherschutzmechanismus unter den Threads vorhanden ist, bedeutet dies auch, dass ein Thread, wenn er abstürzt, alle anderen Threads mit abstürzen lässt. Einen Vergleich des Verwaltungsaufwandes zwischen den Threads und Prozessen finden Sie in den Abbildungen 26.3 und 26.4.
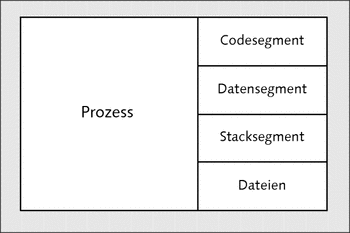
Abbildung 26.3 Das beinhaltet jeder einzelne Prozess.
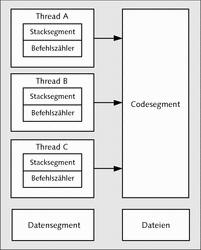
Abbildung 26.4 Threads hingegen teilen sich (abgesehen vom Stacksegment und dem Befehlszähler) die Ressourcen.
In Abbildung 26.4 lässt sich schön erkennen, dass sich Threads den Adressraum teilen. Allerdings macht gerade dies die Threads etwas aufwendiger zu programmieren, denn die Threads teilen sich hierbei die globalen Variablen, geöffneten Dateien (beispielsweise Filedeskriptor) – eben alle globalen Ressourcen außerhalb eines Threads –, weshalb hierbei gewisse Synchronisationsmechanismen nötig sind.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



