


34.3 Gültigkeitsprüfung im DataSet
34.3.1 Dem DataSet Schemainformationen übergeben
Die Daten in einer DataTable können editiert werden. Sie können auch neue Datenzeilen hinzufügen oder vorhandene löschen. Wie das gemacht wird, werden Sie noch später in diesem Kapitel sehen. Unabhängig davon, welche Änderungen Sie vorgenommen haben, betreffen diese zunächst nur das DataSet. Die Produktionsdatenbank weiß davon nichts. Erst zu einem späteren Zeitpunkt werden die Aktualisierungen mit der Update-Methode des SqlDataAdapters zur Originaldatenbank übermittelt und dort gespeichert.
Viele Spalten der Tabelle in der Datenbank unterliegen Gültigkeitsregeln: Beispielsweise lassen einige nur eine maximale Zeichenanzahl zu, andere schreiben einen eindeutigen Eintrag innerhalb der Datensätze der Tabelle vor oder lassen keinen NULL-Wert zu. Eine DataTable, die wir mit Fill füllen, ist hingegen sehr »dumm«. Sie enthält zwar alle angeforderten Daten, weiß aber nichts von den Gültigkeitsregeln, die in der Datenbank festgelegt sind. Die Folge ist, dass in der Anwendung die Daten beliebig verändert werden können, ohne dass eine Überprüfung erfolgt. Der anschließende Versuch, die Änderungen in die Datenbank zu schreiben, wird jedoch scheitern, weil die Datenbank vor der endgültigen Aktualisierung zuerst die Änderungen mit den Gültigkeitsregeln vergleicht und eine Verletzung feststellt. Es kommt zu einer Ausnahme.
Im folgenden Beispielprogramm können Sie dies ausprobieren. Hierzu dient uns wieder die schon reichlich bekannte Tabelle Products der Datenbank Northwind. Das Programm ermöglicht es, den Bezeichner des ersten Artikels, es handelt sich dabei um Chai, zu ändern. Dazu werden Sie an der Konsole aufgefordert. Die Änderung wird zuerst in das DataSet geschrieben, anschließend wird die Originaldatenbank aktualisiert. Die Aktualisierungslogik mit der Methode Update des SqlDataAdapters sowie das zuvor erzeugte Objekt vom Typ SqlCommandBuilder sollen uns an dieser Stelle nicht interessieren.
// Beispiel: ..\Kapitel 34\FehlgeschlageneAktualisierung
class Program {
static void Main(string[] args) {
SqlConnection con = new SqlConnection();
con.ConnectionString = "...";
SqlCommand cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "SELECT ProductID, ProductName, UnitsInStock " +
"FROM Products";
DataSet ds = new DataSet();
SqlDataAdapter da = new SqlDataAdapter(cmd);
da.Fill(ds);
// Ausgabe der Ergebnisliste
Console.WriteLine("Abfrageergebnis:\n");
foreach (DataRow row in ds.Tables[0].Rows)
Console.WriteLine("{0,-35}{1}", row[0], row[1]);
Console.WriteLine(new string('-',60));
// Datenänderung
Console.Write("Namensänderung von 'Chai': ");
ds.Tables[0].Rows[0]["ProductName"] = Console.ReadLine();
SqlCommandBuilder cmb = new SqlCommandBuilder(da);
da.Update(ds);
Console.ReadLine();
}
}
Listing 34.4 Aktualisierung einer Datenzeile
Beachten Sie bitte, dass das Feld ProductName in der Datenbank auf eine Maximallänge von 40 Zeichen begrenzt ist. Ändern Sie den Artikelbezeichner innerhalb dieser Grenzen, wird die Datenbank die Änderung annehmen. Sollten Sie jedoch gegen die Beschränkung verstoßen, wird eine Ausnahme vom Typ SqlException ausgelöst, die von der Datenbank initiiert wird. Die geänderte Spalte im DataSet hatte keinen Einwand gegen die vorgenommene Änderung, denn bekanntlich sind die Daten im DataSet »dumm«. Der Versuch der endgültigen Aktualisierung scheitert jedoch an der Feldlängenbegrenzung in der Datenbank.
Obwohl aufgrund der Einschränkungen in der Datenbank sichergestellt ist, dass keine unzulässigen Daten geschrieben werden, stellt der gezeigte Ansatz keine gute Lösung dar. Denken Sie nur an eine stark frequentierte Datenbank im Internet. Jeder Anwender, der unzulässige Daten übermittelt, würde von der Datenbank in Form einer Ausnahme über das Scheitern der Aktualisierung informiert. Der Datenfluss von der Datenbank zum Anwender würde nicht nur das Netz belasten, sondern darüber hinaus auch die Performance der Anwendung verschlechtern.
Besser ist es, wenn bereits das DataSet die Gültigkeitsregeln kennt. Das hat zur Folge, dass Änderungen überprüft werden, bevor sie der Datenbank übermittelt werden. In unserem Beispiel hätte dann das DataSet eine Änderung des Artikelbezeichners abgelehnt, ohne dabei die Datenbank zu kontaktieren.
Um eine Gültigkeitsüberprüfung vom DataSet vornehmen zu lassen, werden Schemainformationen benötigt, die auf drei verschiedenen Wegen einer Anwendung bereitgestellt werden können:
- Die Schemainformationen werden mittels Programmcode für alle betreffenden Tabellen und Spalten explizit festgelegt.
- Die Schemainformationen werden von der Datenbank mit dem SqlDataAdapter bezogen. Dazu bieten sich die Methode FillSchema sowie die Eigenschaft MissingSchemaAction an.
- Die Schemainformationen werden aus einer XML-Schemadatei bezogen.
Schemainformationen beschreiben Datenüberprüfungsmechanismen, die sogenannten Einschränkungen (Constraints). Dabei handelt es sich um Einschränkungen auf Spalten- und Tabellenebene, die auch von einer DataTable und einer DataColumn unterstützt werden. Ehe ich Ihnen zeige, wie Sie ein DataSet davon überzeugen, eine Gültigkeitsüberprüfung vorzunehmen, sollten wir uns ansehen, wie die Beschränkungen von ADO.NET realisiert werden.
34.3.2 Eigenschaften einer DataColumn, die der Gültigkeitsprüfung dienen
Um die in der Anwendung eingegebenen Daten mittels Programmcode zu überprüfen, veröffentlicht das DataColumn-Objekt, mit dem eine Spalte der Abfrage beschrieben wird, einige Eigenschaften.
| Eigenschaft | Beschreibung |
|
AllowDBNull |
Mit dieser Eigenschaft legen Sie fest, ob eine Spalte den Wert NULL akzeptiert oder nicht. |
|
MaxLength |
Mit dieser Eigenschaft legen Sie die Länge einer Zeichenfolge in einer Spalte fest. |
|
ReadOnly |
Sollen die Daten einer Spalte schreibgeschützt sein, setzen Sie diese Eigenschaft für die betreffende Spalte auf true. |
|
Unique |
Mit dieser Eigenschaft geben Sie an, ob die Werte in einer Spalte eindeutig sein müssen. Ist diese Eigenschaft einer Spalte auf true gesetzt, prüft ADO.NET die Werte in jeder Zeile dieser Tabelle, wenn Sie in einer Datenzeile den Wert einer UNIQUE-Spalte ändern oder einen neuen Datensatz hinzufügen. Wird gegen die Regel verstoßen, wird die Ausnahme ConstraintException ausgelöst. |
34.3.3 Die Constraints-Klassen einer »DataTable«
Die folgenden beiden Klassen beschreiben Einschränkungen einer DataTable:
Beide Klassen sind von der gleichen Basisklasse Constraint abgeleitet. Da eine DataTable mehrere Einschränkungen beschreiben kann, werden alle Constraint-Objekte in einer Auflistung (Typ: ConstraintCollection) verwaltet. Die Eigenschaft Constraint der DataTable liefert die Referenz auf diese Collection.
Die Klasse »UniqueConstraint«
Ein UniqueConstraint-Objekt wird automatisch angelegt, wenn die Eigenschaft Unique einer Spalte auf true gesetzt wird. Gleichzeitig wird das Objekt der ConstraintCollection hinzugefügt. Sie können ein UniqueConstraint-Objekt natürlich auch per Code erzeugen und dessen Eigenschaft Columns der Spalte übergeben, auf der die Einschränkung gesetzt wird. Das Setzen der Eigenschaft Unique einer Spalte ist aber einfacher. Trotzdem kann das explizite Erzeugen sinnvoll sein. Das ist der Fall, wenn Sie sicherstellen müssen, dass die Kombination von Werten aus mehreren Spalten eindeutig ist.
Die Klasse »ForeignKeyConstraint«
Mit einem ForeignKeyConstraint-Objekt können Sie festlegen, wie sich eine Beziehung zwischen Tabellen bezüglich Datenänderungen auswirken soll. In der Tabelle Products der Northwind-Datenbank muss die Spalte CategoryID einen Wert enthalten, der in der Tabelle Categories enthalten ist. Der Spalte CategoryID wird dazu ein ForeignKeyConstraint-Objekt zugeordnet. Allerdings müssen Sie dieses nicht explizit erzeugen. Wenn Sie im DataSet eine Beziehung zwischen zwei Tabellen einrichten, wird automatisch ein ForeignKeyConstraint-Objekt erzeugt. Wir werden auf das Thema der Einrichtung einer Beziehung zwischen zwei Tabellen später noch einmal zurückkommen.
Primärschlüsselfelder
Primärschlüssel werden in der DataTable definiert. Die entsprechende Eigenschaft lautet PrimaryKey. Dass ein Primärschlüssel nicht die Eigenschaft einer DataColumn besitzt, liegt daran, dass viele Tabellen mehrere Spalten zu einem gemeinsamen Primärschlüssel kombinieren. Die PrimaryKey-Eigenschaft der DataTable beschreibt deshalb auch ein Array von DataColumn-Objekten. Beim Festlegen der PrimaryKey-Eigenschaft wird ein UniqueConstraint-Objekt erzeugt, um die Primärschlüsseleinschränkung durchzusetzen.
34.3.4 Das Schema mit Programmcode erzeugen
Verhältnismäßig aufwendig ist die Bereitstellung eines Schemas. Mit den Eigenschaften AllowDBNull, MaxLength und Unique einer DataColumn sowie PrimaryKey einer DataTable können Sie Datenmechanismen implementieren. Mit ReadOnly=true haben Sie zudem die Möglichkeit, gültige Daten vor einer Veränderung durch den Benutzer zu schützen.
Auch im folgenden Beispiel soll der Artikelbezeichner eines Artikels der Tabelle Products geändert werden. Ein ähnliches Beispiel habe ich ein paar Seiten zuvor schon einmal gezeigt. Diesmal wird die DataTable im DataSet jedoch mit den Schemainformationen für die abgefragten Felder gefüllt. Aus Gründen der Übersicht wird der entsprechende Programmcode in eine spezielle Methode ausgelagert, die nach dem Füllen des DataSets aufgerufen wird.
// Beispiel: ...\Kapitel 34\SchemaMitCode
class Program {
static void Main(string[] args) {
SqlConnection con = new SqlConnection();
con.ConnectionString = "...";
SqlCommand cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "SELECT ProductID, ProductName, " +
"QuantityPerUnit, Discontinued FROM Products";
DataSet ds = new DataSet();
SqlDataAdapter da = new SqlDataAdapter(cmd);
da.Fill(ds);
FillSchemaInfos(ds.Tables[0]);
// Der Artikelbezeichner des Artikels in der ersten Datenzeile
// soll geändert werden
DataRow row = ds.Tables[0].Rows[0];
Console.Write("Produktname ändern: ");
row["ProductName"] = Console.ReadLine();
// Änderung in die Originaldatenbank schreiben
SqlCommandBuilder cmb = new SqlCommandBuilder(da);
da.Update(ds);
Console.WriteLine("Aktualisierung erfolgreich.");
Console.ReadLine();
}
// Diese Methode füllt die Tabelle mit Schemainformationen
static void FillSchemaInfos(DataTable tbl) {
// ProductID
tbl.PrimaryKey = new DataColumn[]{ tbl.Columns["ProductID"]};
// ProductName
tbl.Columns["ProductName"].MaxLength = 40;
tbl.Columns["ProductName"].AllowDBNull = false;
// QuantityPerUnit
tbl.Columns["QuantityPerUnit"].MaxLength = 20;
// Discontinued
tbl.Columns["Discontinued"].AllowDBNull = false;
}
}
Listing 34.5 Aktualisierung im Kontext von Metadateninformationen
Sie können selbst bestimmen, welchen Bezeichner der Artikel bekommen soll. Entscheiden Sie sich für einen Bezeichner mit maximal 40 Zeichen, wird die Änderung in die Datenbank geschrieben. Geben Sie aber mehr als 40 Zeichen ein, wird eine Ausnahme vom Typ ArgumentException ausgelöst. Vielleicht erinnern Sie sich an das ähnliche Aktualisierungsbeispiel weiter oben. Dort wurde das Überschreiten der zulässigen Maximallänge des Feldes ProductName mit einer Ausnahme vom Typ SqlException beantwortet. Diese kam vom SQL Server. Die Ausnahme ArgumentException hingegen wird von ADO.NET in der Clientanwendung ausgelöst.
Vergleichen Sie auch, in welcher Codezeile die Ausnahme ausgelöst wird: Aktualisieren Sie ohne Schemainformationen, ist die Update-Methode des SqlDataAdapters der Urheber. Liegen Schemainformationen im DataSet vor und wird gegen die Einschränkungen verstoßen, handelt es sich um die Anweisung mit der fehlschlagenden Zuweisung, in unserem Beispiel also:
row["ProductName"] = Console.ReadLine();
Das DataSet nimmt die Änderung überhaupt nicht entgegen. Damit ist gezeigt, dass ein DataSet mit Schemainformationen zur Entlastung des Datenbankservers beiträgt.
34.3.5 Schemainformationen mit SqlDataAdapter abrufen
Schemainformationen mit »FillSchema« abrufen
Enthält ein DataSet mehrere Tabellen mit jeweils vielen Spalten, kann die Codierung der Schemainformationen ziemlich aufwendig sein. Ebenso können Sie mit der Methode FillSchema des SqlDataAdapters alle Schemainformationen für das DataSet oder die DataTable abrufen. Die Methode ruft das Schema bei der Datenbank ab. Grundlage ist dabei das in SelectCommand beschriebene SELECT-Kommando. Als Ergebnis des Methodenaufrufs werden die Eigenschaften ReadOnly, AllowDBNull, AutoIncrement, Unique und MaxLength der in der Abfrage enthaltenen Spalten gesetzt. Außerdem werden die Eigenschaften PrimaryKey und Constraints der entsprechenden Tabelle festgelegt.
FillSchema ist mehrfach überladen. Alle Überladungen erwarten ein Argument vom Typ der Enumeration SchemaType. Die Aufzählung hat zwei Mitglieder: Source und Mapped. Über diese Parameter wird gesteuert, ob der SqlDataAdapter die Zuordnungen, die in der DataTableMappingCollection und der DataColumnMappingCollection angegeben sind, verwenden soll.
Beschreiben Sie mittels Programmcode die Gültigkeitsregeln, können diese zu jedem beliebigen Zeitpunkt gesetzt werden. Es muss nur vor der Aktualisierung der Daten im DataSet sein. Benutzen Sie dagegen die Methode FillSchema, muss dies vor dem Füllen des DataSets erfolgen.
[...]
DataSet ds = new DataSet();
da.FillSchema(ds, SchemaType.Source);
da.Fill(ds);
[...]
Der Aufruf der Methode ist einerseits natürlich sehr bequem, aber andererseits dürfen Sie nicht vergessen, dass dabei sowohl das Netzwerk als auch die Datenbank selbst belastet werden.
Die Eigenschaft »MissingSchemaAction« des SqlDataAdapters
Per Vorgabe ist der SqlDataAdapter so eingestellt, dass Spalten zu einer DataTable hinzugefügt werden, wenn diese in der DataTable noch nicht existieren. Damit stellt der SqlDataAdapter sicher, die Ergebnisse einer Abfrage speichern zu können. Gesteuert wird dieses Verhalten von der Eigenschaft MissingSchemaAction, die Werte der gleichnamigen Aufzählung beschreibt.
| Wert | Beschreibung |
|
Add |
Fügt die erforderlichen Spalten zum Vervollständigen des Schemas hinzu. |
|
AddWithKey |
Findet der SqlDataAdapter eine Spalte, die noch nicht in der DataTable existiert, fügt er die Spalte hinzu und setzt die Eigenschaften MaxLength und AllowDBNull. Falls die DataTable noch nicht existiert, wird die Datenbank zudem nach Primärschlüsselinformationen abgefragt. |
|
Error |
Wenn die angegebene Spaltenzuordnung fehlt, wird die Ausnahme InvalidOperation ausgelöst. |
|
Ignore |
Ignoriert die zusätzlichen Spalten. |
Legen Sie die Eigenschaft MissingSchemaAction auf den Wert AddWithKey fest, werden ähnlich wie mit der Methode FillSchema die Schemainformationen abgerufen. Diese sind jedoch auf den Primärschlüssel der Tabelle sowie die Einschränkungen AllowDBNull und MaxLength der Spalten beschränkt. Unique, AutoIncrement und ReadOnly werden hierbei nicht berücksichtigt.
Schemainformationen aus einer XML-Schemadatei beziehen
Nun kennen Sie zwei Varianten, Metadaten einer Tabelle im DataSet bereitzustellen. Sie wissen, dass es sehr einfach ist, mit FillSchema oder MissingSchemaAction=AddWithKey zu arbeiten. Nachteil dabei ist die erhöhte Belastung des Netzes und der Datenbank. Daher ist dies wohl eher nur für Ad-hoc-Abfragen geeignet. Alternativ können Sie die Schemainformationen auch mittels Programmcode beschreiben. Zur Laufzeit ist das sicher effektiv, weil das Netz und die Datenbank nur die tatsächlich benötigten Dateninformationen liefern müssen, während die Metadaten im Code beschrieben werden. Allerdings bedeutet das einen nicht zu vernachlässigenden Programmieraufwand.
Die nun vorgestellte dritte Möglichkeit ist wohl in den meisten Fällen diejenige, die sich am besten eignet. Ausgangspunkt sind zwei Methoden des DataSets: WriteXmlSchema und ReadXmlSchema. Mit WriteXmlSchema können Sie die Schemainformationen eines DataSets in ein XML-Dokument schreiben und es später mit ReadXmlSchema auswerten. Das Schema enthält Definitionen von Tabellen, Beziehungen und Einschränkungen. XML-Schemadateien haben üblicherweise die Dateiendung .xsd.
Bevor Sie das Schema eines DataSets in einer Schemadatei speichern, muss das Schema im DataSet bekannt sein. Sie können sich dieses daher zur Entwicklungszeit mit FillSchema besorgen und anschließend mit WriteXmlSchema in einer Datei speichern.
ds.WriteXmlSchema(@"D:\Products.xsd");
Die erzeugte Schemadatei muss zusammen mit der Anwendung ausgeliefert werden. In Abbildung 34.2 sehen Sie die Schemadatei, die auf einer Abfrage basiert, die die Spalten ProductID und ProductName der Tabelle Products wiedergibt.
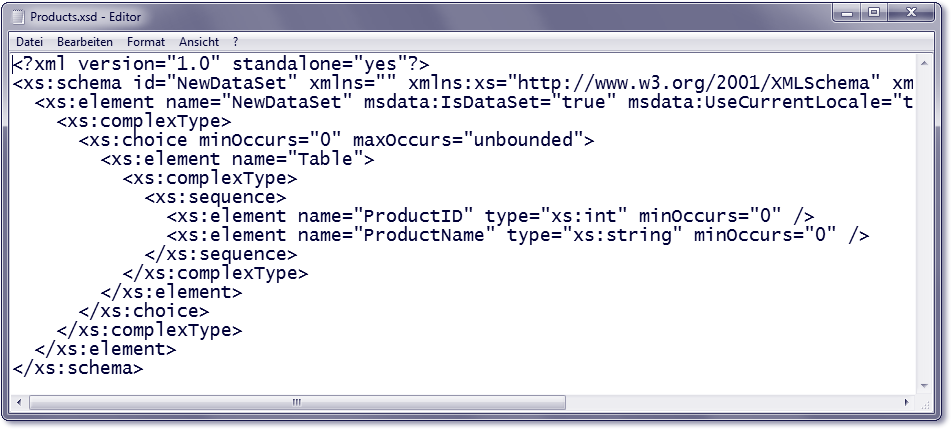
Abbildung 34.2 Beispiel einer mit der Methode »WriteXmlSchema« erzeugten Schemadatei
Sie erkennen, dass die Spalte ProductID die Primärschlüsselspalte der Tabelle beschreibt. AutoIncrement=True signalisiert, das der Spaltenwert bei einer neu hinzugefügten Spalte automatisch erhöht wird. Infolgedessen gilt für die Spalte ProductID auch ReadOnly=True. Die Spalte ProductName weist lediglich eine Einschränkung auf, nämlich die Begrenzung auf maximal 40 Zeichen.
Die Auswertung einer Schemadatei ist sehr einfach. Zur Laufzeit erzeugen Sie zuerst das DataSet-Objekt, lesen anschließend die Schemadatei ein und füllen danach das DataSet mit den Daten.
[...]
DataSet ds = new DataSet();
ds.ReadXmlSchema(@"D:\Products.xsd");
da.Fill(ds);
Dateninformationen und Schemadaten in eine Datei schreiben
Mit WriteXmlSchema erzeugen Sie eine Schemadatei, die die Metadaten des DataSets beinhaltet. Mit der einfach parametrisierten Methode WriteXml des DataSets lassen sich die Daten in einer XML-Datei sichern.
Benötigen Sie beide Informationen, müssen Sie nicht zwangsläufig Metadaten und Dateninformationen jeweils in einer separaten Datei speichern. Mit einer Überladung von WriteXml lässt sich der aktuelle Inhalt des DataSets als XML-Daten mit den Metadaten als XSD-Inlineschema beschreiben. Sowohl Daten als auch Schema sind in einer Datei gespeichert.
ds.WriteXml(@"D:\Products.xml", XmlWriteMode.WriteSchema);
Der Vorgabewert von XmlWriteMode ist IgnoreSchema. Das ist die Einstellung, wenn Sie die einfach parametrisierte Methode aufrufen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



