


17.4 Partitionierung
Sie wissen sicherlich, dass Sie eine Festplatte in viele einzelne Partitionen zerlegen können. Es stellt sich natürlich die Frage nach dem Sinn einer Partitionierung – gerade bei einem Server:
- Upgrade
Im Gegensatz zu einem Serversystem unterliegt ein Desktop-Rechner einer höheren Aktualisierungsrate. Hierbei ist ein separat partitioniertes home-Verzeichnis durchaus sinnvoll, da Sie dann das gesamte »restliche« System neu installieren können, ohne Ihre persönlichen Daten anzutasten. Die Neuinstallation eines Servers geschieht nur alle paar Jahre (»Never change a running system«) und geht oftmals einher mit einer Hardware-Neuanschaffung. Dadurch können Sie den alten Server so lange weiterlaufen lassen, bis der neue fehlerfrei funktioniert. - Parallelinstallation
Ein weiterer wichtiger Grund für die Partitionierung ist natürlich, wenn Sie beispielsweise mehrere Betriebssysteme parallel installieren möchten. Auf einem Server ist – wie bereits erwähnt – eine Parallelinstallation aus Logik-, Sicherheits- und Stabilitätsgründen nicht sinnvoll.
Warum spielt aber das Thema Partitionierung bei einem Server dennoch eine Rolle? Hierfür gibt es eigentlich nur zwei Gründe, wobei dem ersten eine übertriebene Bedeutung zugemessen wird:
- Optimierte Geschwindigkeit
Man hört oft, dass speziell optimierte Dateisysteme für bestimmte Dateitypen das Nonplusultra wären und dass somit eine spezielle Partitionierung mit unterschiedlichen Dateisystemen eine deutliche Geschwindigkeitssteigerung hervorrufen würde. Ehrlich gesagt halte ich diesen Vorteil für marginal und damit vernachlässigbar. Ein Administrator hat in der Regel bei der täglichen Arbeit wichtigere Sachen zu tun, als sich mit 1 % Geschwindigkeitszuwachs zu beschäftigen. - Flexibilität
Bei möglichen Fehlern haben Sie bei getrennten Partitionen die große Flexibilität, dass Sie eventuell nur einzelne Serverdienste abschalten müssen, wenn Sie einzelne Datenpartitionen überprüfen müssen. Im schlimmsten Fall könnten Sie noch eine statische Internetseite online schalten, auf der Ihre Besucher um Geduld gebeten werden, während Sie im Hintergrund nach dem Fehler suchen. Wenn Sie nur eine einzelne Partition haben, müssten Sie den gesamten Server offline nehmen, um ihn zu überprüfen.
Sorgfältige Planung
![]()
Gehen Sie bei der Partitionierung Ihres Servers mit Bedacht zu Werke. Nachträgliche Änderungen sind oftmals nur unter sehr großem Aufwand oder gar nicht möglich. Die Größenänderung einer Partition hat normalerweise den kompletten Datenverlust in diesem Abschnitt zur Folge. Es gibt zwar Mittel und Wege, den Datenverlust zu verhindern, aber Sie können sich bei guter Vorbereitung eine Menge Ärger ersparen. Es ist in diesem Punkt von Vorteil, wenn Sie ungefähr abschätzen können, welche Aufgaben Ihr Server in der Zukunft übernehmen soll, damit Sie die Größenverhältnisse entsprechend anpassen können. Eine elegante Möglichkeit höchstmöglicher Flexibilität stellt LVM dar (siehe Abschnitt 17.4.4, »Methode II – Logical Volume Manager (LVM)«).
Systempartition
Die Systempartition ist die einzige Partition, die zwingend notwendig ist. Hierin befindet sich das gesamte Linux-System, und sie ist die Wurzel des gesamten Dateiverzeichnisses. Aus diesem Grund wird sie auch als Root-Partition bezeichnet und mit »/« in das Dateisystem eingebunden.
Swap
Bei der Swap-Partition handelt es sich quasi um das Pendant zur Windows-Auslagerungsdatei. Dies bedeutet, dass bei einem knappen Arbeitsspeicher Dateien in die Swap-Partition ausgelagert werden. Dies geschieht aber nicht nur bei knappem Arbeitsspeicher. Mehr Details zur Swap-Partition erfahren Sie in Abschnitt 14.8.4, »Swap«. Wie der Begriff »Partition« hier bereits andeutet, handelt es sich dabei unter Linux nicht um eine Datei wie unter Windows. Dies hat den Vorteil einer wesentlich höheren Geschwindigkeit beim Lesen und Schreiben.
Device-Dateien: Linux greift auf Festplatten und Partitionen über sogenannte Device-Dateien zu. Diese Dateien haben eindeutige Bezeichnungen:
Festplatten erhalten der Reihe nach die Bezeichnungen /dev/sda, /dev/sdb /dev/sdc...Die Partitionen auf diesen Festplatten werden nummeriert, wobei 1 bis 4 für primäre und erweiterte Partitionen reserviert sind. Logische Partitionen, die immer nur Teil einer erweiterten Partition sein können, werden ab 5 beginnend gezählt.Bei der Partitionierung fangen Sie also grundsätzlich zuerst mit den primären Partitionen an. Wenn Sie mehr als drei Partitionen auf einer Festplatte benötigen (/dev/sda1, /dev/sda2 und /dev/sda3), legen Sie eine erweiterte Partition an (/dev/sda4), in der Sie beliebig viele logische Partitionen unterbringen können (/dev/sda5, /dev/sda6 ...).
Diese Vorgehensweise ist sehr technisch und einem Einsteiger nur schwer zu vermitteln. Daher fragen die meisten Installationsprogramme heutzutage nur noch die Anzahl der Partitionen ab und teilen diese dann selbständig im Hintergrund in primäre, erweiterte und logische Partitionen auf.
Ganz allgemein ist ein Device eine Geräteschnittstelle, die unter Linux als Gerätedatei im virtuellen Dateisystem vorhanden ist. Diese Dateien finden Sie immer in dem Verzeichnis /dev.
Datenpartitionen
Tabelle 17.2 gibt Ihnen einen Überblick über den Zweck der jeweiligen Verzeichnisse. Sie können bei Bedarf entscheiden, ob Sie eines oder mehrere von ihnen in einzelnen Partitionen speichern. Mehr Details zum Verzeichnisbaum erfahren Sie in Abschnitt 14.8.5, »Der Verzeichnisbaum«.
Ist eine Boot-Partition notwendig?
Eine separate /boot-Partition beherbergt ausschließlich die Daten, die während der ersten Phase des Systemstarts benötigt werden. Hierzu zählen insbesondere die folgenden beiden Dateien sowie einige weitere kleine Dateien des Bootloaders:
- vmlinuz
Dies ist der komprimierte Linux-Kernel (erkennbar an der Endung »z«), der beim Booten als erstes in den Arbeitsspeicher geladen wird. Unter Umständen haben Sie nach einigen Kernel-Aktualisierungen im laufenden Betrieb in dem Verzeichnis /boot mehrere komprimierte Kernel-Dateien. Durch den Befehl ls -l /boot verschaffen Sie sich einen Überblick. - initrd
Die Initial-RAM-Disk (sinngemäß zu Deutsch: »Ausgangspartition im Arbeitsspeicher«) ist ein temporäres Abbild eines Dateisystems, das vom Linux-Kernel während des Boot-Vorgangs als Stammverzeichnis für den Kernel (vmlinuz, siehe oben) eingehängt wird.
Alle diese Dateien nehmen normalerweise nicht mehr als 200 MB Speicherplatz ein. Eine solche /boot-Partition ist lediglich sinnvoll, wenn der Bootloader (bei Ubuntu ist dies GRUB) keine Dateien aus der Systempartition lesen kann. Dass GRUB diese Daten nicht lesen kann, ist wiederum eigentlich nur der Fall, wenn GRUB das Dateisystem der Systempartition nicht kennt (siehe hierzu auch den folgenden Abschnitt »Dateisystem«).
Ubuntu verwendet GRUB 2, das – im Gegensatz zu GRUB 1 (legacy) – inzwischen sogar Boot-Dateien aus Software-RAIDs und LVM-Installationen lesen kann. Somit ist unter normalen Umständen keine separate /boot-Partition notwendig. Ein Wermutstropfen bleibt: Nutzen Sie das Dateisystem btrfs für Ihre Systempartition, so kommen Sie an dem Einsatz einer /boot-Partition dennoch nicht vorbei – GRUB versteht btrfs nicht.
GRUB Legacy: Viele Linux-Distributionen wechseln zurzeit zu der neuen GRUB-Version 2 oder haben diesen Wechsel bereits vollzogen. Der Grund ist in erster Linie, dass die ältere GRUB-Version 0.97 (manchmal auch »GRUB Legacy« genannt) das neue Dateisystem ext4 nicht versteht. Darüber hinaus kann GRUB Legacy die Boot-Dateien weder aus einem Software-RAID noch aus LVM-Partitionen lesen.
Platzbedarf je nach Einsatzbereich
Nachdem Sie gesehen haben, welche Verzeichnisse spezielle Serveraufgaben erfüllen, stellt sich die Frage nach dem Platzbedarf: Wie groß sollen die Partitionen jeweils bemessen sein? Die Antwort ist von Ihrer individuellen Nutzung abhängig und kann nicht pauschal beurteilt werden. Bei intensiver Nutzung steigt der Platzbedarf einzelner Verzeichnisse:
- Dateiserver: /home (siehe Abschnitt 20, »Datei-Server – Ubuntu im Netzwerk«),
- Webserver: /var/www (siehe Abschnitt 21, »Der Server im Internet«),
- Datenbankserver: /var/lib/mysql (siehe Abschnitt 21.2.1, »Allgemeines zu MySQL«) usw.
17.4.1 Dateisystem
Das Formatieren einer Partition ist nötig, um ein Dateisystem zu erstellen, mit dem Dateien auf dem Server gespeichert werden können. Übliche Dateisysteme sind:
- ext2
ext2 ist das traditionelle Dateisystem von Linux. Es ist sehr stabil, braucht aber seine Zeit, um das Dateisystem im Bedarfsfall zu reparieren. Es wird hauptsächlich auf kleineren Volumes genutzt, die in der Regel read-only sind. - ext3/ext4
Dieses Dateisystem ist die Weiterentwicklung von ext2 und enthält zusätzlich die Journaling-Funktion. Damit ist es möglich, einen konsistenten Zustand der Daten zu rekonstruieren, auch wenn ein Schreibvorgang an beliebiger Stelle abgebrochen wurde. Diese Eigenschaft ist im Fall von Systemabstürzen oder Stromausfällen von Vorteil.So kann die bei herkömmlichen Dateisystemen nach solchen Vorfällen oft automatisch gestartete Überprüfung des ganzen Dateisystems mit oft erfolglosen Reparaturversuchen entfallen. Speziell bei großen Festplatten mit Partitionsgrößen über 100 GByte ergibt sich hieraus auch eine beträchtliche Zeitersparnis beim Booten, da das Überprüfen solch großer Platten durchaus mehrere Stunden dauern kann. Der Nachteil besteht darin, dass das Indexing in ext3/ext4 eher begrenzt ist.
- XFS
XFS wurde von dem Hersteller der Supercomputer, SGI, als Open-Source-Dateisystem erstellt und eignet sich hervorragend für wirklich große Volumes. XFS ist ein vollständiges 64-Bit-Dateisystem und besitzt einige Tuning-Optionen, ein Journal und einen sehr guten Index. Im Moment wird dieses Dateisystem als die beste Variante zum Speichern von Dateien betrachtet. - ReiserFS
ReiserFS ist ein Mehrzweck-Dateisystem, das von einer Entwicklergruppe um Hans Reiser unter der GPL entwickelt wurde. ReiserFS war das erste Journaling-Dateisystem, das im Linux-Kernel erstmals standardmäßig (ab Kernel-Version 2.4.1) enthalten war. Zurzeit wird ReiserFS in der Version 3 vom Linux-Kernel vollständig unterstützt. ReiserFS ist eine gute Alternative für Systeme, in denen viele große Dateien verwaltet werden müssen. Trotzdem gibt es Probleme bei der Stabilität, so dass früher oder später Probleme auftreten könnten. - JFS
JFS ist eine IBM-Entwicklung und erhielt als erstes Dateisystem die Journaling-Funktion. Das primäre Designziel von JFS war die stetige Konsistenz des Dateisystems: Änderungen am Dateisystem werden transaktionsorientiert geschrieben sowie im Journal protokolliert. Bei einem Absturz kann somit – ausgehend von einem Konsistenzpunkt der Transaktionen – über das Journal sehr effizient ein konsistenter Status des Dateisystems hergestellt werden. Ein voller Zugriff auf das Dateisystem ist also sehr schnell wieder erreicht. Im Fokus steht damit die Verfügbarkeit der Ressource »Dateisystem«, nicht die Performance oder die Integrität der Dateiinhalte. Diese Skalierbarkeit des Dateisystems kann unter anderem vom Logical Volume Manager verwendet werden: Im laufenden Betrieb und unter Last können einfach Festplatten in der Konfiguration ergänzt und in die Volume Group aufgenommen werden, um das Dateisystem zu erweitern. - btrfs
Dem Dateisystem btrfs wird eine glänzende und bedeutende Zukunft vorausgesagt. Und tatsächlich sind die Voraussetzungen dafür beachtlich. Dieses Dateisystem beherrscht viele neue Funktionen, etwa Snapshots oder integrierte SSD- und RAID-Unterstützung. Leider gibt es im Moment noch keine Möglichkeit (wie beispielsweise den Befehl fsck), ein defektes Dateisystem zu reparieren.
Problem: SSDs und Achtung bei neuen Festplatten
Die oben aufgezählten Dateisysteme leiden unter einem fundamentalen Problem: Sie sind nicht für den Einsatz von Flash-Speicher optimiert (SSDs, Solid-State-Disks). Diese Speichertechnologie wird in absehbarer Zeit auch im Serverbereich Einzug halten und kann nur mit entsprechenden Treibern und Dateisystemen effektiv verwaltet werden. Es soll nicht unerwähnt bleiben, dass auch die Betriebssystemkonkurrenz bisher keine Lösung für dieses Problem anbieten kann. Ich empfehle Ihnen daher, bei Ihrem Server vorerst auf SSDs zu verzichten.
Festplatten sind physisch in sogenannte Sektoren unterteilt, die wiederum die Basis für das Anlegen von Partitionen darstellen. In den letzten zwanzig Jahren war eine Sektorgröße von 512 Byte Standard, diese ist aber in den letzten Jahren durch das stete Wachstum der Festplatten immer mehr in Frage gestellt worden. Bei den heute erhältlichen Festplattengrößen von 1 bis 2 Terabyte bringt eine Vergrößerung dieser Sektoren deutliche Geschwindigkeitsvorteile. Aus diesem Grund tendieren inzwischen manche Hersteller zu 4.096 Byte, also achtfach größeren Sektoren. Diese neue Sektorgröße bedeutet, dass Festplatten nur effizient ausgenutzt werden können, wenn die Startposition einer jeden Partition ein Vielfaches von 4.096 Byte beträgt. Ansonsten kann es passieren, dass das Dateisystem bei Schreib- und Lesevorgängen im schlimmsten Fall in zwei Sektoren arbeiten muss. Dieser unvorteilhafte Umgang würde zu massiven Leistungseinbußen führen.
Neue Sektorgröße kein Problem für Ubuntu
Ubuntu berücksichtigt bei der Installation automatisch die neuen 4.096-Byte-Sektoren und richtet neue Partitionen dementsprechend ein. Aus Gründen der für Menschen leichteren Lesbarkeit starten neue Partitionen immer bei einem Vielfachen von 1 MByte. Wenn Sie allerdings manuell Partitionen anlegen oder Programme verwenden, die auf die Nutzung von 512 kB großen Sektoren spezialisiert sind, achten Sie darauf, dass die Partitionsgrenzen ein Vielfaches von 8 Sektoren betragen. Das Werkzeug fdisk kümmert sich bei Verwendung der Optionen -c -u automatisch um die korrekte Konfiguration.
17.4.2 Partitionierungsempfehlungen
Abhängig von der Anzahl der verwendeten Festplatten gebe ich Ihnen in Tabelle 17.3 einige Partitionierungsvorschläge. Um es gleich deutlich zu sagen: Wenn möglich, würde ich einen Server immer mit mindestens zwei Festplatten ausstatten. Nur dadurch ist die Erstellung eines (Software-)RAIDs und damit einhergehend eine große Datensicherheit möglich.
| Anzahl der Festplatten | Partitionierungsempfehlung | Weitere Informationen |
| 1 | LVM-Installation – so profitieren Sie von einer einfachen Erweiterbarkeit und der damit verbundenen Flexibilität hinsichtlich der Größe Ihrer Partitionen. Fügen Sie bei Bedarf später einfach eine weitere Festplatte als Physical Volume zur Volume Group hinzu. | Abschnitt 17.4.4, »Methode II – Logical Volume Manager« |
| 2 | Erste Wahl sollte ein RAID 1 sein, wenn Sie Wert auf Ihre Datensicherheit legen. Es bleibt Ihnen überlassen, ob Sie dennoch zusätzlich die Flexibilität einer LVM-Installation brauchen. Dazu sollten Sie sich fragen, ob Sie später beispielsweise vorhandene Partitionen vergrößern oder verkleinern wollen. | |
| Im Falle eines Falles können Sie wiederum zwei neue Festplatten als RAID 1 partitionieren und dieses Device als Physical Volume zur bereits vorhandenen Volume Group hinzufügen. | Abschnitt 17.4.5, »Methode III – RAID« | |
| 3+ | Hier bietet sich ein RAID 5, bei vier Festplatten sogar ein RAID 10 an. Wenn Sie bei Ihrem Server mit besonders vielen kleinen Datenpaketen hantieren, würde ich von einem RAID 5 abraten, da die Leistungsfähigkeit durch das konstante Schreiben von Paritätsinformationen deutlich sinkt. Investieren Sie lieber in eine vierte Festplatte, um ein RAID-10-System aufzubauen. | Abschnitt 17.4.5 »Methode III – RAID« |
17.4.3 Methode I – Klassische Partitionierung
Auf die klassische Partitionierung werde ich an dieser Stelle nicht näher eingehen und verweise Sie auf den entsprechenden Abschnitt 5.5.3, »Partitionierung«. Sie finden dort im Rahmen der textbasierten Installation eines Desktop-Systems alle nötigen Informationen, um auch einen Server »aufzusetzen«.
17.4.4 Methode II – Logical Volume Manager (LVM)
Wir wollen uns nun eine grundlegend andere Art der Partitionierung etwas genauer ansehen, wobei der Begriff »Partitionierung« bei der im Folgenden vorgestellten Technik etwas kurz greift. Die Rede ist vom Logical Volume Manager (LVM), der eine weitere (logische) Schicht zwischen dem System und den eigentlichen Partitionen darstellt.
Der Logical Volume Manager hat sich insbesondere im professionellen Umfeld durchgesetzt. Er wird oft auf dem Gebiet der Hochverfügbarkeitstechnik angewendet, wo es keine Seltenheit ist, dass ein Server jahrelang ununterbrochen läuft. LVM ist bei einer Nicht-RAIDInstallation die Standard-Partitionierungsmethode des Ubuntu-Servers.
LVM: Logical Volume Manager. Eine hauptsächlich im Unix- und Linux-Umfeld verbreitete Abstraktionsebene zwischen Festplatten und Dateisystemen. Festplatten (Physical Volume, PV) werden zu einem Pool (Volume Group, VG) zusammengefasst, aus dem dynamisch Partitionen (Logical Volume, LV) angefordert werden können. Auf Logical Volumes werden die Dateisysteme angelegt.
Grundlagen
LVM ist mit dem Konzept des dynamischen Datenträgers unter Microsoft Windows/Windows Server vergleichbar. Die grundlegende Idee ist folgende: Anstelle von Partitionen starrer Größe verwendet man sogenannte Logical Volumes, die bei Bedarf vergrößert werden können. Dadurch ist es beispielsweise auch möglich, im laufenden Betrieb Festplatten in ein System einzubauen und mit diesen den bestehenden Speicherplatz unterbrechungsfrei zu erweitern.
Die folgenden Begriffe sind für das Verständnis der LVM-Technik wichtig:
- Physical Volume (PV)
Ein Physical Volume ist eine spezielle Partition der Festplatte, kann aber auch aus der kompletten Platte oder einem RAID-Device bestehen. Bis hierhin ist noch kein großer Unterschied zu einer klassischen Partitionierung feststellbar, daher folgt auch die Bezeichnung »Physical Volume«, also eine Art von Speicherdefinition, die direkt auf der physischen Festplatte basiert. - Volume Group (VG)
Die Volume Group fasst ein oder mehrere Physical Volumes zu einer Gruppe zusammen, stellt also quasi einen Speicher-Pool dar. Eine Volume-Gruppe ist jederzeit erweiterbar, zum Beispiel wenn Sie eine zusätzliche Festplatte einbauen. Die Volume Group ist die auf den Physical Volumes aufsetzende Verwaltungsschicht. - Logical Volume (LV)
Die eben genannten Volume Groups verhalten sich logisch wie Festplatten, auf denen Sie jetzt Partitionen anlegen, die sogenannten Logical Volumes. Das Logical Volume entspricht daher im übertragenen Sinne einer normalen Partition bzw. wird vom Betriebssystem als solche angesehen. In Wirklichkeit ist es jedoch nur ein Bereich, der in einer Volume Group zusammengefasst und reserviert wurde. In diesen »Partitionen«, die jetzt einen Device-Namen statt eines Pfades wie zum Beispiel /dev/sda1 haben, wird das Dateisystem angelegt. Auch ein Logical Volume ist jederzeit erweiterbar.
Zunächst benötigen Sie also mindestens ein Physical Volume. Daraus erstellen Sie eine Volume Group. Aus der Volume Group heraus definieren Sie Logical Volumes, die später die einzelnen Dateisysteme beherbergen. Jedes Logical Volume ist erweiterbar; ist der Platz der Volume-Gruppe irgendwann aufgebraucht, können Sie sie durch Hinzufügen eines weiteren Physical Volumes erweitern.
Physical Device und Physical Extent: Diese beiden Begriffe tauchen häufig auf, wenn es um LVM geht. Ein Physical Device (PD) bezeichnet schlicht und einfach eine Festplatte, also ein physisches Gerät. Der Begriff Physical Extent (PE) hingegen bezeichnet die kleinste Dateneinheit eines Logical Volumes, die standardmäßig 4 MByte beträgt. Die Anzahl dieser PEs ist theoretisch unbegrenzt, wobei die Komplexität der Verwaltung mit der Anzahl der PEs zunimmt. Insofern sollten Sie bei sehr großen Logical Volumes die Größe dieser PEs heraufsetzen.
Sehen wir uns nun einmal ein Beispiel an: LVM auf einem Server. Folgende Partitionierung bietet sich für ein System an, das später als Server agieren soll:
- eine Boot-Partition (/boot): 50 MB, Dateisystem: ext3
- eine Root-Partition (/): 300 MB, Dateisystem: ext3
- eine LVM-Partition (kein Mountpoint): der Rest der freien Festplatte
Innerhalb der LVM-Partition werden die folgenden Logical Volumes erstellt:
- /usr: 2 GB, Dateisytem: xfs
- /var: 1 GB, Dateisystem: xfs
- /tmp: 200 MB, Dateisystem: xfs
- /home: je nach Bedarf, als Anfang 1 GB, Dateisystem: xfs
- /swap: je nach Speicher, mindestens 512 MB
Einrichtung
Bei der Partitionierung gehen Sie dann folgendermaßen vor:
- Wählen Sie im Installer die manuelle Partitionierung aus, und legen Sie zwei ext3fs-Partitionen für / und /boot gemäß dem obigen Vorschlag an.
- Der Rest der Festplatte wird für das LVM-Physical-Volume verwendet. Zu diesem Zweck müssen Sie die Option Physical Volume für LVM als Typ auswählen.
- Nun wählen Sie im Partitionierungsmenü die Option Logical Volume Manager konfigurieren aus. Bestätigen Sie den nächsten Dialog, über den die bislang vorhandene Partitionierung auf der Platte übernommen wird. Als erste Aktion erstellen Sie eine Volume Group, für die Sie das oben definierte Physical Volume auswählen (Leertaste betätigen). Der Name kann beispielsweise »vg00« sein.
- Anschließend erstellen Sie Logical Volumes gemäß dem obigen Vorschlag. Idealerweise verwenden Sie selbsterklärende Namen, zum Beispiel »usr« für das zukünftige /usr-Dateisystem.
Sind alle Volumes angelegt, kehren Sie ins Hauptmenü zurück. Dort werden den aufgeführten LVM-»Partitionen« xfs-Dateisysteme und die entsprechenden Mountpoints zugewiesen. Die fertige Partitionslandschaft zeigt Abbildung 17.4.
Angelegte Dateisysteme betrachten
Nun kann die Partitionierung abgeschlossen werden, und die Installation läuft ganz normal weiter. Ist das System fertig installiert, können Sie sich mit dem Befehl df -h auf einer Konsole die gemounteten Dateisysteme anschauen und sehen die angelegten Volumes.
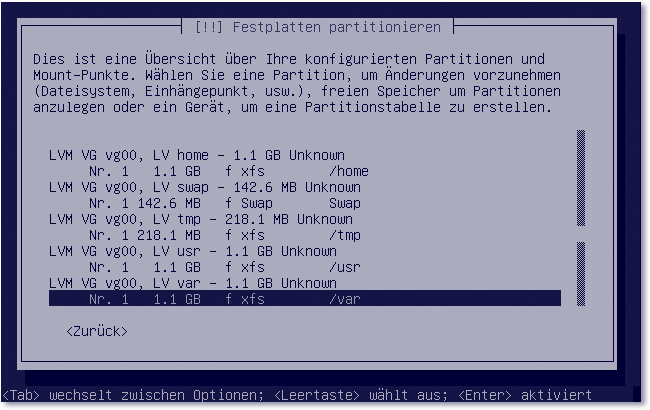
Abbildung 17.4 Anlegen von Partitionen unter »LVM«
17.4.5 Methode III – RAID
Unter einem Redundant Array of Independent Disks (RAID) versteht man ein (häufig auf Servern eingesetztes) Modul aus mehreren voneinander unabhängigen Festplatten. Mit einem RAID kann beispielsweise der Ausfall einer Festplatte ohne Datenverlust verkraftet werden. RAID-Systeme verbessern die Zugriffszeiten, die Speicherkapazität und die Zuverlässigkeit (Ausfallsicherheit) von Magnetplattenspeichern. RAID wird auch als Abkürzung für Redundant Array of Inexpensive Disks interpretiert (redundante Anordnung preiswerter Festplatten). Das RAID-Konzept wurde Ende der 80er Jahre an der Berkeley-Universität in Kalifornien entwickelt.
RAID: Ein RAID-System dient zur Organisation zweier oder mehrerer physischer Festplatten eines Computers zu einem logischen Laufwerk, das eine größere Speicherkapazität, eine höhere Datensicherheit beim Ausfall einzelner Festplatten und/oder einen größeren Datendurchsatz erlaubt als eine einzelne physische Platte. Während die meisten in Computern verwendeten Techniken und Anwendungen darauf abzielen, Redundanzen (das Vorkommen doppelter Daten) zu vermeiden, werden bei RAID-Systemen redundante Informationen gezielt erzeugt, damit beim Ausfall einzelner Komponenten das RAID als Ganzes seine Funktionalität behält.
Verteiltes Speichern
Bei RAID handelt es sich um ein Verfahren zur Datenspeicherung, bei dem die Daten meist zusammen mit Fehlerkorrekturcodes (zum Beispiel Paritäts-Bits) auf mindestens zwei Festplattenlaufwerken verteilt gespeichert werden. Das Festplatten-System wird durch Verwaltungsprogramme und einen Festplatten-Controller gesteuert. Ein Array ist ein Festplattensatz, auf dem die Dateien nach bestimmten Verfahrensweisen wie bei einer Datenbank abgelegt werden.
Komponenten
Ein RAID-System setzt sich aus drei Komponenten zusammen:
- dem Array aus mindestens zwei Magnetspeicherplatten
- dem Hardware-Controller zur Steuerung des Arrays
- dem Programm zur Steuerung der Lese- und Schreibzugriffe auf das Array
- \end{gpAuflistung}
RAID-Level
Es gibt vier Wege, softwarebasierte RAID-Systeme zu implementieren:
- RAID 0 – Disk Striping
Bei dieser Methode werden zwei Festplatten gebündelt. Für die Performance ist dies eine wunderbare Sache, weil Sie zwei Controller haben, die den Datenfluss simultan abarbeiten. RAID 0 hat aber den Nachteil, dass diese Variante relativ fehleranfällig und redundant ist. Wenn eine der beiden Festplatten in RAID 0 kaputtgeht, haben Sie keinen Zugriff mehr auf die Daten. - RAID 1 – Disk-Spiegelung
In einem RAID-1-Verbund wird eine Festplatte dazu verwendet, alle I/O-Aktionen abzuarbeiten, und die andere Festplatte fungiert als Backup-Festplatte. Alles, was auf der aktiven Festplatte passiert, geschieht auch auf dem Backup, so dass die Backup-Platte zu jeder Zeit denselben Datenbestand hält wie die aktive Festplatte. Wenn die aktive Festplatte also einmal ausfallen sollte, kann die Backup-Festplatte leicht übernehmen. Diese Methode ist relativ sicher, hat aber eine verhältnismäßig niedrige Performance. Deswegen sollten Sie diese Variante nicht benutzen, wenn Sie viele Daten in die Speichergeräte schreiben, oder aber Ihr RAID 1 sollte so aufgebaut sein, dass zwei Controller vorhanden sind, die die Schreibgeschwindigkeit erhöhen. Für statische Inhalte ist RAID 1 aber eine gute Lösung. - RAID 10 – der Kompromiss
Diese Variante bietet Ihnen alle Vorteile aus RAID 0 und RAID 1 – exzellente Performance und äußerst geringe Fehleranfälligkeit zugleich. Dennoch gibt es auch einen Nachteil: Sie benötigen mindestens vier Festplatten. - RAID 5
Wenn Sie viele Daten schreiben müssen, bietet RAID 5 die besten Möglichkeiten. Es werden drei Festplatten benötigt. Wird eine Datei geschrieben, wird sie direkt auf zwei der drei Festplatten übertragen, während auf die dritte Festplatte Paritätsinformationen für diese Datei geschrieben werden. Auf diese Weise kann die Datei leicht rekonstruiert werden, falls eine der ersten beiden Festplatten kaputtgeht. Für eine noch bessere Performance werden die Paritätsinformationen auf die gesamte Festplattenmatrix verteilt, so dass keine bestimmte Festplatte alle Paritätsinformationen enthält.
Striping
RAID bewerkstelligt die Bildung eines einzigen logischen Laufwerks aus mehreren Untereinheiten durch einen Vorgang, der als Striping bezeichnet wird. Beim Striping werden Informationen in eine logische Aufteilung gebracht, so dass die einzelnen Dateien über mehrere Laufwerke verteilt sind. Ein Stripe-Segment kann nicht mehr als ein einzelnes Byte oder auch mehrere Sektoren umfassen. Striping hat den Vorteil des schnelleren Datenzugangs, da die einzelnen Laufwerke parallel zugänglich sind. Der Nachteil besteht darin, dass die Kapazität des Arrays mit der Formatierung festgelegt ist, so dass eine Erweiterung nicht durch das Hinzufügen von weiteren Laufwerken erreicht werden kann.
Parität
Paritätsinformationen, die für ein RAID-Setup genutzt werden, sind eine Art Summierung aller Dateien auf dem RAID. Geht eine Festplatte kaputt, kann die Datei anhand der Paritätsinformationen rekonstruiert werden. Neben den genannten RAIDs gibt es aber noch andere RAID-Lösungen. Diese ähneln im Großen und Ganzen den hier erläuterten:
- RAID 3
Bei RAID 3 (»Parallel Array with Parity«) wird bei jeder Datenspeicherung eine Paritätsprüfung durchgeführt und das Ergebnis auf einer eigenen Festplatte festgehalten, der Paritätsplatte. Fällt eine Magnetplatte aus, können die darauf gespeicherten Daten mit Hilfe der Paritätsdaten wiederhergestellt werden. Da jede Schreibaktion den Inhalt der Paritätsplatte verändert, kann nicht gleichzeitig auf alle Platten des Arrays geschrieben werden. Lesezugriffe können jedoch auf alle Platten gleichzeitig erfolgen. - RAID 6
Bei RAID 6 wird zusätzlich zum RAID-5-Verfahren eine weitere, unabhängige Paritätsinformation auf einem zusätzlichen Festplattenlaufwerk gespeichert. Aufgrund der zusätzlichen Paritätsberechnung und -speicherung sind die Schreibzugriffe etwas langsamer als bei RAID 5. Dafür ist die Ausfallsicherheit noch höher. - RAID 7
RAID 7 ähnelt RAID 5, jedoch wird bei RAID 7 in der Steuereinheit zusätzlich ein lokales Betriebssystem mit Echtzeitfunktionalität eingesetzt. Für RAID 7 werden schnelle Datenbusse und mehrere größere Pufferspeicher benutzt. Die Daten in den Pufferspeichern und auf den Laufwerken werden asynchron verarbeitet. Dadurch sind sie unabhängig von der Datenübertragung auf dem Bus. Die asynchrone Verarbeitung beschleunigt die Schreib- und Lesevorgänge gegenüber anderen RAID-Verfahren erheblich. Wie bei RAID 6 kann auch bei RAID 7 die Paritätsinformation für ein oder für mehrere Laufwerke erzeugt werden.
Es ist zumeist auch problemlos möglich, mehrere RAID-Konfigurationen auf einem Server zu betreiben. Einer meiner Server besitzt sechs Festplatten, wobei die ersten beiden zu einem RAID-1-System zusammengefasst sind und die Systempartition beherbergen. Die restlichen vier Festplatten sind in einem RAID 5 organisiert und geben den Datenbanken ihr Zuhause.
Hardware- versus Software-RAID
Sie haben prinzipiell drei Möglichkeiten, ein RAID aufzubauen:
- Hardware
Die ersten beiden Möglichkeiten benötigen eine spezielle Hardware. - RAID-Controller
Bei einem sogenannten Hardware-RAID kümmert sich ein separater RAID-Controller um die Verwaltung der Festplatten. Dies hat den Vorteil, dass die restliche Hardware (zum Beispiel die CPU) durch diese Verwaltung nicht belastet wird. In der Folge ist ein solches RAID sehr schnell und stabil – oftmals ist sogar der Austausch defekter Festplatten während des Betriebs (das sogenannte Hot Swap) problemlos möglich. Nachteile dieser Technik sind der mitunter hohe Preis eines solchen Controllers und das Fehlen geeigneter Linux-Treiber. Wenn Ihr Server einen Hardware-RAID-Controller besitzt, sollten Sie sich die Dokumentation für diesen anschauen. Jeder RAID-Controller hat andere Eigenschaften, so dass sich eine generelle Aussage über die Funktionsweise von RAID-Controllern nicht treffen lässt. Generell gelangen Sie direkt beim Starten des Rechners durch eine angezeigte Tastenkombination in die Konfiguration Ihres RAID-Controllers. Hier können Sie dann die vorhandenen Festplatten in ein RAID zusammenfassen oder die bisherige Konfiguration verändern. - Festplatten-Controller + Software
Ein sogenanntes BIOS-Software-RAID ist sehr weit verbreitet und heutzutage auf vielen Mainboards vorhanden. Hierbei arbeitet das BIOS mit einem günstigen Festplatten-Controller zusammen, um verschiedene RAID-Level zu realisieren. Das Betriebssystem muss zusätzlich bestimmte Treiber zur Verfügung stellen, um dieses RAID nutzen zu können. Oftmals wird eine solche Kombination auch »Fake Raid« genannt, da die Werbung vieler Mainboard-Hersteller das Vorhandensein eines echten RAID-Controllers suggeriert. Gegenüber dem reinen Hardware-RAID muss sich bei dieser Lösung die CPU um die Verwaltung des RAIDS kümmern, was einen Geschwindigkeitsverlust bedeutet. - Software
Wenn Sie keinen »echten« RAID-Controller Ihr Eigen nennen können, ist ein Software-RAID die prädestinierte Methode und auf jeden Fall gegenüber dem BIOS-Software-RAID zu bevorzugen. Hierbei übernimmt das Betriebssystem direkt per Software die RAID-Verwaltung. Die Geschwindigkeit ist zumindest ähnlich, die Flexibilität aber wesentlich höher als bei einem BIOS-Software-RAID. Sie benötigen keine besondere Hardware außer einem gewöhnlichen Festplatten-Controller und mindestens zwei Festplatten. Bei den älteren IDE-Festplatten sollten Sie allerdings darauf achten, dass sie an unterschiedliche Controller angeschlossen sind, um ein Maximum an Geschwindigkeit zu erzielen.
LVM
Zusätzlich zu den RAID-Lösungen gibt es auch noch andere Speichermöglichkeiten mit Festplatten: Logical Volumes und traditionelle Partitionierungen. Vor allem für Data Volumes eignen sich Logical Partitions, weil sie nicht nur leicht zu vergrößern sind, sondern weil sie auch eine sogenannte Snapshot-Funktion enthalten. Unter Verwendung einer weiteren Partition werden alle Änderungen abgefangen und können bei Bedarf leicht und schnell rückgängig gemacht werden. Die Schnappschuss-Partition kann dabei kleiner sein als das Original. Mit Hilfe der Schnappschuss-Funktionen können, anders als bei der traditionellen Partitionierung, weit über 16 Partitionierungen erstellt werden. Einen einzigen Nachteil hat dieses Feature allerdings: Sie können von dieser Partition nicht booten.
RAID-Installation ohne Server
Die Installation eines RAIDs ist nicht nur mit der Ubuntu-Server-CD möglich. Sie können alternativ auch das DVD-Image von Ubuntu verwenden. Wählen Sie dort die Textbasierte Installation. Alle anderen Ubuntu-Images sind nicht für die RAID-Installation geeignet, da der Multi Devices Driver Support (md) in ihnen nicht standardmäßig enthalten ist.
Multi Devices Driver Support: Was ist dieser md-Treiber genau? Kurz gesagt stellt er eine zusätzliche abstrakte Schicht zwischen
dem Festplatten-Controller (SATA/IDE/SCSI) unddem Dateisystemtreiber (zum Beispiel ext3) dar.Der md-Treiber bildet aus mehreren Festplattenpartitionen ein neues logisches Device, auf das der Dateisystemtreiber unter /dev/md* zugreifen kann. Nach der RAID-Konfiguration verwenden Sie statt der herkömmlichen Festplattenpartitionen jetzt die neuen RAID-Partitionen für die Installation des Systems.
Ablauf der Partitionierung
Wir werden im Folgenden ein RAID 1 mit zwei Festplatten (Drive 0 und Drive 1) konfigurieren. Auf diesen beiden Festplatten erstellen wir jeweils zwei Partitionen (sda1/sda2 und sdb1/sdb2). Die genaue Aufteilung können Sie Tabelle 17.4 entnehmen.
| Festplatten | Partition | Typ | Mount-Punkt |
| Drive 0 | /dev/sda1 | primär | / |
| /dev/sda2 | primär | swap | |
| Drive 1 | /dev/sdb1 | primär | / |
| /dev/sdb2 | primär | swap |
Höchstwahrscheinlich werden Sie bei einem realen Server separate /var- und /homePartitionen bevorzugen. Wir nutzen obige Partitionierung, um die Multi-Disk-Geräte md0 und md1 zu erstellen.
| md-Gerät | Typ | Partitionen | Mount-Punkt |
| /dev/mdo | RAID 1 | /dev/sda1 | / |
| /dev/sda2 | swap | ||
| /dev/md1 | RAID 1 | /dev/sdb1 | swap |
| /dev/sdb2 | swap |
Wir werden im Folgenden die Partitionierung stichpunktartig durchgehen:
- Im Partitionierungsdialog wählen Sie Manuell und dann die erste zu partitionierende Festplatte aus (sda). Im Anschluss bestätigen Sie die Abfrage Neue, leere Partitionstabelle auf diesem Gerät erstellen?
- Wechseln Sie mit Hilfe der Pfeiltasten in den freien Speicher, und wählen Sie Eine neue Partition erstellen. Achten Sie darauf, dass diese groß genug ist, und lassen Sie einen Swap-Bereich frei. Wählen Sie Primär als Typ und Anfang als Position.
- Im Auswahldialog Partitionseinstellungen wählen Sie Benutzen als: physikalisches Volume für RAID und versehen die Partition mit einem Boot-Flag (Ein). Zum Abschluss wählen Sie Anlegen der Partition beenden (siehe Abbildung 17.6).
- Wiederholen Sie nun diese Schritte, um eine weitere primäre Partition zu erstellen (beispielsweise für das spätere Swap). Diese zweite Partition sollte allerdings kein Boot-Flag erhalten. Nun haben Sie auf der ersten Festplatte zwei Partitionen angelegt, die den ersten Teil der RAID-Konfiguration darstellen.

Abbildung 17.5 Wählen Sie hier die korrekte Verwendung der Partition für ein RAID.
- Die gleichen Schritte müssen Sie ebenfalls für Ihre zweite Festplatte (sdb) durchführen. Achten Sie hierbei darauf, dass Sie für beide Festplatten unbedingt identische Größen der Partitionen verwenden!
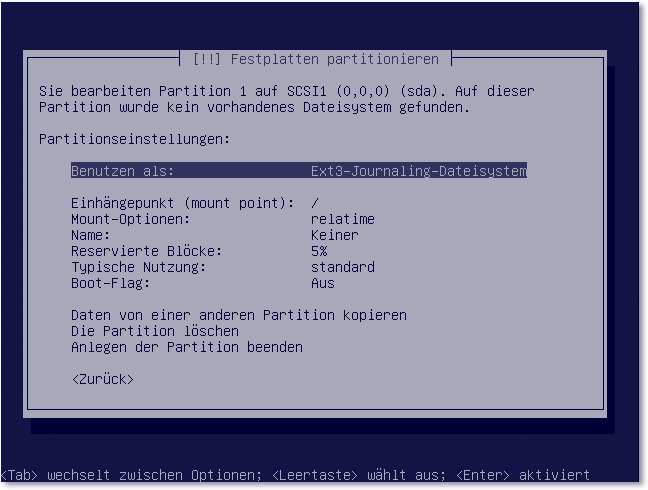
Abbildung 17.6 Achten Sie darauf, dass Sie die Partition mit einem Boot-Flag kennzeichnen.
- Nachdem beide Festplatten konfiguriert sind, wählen Sie in der Übersicht SoftwareRAID konfigurieren. Daraufhin werden die Festplatten partitioniert (siehe Abbildung 17.7).
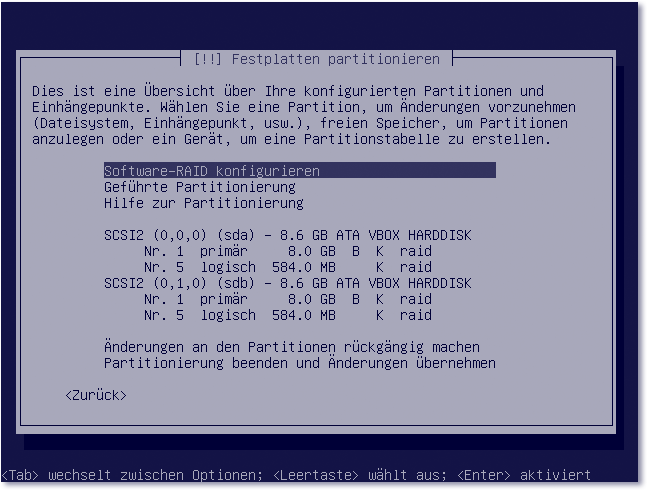
Abbildung 17.7 Nach erfolgter Partitionierung starten Sie den Assistenten zur Erstellung eines Software-RAID.
- Im folgenden Dialog erstellen wir nun ein Multi-Disk-Gerät (MD-Gerät). Die folgenden Schritte sind selbsterklärend. Sie wählen den RAID-Typ (RAID 1) und geben die Anzahl der aktiven Geräte für das RAID1-Array an (in diesem Beispiel 2). Bei der Anzahl der Reserve-Geräte geben Sie null an.
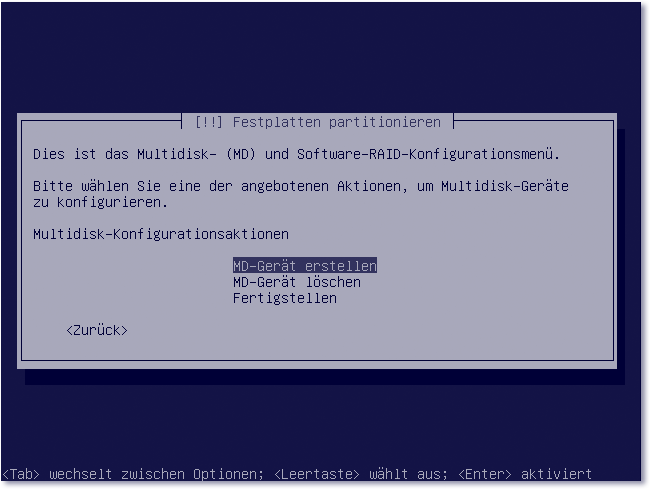
Abbildung 17.8 Aus jeweils zwei gleichen Partitionen erstellen Sie ein Multi-Disk-Gerät.
- Wählen Sie die Partitionen, die Sie für das MD-Gerät verwenden möchten. Für das erste MD-Gerät bestätigen Sie die Partitionen sda1 und sdb1.
- Es folgt jetzt bei Vorhandensein weiterer Partitionen eine erneute Abfrage, ob Sie ein MD-Gerät erstellen möchten. Bestätigen Sie diese, und wählen Sie die beiden verbliebenen Partitionen.

Abbildung 17.9 Wählen Sie die Partitionen, die Sie für das MD-Gerät verwenden wollen.

Abbildung 17.10 Eine Auflistung der MD-Geräte und der zugehörigen Partitionen
- Nach dem Fertigstellen erhalten Sie eine Übersicht Ihrer RAID-Arrays und der zugehörigen Partitionen. Wählen Sie nun die Partition des ersten RAID-Geräts, und aktivieren Sie sie, indem Sie die Option Nicht benutzen entfernen.
- Verfahren Sie im weiteren Verlauf wie bei einer »normalen« Installation, außer dass Sie jetzt die Zwischenschicht mit den MD-Geräten verwenden. Vergessen Sie nicht, einen definierten Einhängepunkt für die Partition anzugeben (/). Bei der zweiten Partition aktivieren Sie die Verwendung als Swap.
Paketsammlungen
Sie können bereits während der Installation einige wichtige Serverdienste auswählen und sich damit eine spätere manuelle Installation dieser Pakete ersparen. Diesen Schritt können Sie selbstverständlich auch überspringen – alle Serverdienste können Sie auch später installieren.
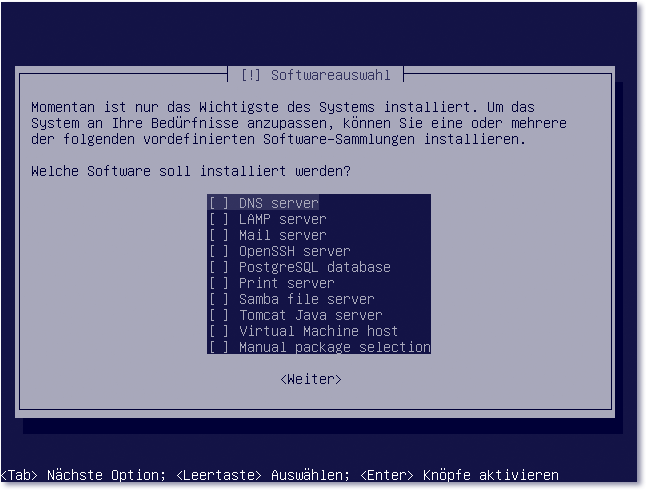
Abbildung 17.11 Auswahl von Serverdiensten
Einzelne Serverdienste wählen Sie durch Betätigen der Leertaste aus und bestätigen
dies durch Drücken der  -Taste. Es ist in diesem Schritt sinnvoll, den OpenSSH-Server auszuwählen. Die spätere
Installation von zusätzlichen Diensten können Sie dann aus der Entfernung durchführen.
-Taste. Es ist in diesem Schritt sinnvoll, den OpenSSH-Server auszuwählen. Die spätere
Installation von zusätzlichen Diensten können Sie dann aus der Entfernung durchführen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



