|
Wer seinen Horizont erweitert, verkleinert den Himmel.
– Klaus Kinski Kapitel 19 XML & Co.
Mit XML ist das so eine Sache: Das Format ist sehr einfach zu verstehen, einfach zu erstellen und auch einfach weiterzuverarbeiten. Allerdings hat es eine ganze Zeit gedauert, bis XML auch wirklich in der Praxis eingesetzt worden ist. Zu praktisch waren häufig proprietäre Binär-Formate. Doch mittlerweile ist XML überall: von Konfigurationsdateien bis hin zu Office-Dokumenten, alles kann mittlerweile mit XML realisiert werden.
Auch JavaScript unterstützt XML. Das liegt auch nahe, steht doch das »X« in AJAX für XML. Doch leider hat die Sache auch einen ganz großen Haken: Eine browserunabhängige XML-Unterstützung ist mit etwas Aufwand verbunden; einige exotischere Browser bleiben bei den im Folgenden gezeigten Techniken auch außen vor.
Dies führt in der Praxis zu folgender Situation: Häufig werden spezielle XML-Bibliotheken eingesetzt, die einfach XML-Funktionalität nachprogrammieren (sprich, einen XML-String von Hand parsen). Im AJAX-Bereich hat JSON mittlerweile XML den Rang abgelaufen. Wenn ein Webserver komplexe Daten schickt, tut er das meist nicht in XML, sondern in der JavaScript Object Notation.
Dieses Kapitel zeigt auf, wie XML-Daten mit JavaScript verarbeitet werden können. Auch einige verwandte XML-Themen, nämlich XSL und XPath, werden behandelt.
19.1 XML  
Aufgrund der strikten Regeln für den Aufbau eines XML-Dokuments ist es dort sehr einfach, das Document Object Model zu nutzen. Auch hier müssen Sie wieder in Knoten denken und in der Hierarchie navigieren.
19.1.1 XML-Daten verarbeiten 
Eine der Haupteinsatzgebiete für XML in JavaScript sind AJAX-Anwendungen: wenn der Server XML zurückliefert. Das XMLHttpRequest-Objekt ist in der Lage, die Rückgabe von einem Server direkt als XML-Objekt zu verwenden, inklusive sofortigen Zugriffs auf das XML-DOM.
Damit das funktioniert, muss allerdings eine Voraussetzung erfüllt sein: Der Server muss den MIME-Typ text/xml im HTTP-Header zurückliefern. Andererseits kann der Browser das XML nicht laden.
Dies lässt sich zum einen durch eine entsprechende Serverkonfiguration erreichen; im Apache-Server beispielsweise ist folgende Zeile in der Konfigurationsdatei mime.types einzufügen:
text/xml xml
Die folgende Datei soll in den Beispielen in diesem Kapitel verwendet werden – Sie kennen die dahinterliegenden Daten bereits aus dem vorherigen Kapitel:
<?xml version="1.0" encoding="UTF-8"?>
<links>
<link id="1">
<text>Mozilla</text>
<url>http://www.mozilla.com/</url>
</link>
<link id="2">
<text>Microsoft</text>
<url>http://www.microsoft.com/</url>
</link>
<link id="1">
<text>Opera</text>
<url>http://www.opera.com/</url>
</link>
</links>
Wenn der entsprechende MIME-Typ nicht geschickt wird (und die folgenden Beispiele nicht funktionieren), müssen Sie zu serverseitigen Mitteln greifen und per PHP oder ASP.NET oder mit einer anderen Technologie den HTTP-Header von Hand setzen. Bei Verwendung von PHP sorgt diese Anweisung (am Anfang der Seite!) dafür, dass der MIME-Typ geschickt wird:
<?php
header('Content-type: text/xml');
?>
Unter ASP.NET verwenden Sie folgenden Code:
<%@ Page Language="JScript" %>
<script runat="server">
function Page_Load() {
Response.ContentType = "text/xml";
}
</script>
Wenn Sie den PHP- oder ASP.NET-Weg gehen (müssen), müssen Sie die Dateinamen in den XMLHttpRequest-Abfragen in den folgenden Beispielen ebenfalls anpassen.
Die XML-Datei beziehungsweise die serverseitigen Skripte können Sie dann mit dem XMLHttpRequest-Objekt laden. Eine XMLHttpRequest-Eigenschaft haben wir aber bisher unter den Tisch fallen lassen: responseXML. Diese ermöglicht den Zugriff auf die zurückgegebenen XML-Daten, und das praktischerweise gleich als XML-Objekt, ohne weitere Konvertierung. Das vom Server gelieferte XML muss dazu nur valide sein, und der bereits angesprochene MIME-Typ muss stimmen.
Im Vergleich zum JavaScript-DOM bietet das XML-DOM vor allem zwei nützliche Erweiterungen: per documentElement greifen Sie auf den Wurzelknoten des Dokuments zu (eine gute Ausgangsbasis für Ausflüge im DOM-Baum), und xml liefert das XML-Markup als String zurück (gut für eigenes Parsen).
In Kapitel 16 haben Sie gesehen, wie Sie mit DOM-Methoden sehr schnell eine Aufzählungsliste oder eine Tabelle erstellen können. Das erste Beispiel wird jetzt mit XML nachgebaut.
Wie üblich werden die Daten per XMLHttpRequest-Objekt geladen; eine Callback-Funktion übernimmt dann die Weiterverarbeitung:
http.open("GET", "links.xml", true);
http.onreadystatechange = ausgeben;
http.send(null);
Der erste Schritt ist der Zugriff auf responseXML – das Ergebnis ist ein XML-Objekt:
var daten = http.responseXML;
Es gibt nun mehrere Möglichkeiten, die Daten im XML-Dokument weiterzuverarbeiten. Der wohl bequemste Weg besteht darin, per getElementsByTagName() auf alle <link>-Elemente zuzugreifen und dann die darunterliegenden Knoten zu analysieren.
var ergebnisse = daten.getElementsByTagName("link");
for (var i = 0; i < ergebnisse.length; i++) {
// ...
}
Im Inneren der Schleife schauen wir uns einfach jeden Knoten an. Die Eigenschaft nodeName dient dann zur Identifikation, welcher Knoten vorliegt. Apropos Knoten: Den Textinhalt eines Knotens erhalten Sie über die Eigenschaft firstChild.nodeValue: Das erste Kind eines Knotens ist der Textknoten innerhalb; nodeValue gibt dessen Text zurück.
with (datum.childNodes[j]) {
if (nodeName == "text") {
name = firstChild.nodeValue;
} else if (nodeName == "url") {
url = firstChild.nodeValue;
}
}
Die Variablen name und url enthalten nun die benötigten Daten; der folgende DOM-Code gibt sie dann aus:
var li = document.createElement("li");
var a = document.createElement("a");
a.setAttribute("href", url);
var txt = document.createTextNode(name);
a.appendChild(txt);
li.appendChild(a);
liste.appendChild(li);
Hier noch einmal der komplette Code im Überblick:
<html>
<head>
<title>AJAX</title>
<script type="text/javascript"><!--
var http = null;
if (window.XMLHttpRequest) {
http = new XMLHttpRequest();
} else if (window.ActiveXObject) {
http = new ActiveXObject("Microsoft.XMLHTTP");
}
window.onload = function() {
if (http != null) {
http.open("GET", "links.xml", true);
http.onreadystatechange = ausgeben;
http.send(null);
}
}
function ausgeben() {
if (http.readyState == 4) {
var liste = document.getElementById("Liste");
var daten = http.responseXML;
var ergebnisse = daten.getElementsByTagName("link");
for (var i = 0; i < ergebnisse.length; i++) {
var name, url;
var datum = ergebnisse[i];
for (var j = 0; j < datum.childNodes.length; j++) {
with (datum.childNodes[j]) {
if (nodeName == "text") {
name = firstChild.nodeValue;
} else if (nodeName == "url") {
url = firstChild.nodeValue;
}
}
}
var li = document.createElement("li");
var a = document.createElement("a");
a.setAttribute("href", url);
var txt = document.createTextNode(name);
a.appendChild(txt);
li.appendChild(a);
liste.appendChild(li);
}
}
}
//--></script>
</head>
<body>
<ul id="Liste"></ul>
</body>
</html>
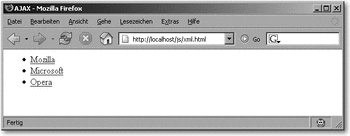
Hier klicken, um das Bild zu Vergrößern
Abbildung 19.1 Die dynamisch erzeugte Liste aus XML-Daten
Das ist recht viel Code, aber es funktioniert in allen Browsern. Doch damit sind wir leider am Ende des browserunabhängigen XML angekommen; die weiteren Technologien sind jeweils browserspezifisch beziehungsweise funktionieren nicht überall.
19.1.2 XML-Dokumente erstellen
Die Eigenschaft responseXML gibt also ein XML-Dokument zurück. Es gibt aber auch die Möglichkeit, aus einem String ein XML-Dokument zu erstellen. Leider haben die verschiedenen Browser etwas unterschiedliche Ansichten darüber, wie so etwas vonstatten gehen sollte. Und besonders gut dokumentiert ist das auch nicht.
Der Microsoft Internet Explorer setzt auf ActiveX. Das zu ladende Objekt heißt Microsoft.XMLDOM. Es kennt die Methode loadXML(), die sowohl eine XML-Datei als auch einen XML-String lädt:
var xml = new ActiveXObject("Microsoft.XMLDOM");
xml.loadXML(daten);
Bei Mozilla-Browsern sieht es anders aus. Sie benötigen ein spezielles Mozilla-JavaScript-Objekt: DOMParser. Dieses besitzt die Methode parseFromString(), die ein DOM-Dokument (also auch XML!) einlesen kann:
var xml = (new DOMParser()).parseFromString(
daten, "text/xml");
Damit ist das XML-Dokument erstellt, und das ist glücklicherweise auch das Ende des browserspezifischen Codes. Das vorherige Beispiel lässt sich also relativ einfach umschreiben und verwendet nicht mehr responseXML, sondern responseText und ein dynamisch erzeugtes XML-JavaScript-Objekt:
<html>
<head>
<title>AJAX</title>
<script type="text/javascript"><!--
var http = null;
if (window.XMLHttpRequest) {
http = new XMLHttpRequest();
} else if (window.ActiveXObject) {
http = new ActiveXObject("Microsoft.XMLHTTP");
}
window.onload = function() {
if (http != null) {
http.open("GET", "links.xml", true);
http.onreadystatechange = ausgeben;
http.send(null);
}
}
function ausgeben() {
if (http.readyState == 4) {
var liste = document.getElementById("Liste");
var daten = http.responseText;
if (window.ActiveXObject) {
var xml = new ActiveXObject("Microsoft.XMLDOM");
xml.loadXML(daten);
} else if (document.implementation) {
var xml = (new DOMParser()).parseFromString(daten, "text/xml");
}
var ergebnisse = xml.getElementsByTagName("link");
for (var i = 0; i < ergebnisse.length; i++) {
var name, url;
var datum = ergebnisse[i];
for (var j = 0; j < datum.childNodes.length; j++) {
with (datum.childNodes[j]) {
if (nodeName == "text") {
name = firstChild.nodeValue;
} else if (nodeName == "url") {
url = firstChild.nodeValue;
}
}
}
var li = document.createElement("li");
var a = document.createElement("a");
a.setAttribute("href", url);
var txt = document.createTextNode(name);
a.appendChild(txt);
li.appendChild(a);
liste.appendChild(li);
}
}
}
//--></script>
</head>
<body>
<ul id="Liste"></ul>
</body>
</html>
Die gute Nachricht: Opera hat Gefallen an der Mozilla-Implementierung von XML gefunden und unterstützt diesen Ansatz ebenfalls – allerdings erst ab Browser-Version 9.
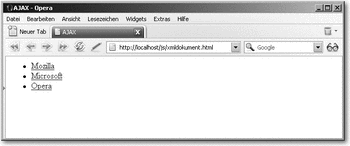
Hier klicken, um das Bild zu Vergrößern
Abbildung 19.2 Das Beispiel funktioniert auch im Opera
Noch ein wichtiger Hinweis zum vorherigen Listing: Beachten Sie, dass Sie mit window.onload arbeiten müssen, damit die XML-Datei erst geladen wird, wenn das gesamte HTML-Dokument übertragen worden ist. Andererseits kann es vor allem im Internet Explorer passieren, dass die Aufzählungsliste (<ul>) noch nicht im DOM-Baum vorhanden ist und das Skript dann nicht funktioniert.
|




 bestellen
bestellen


