


24 MySQL-Grundlagen
MySQL ist die Datenbank unserer Wahl. Die meisten Provider bieten diese Datenbank in Kombination mit PHP als Service an. Wir zeigen Ihnen den richtigen Umgang mit MySQL.
MySQL ist in der Standardversion kostenlos erhältlich und sehr leistungsfähig. Zu einer Datenbank gehören das Datenbanksystem und eine Möglichkeit, diese abzufragen. Die Abfrage erfolgt mit einer eigenen Sprache, kurz SQL (Structured Query Language) genannt. SQL ist sehr einfach gehalten, eine kurze Einführung gibt es am Ende dieses Kapitels. Die Arbeit an unserer Buchwebsite sollte damit kein größeres Problem darstellen.
24.1 Einführung in Datenbanken 

Bevor wir eine Datenbank abfragen können, muss sie zunächst angelegt werden. Wir können hier nicht sehr tief in diese Thematik einsteigen, das würde den Rahmen des Buches sprengen. Bei Galileo Press gibt es einige sehr gute Bücher zum Thema MySQL, die wir nur empfehlen können. Wir wollen uns in erster Linie auf die Anbindung von MySQL in Dreamweaver 8 konzentrieren.
Dennoch sind einige kurze Erläuterungen an dieser Stelle notwendig. Sehr vereinfacht gesagt besteht eine Datenbank aus folgenden Komponenten:
- ein Data Base Management System, das sie verwaltet
- die Datenbank selbst
- Tabellen, die sich in den Datenbanken in beliebiger Anzahl befinden
- Datensätze in Tabellen (jeder einzelne Datensatz wird als Tupel bezeichnet)
- Datenfelder in den Tabellen
Abbildung 24.1 zeigt, wie diese Komponenten zusammenhängen.
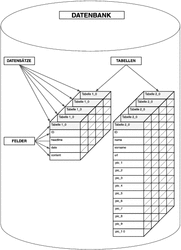
Abbildung 24.1 Allgemeiner Aufbau einer Datenbank
24.1.1 Relationale Datenbanken
MySQL und fast alle anderen modernen Datenbanken sind so genannte relationale Datenbanken. Diese bestehen aus den eben beschriebenen Tabellenstrukturen und Beziehungen (Relationen) zwischen den einzelnen Tabellen. Betrachten Sie Abbildung 24.2. In den Tabellen gibt es zunächst keine Verbindung zwischen Kunden und Produkten.
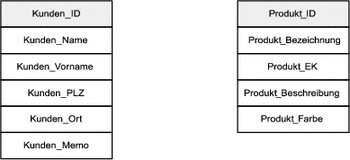
Abbildung 24.2 Eine einfache Datenstruktur für ein Shopsystem
Wir möchten erreichen, dass jeder Kunde Bestellungen ausführen und dabei beliebige Produkte bestellen kann. Diese bestellten Produkte sollen den Kunden zugeordnet werden können. Man könnte jetzt der Kundentabelle ein weiteres Feld für Bestellungen hinzufügen und die Produktbezeichnung darin abspeichern. Wenn der Kunde jedoch mehrere Produkte oder eines mehrfach bestellt, müsste für jeden Bestellvorgang ein weiteres Datenfeld angefügt werden. Dieses müsste für alle Kunden angelegt werden, da Felder immer in allen Datensätzen einer Tabelle erscheinen. Das wäre somit ziemlich umständlich.
Eine einfachere und bessere Lösung bietet das relationale Modell, das wir in Abbildung 24.3 skizziert zu haben.
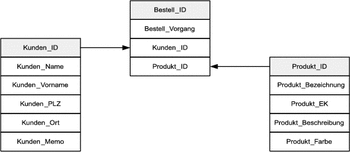
Abbildung 24.3 Relationale Datenbank mit Tabellen in der Relation n:m
Beziehungen herstellen | Es wird eine dritte Tabelle geschaffen, um die Beziehung zwischen den beiden anderen Tabellen zu definieren. In unserem Beispiel wird für jeden neuen Bestellvorgang ein neuer Datensatz angelegt. In diesem werden die Bestellnummer, die Kunden-ID und die Produkt-ID hinterlegt. Der Vorteil dieser Methode ist die wesentlich höhere Flexibilität. Für jede neue Beziehung zwischen Tabellen können Sie eine weitere Tabelle anlegen und bei Bedarf auch wieder löschen. An den eigentlichen Hauptdatensätzen muss keine Veränderung stattfinden.
24.1.2 Relationstypen
Es gibt drei verschiedene Arten von Relationen.
- n:m-Beziehungen: In unserem Beispiel bilden die Tabellen diese Art der Beziehung. Jeder Datensatz einer Tabelle kann mit beliebig vielen Datensätzen einer anderen Tabelle eine Beziehung bilden.
- 1:1-Beziehungen: Diese Beziehung definiert, dass jeder Datensatz einem anderen Datensatz zugehörig ist bzw. sein darf.
- 1:n-Beziehungen: Bei dieser Beziehung kann ein Datensatz mit beliebig vielen (n) Datensätzen einer anderen Tabelle verbunden sein, aber nicht umgekehrt.
24.1.3 Primärschlüssel
Um mit relationalen Datenbanken zu arbeiten, müssen Datensätze eindeutig definiert sein. Das erreicht man mit einem Primärschlüssel.
Primärschlüssel angeben | Der Primärschlüssel ist eine Zahl, die automatisch beim Anlegen eines neuen Datensatzes hoch gezählt (auto-inkrementiert) und mit dem jeweiligen Datensatz gespeichert wird.
Ein Feld in einer Datenbank muss eindeutig als Primärschlüssel ausgewiesen werden. In unserem Beispiel sind die Datensätze Kunden_ID, Produkt_ID und Bestell_ID die Primärschlüssel. Für die Bestimmung von Primärschlüsseln sind folgende zwingende Vorgaben zu beachten:
- Primärschlüssel müssen immer einen Inhalt haben.
- In jeder Tabelle wird nur ein Feld als Primärschlüssel deklariert.
- Vom Primärschlüssel darf es keine Duplikate geben.
24.1.4 Redundanzfreiheit
Damit die eben erwähnten Bedingungen erfüllt werden, muss sichergestellt werden, dass jeder Datensatz nur einmal vorkommt. Die dabei häufigste Fehlerquelle ist mit großem Abstand der Mensch. Schnell wird der Kunde Maier noch einmal als Mayer oder Meier gespeichert, und die Eindeutigkeit ist verloren. Wenn zu erwarten ist, dass solche Probleme auftreten, müssen Sie bereits bei der Eingabe Vorkehrungen treffen, indem Sie zum Beispiel identische Namen, Adressen etc. überprüfen.
24.1.5 Prozessdatenfreiheit
Vermeiden Sie unter allen Umständen das Abspeichern berechneter Werte. Nehmen Sie als Beispiel einen Kunden, und Sie möchten sein Alter als Datensatz hinterlegen. Wenn Sie jetzt sein Alter real abspeichern, zum Beispiel 40 Jahre, stimmt dieser Wert nächstes Jahr bereits nicht mehr. Hinterlegen Sie in diesem Fall das Geburtsdatum, und errechnen Sie das Alter außerhalb der Datenbank immer aufs Neue. Prozessdaten gehören nicht in eine Datenbank!
24.1.6 Fremdschlüssel
In der Tabelle für den Bestellvorgang finden sich die Inhalte der Primärschlüssel aus den beiden anderen Tabellen wieder. Diese eingefügten Werte aus Primärschlüsseln dritter Tabellen bezeichnet man als Fremdschlüssel. Fremdschlüssel bilden die eigentliche Beziehung der Tabellen zueinander.
24.1.7 Referenzielle Integrität
Aus Relationen kann sich allerdings auch ein Problem ergeben. Stellen Sie sich vor, ein Kunde hat 100 Bestellungen über einen längeren Zeitraum aufgegeben. Nun wird eines der Produkte gelöscht oder der Preis verändert. Der erste Fall, die Löschung, würde eine Anfrage mit einem Verweis auf ein nicht mehr vorhandenes Produkt ergeben. Im zweiten Fall, der wesentlich fataler ist, würde eine nachträgliche Kundenumsatzberechnung völlig falsche Ergebnisse liefern. Die Gewährleistung, dass solche Fehler nicht auftreten, nennt man referenzielle Integrität.
Fehler wie der geschilderte sind unter allen Umständen zu vermeiden, und durch entsprechende Programmierung ist Abhilfe zu schaffen. Das ist jedoch ein sehr komplexes Thema. Leider bietet MySQL keine integrierte Unterstützung dafür an, und Sie müssen sich mit Workarounds in PHP behelfen.
Bei einem WCMS spielt dies keine große Rolle. Wenn Sie jedoch ein Shopsystem mit Bestellverwaltung programmieren wollen, sehr wohl. Das ist auch einer der Gründe, warum wir Anfängern vor dem Programmieren eines Shopsystems nur warnen können.
| MySQL 5.0 unterstützt Trigger |
| Trigger sind programmierbare Automatismen, um Bezüge von Datensätzen zu überprüfen und um die referenzielle Integrität sicherzustellen. Da MySQL 5.0 gerade erst (Stand Oktober 2005) neu erschienen ist, können wir auf diese komplexe Thematik hier nicht eingehen und verweisen auf die Dokumentation und geeignete Fachliteratur. |
24.1.8 Endlosschleifen
Im Bereich dynamischer Menüführung tritt ein weiteres Problem auf. Möchten Sie in Ihrem CMS die Menüpunkte frei definieren und beliebig zuweisen, kann es vorkommen, dass sich folgendes Szenario abspielt:
- B ist ein Unterpunkt von A
- C ist ein Unterpunkt von B
- A ist ein Unterpunkt von C
Weil A aber einen Unterpunkt hat, nämlich B, würde eine Abfrage nie zu einem Ergebnis kommen, sondern immer im Kreis laufen.
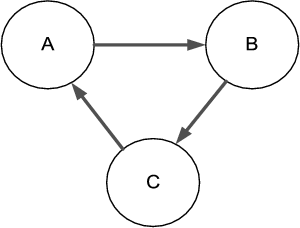
Abbildung 24.4 Endlosschleife von A nach B nach C
Solche Fehler müssen vermieden werden. Die einfachste Möglichkeit dafür ist, die Anzahl der Schleifendurchläufe zu ermitteln und nach einem einzigen Durchlauf zu stoppen. Ansonsten werden die Datensätze unendlich oft ausgegeben.
24.1.9 MySQL-Datentypen
Jedem einzelnen Datenfeld, wie z. B. name, muss ein bestimmter Datentyp zugeordnet werden. Dieser soll dem Inhalt des Feldes möglichst entsprechen. Die exakte Datendefinition ermöglicht es, die Datenbank nicht größer werden zu lassen als nötig, da jeder Feldinhalt einen durch den Datentyp definierten Speicherplatz benötigt. Weiterhin werden Fehler durch nicht eindeutige Datentypen vermieden.
Mit der Definition des Datentyps wird etwa definiert, ob eine 1 als eine Zahl oder ein Zeichen behandelt werden soll. Wenn Sie ein Feld als Zahl definieren, können darin keine abweichenden Zeichen wie Buchstaben oder Symbole gespeichert werden.
MySQL unterstützt die Datentypen aus der folgenden Tabelle:
| Zahlenformate | |
|
TINYINT |
|
|
SMALLINT |
|
|
MEDIUMINT |
|
|
INT |
|
|
BIGINT |
|
|
FLOAT |
|
|
DOUBLE |
|
|
DEZIMAL |
|
| Zeichenformate | |
|
VARCHAR (n) |
|
|
CHAR (n) |
|
|
TINYTEXT |
|
|
MEDIUMTEXT |
|
|
TEXT |
|
|
LONGTEXT |
|
| Binäre Datentypen | |
|
BLOB |
|
|
TINYBLOB |
|
|
MEDIUMBLOB |
|
|
LONGBLOB |
|
| Zeit- und Datumsformate | |
|
DATE |
|
|
TIME |
|
|
TIMESTAMP |
|
|
DATETIME |
|
|
YEAR |
|
| Aufzählungen | |
|
ENUM |
|
|
SET |
|
Tabelle 24.1 MySQL-Datentypen
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



