


14.7 Navigation durch XML (XPath)
14.7.1 Die Klasse »XPathNavigator«
Der XmlReader ermöglicht nur eine Vorwärtsbewegung durch ein XML-Dokument. In manchen Situationen mag das durchaus genügen, aber häufig wird man nach bestimmten Elementen und den von Ihnen beschriebenen Daten suchen und dabei wahlfrei navigieren wollen. Hierbei werden wir von einem Objekt vom Typ XPathNavigator unterstützt, das zum Namensraum System.Xml.XPath gehört. Mit einem XPathNavigator können Sie zum Beispiel auch rückwärts navigieren und darüber hinaus Suchmuster angeben, die ein Filtern der Daten ermöglichen. Diese Suchmuster werden als XPath-Ausdrücke bezeichnet. Die XPathNavigator-Klasse unterstützt die Funktionen von XPath 2.0.
Das hört sich sehr positiv an, ist aber mit einem Nachteil verbunden, denn das ganze XML-Dokument muss zuerst in den Speicher geladen werden. Sie müssen also einen Verlust an Performance und je nach Größe des XML-Dokuments auch eine vergleichsweise hohe Speicherbelastung akzeptieren.
Ein XPathNavigator kann ausgehend von
- einem XPathDocument-Objekt oder
- einem XmlDocument-Objekt
mit der Methode CreateNavigator erstellt werden. Ein XPathDocument-Objekt dient nur dem schnellen Einlesen eines XML-Dokuments, die Daten sind schreibgeschützt und erlauben keinerlei weitere Verarbeitung. Daten hingegen, die ein XmlDocument-Objekt zur Verfügung stellt, können auch verändert werden. Auf die zahlreichen Möglichkeiten, die sich hinter XmlDocument verbergen, kommen wir im nächsten Kapitel zu sprechen.
Um die Vorteile eines XPathNavigator-Objekts nutzen zu können, benötigen Sie zuerst ein XPathDocument-Objekt (oder alternativ ein XmlDocument-Objekt). Dem Konstruktor können Sie den Pfad zu der XML-Datei oder einen Stream übergeben, der die XML-Daten liefert. Anschließend rufen Sie die Methode CreateNavigator auf, die die Referenz auf ein XPathNavigator-Objekt liefert.
XPathDocument xPathDoc = new XPathDocument(@"D:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
Jetzt können die Methoden des XPathNavigator-Objekts zur Navigation des im Speicher befindlichen XML-Dokuments benutzt werden. Dabei gilt es, zwei Techniken zu unterscheiden:
- Navigation mit den Move-Methoden
- Navigation unter Zuhilfenahme von XPath-Ausdrücken
Die zahlreichen Move-Methoden gestatten die beliebige Navigation durch ein XML-Dokument. Allerdings ist der Code insbesondere bei komplexen XML-Strukturen oft nur schwierig nachvollziehbar. Greifen Sie auf XPath-Ausdrücke zurück, wird der Code kürzer und hat dabei auch noch den Vorteil, nach mehreren Elementen gleichzeitig suchen zu können. Nachteilig dabei ist, dass der Einsatz von XPath-Ausdrücken voraussetzt, dass Sie sich zuvor mit der Syntax von XPath anfreunden. Eine Einführung dazu erhalten Sie später.
Navigieren mit den »Move«-Methoden
XPathNavigator verfolgt ein cursorbasiertes Modell, bei dem eine Art Zeiger immer auf einen Knoten im XML-Dokument zeigt. Ausgehend von dem aktuellen Knoten, der auch als Kontextknoten bezeichnet wird, kann man mit einer der zahlreichen Methoden beliebig durch das Dokument navigieren.
An dieser Stelle alle Methoden und Eigenschaften eines XPathNavigator-Objekts vollständig zu beschreiben, würde den Rahmen sprengen. Daher möchte ich mich auf ein paar wenige Navigationsmethoden beschränken, um ein Gefühl dafür zu vermitteln, welche Möglichkeiten in dieser Klasse stecken.
| Methode | Beschreibung |
|
MoveTo |
Dieser Methode wird eine XPathNavigator-Instanz übergeben, die auf dem Knoten positioniert ist, zu dem der aktuelle Knoten wechseln soll. |
|
MoveToFirstAttribute |
Verschiebt den XPathNavigator beim Überschreiben in einer abgeleiteten Klasse auf das erste Attribut des aktuellen Knotens. |
|
MoveToAttribute |
Verschiebt den XPathNavigator zu dem Attribut mit dem angegebenen Namen und Namespace-URI. |
|
MoveToRoot |
Verschiebt die Position des Cursors auf den Stammknoten. |
|
MoveToFirst |
Verschiebt den Cursor auf den ersten nebengeordneten Knoten des aktuellen Knotens. Der Rückgabewert ist true, wenn es einen nebengeordneten Knoten gibt, ansonsten false. |
|
MoveToNext |
Verschiebt den Cursor auf den nächsten nebengeordneten Knoten des aktuellen Knotens. Der Rückgabewert ist true, wenn es einen nebengeordneten Knoten gibt, ansonsten false. |
|
MoveToPrevious |
Verschiebt den Cursor auf den vorhergehenden nebengeordneten Knoten des aktuellen Knotens. Der Rückgabewert ist true, wenn es einen nebengeordneten Knoten gibt, ansonsten false. |
|
MoveToChild |
Verschiebt den Cursor auf den angegebenen untergeordneten Knoten. Der Rückgabewert ist true, wenn es den untergeordneten Knoten gibt, ansonsten false. |
|
MoveToFirstChild |
Verschiebt den Cursor auf den ersten untergeordneten Knoten des aktuellen Knotens. Der Rückgabewert ist true, wenn es einen untergeordneten Knoten gibt, ansonsten false. |
|
MoveToFollowing |
Verschiebt den Cursor auf das Element mit dem angegebenen lokalen Namen oder einen bestimmten XPathNodeType. |
|
MoveToParent |
Verschiebt den Cursor auf den übergeordneten Knoten des aktuellen Knotens. Der Rückgabewert ist true, wenn die Aktion erfolgreich durchgeführt werden konnte, ansonsten false. |
Wie Sie durch ein XML-Dokument navigieren, möchte ich Ihnen nun in Einzelschritten zeigen. Dabei dient wieder die Datei Personen.xml als Basis der einzulesenden XML-Struktur. Nachdem Sie sich ein XPathNavigator-Objekt mit
XPathDocument xPathDoc = new XPathDocument(@"D:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
besorgt haben, müssen Sie den Cursor zuerst auf das Stammelement des XML-Dokuments positionieren. Dazu bieten sich die Methoden MoveToFollowing oder MoveToFirstChild an. Der Methode MoveToFollowing müssen Sie dabei ausdrücklich den Bezeichner des Stammelements übergeben, gegebenenfalls auch noch den Namespace-URI.
navigator.MoveToFollowing("Personen", "");
Einfacher ist die Handhabung der Methode MoveToFirstChild, die parameterlos ist.
navigator.MoveToFirstChild();
Damit steht der Cursor auf dem Stammelement Personen. Um zum ersten untergeordneten Knoten Person zu navigieren, muss MoveToFirstChild ein weiteres Mal aufgerufen werden.
Das Element Person hat mehrere untergeordnete Elemente. Möchte man diese der Reihe nach durchlaufen, muss der Cursor zuerst auf das erste untergeordnete, also Vorname positioniert werden. Das bedeutet bereits den dritten Aufruf der Methode MoveToFirstChild hintereinander. Alle nebengeordneten Elemente Zuname, Alter und Adresse erhält man über jeweils einen Aufruf der Methode MoveToNext.
Zeigt der Cursor auf einen Person-Knoten, müssen Sie nicht alle Elemente Vorname, Zuname und Alter abrufen, um Adresse auszuwerten. Sie können dazu auch die Methode MoveToChild bemühen, der Sie den Bezeichner des gewünschten Elements sowie dessen Namespace-URI angeben.
navigator.MoveToChild("Adresse", "http://www.MyNS.de");
Ist das entsprechende Element keinem Namensraum zugeordnet, übergeben Sie eine leere Zeichenfolge.
Beispielprogramm
Sehen wir uns nun ein komplettes Beispiel an, in dem ein XML-Dokument vollständig durchlaufen wird. Dabei wird eine rekursive Programmiertechnik benutzt, die alle Knoten des Dokuments auswertet. Die Methode Navigate hat die Aufgabe, durch das Dokument zu navigieren, WriteNode gibt die Knotenbezeichner und die von ihnen beschriebenen Werte aus.
// Beispiel: ..\Kapitel 14\XPathNavigatorSample
static void Main(string[] args) {
XPathDocument doc = new XPathDocument(@"..\..\Personen.xml");
XPathNavigator navi = doc.CreateNavigator();
// Zum Stammknoten navigieren
navi.MoveToRoot();
Navigate(navi);
Console.ReadLine();
}
// Methode, die durch die Knoten navigiert
static void Navigate(XPathNavigator navi) {
WriteNode(navi);
// Verschiebt den Cursor auf den ersten untergeordneten Knoten
if (navi.MoveToFirstChild()) {
// Verschiebt den Cursor zum nächsten nebengeordneten Knoten
do {
Navigate(navi);
} while (navi.MoveToNext());
navi.MoveToParent();
}
}
// Methode zur Ausgabe an der Konsole
static void WriteNode(XPathNavigator navi) {
switch (navi.NodeType)
{
case XPathNodeType.Element:
if (navi.HasAttributes) {
Console.Write("<" + navi.Name + " ");
navi.MoveToFirstAttribute();
do {
Console.Write(navi.Name + "=" + navi.Value + " ");
} while (navi.MoveToNextAttribute());
Console.WriteLine(">");
navi.MoveToParent();
}
else {
Console.WriteLine("<" + navi.Name + ">");
}
break;
case XPathNodeType.Text:
Console.WriteLine(navi.Value);
break;
}
}
Listing 14.35 Beispielprogramm mit der Klasse »XPathNavigator«
14.7.2 XPath-Ausdrücke
XPath ist eine Entwicklung des W3-Konsortiums und dient dazu, nach einem oder mehreren Knoten in einer XML-Struktur zu suchen. XPath wird normalerweise im Zusammenhang mit anderen Standards eingesetzt und stellt eine XML-Struktur als einen Baum dar, der aus Knoten besteht. Die Lokalisierung eines oder mehrerer Knoten ähnelt der Notation einer URL – vermutlich stammt auch daher der Name XPath. Für die effiziente Arbeit mit XML ist XPath unabdingbar. Daher wollen wir uns in diesem Abschnitt auch ein wenig mit der XPath-Spezifikation beschäftigen. Dabei auf jedes Detail einzugehen, würde den Rahmen sprengen. Wenn Sie aber über diesen Abschnitt hinaus nach weiteren Informationen suchen, finden Sie diese unter http://www.w3.org/TR/xpath/.
Aber wie sieht ein XPath-Ausdruck aus? Nehmen wir an, Sie interessieren sich für alle Zunamen in dem XML-Dokument, das durch die Datei Personen.xml beschrieben wird. Mit dem folgenden Codefragment können Sie das bereits erreichen.
XPathDocument xPathDoc = new XPathDocument(@"..\..\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
navigator.MoveToFirstChild();
XPathNodeIterator iterator = navigator.Select("//Zuname");
while (iterator.MoveNext())
{
Console.WriteLine(iterator.Current.Value);
}
Listing 14.36 Einfache Navigation mit XPath
Hätten Sie nur die Methoden der Klasse XPathNavigator benutzt, wäre der Code deutlich aufwendiger ausgefallen. Der XPath-Ausdruck //Zuname vereinfacht den Zugriff auf die Zunamen sehr deutlich.
Wie bereits erwähnt, stellt XPath eine XML-Dokumentstruktur als Baum dar. Dabei gibt es verschiedene Knotentypen, zum Beispiel Elementknoten, Textknoten oder Attributknoten. Die Lokalisierung der verschiedenen Ebenen besteht aus maximal drei Teilen:
- eine Achse, die zum Navigieren innerhalb der XML-Struktur dient
- eine Knotenprüfung, um weitere Kriterien zu definieren; damit lassen sich bestimmte Knoten selektieren
- einem Prädikat, um die selektierten Knoten weiter filtern zu können
Die Angaben von Achse und Knotenprüfung sind vorgeschrieben, während ein Prädikat optional ist. Die allgemeine Syntax eines XPath-Ausdrucks lautet:
achse::knotenprüfung[prädikat]
Beschreibt ein XPath-Ausdruck ein Prädikat, dann wird dieses in eckige Klammern eingeschlossen.
14.7.3 Der Kontextknoten
Das Resultat einer XPath-Abfrage hängt davon ab, von wo die Suche gestartet wird. Startet die Suche beim Wurzelelement, kann das Ergebnis ein ganz anderes sein, als würde die Suche bei einem Unterelement beginnen. Daher ist das Startelement von ganz wesentlicher Bedeutung. XPath verwendet das Konzept eines sogenannten Kontextknotens. Dieser Kontextknoten ist der aktuelle Knoten, an dem die Suche gestartet wird.
Die Achsen
Bei der Ausführung einer XPath-Abfrage kann eine bestimmte Richtung vorgeschrieben werden. Diese wird als Achse bezeichnet. Eine Analogie findet sich im Dateisystem, denn Sie können beispielsweise mit »..« zum übergeordneten Verzeichnis wechseln.
Da einige Achsen sehr häufig benötigt werden, besitzen sie eine Abkürzung. In der folgenden Tabelle sind die wichtigsten Achsen beschrieben.
| Achse | Beschreibung |
|
attribute |
Hiermit werden die Attribute des Kontextknotens bestimmt. (Abkürzung: @) |
|
child |
Mit dieser Achse werden die dem Kontextknoten untergeordneten Elemente (Nachkommen) beschrieben. |
|
descendant |
Irgendein untergeordnetes Element des Kontextknotens. Dabei kann es sich auch um einen Nachkommen über zwei oder mehr Ebenen handeln. |
|
descendant-or-self |
Wie descendant, jedoch unter Einbeziehung des Kontextknotens. (Abkürzung: //) |
|
following |
Mit dieser Achse werden die Knoten angesprochen, die sich auf der Ebene des Kontextknotens befinden und diesem nachfolgen. Zu der Ergebnismenge gehören auch die untergeordneten Elemente der gefundenen Knoten. |
|
parent |
Das dem Kontextknoten übergeordnete Element. (Abkürzung: ..) |
|
preceding |
Vorherige Knoten des Kontextknotens auf gleicher Ebene, einschließlich der ihnen untergeordneten Knoten. |
In XPath steht das Pfad-Trennzeichen »/« für tatsächliche Namen von Knoten. Beginnt ein XPath-Ausdruck nicht mit »/« oder »//«, beginnt die Suche immer an der aktuellen Cursorposition. Die Suche beschränkt sich dann auf die Elemente des Teils der XML-Struktur, der an der Cursorposition beginnt.
Knotenprüfungen
Ein weiteres Kriterium zur Filterung eines Elements können Sie nach der Angabe der Achse festlegen. Es handelt sich um die Knotenprüfung, die anhand der Achse eine Auswahl der zu selektierenden Elemente trifft. Die Angabe der Prüfung kann direkt der Elementname sein.
| Knotentyp | Beschreibung |
|
node() |
Es werden alle Knoten, auch unter Einbeziehung von Namensraum- und Attributsknoten, ausgewählt. |
|
comment() |
Auswahl eines Kommentarknotens. |
|
text() |
Auswahl von Knoten, die einen Text enthalten. |
|
processing-instruction() |
Auswahl der Prozessoranweisungen im XML-Dokument. |
Prädikate
Auf allen Knoten, die die Ergebnismenge nach der Achsenbestimmung und der Knotenprüfung bilden, können Sie spezielle Prädikate anwenden, um die selektierten Knoten weiter zu filtern:
- Logische Operatoren: or, and, !, <, >, <=, >=, =, !=
- Arithmetische Operatoren: +, -, div, *, mod
Da die Zeichen »<« und »>« in XML eine besondere Bedeutung haben, müssen Sie sie durch < sowie > ersetzen.
14.7.4 Beispiele mit XPath-Ausdrücken
Nachfolgend zeige ich Ihnen einige XPath-Ausdrücke und deren Ergebnismenge. Alle Beispiele basieren auf einem XML-Dokument, in dem insgesamt vier Person-Elemente definiert sind und zusätzlich noch das Element Mitarbeiter. Das Stammelement lautet auch hier Personen.
<Personen>
<Person>
<Vorname>Manfred</Vorname>
<Zuname>Fischer</Zuname>
<Alter>45</Alter>
<Adresse Ort="Bonn" Strasse="Neuestr.34"></Adresse>
</Person>
[...]
<Mitarbeiter>
<Vorname>Peter</Vorname>
<Zuname>Goldbach</Zuname>
<Position>Chef</Position>
</Mitarbeiter>
</Personen>
Listing 14.37 Zugrunde liegendes XML-Dokument für XPath-Ausdrücke
Beispiel 1: Die Auswertung des folgenden Positionspfades liefert alle Person- und Mitarbeiter-Elemente, einschließlich der den Elementen Person und Mitarbeiter untergeordneten Elemente, jedoch ohne die Attribute. In der Ergebnisliste steht nur ein Gesamtergebnis. Das Ergebnis ist unabhängig von der Cursorposition.
//Personen
Die Achse »//« ist sehr nützlich, um Elemente unabhängig von ihrer Position in der Struktur zu finden.
Beispiel 2: Zum gleichen Ergebnis führt auch der Ausdruck
/Personen
Zu keinem Ergebnis führt jedoch die Auswertung des folgenden Aufrufs, da hier die Angabe des Stammelements fehlt:
/Person
Anders hingegen das nächste Beispiel. Der Ausdruck beschreibt alle Person-Elemente, unabhängig von deren Position innerhalb der XML-Struktur. In der Ergebnisliste steht für jede Person ein separates Resultat. Da das XML-Dokument vier Personen beschreibt, liegen somit auch vier Teilergebnisse vor.
//Person
Möchten Sie vielleicht auf ein bestimmtes Person-Element zugreifen, dessen Position Sie im XML-Dokument kennen? Der nächste XPath-Ausdruck liefert das dritte Person-Element zurück.
//Person[3]
XPath unterstützt auch Platzhalter. Der folgende Ausdruck wählt alle Elemente aus, die dem Stammelement Personen untergeordnet sind. Es liegen auch hier fünf Resultate in der Ergebnismenge vor, da sowohl Person als auch Mitarbeiter ausgewertet werden. Besonders sinnvoll ist der Ausdruck, wenn dem Stammelement mehrere verschiedene Elemente untergeordnet sind und alle in der Ergebnismenge stehen sollen.
/Personen/*
Den Platzhalter können Sie auch angeben, um auf die Attribute des Elements Adresse zuzugreifen.
/Personen/Person/Adresse/@*
Interessieren hingegen nur die Werte, die durch das Attribut Ort beschrieben werden, geben Sie den Attributsbezeichner anstelle des Platzhalters an.
/Personen/Person/Adresse/@Ort
Nehmen wir nun an, der Positionscursor zeige auf das erste Element Person in der XML-Struktur. Mit dem XPath-Ausdruck
Vorname
wird als Ergebnis Manfred ausgegeben. Wird explizit keine Achse angegeben, gilt child als Vorgabe. Somit führt der gezeigte Ausdruck zum gleichen Ergebnis wie
child::Vorname
Hätte der Cursor eine andere Position eingenommen, wäre die Ergebnismenge leer.
Unabhängig von der Cursorposition wird der nächste XPath-Ausdruck alle Vornamen ausgeben, da er gleichbedeutend mit dem XPath-Ausdruck Vorname ist:
//child::Vorname
Mit
/child::Vorname
bleibt die Ergebnismenge jedoch leer.
Mit optionalen Prädikaten lassen sich Ergebnismengen weiter filtern. Sie sind Teil des Positionspfades, der in eckigen Klammern erscheint. Der nächste Ausdruck verwendet ein Prädikat, um die Auswahl der Person-Elemente auf die Personen einzugrenzen, deren Alter größer 40 ist.
//Person[Alter > 40]
Sehr ähnlich wird mit dem folgenden Ausdruck gefiltert. Hierbei interessieren uns alle Personen, die in Bonn wohnen. Da der Ort als Attribut definiert ist, muss auf den Attributinhalt zugegriffen werden.
//Person/Adresse[@Ort = 'Bonn']
Prädikate dürfen gemäß XPath-Spezifikation auch mit and oder or verknüpft werden. Im folgenden XPath-Ausdruck werden die beiden zuvor gezeigten Ausdrücke benutzt, um alle Person-Elemente zu finden, die sowohl älter als 40 sind als auch in Bonn wohnen.
//Person[Alter > 40 and Adresse[@Ort = 'Bonn']]
XPath unterstützt integrierte Funktionen, die häufig in Prädikaten verwendet werden. Die Auswertung des folgenden Ausdrucks ergibt alle Person-Elemente, deren Vorname mit dem Buchstaben »P« beginnt.
//Person[starts-with(Vorname, 'P')]
Zum Abschluss der XPath-Beispiele möchte ich Ihnen noch zeigen, wie der Ausdruck lauten muss, um nach allen Personen innerhalb der XML-Struktur zu suchen, deren Zuname »Schmidt« oder »Meier« lautet.
//Zuname[text()='Meier' or text()='Schmidt']
Die bis hier gezeigten Beispiele können vielleicht einen Eindruck darüber vermitteln, wie mächtig XPath-Ausdrücke formuliert werden können. Hier alle Möglichkeiten zu zeigen, ist aus Platzgründen nicht möglich. Für das weitere Vorgehen und das Verständnis der folgenden Beispiele reichen die Ausführungen aber aus. Wenn Sie intensiver in das Thema XPath einsteigen wollen, empfiehlt es sich, einen Blick in die Originalspezifikation zu werfen, deren Link Sie am Anfang des Kapitels finden.
14.7.5 Knotenmengen mit der »Select«-Methode
In Abschnitt 14.7.1 haben Sie gesehen, wie Sie mit den Methoden der Klasse XPathNavigator durch die Struktur einer XML-Vorlage navigieren können. Mit den Kenntnissen von XPath-Ausdrücken ausgestattet lässt sich ein XPathNavigator-Objekt aber noch effektiver einsetzen.
Um einen XPath-Ausdruck gegen ein XML-Dokument abzusetzen, steht Ihnen die Methode Select zur Verfügung. Das Ergebnis des Methodenaufrufs ist eine Menge von Knoten, die von einem XPathNodeIterator-Objekt beschrieben werden. Der XPathNodeIterator ist zunächst auf dem Kontextknoten positioniert, der Ausgangspunkt der XPath-Abfrage ist. Um zum ersten Knoten in der Ergebnismenge zu gelangen, muss daher zuerst MoveNext auf das Iterator-Objekt aufgerufen werden. MoveNext eignet sich sehr gut, um in einer Schleife eingesetzt zu werden, da der Rückgabewert true ist, falls noch ein weiterer Knoten in der Ergebnismenge vorliegt.
XPathDocument xPathDoc = new XPathDocument(@"C:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
XPathNodeIterator iter = navigator.Select("//Person");
while (iter.MoveNext()) {
Console.WriteLine(iter.Current.Value);
}
Listing 14.38 Navigieren zum ersten Knoten mit »MoveNext«
Die Eigenschaft Current des Iterators ist schreibgeschützt und liefert ein neues XPathNavigator-Objekt, das auf das aktuelle XML-Element in der Ergebnismenge zeigt:
public XPathNavigator Current {get;}
Current ist nicht nur wichtig für die Auswertung des gefundenen Knotens, sondern kann darüber hinaus auch Ausgangspunkt für weitere Suchoperationen sein.
Das XPathNodeIterator-Objekt hat neben Current noch zwei weitere interessante Eigenschaften: Count und CurrentPosition. Count liefert die Anzahl der Knoten in der Ergebnismenge und CurrentPosition den Index der aktuellen Position in der Ergebnismenge. Aber Vorsicht, denn der Index ist nicht 0-basiert, sondern 1-basiert. Der Index 0 gibt nämlich an, dass keine Knoten ausgewählt sind.
Ändern des Kontextknotens
Das XPathNavigator-Objekt, auf das die Select-Methode aufgerufen worden ist, ändert seine Position auch dann nicht, wenn die Ergebnismenge durchlaufen wird. Der Kontextknoten bleibt also gleich. Wenn der XPath-Ausdruck nicht mit »/« oder »//« beginnt, beginnt die Suche nach den Elementen an der aktuellen Cursorposition des XPathNavigator-Objekts.
Um die Cursorposition auf eines der Suchergebnisse zu setzen, können Sie anstatt der Methode Select die Methode SelectSingleNode des XPathNavigator-Objekts einsetzen. Der Rückgabewert ist ein neues XPathNavigator-Objekt, das Sie der MoveTo-Methode übergeben.
bool result = navigator.MoveTo(navigator.SelectSingleNode("XPath-Ausdruck"));
Der Aufruf liefert true, wenn die Position des Navigators verschoben werden konnte, bei false bleibt die Cursorposition unverändert.
Weitere »Select«-Methoden
Neben Select gibt es mit
- SelectAncestors
- SelectChildren
- SelectDescendants
noch drei weitere Varianten zur Filterung von XML-Elementen. SelectAncestors wählt alle übergeordneten Knoten des aktuellen Knotens aus, SelectChildren alle direkt untergeordneten Knoten und SelectDescendants ausnahmslos alle untergeordneten Knoten. Allen drei genannten Methoden können Sie bestimmte Kriterien für die Filterung übergeben: Entweder Sie geben den Namen des gesuchten Elements an oder den Knotentyp (XmlNodeType).
Das folgende Beispiel zeigt, wie die genannten Select-Methoden benutzt werden können. Als Grundlage dazu dient uns die Datei Personen.xml, die jedoch um das zusätzliche Element Geschlecht ergänzt worden ist, das Zuname untergeordnet ist.
<Person>
<Vorname>Manfred</Vorname>
<Zuname>Fischer
<Geschlecht>Männlich</Geschlecht>
</Zuname>
<Alter>45</Alter>
<Adresse Ort="Bonn" Strasse="Neuestr.34"></Adresse>
</Person>
Listing 14.39 XML-Dokument für das Listing 14.40
Hier nun der Code des Beispielprogramms:
// Beispiel: ..\Kapitel 14\SelectSample
static void Main(string[] args) {
string trenner = new string('-', 45);
XPathDocument doc = new XPathDocument("..\\..\\Personen.xml");
XPathNavigator navigator = doc.CreateNavigator();
navigator.MoveToChild("Personen","");
navigator.MoveToChild("Person", "");
// Alle untergeordneten Elemente einer 'Person'
XPathNodeIterator descendant =
navigator.SelectDescendants("", "", false);
Console.WriteLine("Alle untergeordneten Elemente von 'Person':");
Console.WriteLine(trenner);
while (descendant.MoveNext()) {
Console.WriteLine(descendant.Current.Name);
}
// Alle direkt untergeordneten Elemente einer 'Person'
XPathNodeIterator children = navigator.SelectChildren("", "");
Console.WriteLine("\nDirekt untergeordnete Elemente von 'Person':");
Console.WriteLine(trenner);
while (children.MoveNext()) {
Console.WriteLine(children.Current.Name);
}
// Die übergeordneten Elemente von 'Zuname'
navigator.MoveToChild("Zuname", "");
XPathNodeIterator ancestors = navigator.SelectAncestors("", "", false);
Console.WriteLine("\nÜbergeordnete Elemente von 'Zuname':");
Console.WriteLine(trenner);
while (ancestors.MoveNext()) {
Console.WriteLine(ancestors.Current.Name);
}
Console.ReadLine();
}
Listing 14.40 Das Beispielprogramm »SelectSample«
Als Grundlage der Select-Methoden wird jeweils die Überladung benutzt, die im ersten Parameter den Knotenbezeichner erwartet. Gibt man eine leere Zeichenfolge an, werden der Ergebnismenge alle gefundenen Knoten hinzugefügt. Der zweite Parameter erwartet den Namespace-URI. Da in unserem XML-Dokument kein Namespace definiert ist, wird hier eine leere Zeichenfolge übergeben. Der dritte Parameter der Methoden SelectAncestors und SelectDescendants schließlich erwartet einen booleschen Wert, der angibt, ob der aktuelle Knoten (der Kontextknoten) in die Ergebnismenge aufgenommen werden soll. In beiden Fällen wurde unter Angabe von false darauf verzichtet.
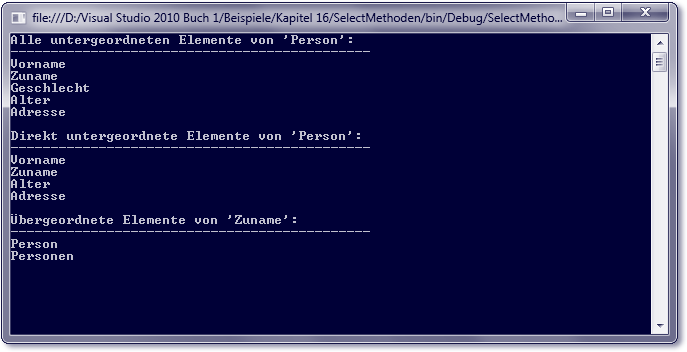
Abbildung 14.6 Ergebnisliste des Beispiels »SelectSample«
Kompilieren von XPath-Ausdrücken
Bei der Filterung von Knoten mit XPath-Ausdrücken führt der Parser immer wieder eine Analyse und Optimierung der Abfrage durch. Bei Abfragen, die wiederholt verwendet werden, bedeutet das eine Leistungseinbuße. Um dem zu begegnen, besitzen die Methoden, die einen XPath-Ausdruck akzeptieren, auch eine Überladung für einen kompilierten Ausdruck, der durch XPathExpression dargestellt wird. Dazu zählt auch Select.
Ein XPathExpression-Objekt erhalten Sie als Rückgabewert der statischen Methode Compile der Klasse XPathExpression.
public static XPathExpression Compile(string xpath)
Der Einsatz eines kompilierten XPath-Ausdrucks kann insbesondere bei komplexen Ausdrücken eine durchaus deutliche Steigerung der Abfrageleistung bringen.
XPathDocument xPathDoc = new XPathDocument(@"D:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
XPathExpression xpathExpr = XPathExpression.Compile("//Person");
XPathNodeIterator iter = navigator.Select(xpathExpr);
while (iter.MoveNext()) {
Console.WriteLine(iter.Current.Value);
}
Listing 14.41 Kompilierter XPath-Ausdruck
14.7.6 Auswerten von XPath-Ausdrücken
Die Methode »Evaluate«
Bisher habe ich Ihnen nur gezeigt, wie Sie mit XPath-Ausdrücken eine auf Knoten basierende Ergebnismenge auswerten können. XPath-Ausdrücke ermöglichen es aber auch, Berechnungen auszuführen. Dabei hilft die Methode Evaluate des XPathNavigator-Objekts weiter:
public virtual Object Evaluate(string xpath)
Es gibt weitere Überladungen, die auch ein XPathExpression- oder XPathNodeIterator-Objekt entgegennehmen.
Dazu sofort ein Beispiel. Angenommen, Sie interessieren sich für das Durchschnittsalter aller Personen, die in der Datei Personen.xml beschrieben werden. Der XPath-Ausdruck dazu lautet:
sum(//Alter) div count(//Alter)
Die Funktion sum liefert die Summe der in der Ergebnismenge //Alter enthaltenen Werte, und count liefert die Anzahl der zurückgegebenen Ergebnisse aus der Abfrage //Alter. Die Funktion div ist der Divisionsoperator.
string xPath = "sum(//Alter) div count(//Alter)";
XPathDocument xPathDoc = new XPathDocument(@"D:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
double result = Convert.ToDouble(navigator.Evaluate(xPath));
Console.WriteLine("Durchschnittsalter = {0}",result);
Listing 14.42 Die Methode »Evaluate«
Da der Rückgabewert von Evaluate vom Typ Object ist, muss noch in den passenden Typ konvertiert werden.
Die Methode »Matches«
Mit der Methode Matches können Sie feststellen, ob der aktuelle Knoten des XPathNavigators einem bestimmten XPath-Ausdruck entspricht.
public virtual bool Matches(string xpath)
Matches akzeptiert auch einen kompilierten XPath-Ausdruck vom Typ XPathExpression.
Im folgenden Codefragment wird untersucht, ob der Cursor das Personen-Element beschreibt. Der Rückgabewert ist in diesem Fall true, da zuvor mit MoveToFirstChild zum Stammelement des XML-Dokuments navigiert wird.
XPathDocument xPathDoc = new XPathDocument(@"D:\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
navigator.MoveToFirstChild();
Console.WriteLine(navigator.Matches("//Personen").ToString());
Listing 14.43 Die Methode »Matches«
Namensräume
In nahezu jedem XML-Dokument wird die Technik der Namensräume benutzt, um Elemente eindeutig zuordnen zu können. XPathNavigator unterstützt mit mehreren Eigenschaften und Methoden die Namensräume.
| Eigenschaft/Methode | Beschreibung |
|
LocalName |
(Eigenschaft) Ruft den Bezeichner des aktuellen Knotens ohne Namespace-Präfix ab. Die ähnliche Eigenschaft Name liefert den Bezeichner samt Präfix. |
|
NamespaceURI |
(Eigenschaft) Ruft den Namespace-URI des aktuellen Knotens ab. |
|
Prefix |
(Eigenschaft) Ruft das Namespace-Präfix des aktuellen Knotens ab. |
|
GetNamespacesInScope |
(Methode) Gibt alle im Gültigkeitsbereich befindlichen Namespaces des aktuellen Knotens zurück. |
|
LookupNamespace |
(Methode) Ruft den Namespace-URI für das angegebene Präfix ab. |
|
LookupPrefix |
(Methode) Ruft das Namespace-Präfix für das angegebene |
|
MoveToFirstNamespace |
(Methode) Verschiebt den XPathNavigator auf den ersten Namespace-Knoten des aktuellen Knotens. |
|
MoveToNextNamespace |
(Methode) Verschiebt den XPathNavigator auf den nächsten Namespace-Knoten des aktuellen Knotens. |
Die Eigenschaften LocalName, NamespaceURI und Prefix sind schon vom XmlReader her bekannt und werden auf dem aktuellen Knoten ausgewertet. LookupNamespace und LookupPrefix liefern Informationen, die das gesamte XML-Dokument betreffen, aber nur auf ein Präfix oder einen Namensraum bezogen sind.
Die Methode GetNamespacesInScope müssen wir uns noch genauer ansehen, da ihr Einsatz etwas komplexer ist. Die Methode liefert alle Namespaces, die sich im Gültigkeitsbereich des aktuellen Knotens befinden. Ist der Navigator auf das Stammelement positioniert, handelt es sich folgerichtig um alle Namespaces des XML-Dokuments. Der Rückgabewert der Methode ist eine generische Collection, in der die einzelnen Elemente über ein Key-Value-Paar beschrieben werden. Jeder Namespace-Eintrag wird in der Collection durch den Typ KeyValuePair<string, string> beschrieben.
Sie müssen GetNamespacesInScope mitteilen, ob die gelieferte Liste gefiltert werden soll. Dazu übergeben Sie der Methode ein Argument vom Typ der Enumeration XmlNamespaceScope.
| Enumerationswert | Beschreibung |
|
All |
Liefert alle Namespaces, die sich im Gültigkeitsbereich des aktuellen Knotens befinden. Dies beinhaltet auch den xmlns:xml-Namespace, der immer implizit deklariert wird. |
|
ExcludeXml |
Liefert alle Namespaces, die im Gültigkeitsbereich des aktuellen Knotens definiert sind. Davon ausgeschlossen ist der xmlns:xml-Namespace, der immer implizit deklariert ist. |
|
Local |
Liefert alle Namespaces, die am aktuellen Knoten lokal definiert sind. |
Im folgenden Codefragment wird die Liste der Namespaces eines XML-Dokuments abgefragt, ohne den impliziten xmlns:xml-Namespace zu berücksichtigen.
IDictionary<string, string> liste =
navi.GetNamespacesInScope(XmlNamespaceScope.ExcludeXml);
foreach (KeyValuePair<string, string> temp in liste)
Console.WriteLine("Key: {0,-3} Value: {1}", temp.Key, temp.Value);
Listing 14.44 Liste aller Namespaces abfragen
Alternativ zu GetNamespacesInScope bieten sich auch die Methoden MoveToFirstNamespace und MoveToNextNamespace an, die beide auf den aktuellen Knoten bezogen sind. Beide Methoden liefern einen booleschen Wert zurück, der true ist, wenn der XPathNavigator auf den ersten bzw. nächsten Namespace positioniert werden kann.
if (navigator.MoveToFirstNamespace())
do {
Console.WriteLine("Präfix: {0} - Namespace: {1} ",
navigator.Name, navigator.Value);
} while (navigator.MoveToNextNamespace());
Beachten Sie, dass ein Präfix mit der Eigenschaft Name ausgewertet wird und der zugehörige Namensraum mit der Eigenschaft Value.
Namespaces in XPath-Ausdrücken
Eine etwas andere Behandlung erfahren die Namespaces, die in XPath-Ausdrücken verwendet und korrekt ausgewertet werden sollen. Grundsätzlich verlangt die XPath-Syntax, dass vor dem Elementnamen das Präfix angegeben wird, also:
Präfix:Elementbezeichner
Eine Überladung der Select-Methode des XPathNavigators berücksichtigt genau diesen Fall und schreibt ein Objekt mit IXmlNamespaceResolver vor. Diese Schnittstelle wird von der Klasse XmlNamespaceManager implementiert. Sie müssen also nur ein Objekt dieses Typs der Select-Methode übergeben.
Ein XmlNamespaceManager verwaltet alle Namespaces und die ihnen zugeordneten Präfixe. Dabei müssen die Elemente, die sich im Standardnamensraum befinden, besonders behandelt werden, denn in XML-Dokumenten ist diesen Elementen kein Präfix vorangestellt. Die XPath-Syntax verlangt aber auch in diesem Fall ein Präfix. Daher ist es erforderlich, dass Sie auch diesen Elementen ein Präfix zuordnen.
Das folgende Beispiel zeigt, wie Sie die Klasse XmlNamespaceManager einsetzen und einen Standard-Namespace definieren können. Beachten Sie dabei, dass jeder gefundene Namespace explizit dem XmlNamespaceManager-Objekt mit AddNamespace hinzugefügt werden muss.
// Beispiel: ..\Kapitel 14\XPathWithNamespaces
static void Main(string[] args)
{
XPathDocument xPathDoc = new XPathDocument(@"..\..\Personen.xml");
XPathNavigator navigator = xPathDoc.CreateNavigator();
// XmlNamespaceManager instanziieren
XmlNamespaceManager mgr = new XmlNamespaceManager(new NameTable());
navigator.MoveToRoot();
if (navigator.MoveToChild(XPathNodeType.Element)) {
foreach (KeyValuePair<string, string> temp in
navigator.GetNamespacesInScope(XmlNamespaceScope.All))
// Namespaces zum XmlNamespaceManager hinzufügen
if (temp.Key == "")
mgr.AddNamespace("default", temp.Value);
else
mgr.AddNamespace(temp.Key, temp.Value);
}
// Ausgabe aller Person-Elemente, die dem durch 'x'
// beschriebenen Namespace zugeordnet werden
XPathNodeIterator iterator = navigator.Select("//x:Person", mgr);
while (iterator.MoveNext()) {
Console.WriteLine(iterator.Current.Value);
}
Console.ReadLine();
}
Listing 14.45 Beispielprogramm »XPathWithNamespaces«
Die verwendete Personen.xml ist in diesem Fall:
<?xml version="1.0" encoding="utf-8"?>
<x:Personen xmlns="http://www.MyDefaultNS.de"
xmlns:x="http://www.MyNS.de">
<x:Person>
<x:Zuname>Kleynen</x:Zuname>
<x:Vorname>Peter</x:Vorname>
<Adresse Ort="Eifel" Strasse="Am Wald 1">Germany</Adresse>
</x:Person>
</x:Personen>
Listing 14.46 Das in Listing 14.45 verwendete XML-Dokument
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



