

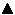
33.3 Datenbanken 
Je mehr Daten ein Programm verwalten muss und je komplexer die Struktur dieser Daten wird, desto größer wird der programmtechnische Aufwand für die dauerhafte Speicherung und Verwaltung der Daten. Außerdem müssten Aufgaben wie das Lesen, Schreiben oder Aktualisieren von Daten, die in vielen Programmen benötigt werden, immer wieder neu implementiert werden.
Abhilfe für diese Problematik wird geschaffen, indem man eine Abstraktionsschicht zwischen dem benutzenden Programm und dem physikalischen Massenspeicher einzieht, die sogenannte Datenbank. Dabei erfolgt die Kommunikation zwischen Benutzerprogramm und Datenbank über eine vereinheitlichte Schnittstelle.
Abbildung 33.2 Die Datenbankschnittstelle
Das Datenbanksystem nimmt Abfragen, sogenannte Querys, entgegen und gibt alle Datensätze zurück, die den Bedingungen der Abfragen genügen.
Wir beschäftigen uns in diesem Kapitel ausschließlich mit relationalen Datenbanken, die einen Datenbestand in Tabellen organisieren.[ 140 ](Das Attribut »relational« geht auf den Begriff der Relation aus der Mathematik zurück. Vereinfacht gesagt, ist eine Relation eine Zuordnung von Elementen zweier oder mehrerer Mengen in Form einer Tabelle. ) Für die Abfragen in relationalen Datenbanken wurde eine eigene Sprache entwickelt, deren Name SQL (Structured Query Language, dt. »strukturierte Abfragesprache») ist. SQL ist zu komplex, um es in diesem Kapitel erschöpfend zu beschreiben. Wir werden hier nur auf grundlegende SQL-Befehle eingehen, die nötig sind, um das Prinzip von Datenbanken und deren Anwendung in Python zu verdeutlichen.
SQL ist standardisiert und wird von den meisten relationalen Datenbanksystemen unterstützt. Beachten Sie dabei, dass die Systeme häufig nur Teilmengen der Sprache implementieren und sie teilweise geringfügig abändern. Aus diesem Grund werden wir Ihnen hier die SQL-Variante vorstellen, die von SQLite, der Standarddatenbank in Python, genutzt wird.
[»] Hinweis
Neben der Abfragesprache SQL ist in Python auch die Schnittstelle der Datenbankmodule standardisiert. Dies hat für den Programmierer den angenehmen Nebeneffekt, dass sein Code mit minimalen Anpassungen auf allen Datenbanksystemen lauffähig ist, die diesen Standard implementieren. Die genaue Definition dieser sogenannten Python Database API Specification können Sie in PEP 249 nachlesen.
Bevor wir uns aber mit der Abfragesprache SQL selbst beschäftigen, erarbeiten wir eine kleine Beispieldatenbank und überlegen, welche Operationen man überhaupt ausführen kann. Anschließend implementieren wir dieses Beispiel mithilfe von SQLite und gehen dabei auf Teile der Abfragesprache SQL und die Verwendung in Python-Programmen ein.
Stellen Sie sich vor, Sie müssten das Lager eines Computerversands verwalten. Sie sind dafür verantwortlich, dass die gelieferten Teile an der richtigen Stelle im Lager aufbewahrt werden, wobei für jede Komponente der Lieferant, der Lieferzeitpunkt und die Nummer des Fachs im Lager gespeichert werden sollen. Für Kunden, die bei dem Versand ihre Rechner bestellen, werden die entsprechenden Teile reserviert, und diese sind dann für andere Kunden nicht mehr verfügbar. Außerdem sollen Sie Listen mit allen Kunden und Lieferanten der Firma bereitstellen.
Um ein Datenbankmodell für dieses Szenario zu erstellen, legen Sie zuerst eine Tabelle namens »Lager« an, die alle im Lager befindlichen Komponenten enthält. Sie gehen der Einfachheit halber davon aus, dass Ihr Lager in Fächer eingeteilt ist, die fortlaufend nummeriert sind. Dabei kann jedes Fach nur ein einzelnes Computerteil aufnehmen.
Eine entsprechende Tabelle mit ein paar Beispieldatensätzen für das Lager könnte dann wie folgt aussehen, wenn Sie zusätzlich den Lieferanten und den Reservierungsstatus speichern möchten.
| Fachnummer | Seriennummer | Komponente | Lieferant | Reserviert |
|---|---|---|---|---|
| 1 | 26071987 | Grafikkarte Typ 1 | FC | 0 |
| 2 | 19870109 | Prozessor Typ 13 | LPE | 57 |
| 10 | 06198823 | Netzteil Typ 3 | FC | 0 |
| 25 | 11198703 | LED-Lüfter | FC | 57 |
| 26 | 19880105 | Festplatte 128 GB | LPE | 12 |
Tabelle 33.4 Tabelle »Lager« für den Lagerbestand
Die Spalte »Lieferant« enthält dabei das Kürzel der liefernden Firma, und das Feld »Reserviert« ist auf »0« gesetzt, wenn der betreffende Artikel noch nicht von einem Kunden reserviert wurde. Ansonsten enthält das Feld die Kundennummer des reservierenden Kunden. In der Tabelle werden nur die belegten Fächer gespeichert, weshalb alle Fächer, für die kein Eintrag existiert, mit neuen Teilen gefüllt werden können.
Die ausführlichen Informationen zu Lieferanten und Kunden werden in zwei weiteren Tabellen namens »Lieferanten« und »Kunden« abgelegt:
| Kurzname | Name | Telefonnummer |
|---|---|---|
| FC | FiboComputing Inc. | 011235813 |
| LPE | LettgenPetersErnesti | 026741337 |
| GC | Golden Computers | 016180339 |
Tabelle 33.5 Tabelle »Lieferanten«
| Kundennummer | Name | Anschrift |
|---|---|---|
| 12 | Heinz Elhurg | Turnhallenstr. 1, 3763 Sporthausen |
| 57 | Markus Altbert | Kämperweg 24, 2463 Duisschloss |
| 64 | Steve Apple | Podmacstr. 2, 7467 Iwarhausen |
Tabelle 33.6 Tabelle »Kunden«
Damit Sie als Lagerverwalter von dieser Datenbank profitieren können, müssen Sie die Möglichkeit haben, den Datenbestand zu manipulieren. Sie brauchen Routinen, um neue Kunden und Lieferanten hinzuzufügen, ihre Daten beispielsweise bei einem Umzug zu aktualisieren oder sie auf Wunsch aus Ihrer Datenbank zu entfernen. Auch in die Tabelle »Lager« müssen Sie neue Einträge einfügen und alte löschen oder anpassen. Um die Datenbank aktuell zu halten, benötigen Sie also Funktionen zum Hinzufügen und Löschen.
Wirklich nützlich wird die Datenbank aber erst, wenn Sie die enthaltenen Daten nach bestimmten Kriterien abfragen können. Im einfachsten Fall möchten Sie beispielsweise einfach nur eine Liste aller Kunden oder Lieferanten anfordern oder sich informieren, welche Fächer zurzeit belegt sind. Es könnte Sie aber auch interessieren, ob der Kunde mit dem Namen »Markus Altbert« Artikel reserviert hat und – wenn ja – welche Artikel das sind und wo diese gelagert werden; oder Sie möchten wissen, welche Komponenten Sie von dem Lieferanten mit der Telefonnummer »011235813« nachbestellen müssen, weil sie nicht mehr vorhanden oder bereits reserviert sind. Bei diesen Operationen werden immer Datensätze nach bestimmten Kriterien ausgewählt und an das aufrufende Benutzerprogramm zurückgegeben.
Nach dieser theoretischen Vorbereitung werden wir uns nun der Implementation des Beispiels in einer SQLite-Datenbank zuwenden.
33.3.1 Pythons eingebaute Datenbank – sqlite3
SQLite ist ein einfaches Datenbanksystem, das im Gegensatz zu anderen Systemen ohne separaten Datenbankserver auskommt und die gesamte Datenbank in einer einzigen Datei abspeichert. Die Programmbibliothek von SQLite ist nur einige Hundert Kilobyte groß, wodurch sie sich besonders für eingebettete Systeme eignet.
Trotzdem unterstützt SQLite einen Großteil der Sprache SQL und hat sich in der Praxis in puncto Skalierbarkeit und Geschwindigkeit bewährt.[ 141 ](Beispielsweise verwendet Apple SQLite in der Software für das iPhone, und der populäre Browser Firefox verwaltet damit Lesezeichen und Cookies. )
In Python müssen Sie das Modul sqlite3 importieren, um mit der Datenbank zu arbeiten. Anschließend können Sie eine Verbindung zu der Datenbank aufbauen, indem Sie die connect-Funktion, die ein Connection-Objekt zu der Datenbank zurückgibt, aufrufen und ihr den Dateinamen für die Datenbank übergeben:
import sqlite3
connection = sqlite3.connect("lagerverwaltung.db")
Die Dateiendung kann frei gewählt werden und hat keinerlei Einfluss auf die Funktionsweise der Datenbank. Der oben dargestellte Code führt dazu, dass die Datenbank, die in der Datei lagerverwaltung.db im selben Verzeichnis wie das Programm liegt, eingelesen und mit dem Connection-Objekt connection verbunden wird. Wenn es noch keine Datei mit dem Namen lagerverwaltung.db gibt, wird eine leere Datenbank erzeugt und die Datei angelegt.
Oft benötigt man eine Datenbank nur während des Programmlaufs, um Daten zu verwalten oder zu ordnen, ohne dass diese dauerhaft auf der Festplatte gespeichert werden müssen. Zu diesem Zweck gibt es die Möglichkeit, eine Datenbank im Arbeitsspeicher zu erzeugen, indem Sie anstelle eines Dateinamens den String ":memory:" an die connect-Methode übergeben:
connection = sqlite3.connect(":memory:")
Um mit der verbundenen Datenbank zu arbeiten, werden sogenannte Cursors (dt. »Positionsanzeigen«) verwendet. Einen Cursor können Sie sich ähnlich wie den blinkenden Strich in Textverarbeitungsprogrammen als aktuelle Bearbeitungsposition innerhalb der Datenbank vorstellen. Mit solchen Cursors können wir Datensätze verändern oder abfragen, wobei es zu einer Datenbankverbindung beliebig viele Cursors geben kann. Ein neuer Cursor wird mithilfe der cursor-Methode des Connection-Objekts erzeugt:
cursor = connection.cursor()Neue Tabellen anlegen
Nun können wir unser erstes SQL-Statement an die Datenbank schicken, um unsere Tabellen anzulegen. Für das Anlegen der Tabelle »Lager« sieht das SQL-Statement folgendermaßen aus:
CREATE TABLE lager (
fachnummer INTEGER, seriennummer INTEGER, komponente TEXT,
lieferant TEXT, reserviert INTEGER
)
[»] Hinweis
Alle großgeschriebenen Wörter sind Bestandteile der Sprache SQL. Allerdings unterscheidet SQL nicht zwischen Groß- und Kleinschreibung, weshalb wir auch alles hätten kleinschreiben können. Wegen der besseren Lesbarkeit werden wir SQL-Schlüsselwörter immer komplett groß- und von uns vergebene Namen durchgängig kleinschreiben.
Die Zeichenketten INTEGER und TEXT hinter den Spaltennamen geben den Datentyp an, der in den Spalten gespeichert werden soll. Sinnvollerweise werden die Spalten fachnummer, seriennummer und reserviert als Ganzzahlen und die Spalten komponente und lieferant als Zeichenketten definiert. SQLite kennt mehrere solcher Datentypen für die Spalten der Datenbank.
Standardmäßig werden Python-Datentypen beim Schreiben in eine SQLite-Datenbank automatisch in entsprechende SQLite-Datentypen umgewandelt. Tabelle 33.7 zeigt das Umwandlungsschema von Python- zu SQLite-Datentypen.
| Python-Datentyp (Quelltyp) | SQLite-Datentyp (Zieltyp) |
|---|---|
| None | NULL |
| int | INTEGER |
| float | REAL |
| str | TEXT |
| bytes | BLOB |
Tabelle 33.7 So konvertiert SQLite beim Schreiben der Daten.
Es ist auch möglich, andere Datentypen in SQLite-Datenbanken abzulegen, wenn entsprechende Konvertierungsfunktionen definiert wurden. Wie das genau erreicht werden kann, wird im Abschnitt »Adapter und Konvertierer« behandelt.
Nun senden wir das SQL-Statement mithilfe der execute-Methode des Cursor-Objekts an die SQLite-Datenbank:
cursor.execute("""CREATE TABLE lager (
fachnummer INTEGER, seriennummer INTEGER,
komponente TEXT, lieferant TEXT, reserviert INTEGER)""")
Die Tabellen für die Lieferanten und Kunden erzeugen wir auf die gleiche Weise:
cursor.execute("""CREATE TABLE lieferanten (
kurzname TEXT, name TEXT, telefonnummer TEXT)""")
cursor.execute("""CREATE TABLE kunden (
kundennummer INTEGER, name TEXT, anschrift TEXT)""")
Daten in die Tabellen einfügen
Als Nächstes werden wir die noch leeren Tabellen mit unseren Beispieldaten füllen. Zum Einfügen neuer Datensätze in eine bestehende Tabelle dient das INSERT-Statement, das für den ersten Beispieldatensatz folgendermaßen aussieht:
INSERT INTO lager VALUES (
1, 26071987, 'Grafikkarte Typ 1', 'FC', 0
)
Innerhalb der Klammern hinter VALUES stehen die Werte für jede einzelne Spalte in der gleichen Reihenfolge, wie auch die Spalten selbst definiert wurden. Wie bei allen anderen Datenbankabfragen auch können wir mit der execute-Methode unser Statement abschicken:
cursor.execute("""INSERT INTO lager VALUES (
1, 26071987, 'Grafikkarte Typ 1', 'FC', 0)""")
Beim Einfügen von Datensätzen müssen Sie allerdings beachten, dass die neuen Daten nicht sofort nach dem Ausführen eines INSERT-Statements in die Datenbank daten geschrieben werden, sondern vorerst nur im Arbeitsspeicher liegen. Um sicherzugehen, dass die Daten wirklich auf der Festplatte landen und damit dauerhaft gespeichert sind, müssen Sie die commit-Methode des Connection-Objekts aufrufen:
connection.commit()Dies ist deshalb notwendig, damit die Datenbank transaktionssicher ist. Transaktionen sind Ketten von Operationen, die vollständig ausgeführt werden müssen, damit die Konsistenz der Datenbank erhalten bleibt. Stellen Sie sich einmal vor, bei einer Bank würde während einer Überweisung zwar das Geld von Ihrem Konto abgebucht, jedoch aufgrund eines Fehlers nicht dem Empfänger gutgeschrieben. Mit der Methode rollback können alle Operationen seit dem letzten commit-Aufruf wieder rückgängig gemacht werden, um solche Probleme zu vermeiden.
Um die Konsistenz der Datenbank sicherzustellen, können Sie kritische Datenbankmanipulationen mit einer try-except-Anweisung umgeben und im Fehlerfall die Änderungen mit rollback als Ganzes verwerfen.
try:
cursor = connection.cursor()
cursor.execute("""INSERT INTO lager VALUES (
1, 26071987, 'Grafikkarte Typ 1', 'FC', 0)""")
# Hier können andere Datenbankmanipulationen stehen
connection.commit()
except:
print("Ein Problem trat auf -> Rollback")
connection.rollback()
Alternativ können Sie das connection-Objekt als Transaktionsmanager zusammen mit der with-Anweisung verwenden, um kritische Bereiche abzusichern. Dabei sorgt die with-Anweisung automatisch dafür, dass beim erfolgreichen Ausführen aller Zeilen im with-Block ein Commit und im Fehlerfall ein Rollback ausgeführt wird. Allerdings werden auftretende Exceptions an die nächsthöhere Ebene durchgereicht und müssen dort abgefangen werden. Das Beispiel oben lässt sich folgendermaßen mit with umsetzen:
try:
with connection:
cursor = connection.cursor()
cursor.execute("""INSERT INTO lager VALUES (
1, 26071987, 'Grafikkarte Typ 1', 'FC', 0)""")
# Hier können andere Datenbankmanipulationen stehen
except:
print("Ein Problem trat auf -> Automatischer Rollback")
Mehr zur with-Anweisung erfahren Sie in Abschnitt 24.1.
Zur Verbesserung der Übersichtlichkeit werden wir in den Beispielen auf Fehlerbehandlungen und Absicherungen verzichten.
Sicherer Datentransfer
In der Regel werden die Daten, die wir in die Datenbank einfügen wollen, nicht schon vor dem Programmlauf bekannt sein und deshalb auch nicht in Form von String-Konstanten im Quellcode stehen. Stattdessen werden es Benutzereingaben oder Berechnungsergebnisse sein, die wir dann als Python-Instanzen im Speicher haben. Auf den ersten Blick scheint für solche Fälle die Formatierungsmethode format für Strings ein geeignetes Mittel zu sein, und die letzte INSERT-Anweisung hätte auch folgendermaßen zusammengebaut werden können:
>>> werte = (1, 26071987, "Grafikkarte Typ 1", "FC", 0)
>>> "INSERT INTO lager VALUES ({}, {}, '{}', '{}', {})".format(*werte)
"INSERT INTO lager VALUES (1, 26071987, 'Grafikkarte Typ 1', 'FC', 0)"
Diese auf den ersten Blick elegante Methode entpuppt sich bei genauer Betrachtung aber als gefährliche Sicherheitslücke. Betrachten wir einmal folgende INSERT-Anweisung, die einen neuen Lieferanten in die Tabelle »Lieferanten« einfügen soll:
>>> werte = ("DR", "Danger Electronics",
... "666'); Hier kann Schadcode stehen")
>>> "INSERT INTO lieferanten VALUES ('{}', '{}', '{}')".format(*werte)
"INSERT INTO lieferanten VALUES ('DR', 'Danger Electronics', '666'); Hier kann Schadcode stehen')"
Wie Sie sehen, haben wir dadurch, dass der Wert für die Telefonnummer den String "');" enthält, die SQL-Abfrage verunstaltet, sodass der Versuch, sie auszuführen, zu einem Fehler führen und damit unser Programm zum Absturz bringen würde. Durch den außerdem enthaltenen Text "Hier kann Schadcode stehen" haben wir angedeutet, dass es unter Umständen sogar möglich ist, eine Abfrage so zu manipulieren, dass wieder gültiger SQL-Code dabei herauskommt, wobei jedoch eine andere Operation als beabsichtigt (zum Beispiel das Auslesen von Benutzerdaten) ausgeführt wird.[ 142 ](Man nennt diese Form des Angriffs auf verwundbare Programme auch SQL Injection. )
[»] Hinweis
Verwenden Sie deshalb niemals die String-Formatierung zur Übergabe von Parametern in SQL-Abfragen!
Um sichere Parameterübergaben durchzuführen, schreiben Sie in den Query-String an die Stelle, an der der Parameter stehen soll, ein Fragezeichen und übergeben der execute-Methode ein Tupel mit den entsprechenden Werten als zweiten Parameter:
werte = ("DR", "Danger Electronics",
"666'); Hier kann Schadcode stehen")
sql = "INSERT INTO lieferanten VALUES (?, ?, ?)"
cursor.execute(sql, werte)
In diesem Fall kümmert sich SQLite darum, dass die übergebenen Werte korrekt umgewandelt werden und es nicht zu Sicherheitslücken durch böswillige Parameter kommen kann.
Analog zur String-Formatierung gibt es auch hier die Möglichkeit, den übergebenen Parametern Namen zu geben und anstelle der tuple-Instanz mit einem Dictionary zu arbeiten. Dazu schreiben Sie im Query-String anstelle des Fragezeichens einen Doppelpunkt, gefolgt von dem symbolischen Namen des Parameters, und übergeben das passende Dictionary als zweiten Parameter an execute:
werte = {"kurz" : "DR", "name" : "Danger Electronics",
"telefon" : "123456"}
sql = "INSERT INTO lieferanten VALUES (:kurz, :name, :telefon)"
cursor.execute(sql, werte)Mit diesem Wissen können wir unsere Tabellen elegant und sicher mit Daten füllen:
for row in ((1, "2607871987", "Grafikkarte Typ 1", "FC", 0),
(2, "19870109", "Prozessor Typ 13", "LPE", 57),
(10, "06198823", "Netzteil Typ 3", "FC", 0),
(25, "11198703", "LED-Lüfter", "FC", 57),
(26, "19880105", "Festplatte 128 GB", "LPE", 12)):
cursor.execute("INSERT INTO lager VALUES (?,?,?,?,?)", row)
connection.commit()
Strukturen wie die oben dargestellte for-Schleife, die die gleiche Datenbankoperation sehr oft für jeweils andere Daten durchführen, kommen häufig vor und bieten großes Optimierungspotenzial. Aus diesem Grund haben cursor-Instanzen zusätzlich die Methode executemany, die als zweiten Parameter eine Sequenz oder ein anderes iterierbares Objekt erwartet, das die Daten für die einzelnen Operationen enthält. Wir nutzen executemany, um unsere Tabellen »Lieferanten« und »Kunden« mit Daten zu füllen:
lieferanten = (("FC", "FiboComputing Inc.", "011235813"),
("LPE", "LettgenPetersErnesti", "026741337"),
("GC", "Golden Computers", "016180339"))
cursor.executemany("INSERT INTO lieferanten VALUES (?,?,?)",
lieferanten)
kunden = ((12, "Heinz Elhurg",
"Turnhallenstr. 1, 3763 Sporthausen"),
(57, "Markus Altbert",
"Kämperweg 24, 2463 Duisschloss"),
(64, "Steve Apple",
"Podmacstr 2, 7467 Iwarhausen"))
cursor.executemany("INSERT INTO kunden VALUES (?,?,?)", kunden)
connection.commit()
Nun haben Sie gelernt, wie Sie Datenbanken und Tabellen anlegen und diese mit Daten füllen. Im nächsten Schritt wollen wir uns mit dem Abfragen von Daten beschäftigen.
Daten abfragen
Um Daten aus der Datenbank abzufragen, verwenden Sie das SELECT-Statement. SELECT erwartet als Parameter, durch Kommata getrennt, die Spalten, die Sie von den Datensätzen interessieren, und den Tabellennamen der Tabelle, die Sie abfragen wollen. Standardmäßig werden alle Zeilen aus der abgefragten Tabelle zurückgegeben. Mit einer WHERE-Klausel können Sie nur bestimmte Datensätze auswählen, indem Sie Bedingungen für die Auswahl angeben. Ein einfaches SELECT-Statement ist folgendermaßen aufgebaut:
SELECT <spaltenliste> FROM <tabellenname> [WHERE <bedingung>]
Wie durch die eckigen Klammern angedeutet wird, ist die WHERE-Klausel optional und kann entfallen.
Wenn Sie beispielsweise alle belegten Fachnummern und die dazugehörigen Komponenten abfragen wollen, formulieren Sie das folgende Statement:
SELECT fachnummer, komponente FROM lager
Bevor wir Daten aus einer Datenbank lesen können, muss diese geladen worden sein. Sie können mit der in den vorherigen Abschnitten verwendeten Datenbank im Arbeitsspeicher fortfahren oder eine gespeicherte Datenbank von der Festplatte laden:
>>> connection = sqlite3.connect("lagerverwaltung.db")
>>> cursor = connection.cursor()
Auch bei Datenabfragen benutzen Sie die execute-Methode des Cursor-Objekts, um der Datenbank Ihr Anliegen mitzuteilen. Anschließend können Sie sich mit cursor.fetchall alle Datensätze zurückgeben lassen, die Ihre Abfrage ergeben hat:
>>> cursor.execute("SELECT fachnummer, komponente FROM lager")
>>> cursor.fetchall()
[(1, 'Grafikkarte Typ 1'), (2, 'Prozessor Typ 13'),
(10, 'Netzteil Typ 3'), (25, 'LED-Lüfter'),
(26, 'Festplatte 128 GB')]
Der Rückgabewert von fetchall ist eine Liste, die für jeden Datensatz ein Tupel mit den Werten der angeforderten Spalten enthält.
Mit einer passenden WHERE-Klausel können Sie die Auswahl auf die Computerteile beschränken, die noch nicht reserviert sind:
>>> cursor.execute("""
... SELECT fachnummer, komponente FROM lager WHERE reserviert=0
... """)
>>> cursor.fetchall()
[(1, 'Grafikkarte Typ 1'), (10, 'Netzteil Typ 3')]
Sie können auch mehrere Bedingungen mittels logischer Operatoren wie AND und OR zusammenfassen. Damit ermitteln Sie beispielsweise, welche Artikel, die von der Firma »FiboComputing Inc.« geliefert wurden, schon reserviert worden sind:
>>> cursor.execute("""
... SELECT fachnummer, komponente FROM lager
... WHERE reserviert!=0 AND lieferant='FC'
... """)
>>> cursor.fetchall()
[(25, 'LED-Lüfter')]
Da es lästig ist, immer die auszuwählenden Spaltennamen anzugeben und man oft Abfragen über alle Spalten vornehmen möchte, gibt es dafür eine verkürzte Schreibweise, bei der die Spaltenliste durch ein Sternchen ersetzt wird:
>>> cursor.execute("SELECT * FROM kunden")
>>> cursor.fetchall()
[(12, 'Heinz Elhurg', 'Turnhallenstr. 1, 3763 Sporthausen'),
(57, 'Markus Altbert', 'Kämperweg 24, 2463 Duisschloss'),
(64, 'Steve Apple', 'Podmacstr 2, 7467 Iwarhausen')]
Die Reihenfolge der Spaltenwerte richtet sich danach, in welcher Reihenfolge die Spalten der Tabelle mit CREATE definiert wurden.
Als letzte Ergänzung zum SELECT-Statement wollen wir uns mit den Abfragen über mehrere Tabellen, den sogenannten Joins (dt. »Verbindungen«), beschäftigen. Sie möchten zum Beispiel abfragen, welche Komponenten des Lieferanten mit der Telefonnummer »011235813« zurzeit im Lager vorhanden sind und in welchen Fächern sie liegen.
Eine Abfrage über mehrere Tabellen unterscheidet sich von einfachen Abfragen dadurch, dass anstelle des einfachen Tabellennamens eine durch Kommata getrennte Liste angegeben wird, die alle an der Abfrage beteiligten Tabellen enthält. Wenn auf Spalten, zum Beispiel in der WHERE-Bedingung, verwiesen wird, muss der jeweilige Tabellenname mit angegeben werden. Das gilt auch für die auszuwählenden Spalten direkt hinter SELECT. Unsere Beispielabfrage betrifft nur die Tabellen »Lager« und »Lieferanten« und lässt sich als Join folgendermaßen formulieren:
SELECT lager.fachnummer, lager.komponente, lieferanten.name
FROM lager, lieferanten
WHERE lieferanten.telefonnummer='011235813' AND
lager.lieferant=lieferanten.kurzname
Sie können sich die Verarbeitung eines solchen Joins so vorstellen, dass die Datenbank jede Zeile der Tabelle »Lager« mit jeder Zeile der Tabelle »Lieferanten« zu neuen Datensätzen verknüpft und aus der dadurch entstehenden Liste alle Zeilen zurückgibt, bei denen die Spalte lieferanten.telefonnummer den Wert '011235813' hat und die Spalten lager.lieferant und lieferanten.kurzname übereinstimmen.
Führen Sie die Abfrage mit SQLite aus, erhalten Sie die erwartete Ausgabe:
>>> sql = """
... SELECT lager.fachnummer, lager.komponente, lieferanten.name
... FROM lager, lieferanten
... WHERE lieferanten.telefonnummer='011235813' AND
... lager.lieferant=lieferanten.kurzname"""
>>> cursor.execute(sql)
>>> cursor.fetchall()
[(1, 'Grafikkarte Typ 1', 'FiboComputing Inc.'),
(10, 'Netzteil Typ 3', 'FiboComputing Inc.'),
(25, 'LED-Lüfter', 'FiboComputing Inc.')]
Bis hierher haben Sie nach einer Abfrage mit cursor.fetchall immer alle Ergebnisse der Abfrage auf einmal aus der Datenbank geladen und dann gesammelt ausgegeben. Diese Methode eignet sich allerdings nur für relativ kleine Datenmengen, da erstens das Programm so lange warten muss, bis die Datenbank alle Ergebnisse ermittelt und zurückgegeben hat, und zweitens das Resultat komplett als Liste im Speicher gehalten wird. Dass dies bei sehr umfangreichen Ergebnissen eine Verschwendung von Speicherplatz darstellt, bedarf keiner weiteren Erklärung. Aus diesem Grund gibt es die Möglichkeit, die Daten zeilenweise, also immer in kleinen Portionen, abzufragen. Sie erreichen durch dieses Vorgehen, dass Sie nicht mehr auf die Berechnung der kompletten Ergebnismenge warten müssen, sondern schon währenddessen mit der Verarbeitung beginnen können. Außerdem müssen nicht mehr alle Datensätze zeitgleich im Arbeitsspeicher verfügbar sein.
Mit der Methode fetchone der cursor-Klasse fordern wir jeweils ein Ergebnis-Tupel an. Wurden bereits alle Datensätze der letzten Abfrage ausgelesen, gibt fetchone den Wert None zurück. Damit lassen sich auch große Datenmengen speichereffizient auslesen, auch wenn unser Beispiel mangels einer großen Datenbank nur drei Zeilen ermittelt:
>>> cursor.execute("SELECT * FROM kunden")
>>> row = cursor.fetchone()
>>> while row:
... print(row)
... row = cursor.fetchone()
(12, 'Heinz Elhurg', 'Turnhallenstr. 1, 3763 Sporthausen')
(57, 'Markus Altbert', 'Kämperweg 24, 2463 Duisschloss')
(64, 'Steve Apple', 'Podmacstr 2, 7467 Iwarhausen')
Diese Methode führt durch die while-Schleife zu etwas holprigem Code und wird deshalb seltener eingesetzt. Eine wesentlich elegantere Methode bietet die Iterator-Schnittstelle der cursor-Klasse, die es uns erlaubt, wie bei einer Liste mithilfe von for über die Ergebniszeilen zu iterieren:
>>> cursor.execute("SELECT * FROM kunden")
>>> for row in cursor:
... print(row)
(12, 'Heinz Elhurg', 'Turnhallenstr. 1, 3763 Sporthausen')
(57, 'Markus Altbert', 'Kämperweg 24, 2463 Duisschloss')
(64, 'Steve Apple', 'Podmacstr 2, 7467 Iwarhausen')
Aufgrund des besser lesbaren Programmtextes sollten Sie die Iterator-Methode für solche Anwendungen der Methode fetchone vorziehen. Sie sollten fetchone nur dann benutzen, wenn Sie gezielt jede Ergebniszeile separat und auf eine andere Weise verarbeiten wollen.
Datentypen bei SQLite
Aus dem einleitenden Teil dieses Abschnitts kennen Sie bereits das Schema, nach dem SQLite Daten beim Schreiben der Datenbank konvertiert. Die entsprechende Rückübersetzung von SQLite-Datentypen zu Python-Datentypen beschreibt Tabelle 33.8:
| SQLite-Datentyp (Quelltyp) | Python-Datentyp (Zieltyp) |
|---|---|
| NULL | None |
| INTEGER | int |
| REAL | float |
| TEXT | str |
| BLOB | bytes |
Tabelle 33.8 Typumwandlung beim Lesen von SQLite-Datenbanken
Im Wesentlichen wirft diese Tabelle zwei Fragen auf: Wie werden andere Datentypen, beispielsweise Listen oder eigene Klassen, in der Datenbank gespeichert, wenn doch nur diese Typen unterstützt werden? Und wie können wir in den Rückübersetzungsprozess eingreifen, um Daten beim Auslesen aus der Datenbank unseren Vorstellungen entsprechend anzupassen?
Wir werden zuerst die zweite Frage beantworten.
Connection.text_factory
Jede von sqlite3.connect erzeugte Connection-Instanz hat ein Attribut text_factory, das eine Referenz auf eine Funktion enthält, die immer dann aufgerufen wird, wenn TEXT-Spalten ausgelesen werden. Im Ergebnis-Tupel der Datenbankabfrage steht dann der Rückgabewert dieser Funktion. Standardmäßig ist das text_factory-Attribut auf die Built-in Function str gesetzt.
>>> connection = sqlite3.connect("lagerverwaltung.db")
>>> connection.text_factory
<class 'str'>
Um Ihr Ziel zu erreichen, str-Instanzen für TEXT-Spalten zu erhalten, in denen alle Buchstaben groß sind, können Sie eine eigene text_factory-Funktion angeben. Diese Funktion muss einen Parameter erwarten und den konvertierten Wert zurückgeben. Der Parameter ist ein bytes-String, der die Rohdaten aus der Datenbank mit UTF-8 codiert enthält. In unserem Fall reicht also eine einfache Funktion aus, die den ausgelesenen Wert erst in einen String umwandelt und anschließend mit der upper-Methode alle Buchstaben zu Großbuchstaben macht:
>>> def my_text_factory(value):
... return str(value, "utf-8", "ignore").upper()
Nun müssen Sie nur noch das Attribut text_factory Ihres Connection-Objekts auf Ihre neue Funktion setzen und können sich über das erwartete Ergebnis freuen:
>>> connection.text_factory = my_text_factory
>>> cursor = connection.cursor()
>>> cursor.execute("SELECT * FROM kunden")
>>> cursor.fetchall()
[(12, 'HEINZ ELHURG', 'TURNHALLENSTR. 1, 3763 SPORTHAUSEN'),
(57, 'MARKUS ALTBERT', 'KÄMPERWEG 24, 2463 DUISSCHLOSS'),
(64, 'STEVE APPLE', 'PODMACSTR 2, 7467 IWARHAUSEN')]
Es ist noch interessant zu wissen, dass sqlite3 schon über eine alternative text_factory-Funktion verfügt: sqlite3.OptimizedUnicode. Diese erkennt automatisch, ob es sich bei dem gerade aus der Datenbank gelesenen bytes-String um gültiges UTF-8 oder um binäre Daten handelt. Davon abhängig entscheidet sqlite3.OptimizedUnicode dann, ob ein str-Objekt oder ein bytes-String zurückgegeben werden soll. Um das Verhalten von sqlite3.OptimizedUnicode zu demonstrieren, legen Sie eine Datenbank im Arbeitsspeicher an und erzeugen eine Tabelle »test«. Anschließend schreiben Sie einen normalen String und einen UTF-16-codierten String in die Tabelle »test«.
>>> connection1 = sqlite3.connect(":memory:")
>>> connection1.text_factory = sqlite3.OptimizedUnicode
>>> cursor1 = connection1.cursor()
>>> cursor1.execute("CREATE TABLE test (spalte TEXT)")
>>> cursor1.execute("INSERT INTO test VALUES('Hallo Welt')")
>>> cursor1.execute("INSERT INTO test VALUES(?)", ("foo".encode("UTF-16"),))
Da Sie "foo" mit UTF-16 codieren, sieht sqlite3 diesen Eintrag als Binärdatum. Nun lesen Sie die beiden Zeilen wieder aus und stellen fest, dass tatsächlich im ersten Fall eine str-Instanz und im zweiten Fall ein bytes-String zurückgeliefert wird:
>>> cursor1.execute("SELECT * FROM test")
>>> cursor1.fetchall()
[('Hallo Welt',), (b'\xff\xfef\x00o\x00o\x00',)]
Der Name OptimizedUnicode kommt nicht von ungefähr, denn diese Funktion ist auf Geschwindigkeit optimiert.
Um das ursprüngliche Ausgabeverhalten wiederherzustellen, weisen Sie text_factory einfach den Standardwert str zu:
>>> connection.text_factory = strConnection.row_factory
Ein ähnliches Attribut wie text_factory für TEXT-Spalten existiert auch für ganze Datensätze. In dem Attribut row_factory kann eine Referenz auf eine Funktion gespeichert werden, die Zeilen für das Benutzerprogramm aufbereitet. Standardmäßig wird die Funktion tuple benutzt. Wir wollen beispielhaft eine Funktion implementieren, die uns auf die Spaltenwerte eines Datensatzes über die Namen der jeweiligen Spalten zugreifen lässt. Das Ergebnis soll dann folgendermaßen aussehen:
>>> cursor.execute("SELECT * FROM kunden")
>>> cursor.fetchall()
[(12, 'Heinz Elhurg', 'Turnhallenstr. 1, 3763 Sporthausen'),
(57, 'Markus Altbert', 'Kämperweg 24, 2463 Duisschloss'),
(64, 'Steve Apple', 'Podmacstr 2, 7467 Iwarhausen')]
Um dies zu erreichen, benötigen wir noch das Attribut description der Cursor-Klasse, das uns Informationen zu den Spaltennamen der letzten Abfrage liefert. Das Attribut description enthält dabei eine Sequenz, die für jede Spalte ein Tupel mit sieben Elementen bereitstellt, von denen uns aber nur das erste, nämlich der Spaltenname interessiert:[ 143 ](Die anderen sechs Einträge existieren nur aus Kompatibilitätsgründen zur Python DB API und sind immer mit dem Wert None belegt. )
>>> connection = sqlite3.connect("lagerverwaltung.db")
>>> cursor = connection.cursor()
>>> cursor.execute("SELECT * FROM kunden")
>>> cursor.description
(('kundennummer', None, None, None, None, None, None),
('name', None, None, None, None, None, None),
('anschrift', None, None, None, None, None, None))
Die row_factory-Funktion erhält als Parameter eine Referenz auf den Cursor, der für die Abfrage verwendet wurde, und die Ergebniszeile als Tupel.
Mit diesem Wissen können wir unsere row_factory-Funktion namens zeilen_dict wie folgt implementieren:
def zeilen_dict(cursor, zeile):
ergebnis = {}
for spaltennr, spalte in enumerate(cursor.description):
ergebnis[spalte[0]] = zeile[spaltennr]
return ergebnis
[»] Hinweis
Zur Erinnerung: enumerate erzeugt einen Iterator, der für jedes Element der übergebenen Sequenz ein Tupel zurückgibt, das den Index des Elements in der Sequenz und seinen Wert enthält. Mehr dazu erfahren Sie in Abschnitt 19.8.13.
In der Praxis arbeitet unsere row_factory wie folgt:
>>> connection.row_factory = zeilen_dict
>>> cursor = connection.cursor()
>>> cursor.execute("SELECT * FROM kunden")
>>> cursor.fetchall()
[{'kundennummer': 12, 'name': 'Heinz Elhurg', 'anschrift':
'Turnhallenstr. 1, 3763 Sporthausen'},
{'kundennummer': 57, 'name': 'Markus Altbert', 'anschrift': 'Kämperweg 24, 2463 Duisschloss'}, {'kundennummer': 64, 'name': 'Steve Apple', 'anschrift':
'Podmacstr 2, 7467 Iwarhausen'}]
Pythons sqlite3-Modul liefert schon eine erweiterte row_factory namens sqlite3.Row mit, die die Zeilen in ähnlicher Weise verarbeitet wie unsere zeilen_dict-Funktion. Da sqlite3.Row stark optimiert ist und außerdem der Zugriff auf die Spaltenwerte über den jeweiligen Spaltennamen unabhängig von Groß- und Kleinschreibung erfolgen kann, sollten Sie die eingebaute Funktion unserem Beispiel vorziehen und nur dann eine eigene row_factory implementieren, wenn Sie etwas ganz anderes erreichen möchten.
Nach diesem kleinen Ausflug zu den factory-Funktionen wenden wir uns der ersten unserer beiden Fragen zu: Wie können wir beliebige Datentypen in SQLite-Datenbanken speichern?
Adapter und Konvertierer
Wie Sie bereits wissen, unterstützt SQLite nur eine beschränkte Menge von Datentypen. Als Folge davon müssen wir alle anderen Datentypen, die wir in der Datenbank ablegen möchten, durch die vorhandenen abbilden. Aufgrund ihrer unbeschränkten Länge eignen sich die TEXT-Spalten am besten, um beliebige Daten aufzunehmen, weshalb wir uns im Folgenden auf sie beschränken werden.
Bei der String-Codierung haben wir str-Instanzen mittels ihrer encode-Methode in gleichwertige bytes-Instanzen umgeformt und die ursprünglichen Unicode-Daten mithilfe der decode-Methode wiederherstellen können. Analog dazu betrachten wir nun Operationen, um beliebige Datentypen erst in Strings zu transformieren und anschließend die Ursprungsdaten wieder aus dem String zu extrahieren. Dabei geht es uns darum, die generierten Strings in einer Datenbank zu speichern und später wieder auszulesen.
Das Umwandeln beliebiger Datentypen in einen String wird Adaption genannt, und die Rückgewinnung der Daten aus diesem String heißt Konvertierung. Abbildung 33.3 veranschaulicht diesen Zusammenhang am Beispiel der Klasse Kreis, die als Attribute die Koordinaten des Kreismittelpunktes Mx und My sowie die Länge des Radius R besitzt:
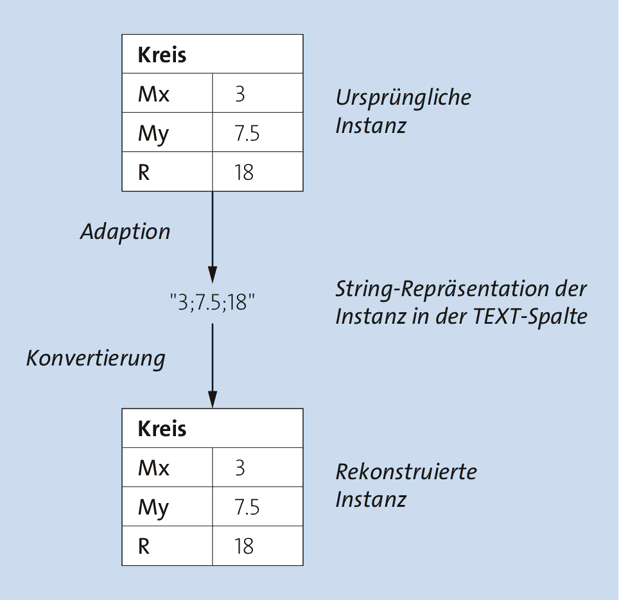
Abbildung 33.3 Schema der Adaption und Konvertierung
Eine entsprechende Kreis-Klasse lässt sich folgendermaßen definieren:
class Kreis:
def __init__(self, mx, my, r):
self.Mx = mx
self.My = my
self.R = r
Nun müssen wir eine Adapterfunktion erstellen, die aus unseren Kreis-Instanzen Strings macht.
Die Umwandlung nehmen wir so vor, dass wir einen String erstellen, der, durch Semikola getrennt, die drei Attribute des Kreises enthält:
def kreisadapter(k):
return "{};{};{}".format(k.Mx, k.My, k.R)
Damit die Datenbank weiß, dass wir die Kreise mit dieser Funktion adaptieren möchten, muss sie registriert und mit dem Datentyp Kreis verknüpft werden. Dies geschieht durch den Aufruf der sqlite3.register_adapter-Methode, die als ersten Parameter den zu adaptierenden Datentyp und als zweiten Parameter die Adapterfunktion erwartet:
>>> sqlite3.register_adapter(Kreis, kreisadapter)Durch diese Schritte ist es uns möglich, Kreise in TEXT-Spalten abzulegen. Wirklich nützlich wird das Ganze aber erst dann, wenn beim Auslesen auch automatisch wieder Kreis-Instanzen generiert werden.
Deshalb müssen wir noch die Umkehrfunktion von kreisadapter, den Konverter, definieren, der aus dem String die ursprüngliche Kreis-Instanz wiederherstellt. In unserem Beispiel erweist sich das als sehr einfach:
def kreiskonverter(bytestring):
mx, my, r = bytestring.split(b";")
return Kreis(float(mx), float(my), float(r))
Genau wie der Adapter muss auch die Konverterfunktion bei SQLite registriert werden, was wir mit der Methode sqlite3.register_converter() erreichen:
>>> sqlite3.register_converter("KREIS", kreiskonverter)
Anders als register_adapter erwartet register_convert dabei einen String als ersten Parameter, der dem zu konvertierenden Datentyp einen Namen innerhalb von SQLite zuweist. Dadurch haben wir einen neuen SQLite-Datentyp namens KREIS definiert, den wir genau wie die eingebauten Typen für die Spalten unserer Tabellen verwenden können. Allerdings müssen wir SQLite beim Verbinden zu der Datenbank mitteilen, dass wir von uns definierte Typen verwenden möchten. Dazu übergeben wir der connect-Methode einen entsprechenden Wert als Schlüsselwortparameter detect_types:
>>> connection = sqlite3.connect(":memory:",
... detect_types=sqlite3.PARSE_DECLTYPES)
Im Folgenden demonstrieren wir die Definition und Verwendung unseres neuen Datentyps Kreis in einem Miniprogramm:
import sqlite3
class Kreis:
def __init__(self, mx, my, r):
self.Mx = mx
self.My = my
self.R = r
def __str__(self):
return "Kreis({}, {}, {})".format(self.Mx, self.My, self.R)
def kreisadapter(k):
return "{};{};{}".format(k.Mx, k.My, k.R)
def kreiskonverter(bytestring):
mx, my, r = bytestring.split(b";")
return Kreis(float(mx), float(my), float(r))
# Adapter und Konverter registrieren
sqlite3.register_adapter(Kreis, kreisadapter)
sqlite3.register_converter("KREIS", kreiskonverter)
# Hier wird eine Beispieldatenbank im Arbeitsspeicher mit
# einer einspaltigen Tabelle für Kreise definiert
connection = sqlite3.connect(":memory:",
detect_types=sqlite3.PARSE_DECLTYPES)
cursor = connection.cursor()
cursor.execute("CREATE TABLE kreis_tabelle(k KREIS)")
# Kreis in die Datenbank schreiben
kreis = Kreis(1, 2.5, 3)
cursor.execute("INSERT INTO kreis_tabelle VALUES (?)", (kreis,))
# Kreis wieder auslesen
cursor.execute("SELECT * FROM kreis_tabelle")
gelesener_kreis = cursor.fetchall()[0][0]
print(type(gelesener_kreis))
print(gelesener_kreis)
Die Ausgabe dieses Programms ergibt sich wie folgt und zeigt, dass gelesener_kreis tatsächlich eine Instanz unserer Kreis-Klasse mit den korrekten Attributen ist:
<class '__main__.Kreis'>
Kreis(1.0, 2.5, 3.0)
Einschränkungen
Das Datenbanksystem SQLite ist im Vergleich zu anderen Datenbanken in bestimmten Punkten eingeschränkt. Beispielsweise wird eine Datenbank beim Verändern oder Hinzufügen von Datensätzen für Lesezugriffe gesperrt, was besonders bei Webanwendungen unpraktisch ist: In der Regel werden mehrere Besucher eine Internetseite gleichzeitig aufrufen, und wenn jemand zum Beispiel einen neuen Foreneintrag erstellt, wollen die anderen Besucher nicht länger auf die Anzeige der Seite warten müssen.
 Python 3
Python 3 Jetzt Buch bestellen
Jetzt Buch bestellen





