

32.3 Parallelisierung von Funktionsaufrufen 
Für den Anwendungsfall, dass ein Programm komplexe, aber voneinander unabhängige Aufgaben ausführen muss, existiert das Modul concurrent.futures. Mit concurrent.futures können Funktionsaufrufe in komfortabler Weise in Threads oder Prozessen ausgeführt werden.
Es werden die Klassen ThreadPoolExecutor und ProcessPoolExecutor bereitgestellt, deren Instanzen jeweils eine Menge von Threads beziehungsweise Prozessen repräsentieren. Beide Klassen implementieren eine gemeinsame Schnittstelle, die eines Executors. Ein Executor dient dazu, eine Folge von Aufgaben abzuarbeiten, wobei er sich mehrerer Workers, eben der Threads beziehungsweise Prozesse, bedienen kann.
Die Schnittstelle eines Executors umfasst die folgenden Methoden:
| Methode | Beschreibung |
|---|---|
| submit(fn, [*args], {**kwargs}) | Meldet eine neue Aufgabe beim Executor an. Die Aufgabe besteht darin, die Funktion fn mit den Parametern args und kwargs aufzurufen. |
| map(fn, [*iterables], {timeout}) | Wendet die Funktion fn auf alle Elemente der iterierbaren Objekte iterables an und erzeugt einen Iterator über die Ergebnisse. |
| shutdown([wait]) | Weist den Executor an, alle verwendeten Ressourcen wieder freizugeben, sobald die übergebenen Aufgaben abgearbeitet sind. |
Tabelle 32.2 Die Methoden der Executor-Klassen
Sie können sich einen Executor wie den Chef eines Teams aus mehreren Arbeitern vorstellen, dem Sie über die Methode submit die Aufgaben mitteilen, die das Team für uns erledigen soll. Die Verteilung dieser Aufgaben an die einzelnen Arbeiter wird dabei vom Executor übernommen.
Beim Erzeugen einer neuen Executor-Instanz können wir die Anzahl der gewünschten Workers über den Schlüsselwortparameter max_workers festlegen.
32.3.1 Ein Beispiel mit einem futures.ThreadPoolExecutor
Im folgenden Beispiel verwenden wir einen ThreadPoolExecutor, um vier Aufrufe einer einfachen Beispielfunktion in drei Threads auszuführen.
from concurrent import futures
from time import sleep, time
def test(t):
sleep(t)
print("Ich habe {} Sekunden gewartet. Zeit: {:.0f}".format(t, time()))
e = futures.ThreadPoolExecutor(max_workers=3)
print("Startzeit: {:.0f}".format(time()))
e.submit(test, 9)
e.submit(test, 2)
e.submit(test, 5)
e.submit(test, 6)
print("Alle Aufgaben gestartet.")
e.shutdown()
print("Alle Aufgaben erledigt.")
Die Funktion test erzeugt eine verzögerte Ausgabe auf dem Bildschirm, wobei mit dem Parameter t die Länge der Verzögerung festgelegt werden kann. Im Beispiel lassen wir den Executor diese Funktion mit verschiedenen Verzögerungen aufrufen, was die folgende Ausgabe erzeugt:
Startzeit: 1428830988
Alle Aufgaben gestartet.
Ich habe 2 Sekunden gewartet. Zeit: 1428830990
Ich habe 5 Sekunden gewartet. Zeit: 1428830993
Ich habe 6 Sekunden gewartet. Zeit: 1428830996
Ich habe 9 Sekunden gewartet. Zeit: 1428830997
Alle Aufgaben erledigt.
Die Zeitstempel der Ausgaben belegen, dass die Funktionsaufrufe parallel ausgeführt worden sind, denn die Ausgaben für die Wartezeiten von 2, 5 und 9 Sekunden erfolgen genau um die jeweilige Wartezeit verzögert nach der Startzeit. Wären die Aufrufe sequenziell abgearbeitet worden, hätten sich die Zeiten aufsummiert.
Eine Ausnahme bildet der Aufruf für die Wartezeit von 6 Sekunden, die erst nach 8 Sekunden auf dem Bildschirm erscheint. Der Grund für diese Verzögerung ist die Anzahl der Worker-Threads unseres Executors. Der Executor verwaltet intern eine Warteschlange der Aufgaben, die ihm per submit übergeben worden sind. Diese Warteschlange wird in derselben Reihenfolge abgearbeitet, in der die jeweiligen Aufrufe von submit erfolgt sind. In unserem Beispiel stehen dem Executor drei Threads zur Verfügung, um die vier Aufgaben zu erledigen. Zuerst wird also der Aufruf der Funktion test mit dem Parameter 9 in einem Thread gestartet. Nachdem dann auch noch die Aufrufe mit den Parametern 2 und 5 in eigenen Threads gestartet worden sind, hat der Executor die von uns festgelegte maximale Anzahl von Workers erreicht. Deshalb erfolgt der Aufruf mit dem Parameter 6 erst dann, wenn wieder ein Worker-Thread frei geworden ist. Nach 2 Sekunden ist die Aufgabe mit der kürzesten Wartezeit abgearbeitet, sodass der Aufruf für den Parameter 6 mit der entsprechenden Verzögerung gestartet wird.
Interessant ist außerdem das unterschiedliche Verhalten der Methoden submit und shutdown, denn jeder Aufruf von submit gibt die Kontrolle sofort wieder an die aufrufende Ebene zurück, ohne darauf zu warten, dass die übergebene Funktion ihre Arbeit vollendet hat. Deshalb erscheint die Ausgabe »Alle Aufgaben gestartet.« vor den Ausgaben der Funktion test. Der Aufruf von shutdown hingegen blockiert die Ausführung der aufrufenden Ebene so lange, bis alle Aufgaben abgearbeitet sind, und gibt dann die verwendeten Ressourcen wieder frei.
Wird für den Parameter wait der Wert False übergeben, gibt auch shutdown die Kontrolle sofort wieder an die aufrufende Ebene zurück, sodass dort ohne Verzögerung weitergearbeitet werden kann. Das gesamte Programm wird dann trotzdem so lange nicht beendet, wie noch Arbeiten im Hintergrund ausgeführt werden. Wichtig ist dabei, dass ein Executor nach dem Aufruf von shutdown keine weiteren Aufgaben mehr entgegennehmen kann.
Ersetzen wir im Beispielprogramm die Zeile e.shutdown() durch e.shutdown(False), ändert sich die Ausgabe deshalb folgendermaßen:
Startzeit: 1428829782
Alle Aufgaben gestartet.
Alle Aufgaben erledigt.
Ich habe 2 Sekunden gewartet. Zeit: 1428829784
Ich habe 5 Sekunden gewartet. Zeit: 1428829787
Ich habe 6 Sekunden gewartet. Zeit: 1428829788
Ich habe 9 Sekunden gewartet. Zeit: 1428829791
Wie Sie sehen, erscheint die Ausgabe nach dem Aufruf von e.shutdown nun sofort auf dem Bildschirm, obwohl noch Hintergrundarbeiten laufen. Trotzdem wartet Python auf die noch laufenden Hintergrundprozesse, sodass noch alle verbleibenden Ausgaben erfolgen, bevor das Programm beendet wird.
32.3.2 Executor-Instanzen als Kontext-Manager
Der typische Lebenszyklus einer Executor-Instanz sieht so aus, dass sie erzeugt wird, ihr Aufgaben zugeteilt werden und sie dann auf das Ende der Aufgaben wartet, um abschließend wieder freigegeben zu werden.
Um diesen typischen Ablauf abzubilden, können Sie jeden Executor als Kontext-Manager mit der with-Anweisung verwenden, wodurch der explizite Aufruf von shutdown entfällt. Der letzte Teil in unserem Beispiel kann durch den folgenden with-Block ersetzt werden:
print("Startzeit: {:.0f}".format(time()))
with futures.ThreadPoolExecutor(max_workers=3) as e:
e.submit(test, 9)
e.submit(test, 2)
e.submit(test, 5)
e.submit(test, 6)
print("Alle Aufgaben gestartet.")
print("Alle Aufgaben erledigt.")
Wenn Sie einen Executor als Kontext-Manager mit with verwenden, wird der with-Block erst dann verlassen, wenn alle zugeteilten Aufgaben erledigt sind, da die Methode e.shutdown implizit ohne Parameter gerufen wird.
32.3.3 Die Verwendung von futures.ProcessPoolExecutor
Um anstelle von Threads im obigen Beispiel Prozesse für die Parallelisierung zu verwenden, wird die Klasse futures.ThreadPoolExecutor durch futures.ProcessPoolExecutor ersetzt. Außerdem muss dafür gesorgt werden, dass die Kindprozesse ihrerseits nicht wieder neue Prozesse starten. Das angepasste Beispielprogramm sieht dann folgendermaßen aus, wobei wir die Version mit with-Anweisung zugrunde gelegt haben:
from concurrent import futures
from time import sleep, time
def test(t):
sleep(t)
print("Ich habe {} Sekunden gewartet. Zeit: {:.0f}".format(t, time()))
if __name__ == "__main__":
print("Startzeit: {:.0f}".format(time()))
with futures.ProcessPoolExecutor(max_workers=3) as e:
e.submit(test, 9)
e.submit(test, 2)
e.submit(test, 5)
e.submit(test, 6)
print("Alle Aufgaben gestartet.")
print("Alle Aufgaben erledigt.")
Neben der Verwendung von ProcessPoolExecutor anstelle von ThreadPoolExecutor haben wir mit der Abfrage der globalen Variablen __name__ geprüft, ob die Python-Datei direkt ausgeführt wird, und nur in diesem Fall die Unterprozesse gestartet. Hintergrund ist, dass die Python-Datei, in der die Unterprozesse gestartet werden, von diesen als Modul importierbar sein muss. Der Wert der globalen Variablen __name__ ist nur dann "__main__", wenn die Datei direkt mit dem Python-Interpreter ausgeführt wird. Wird die Datei hingegen als Modul importiert, hat sie einen anderen Wert, nämlich den Namen des Moduls. Durch diese Abfrage wird somit verhindert, dass ein Unterprozess beim Importieren des Moduls erneut den Code im if-Block ausführt.
[»] Hinweis
Eine interaktive Session kann natürlich nicht von einem Unterprozess importiert werden. Daher funktioniert der ProcessPoolExecutor nicht im interaktiven Modus von Python.
Nun sind Sie in der Lage, eine Funktion parallel in verschiedenen Threads oder Prozessen auszuführen. Im nächsten Abschnitt beschäftigen wir uns damit, wie Sie auf die Rückgabewerte der Funktionsaufrufe zugreifen können.
32.3.4 Die Verwaltung der Aufgaben eines Executors
Die Funktion test in unserem einführenden Beispiel ist von besonders einfacher Bauart, da sie keinen Rückgabewert besitzt, den die aufrufende Ebene verwenden könnte. Interessanter sind hingegen Funktionen, die nach einer (unter Umständen langwierigen) Berechnung einen Wert zurückgeben.
Eine Modellfunktion für eine aufwendige Berechnung
Als Modellbeispiel verwenden wir im Folgenden eine Funktion, die die Kreiszahl π mithilfe des wallisschen Produkts[ 130 ](Das Produkt ist nach dem englischen Mathematiker John Wallis (1616–1703) benannt, der es im Jahre 1655 entdeckte. ) approximiert.
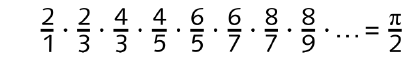
Im Zähler stehen dabei immer gerade Zahlen, die sich bei jedem zweiten Faktor um 2 erhöhen. Der Nenner enthält nur ungerade Zahlen, die sich mit Ausnahme des ersten Faktors ebenfalls alle zwei Faktoren um 2 erhöhen.
Die Funktion naehere_pi_an, die als Parameter die Anzahl der zu berücksichtigenden Faktoren erhält, implementieren wir folgendermaßen:
def naehere_pi_an(n):
pi_halbe = 1
zaehler, nenner = 2.0, 1.0
for i in range(n):
pi_halbe *= zaehler / nenner
if i % 2:
zaehler += 2
else:
nenner += 2
return 2*pi_halbe
Mit dem Parameter 1000 für n erzeugt die Funktion beispielsweise folgende Ausgabe, bei der nur die ersten beiden Nachkommastellen korrekt sind.
>>> naehere_pi_an(1000)
3.140023818600586
Mit größer werdendem Wert für n werden immer bessere Näherungen von π berechnet, was aber auch mit mehr Rechenzeit bezahlt werden muss. Beispielsweise benötigt ein Aufruf mit n = 30000000 auf unserem Testrechner ca. acht Sekunden.
Mit naehere_pi_an haben wir damit eine Beispielfunktion, die einen Prozessorkern voll auslastet und für größere Werte von n immer länger für die Berechnung benötigt. In den folgenden Programmen dient naehere_pi_an als Beispiel für eine aufwendige Funktion, die von einem Parameter abhängt.
Nun werden wir naehere_pi_an in mehreren Threads beziehungsweise Prozessen ausführen.
Der Zugriff auf die Ergebnisse der Berechnung
Im einführenden Beispiel haben wir die Methode submit einer Executor-Instanz verwendet, um neue Aufgaben in die Warteschlange des Executors einzureihen. Dabei erzeugt die Methode submit bei jedem Aufruf eine Instanz vom Typ futures.Future, was wir bisher ignoriert haben. Sie können sich diese Instanz wie einen Abholschein vorstellen, mit dem Sie den Status der übergebenen Aufgabe prüfen und nach Abschluss der Berechnung das Ergebnis abholen können. Im einfachsten Fall verwenden wir die Methode result der Future-Instanz, um das Ergebnis zu erhalten.
with futures.ThreadPoolExecutor(max_workers=4) as e:
f = e.submit(naehere_pi_an, 10000000)
print(f.result())
Als Ausgabe erhalten wir wie gewünscht eine näherungsweise Berechnung von π mit 10000000 Faktoren im wallisschen Produkt. Die Methode result einer Future-Instanz blockiert die aufrufende Ebene dabei so lange, bis die zugehörige Berechnung abgeschlossen ist. Insbesondere wenn Sie gleichzeitig mehrere Aufgaben mit unterschiedlicher Laufzeit ausführen lassen, müssen Sie dadurch unter Umständen auf bereits verfügbare Ergebnisse unnötig lange warten.
with futures.ThreadPoolExecutor(max_workers=4) as e:
f1 = e.submit(naehere_pi_an, 10000000)
f2 = e.submit(naehere_pi_an, 100)
print("f1:", f1.result())
print("f2:", f2.result())
In diesem Beispiel werden zwei Berechnungen durchgeführt, wobei die eine deutlich länger rechnet als die andere. Trotzdem wird zunächst das Ergebnis der Rechnung mit n=10000000 und erst danach das zu n=100 ausgegeben.
f1: 3.1415924965090136
f2: 3.126078900215409
Das Modul concurrent.futures stellt Funktionen bereit, um bequem auf die Ergebnisse mehrerer Berechnungen zuzugreifen.
concurrent.futures.as_completed(fs, [timeout])
Mit der Funktion as_completed wird ein Iterator erzeugt, der über die Ergebnisse des Containers fs von Future-Instanzen iteriert. Dabei werden die Ergebnisse in der Reihenfolge durchlaufen, in der sie zur Verfügung stehen. Dadurch kann die aufrufende Ebene die Ergebnisse sofort weiterverarbeiten, wenn die jeweilige Berechnung abgeschlossen ist.
N = (12345678, 123456, 1234, 12)
with futures.ThreadPoolExecutor(max_workers=4) as e:
fs = {e.submit(naehere_pi_an, n): n for n in N}
for f in futures.as_completed(fs):
print("n={:10}: {}".format(fs[f], f.result()))
Im Beispiel lassen wir die Funktion naehere_pi_an mit verschiedenen Parametern durch einen ThreadPoolExecutor mit 4 Threads ausführen. Durch die Verwendung von futures.as_completed erhalten wir die folgende Ausgabe, bei der die Ergebnisse der kürzeren Rechnungen zuerst ausgegeben werden:
n= 12: 3.02317019200136
n= 1234: 3.1403210113038207
n= 123456: 3.1415799301866607
n= 12345678: 3.1415925263536626
Das Dictionary fs verwenden wir, um uns die Zuordnung von Eingabeparametern zur zugehörigen Future-Instanz zu merken. Interessant ist noch, dass wir wie oben die Methode result der Future-Instanzen verwenden, um das Ergebnis der Berechnung abzufragen. Da die Funktion futures.as_completed nur die Future-Instanzen liefert, deren Berechnung schon abgeschlossen ist, muss result nicht auf die Vollendung der Berechnung warten, sondern liefert sofort den bereits bestimmten Wert.
Mit dem Parameter timeout kann optional eine Zeit in Sekunden angegeben werden, die futures.as_completed auf die Berechnung aller Ergebnisse warten soll. Ist nach timeout Sekunden das letzte Ergebnis noch nicht berechnet, wird eine TimeoutError-Exception geworfen.
concurrent.futures.wait(fs, [timeout, return_when])
Die Funktion futures.wait wartet so lange, bis das von return_when spezifizierte Ereignis eingetreten oder die Zeit timeout abgelaufen ist. Der Rückgabewert ist eine Instanz, die die beiden Attribute done und not_done besitzt. Dabei referenziert done die Menge der Future-Instanzen in fs, die zum Zeitpunkt des Ereignisses bereits abgearbeitet worden sind, während not_done die noch ausstehenden Future-Instanzen in einer Menge enthält.
Die möglichen Werte für return_when sind in Tabelle 32.3 aufgelistet.
| Konstante | Bedeutung |
|---|---|
| futures.FIRST_COMPLETED | Die erste Aufgabe in fs ist fertiggestellt. |
| futures.FIRST_EXCEPTION |
Die erste Aufgabe in fs wirft eine Exception. Wird keine Exception geworfen, wird gewartet, bis alle Aufgaben in fs abgearbeitet sind. |
| futures.ALL_COMPLETED | Alle Aufgaben in fs sind fertiggestellt. |
Tabelle 32.3 Die von futures.wait unterstützten Ereignisse
Standardmäßig wird gewartet, bis alle Aufgaben abgearbeitet sind, wie im folgenden Beispiel gezeigt.
with futures.ThreadPoolExecutor(max_workers=4) as e:
fs = {e.submit(naehere_pi_an, n): n for n in N}
res = futures.wait(fs)
for f in res.done:
print("n={:10}: {}".format(fs[f], f.result()))
Ähnlich wie bei futures.as_completed kann mit timeout eine Maximalzeit in Sekunden angegeben werden, die wait abwartet, bevor es die Kontrolle wieder an die aufrufende Ebene zurückgibt. Das folgende Beispiel gibt jede Sekunde die fertigen Ergebnisse aus, bis keine mehr übrig sind.
with futures.ThreadPoolExecutor(max_workers=4) as e:
fs = {e.submit(naehere_pi_an, n): n for n in N}
fertig = False
while not fertig:
res = futures.wait(fs, timeout=1.0)
for f in res.done:
print("n={:10}: {}".format(fs[f], f.result()))
del fs[f]
fertig = (len(res.not_done) == 0)
Durch die Festlegung eines Timeouts kann sichergestellt werden, dass die aufrufende Ebene in regelmäßigen Abständen die Kontrolle zurückerhält, während auf das nächste Ergebnis gewartet wird.
[»] Hinweis
Sowohl bei der Funktion futures.as_completed als auch bei futures.wait kann fs auch Futures-Instanzen enthalten, die zu verschiedenen Executor-Instanzen gehören.
Executor.map(func, [*iterables], {timeout, chunksize})
Die Executor-Instanzen selbst besitzen eine Methode map, mit der sich eine Funktion auf alle Werte in iterierbaren Objekten, also beispielsweise Listen, anwenden lässt. Sie verhält sich also genauso wie die Built-in Function map[ 131 ](Die Beschreibung zur Built-in Function map finden Sie in Abschnitt 19.8.30. ), mit der Ausnahme, dass sie die Funktion func mithilfe des Executors parallel in Threads oder Prozessen ausführen kann.
Mit dem Parameter timeout kann eine Zeitspanne in Sekunden festgelegt werden, die das Abarbeiten der Funktionsaufrufe insgesamt dauern darf. Dauert die Berechnung länger, wird eine concurrent.futures.TimeoutError-Exception geworfen. Standardmäßig ist die erlaubte Zeit unbegrenzt.
Mit chunksize kann dafür gesorgt werden, dass die Elemente von iterables blockweise abgearbeitet werden. Wird beispielsweise eine Liste mit 100 Elementen als iterables zusammen mit chunksize=20 übergeben, werden 5 Pakete mit jeweils 20 Elementen verarbeitet. Standardmäßig wird für jedes Element ein neuer Prozess gestartet. Ein von 1 abweichender Wert von chunksize kann die Verarbeitungsgeschwindigkeit gegebenenfalls stark verbessern. Beachten Sie, dass chunksize nur bei Verwendung der Klasse ProcessPoolExecutor von Bedeutung ist.
Nun werden wir untersuchen, wie sich die Verwendung von Threads und Prozessen auf die Laufzeit eines Programms auswirkt.
Rechnungen auf mehreren Prozessoren mit ProcessPoolExecutor
Das folgende Beispiel ruft die Funktion naehere_pi_an für eine Liste relativ großer Werte für n auf, wobei mithilfe eines Kommandozeilenparameters festgelegt wird, ob die Built-in Function map oder Executor.map mit Threads beziehungsweise Prozessen verwendet werden soll. Das Programm errechnet die Laufzeit, indem es die Differenz zwischen Start- und Endzeit berechnet und ausgibt.
from concurrent import futures
import sys
import time
def naehere_pi_an(n):
...
if __name__ == "__main__":
start = time.perf_counter()
N = (34567890, 5432198, 44444444, 22222222, 56565656,
43236653, 23545353, 32425262)
if sys.argv[1] == "threads":
with futures.ThreadPoolExecutor(max_workers=4) as e:
res = e.map(naehere_pi_an, N)
elif sys.argv[1] == "processes":
with futures.ProcessPoolExecutor(max_workers=4) as e:
res = e.map(naehere_pi_an, N)
else:
res = map(naehere_pi_an, N)
print(list(res))
print(time.perf_counter()-start)
Auf einem Beispielrechner mit vier Prozessorkernen haben sich folgende Ausgaben ergeben, wobei die Liste der Ergebnisse weggelassen wurde.
$ python benchmark.py builtin
70.19322323799133
$ python benchmark.py threads
89.58459234237671
$ python benchmark.py processes
26.78869891166687
Wie Sie sehen, ist der Durchlauf mit vier Worker-Prozessen um etwa den Faktor 2,5 schneller als der Durchlauf mit der Built-In-Funktion map. Dies liegt daran, dass das Programm alle vier Kerne des Rechners nutzen konnte, um die Berechnung zu beschleunigen. Die Berechnung lief also tatsächlich parallel auf verschiedenen Prozessorkernen ab.
Auf den ersten Blick verwunderlich ist die im Vergleich zur Built-in Function map verlängerte Laufzeit beim Durchlauf mit vier Worker-Threads. Wenn man aber bedenkt, dass aufgrund der Einschränkungen von CPython immer nur ein Thread zur gleichen Zeit ausgeführt werden kann, wird klar, dass man keinen Geschwindigkeitszuwachs erwarten kann. Dass die Threads-Variante sogar langsamer ist, liegt an dem zusätzlichen Aufwand, der für die Verwaltung der Threads betrieben werden muss. In CPython eignen sich Threads also nicht für die Beschleunigung aufwendiger Rechnungen, sondern nur, um ein Blockieren des Programms zu verhindern.
[»] Hinweis
Die Funktion perf_counter des Moduls time ist ein Zeitgeber speziell zum Messen von Programmlaufzeiten. Nähere Informationen finden Sie im Abschnitt 17.1.2.
Der Umgang mit Instanzen des Typs futures.Future
Bisher haben wir Instanzen des Typs futures.Future nur dazu genutzt, um die Ergebnisse von Executor-Aufgaben auszulesen. Tatsächlich bieten sie eine Reihe weiterer Methoden, um ihren aktuellen Status zu erfragen oder ihre Ausführung zu beeinflussen.
Tabelle 32.4 listet diese Methoden auf.
| Methode | Beschreibung |
|---|---|
| cancel() | Versucht, die Aufgabe abzubrechen, und gibt bei Erfolg True, ansonsten False zurück. |
| cancelled() | Gibt True zurück, wenn die Aufgabe abgebrochen wurde, sonst False. |
| running() | Gibt True zurück, wenn die Aufgabe gerade ausgeführt wird, sonst False. |
| done() | Ist der Rückgabewert True, wurde die Aufgabe abgeschlossen oder abgebrochen. |
| result([timeout]) | Liefert das Ergebnis der Aufgabe, wobei maximal timeout Sekunden gewartet wird. |
| exception([timeout]) | Liefert die in der Aufgabe-Funktion geworfene Exception, wobei maximal timeout Sekunden gewartet wird. Falls die Aufgabe erfolgreich abgeschlossen wird, wird None zurückgegeben. |
| add_done_callback(fn) | Sorgt dafür, dass die Funktion fn mit dem Ergebnis der Aufgabe aufgerufen wird, sobald das Ergebnis vorliegt. Die Methode add_done_callback kann mehrfach für verschiedene Funktionen aufgerufen werden. |
Tabelle 32.4 Die Methoden einer Instanz des Typs futures.Future
 Python 3
Python 3 Jetzt Buch bestellen
Jetzt Buch bestellen





