


23.3 XML_RSS 
| Besprochene Version: 0.9.2 | Lizenz: PHP-Lizenz |
| Klassendatei(en): XML/RSS.php | |
RSS-Feeds sind eine beliebte Möglichkeit, um eine Übersicht einer Nachrichtenseite oder eines Blogs im Internet zur Verfügung zu stellen. Gerade Nachrichtenagenturen, Zeitungen und Zeitschriften oder private Blog-Betreiber bieten RSS-Feeds an, die Sie dann auf Ihrer eigenen Seite integrieren können. Somit können Sie z. B. einen kurzen Überblick über aktuelle Nachrichten auf Ihrer Seite integrieren. Jeder der Einträge in der Übersicht kann dann wiederum mit der kompletten Nachricht auf der Seite des Nachrichtenanbieters verlinkt werden.
RSS ist in verschiedenen Versionen verfügbar. Die einfachste Version 0.9X wird von diesem Paket unterstützt. Die Versionen 1.0 und 2.0, die auch auf dem Markt sind, bieten mehr Möglichkeiten, werden aber noch nicht ganz so oft genutzt. Da der Großteil der Informationen aber abwärtskompatibel ist, können auch Feeds der höheren Versionen ohne Probleme von dem Paket ausgewertet werden.
Ein solcher RSS-Feed kann in seiner Rohform beispielsweise so aussehen wie in diesem Beispiel von www.heise.de [Die komplette URL lautet http://www.heise.de/newsticker/heise.rdf. ] (gekürzt):
<rdf:RDF> <channel> <title>heise online news</title> <link>http://www.heise.de/newsticker/</link> <description>Nachrichten aus der Welt des Computers</description> </channel> <item> <title>CAS bietet neuen Routenplaner für Notebooks</title> <link>http://www.heise.de/newsticker/meldung/55187</link> </item> <item> <title>Neues im Virtuellen Markenmuseum</title> <link>http://www.heise.de/newsticker/meldung/55189</link> </item> </rdf:RDF>
Das Paket kann die Daten direkt vom Anbieter des Feeds über das http-Protokoll übernehmen. Wie Sie in diesem Beispiel sehen, sind unterschiedliche Elemente in einem solchen Nachrichten-Angebot vorgesehen. Zum Ersten sind Informationen zum Channel, also zum »Nachrichten-Kanal«, vorhanden. Danach schließen sich die eigentlichen Nachrichten-Blöcke, die so genannten Items, an. Des Weiteren können noch Container mit Bildern oder Text-Eingabe-Elementen vorhanden sein, die jeweils mit <image ...> bzw. <textinput ...> eingeleitet werden.
Der Konstruktor bekommt einen Verweis auf die RSS-Quelle übergeben. Üblicherweise handelt es sich um eine URL, aber Sie können auch einen Dateinamen nutzen. Nach dem Instanziieren des Objekts müssen Sie die eingelesenen Daten mit der Methode parse() analysieren. Ist das erfolgt, können Sie die einzelnen Blöcke auslesen. Mit getChannelInfo() liefert das Paket die Information zu dem Channel zurück. getItems() liefert Ihnen ein großes Array, das wiederum aus Arrays besteht, in denen die Daten der einzelnen Einträge enthalten sind. Das Gleiche gilt für die Methoden getImages() und getTextinputs(). Sollten Sie alle Daten auf einmal auslesen wollen, steht auch getStructure() zur Verfügung. Diese Methode liefert den gesamten Inhalt der Datei bzw. der URL als ein großes Array zurück.
Den RSS-Feed von www.heise.de können Sie mit Listing 23.2 auf Ihrer Website einbinden.
require_once("XML/RSS.php"); $rss =new XML_RSS("http://www.heise.de/newsticker/heise.rdf"); // Daten parsen $res=$rss->parse(); if (true===PEAR::isError($res)) { die ($res->getMessage()); } //Channel-Info auslesen $channel=$rss->getChannelInfo(); // Titel des Channels ausgeben echo "<h2>".utf8_decode($channel['title'])."</h2>"; // URL zum Angebot aufbereiten und als Link ausgeben $url=utf8_decode($channel['link']); echo "<a href='$url'>$url</a><br />"; // Beschreibung des Channels ausgeben echo "<b>".utf8_decode($channel[description])."</b>"; // Alle Items auslesen $items= $rss->getItems(); echo "<ul>"; // Items in einer Schleife abarbeiten foreach ($items as $item ) { echo "<li><a href='".utf8_decode($item['link'])."'>"; echo utf8_decode($item['title'])."</a></li>"; } echo "</ul>";
Listing 23.2 Script zum Einbinden der heise.de-News
Wie Ihnen sicher aufgefallen ist, habe ich die Daten mit utf8_decode() bearbeitet. Da heise.de diesen Zeichensatz nutzt, ist es die einfachste Variante, die Daten damit nach ISO-8859–1 umzuwandeln, um Darstellungsfehler zu verhindern. Die Ausgabe dieses Scripts sehen Sie in Abbildung 23.1.
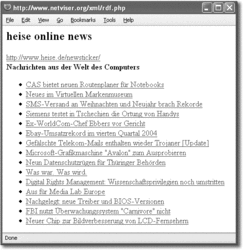
Abbildung 23.1 Darstellung des heise.de-RSS-Feeds im Browser
Vielleicht fragen Sie sich, woher man wissen kann, welche Felder in den zurückgelieferten Arrays zu finden sind. Nun, das Einfachste ist, wenn Sie sich die RSS-Daten in einem einfachen Text-Editor ansehen. Die Tags, die innerhalb der channel- bzw. dem item-Elemente vorhanden sind, werden jeweils zu den Array-Schlüsseln und die darin enthaltenen Texte zu den Werten. Da es, wie schon erwähnt, innerhalb der einzelnen RSS-Versionen unterschiedliche Spezifikationen gibt, kann es durchaus passieren, dass nicht alle Tags ausgewertet werden. Für welches Element momentan welche Inhalte unterstützt werden, können Sie Tabelle 23.2 entnehmen.
Nachfolgend finden Sie einen Ausschnitt aus dem SWR3-RDF-Feed:
<rdf:RDF> <channel rdf:about="http://www.swr3.de/?ref=rdf"> <title>SWR3 RDF-Feed</title> <link>http://www.swr3.de/?ref=rdf</link> <description> Mehr Hits, mehr Kicks - einfach SWR3 </description> <image rdf:resource="http://www.swr3.de/sidebar/header.gif"/> <items> <rdf:Seq> <rdf:li resource="http://www.swr3.de/info/topthema/?ref=rdf"/> <rdf:li resource="http://www.swr3.de/info/wetter/?ref=rdf"/> <rdf:li resource="http://www.swr3.de/info/stau.html?ref=rdf"/> </rdf:Seq> </items> <dc:date>2005–01–16T21:41:32+00:00</dc:date> <dc:publisher>SWR3.de</dc:publisher> </channel> <image rdf:about="http://www.swr3.de/sidebar/header.gif"> <title>SWR3.de - einfach besser und schneller informiert</title> <link>http://www.swr3.de/?ref=rdf</link> <url>http://www.swr3.de/sidebar/header.gif</url> </image> <item rdf:about="http://www.swr3.de/musik/webradio/info/TID-11338.htm?ref=rdf"> <title> [Playing now] Louisan, Annett: Das Spiel (16.01.2005 21:38) </title> <link> http://www.swr3.de/musik/webradio/info/TID-11338.htm?ref=rdf </link> <description>Informationen zum Song Das Spiel (Louisan, Annett)</description> <dc:creator>SWR3.de</dc:creator> </item> </rdf:RDF>
In diesem Beispiel sind noch einige Dinge enthalten, die das Paket nicht interpretieren kann. So ist im channel-Element beispielsweise ein leeres image-Tag enthalten. Dieses Tag wird gelesen, da es aber keinen Inhalt hat, erzeugt es nur ein leeres Element, wenn getImages() aufgerufen wird. Und auch das Element items innerhalb des ersten Elements kann nicht interpretiert werden. Trotz dieser kleinen Einschränkungen kann der Feed ohne Probleme mit Listing 23.3 eingebunden werden.
require_once("XML/RSS.php"); // Funktion zum Dekodieren der Umlaute function _decode($str) { return chr($str[1]); } $rss = new XML_RSS("http://www.swr3.de/rdf-feed/"); $res=$rss->parse(); if (true===PEAR::isError($res)) { die ($res->getMessage()); } $logo=$rss->getImages(); $url_logo=$logo[1]['url']; echo "<img src='$url_logo' align='right'>"; $channel=$rss->getChannelInfo(); echo "<h2>$channel[title]</h2>"; echo "<a href='$channel[link]'>$channel[link]</a><br />"; echo "<b>$channel[description]</b>"; $items= $rss->getItems(); echo "<ul>"; // Items in einer Schleife abarbeiten foreach ($items as $item ) { echo "<li><a href='$item[link]'>"; // Erst utf8 entfernen $text=utf8_decode($item['title']); // ASCII entfernen $text=preg_replace_callback( '/#([0–9]{3});/','_decode',$text); echo "$text</a><br />"; if (false===empty($item['dc:creator'])) { echo "von: ".$item['dc:creator']."</li>"; } } echo "</ul>";
Listing 23.3 Script zum Einbinden des SWR3-Feeds
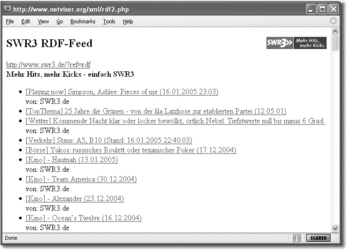
Wenn Sie den SWR3-Feed analysieren, werden Sie feststellen, dass die Umlaute hier aus mir nicht bekannten Gründen in unterschiedlichen Kodierungen vorkommen können. Einige liegen als UTF-8 vor, andere als numerische Entitäten, die nicht von jedem Browser verstanden werden. Um beides in ISO-8859–1 zu konvertieren, habe ich auf utf8_decode() und preg_replace_callback() zurückgegriffen. Die Ausgabe des Scripts sehen Sie in Abbildung 23.2.

 Jetzt Buch bestellen!
Jetzt Buch bestellen!



