


6.3 Abbildung auf relationale Datenbanken 

Um Objekte mit ihren Beziehungen in relationalen Datenbanken speichern zu können, müssen wir beschreiben, wie diese auf die relationalen Strukturen abgebildet werden.
6.3.1 Abbildung von Objekten in relationalen Datenbanken
Schauen wir uns zunächst an, wie man die grundsätzlichen Daten der Objekte in einer relationalen Datenbank speichern kann. Wenn wir davon ausgehen, dass alle Exemplare einer Klasse etwa die gleiche Datenstruktur haben, können wir für die Speicherung ihrer Daten eine Tabelle definieren, deren Spalten den Attributen beziehungsweise den Dateneinträgen der Objekte entsprechen.
Wir können aber durchaus auch mehrere Attribute eines Objekts in einer Spalte speichern. Im Extremfall könnten wir sogar alle Daten eines Objekts serialisieren und sie so in einem Feld eines Datensatzes speichern.
Zugriffsrelevanz
Wichtig für solche Entscheidungen ist immer die Frage: Werde ich auf die Werte der einzelnen Eigenschaften in der Datenbank zugreifen müssen? Werde ich nach ihnen suchen? Wenn ich zum Beispiel alle Kunden aus einem Postleitzahlenbereich finden möchte, ist es sinnvoll, die Postleitzahl des Kunden in einer separaten Spalte der Kundentabelle zu speichern und sie nicht in einer breiteren Adressspalte zusammen mit dem Straßen- und dem Stadtnamen zu verbinden.
Als Richtlinie kann uns dabei die Struktur des Objekts selbst dienen. Wenn die Adresse in unserer Anwendung einfach als eine Zeichenkette gehandhabt wird, spricht nicht vieles dafür, sie nur wegen der Speicherung in der Datenbank in ihre Bestandteile zu zerlegen. Wurde dagegen eine Adresse in unserem Klassenmodell als eine eigenständige Klasse mit gesonderten Attributen modelliert, wird es wohl meistens sinnvoll sein, diese auch getrennt in der Datenbank zu speichern.
Verteilung auf mehrere Tabellen
Es kann aber auch sinnvoll sein, die Daten einer Klasse auf Datensätze in mehreren Tabellen zu verteilen. Dabei kann man die ursprüngliche Tabelle auf zwei Arten trennen:
Vertikale Verteilung
- Vertikal Bei dieser Verteilung speichert man verschiedene Attribute der Objekte in verschiedenen Tabellen, also die Daten eines einzelnen Objekts werden in mehreren Datensätzen verschiedener Tabellen gespeichert. Dies ist vor allem dann sinnvoll, wenn die Attribute optional sind und häufig keinen Wert haben oder wenn die Werte bestimmter Attribute selten gebraucht werden. Durch die vertikale Teilung kann die Tabelle mit den häufig verwendeten Daten der Objekte kleiner und die Zugriffe auf diese Tabelle können schneller werden. Braucht man jedoch auch die in andere Tabellen ausgelagerten Daten, muss man auf mehrere Tabellen zugreifen, was wiederum weniger effektiv ist. Welche Tabellenstruktur man wählen sollte, hängt letzten Endes von der konkreten Anwendung ab.
Horizontale Verteilung
- Horizontal Hier werden verschiedene Objekte in verschiedenen Tabellen mit derselben Struktur gespeichert. Ein Objekt wird aber immer nur in einer Tabelle gespeichert. Diese Aufteilung ist vor allem dann sinnvoll, wenn man häufig nur auf eine bestimmte Menge der Objekte zugreift. So können wir zum Beispiel offene Rechnungen in einer anderen Tabelle speichern als Rechnungen, die bereits beglichen worden sind. Dies ermöglicht einen schnelleren Zugriff auf die offenen Rechnungen, vor allem dann, wenn es nur wenige offene, aber viele beglichene Rechnungen im System gibt. Die erhöhte Komplexität der Anwendung gehört allerdings zu den Nachteilen der horizontalen Aufteilung. Ein anderer Nachteil ergibt sich aus der etwas kleineren Effektivität, wenn wir bei der Suche nach den Objekten das Aufteilungskriterium nicht berücksichtigen können. Suchen wir in unserem Beispiel eine Rechnung nach ihrer Rechnungsnummer und wissen nicht, ob die Rechnung bereits beglichen ist, müssen wir zwei Tabellen statt einer durchsuchen.
Partitionierung
Viele relationale Datenbanksysteme kennen das Konzept der Partitionierung der Tabellen. Eine partitionierte Tabelle ist intern horizontal geteilt, nach außen gibt sie sich aber als eine gewöhnliche Tabelle. Auf diese Art können wir die Vorteile der horizontalen Aufteilung nutzen und die Komplexität dieser Aufteilung der Datenbank überlassen. Selbstverständlich können wir beide Verteilungsstrategien auch kombinieren.
Wir werden zu der Verteilung der Tabellen und der Abbildung der Daten der Objekte auf die Tabellen und ihre Spalten noch einmal in Abschnitt 6.3.3 zurückkommen, in dem wir uns der Abbildung der Vererbung widmen.
Identität
Neben der Abbildung der eigentlichen Daten der Objekte auf die Daten in einer relationalen Datenbank ist es wichtig, dass wir die Identität der Objekte und ihren Bezug zu den richtigen Daten verwalten können.
In einer objektorientierten Anwendung hat jedes Objekt eine eindeutige Identität. Auch Objekte, welche die gleichen Daten enthalten, können als selbstständige, nicht verwechselbare Entitäten betrachtet werden. In einer relationalen Datenbank gibt es den Begriff der Identität aber nicht. Datensätze einer Relation können anhand des Primär- oder eines Alternativschlüssels eindeutig bestimmt werden, ändert man jedoch die Werte der Schlüsselspalten, können wir nicht sagen, ob ein neuer Datensatz entstanden ist und der alte gelöscht wurde oder ob wir einen Datensatz modifiziert haben. Um einen Bezug der Datensätze zu den dazugehörigen Objekten herzustellen, müssen wir die Eigenschaften des Objekts bestimmen, die für die eindeutige Bestimmung seiner Identität verwendet werden können.
Natürlicher Schlüssel
Eine Möglichkeit bieten die sogenannten natürlichen Schlüssel. Ein natürlicher Schlüssel ist ein Attribut, oder eine Gruppe von Attributen, das nach den Fachregeln der Anwendung zur eindeutigen Identifizierung eines Objekts dienen kann. So kann zum Beispiel die zweistellige Internetländerdomäne oder das internationale Länderkennzeichen als natürlicher Schlüssel für die Bestimmung eines Landes dienen.
Ersatzschlüssel Surrogate Key
Häufig gibt es keinen solchen natürlichen Schlüssel. In so einem Fall können wir einen Ersatzschlüssel (engl. Surrogate Key) definieren, der jedem Exemplar einer Klasse zugeordnet wird, um dessen Identität eindeutig zu bestimmen. Ein Ersatzschlüssel hat in der Anwendung keine fachliche Bedeutung, er wird dem Anwender nicht gezeigt, sondern nur intern verwendet, um den Bezug der Objekte zu ihren gespeicherten Daten herzustellen.
Die Verwendung von Ersatzschlüsseln hat eine ganze Reihe von Vorteilen.
Ersatzschlüssel sind einfach.
- Vorteil 1: Während der natürliche Schlüssel komplex sein und aus mehreren Spalten bestehen kann, können wir immer einen einfachen Ersatzschlüssel definieren. Wir können wahrscheinlich eine Person durch ihren Namen, ihr Geburtsdatum und den Geburtsort eindeutig identifizieren, es ist aber wesentlich effizienter, wenn sich diese Information nicht in jeder Tabelle, die Daten zu dieser Person enthält, wiederholen muss.
Ersatzschlüssel müssen nicht geändert werden.
- Vorteil 2: In einigen Fällen kann es fachlich notwendig sein, die Werte der Spalten des natürlichen Schlüssels zu ändern. Dies führt zwangsweise zur erhöhten Komplexität bei der Verwaltung der Identität der Objekte. Wenn wir zum Beispiel die Passnummer als den Schlüssel der Tabelle unserer Spione verwenden, müssen wir die Identität der Daten bei der Ausstellung jedes neuen Passes anpassen. Da der Ersatzschlüssel aber keine fachliche Bedeutung hat, besteht nie der fachliche Bedarf, ihn zu ändern.
-
- Andererseits kann es manchmal sinnvoll sein, die Werte eines Ersatzschlüssels zu ändern, ohne dass dies fachliche Konsequenzen hätte. Wenn man zum Beispiel mehrere Datenbanken zusammenführt, muss man die Schlüsselwerte, die nicht eindeutig sind, ändern. Wenn zwei Firmen fusionieren und ihre Kundendatenbanken konsolidieren, kann die nötige Änderung der Kundennummern einen nicht zu unterschätzenden Aufwand bedeuten.
Ersatzschlüssel gibt es immer.
- Vorteil 3: Für bestimmte Objekte gibt es gar keinen natürlichen Schlüssel, hier sind wir auf die Verwendung einer Ersatzschlüssels angewiesen.
-
- Vor allem dann, wenn es keinen natürlichen Schlüssel für bestimmte Objekte gibt, tendiert man dazu, einen Ersatzschlüssel zu einem natürlichen Schlüssel zu erheben. So haben heutzutage jede Bestellung und jede Rechnung eine im Unternehmen eindeutige Nummer, fast jedes Buch eine ISBN, jedes zugelassene Auto ein Kennzeichen, jeder Kunde eine Kundennummer, jedes Konto eine Kontonummer. Solche für die Anwender sichtbare Schlüssel kann man durchaus als natürliche Schlüssel betrachten. Wenn es dennoch für bestimmte Klassen von Objekten keinen natürlichen Schlüssel gibt, kann es praktisch erscheinen, den Benutzern die Werte der Ersatzschlüssel anzuzeigen. Dies birgt aber die Gefahr, dass der Ersatzschlüssel irgendwann zu einem natürlichen Schlüssel mutiert und dies zu den bereits geschilderten Schwierigkeiten mit natürlichen Schlüsseln führt.
6.3.2 Abbildung von Beziehungen in relationalen Datenbanken
Für die Abbildung von Beziehungen zwischen Objekten in einer Datenbank spielt die Multiplizität [Der Begriff der Multiplizität wurde in Abschnitt 4.3.3, »Kardinalität«, definiert. Obwohl im Bereich der relationalen Datenbank häufiger der Begriff der Kardinalität verwendet wird, bleiben wir aus Konsistenzgründen beim Begriff Multiplizität. ] der Beziehung eine entscheidende Rolle. Bei einer 1:1-Beziehung können wir die Daten beider Objekte in derselben Tabelle speichern, weil die Identität eines Objekts eindeutig die Identität des anderen Objekts bestimmt. Dies ist sogar dann der Fall, wenn einer der Teilnehmer der Beziehung optional ist, in diesem Falle können wir die dazugehörigen Spalten einfach leer lassen.
Beziehung 1:1 1:0..1
Bei der Abbildung der 1:1-Beziehung gelten die gleichen Überlegungen wie bei der vertikalen Aufteilung der Abbildung einer einzelnen Klasse. Je nachdem, wie oft wir auf bestimmte Attribute der Teilnehmer der Beziehung zusammenhängend zugreifen, und je nachdem, wie oft der optionale Teilnehmer vorhanden ist, sollten wir entscheiden, auf wie viele Tabellen wir die Daten verteilen.
Wir sehen, dass schon ein einzelnes Objekt und die 1:1-Beziehungen auf recht vielfältige Art und Weise auf die Tabellenstrukturen in einer relationalen Datenbank abgebildet werden können. Es gibt entsprechend auch eine ganze Anzahl von Möglichkeiten, mehrwertige Beziehungen auf eine relationale Datenbank abzubilden. Die gängigsten davon werden wir in den nächsten Abschnitten vorstellen.
1:*
Wir könnten auch die Daten beider Teilnehmer einer 1:n-Beziehung in einer Tabelle speichern, denn ähnlich wie bei der 1:1-Beziehung bestimmt die Identität des n-Teilnehmers eindeutig die Identität des 1–Teilnehmers. Dies bedeutet aber, dass die Daten des 1-Teilnehmers redundant wiederholt mehrmals [Dass es redundanten Formulierungen an Eleganz mangelt, kann man an der hier gewählten Formulierung erkennen. ] gespeichert werden müssen.
Ein besseres Vorgehen ist es, wenn wir in die Tabelle der n-Teilnehmer nur den eindeutigen Schlüssel des 1-Teilnehmers einfügen und mit diesem Fremdschlüssel die Datensätze in der Tabelle des 1-Teilnehmers referenzieren. Dies ist die gängigste Abbildung einer 1:n-Beziehung in relationalen Datenbanken.
Referenzielle Integrität
Die meisten relationalen Datenbanken können sicherstellen, dass es für den Wert eines Fremdschlüssels immer einen entsprechenden Eintrag in der Zieltabelle gibt. Das Vorhandensein eines entsprechenden Eintrages nennt man referenzielle Integrität. Durch die automatische Überprüfung der referenziellen Integrität kann die Datenbank sicherstellen, dass der von dem n-Teilnehmer referenzierte 1-Teilnehmer existiert. Sie kann aber nicht sicherstellen, dass es die n-Teilnehmer gibt.
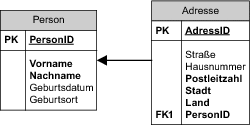
Abbildung 6.3 Referenzielle Integrität und eine 1:*-Beziehung
| Datenmodelle in der Entity-Relationship-Darstellung |
|
Ein Entity-Relationship-Modell (kurz ER-Modell) ist ein Verfahren zur Datenmodellierung, das häufig für Entwurf und Dokumentation von relationalen Datenbanken eingesetzt wird. Die zugehörigen ER-Diagramme beschreiben Beziehungen zwischen Entitäten in der Wirklichkeit. ER-Diagramme weisen Ähnlichkeiten zu den Strukturdiagrammen der UML auf, setzen jedoch einen stärkeren Fokus auf die Beziehungen zwischen Entitäten und den datenbankspezifischen Eigenschaften wie Primär- oder Fremdschlüssel. In ER-Diagrammen wird jede Relation durch ein Kästchen dargestellt. Die Spalten des Primärschlüssels sind oben, sie werden mit PK (Primary Key) markiert und unterstrichen dargestellt. Wenn eine Relation einen Fremdschlüssel zu einer anderen Relation enthält, wird dies durch einen Pfeil dargestellt. Die Spalten des Fremdschlüssels werden mit FK (Foreign Key) markiert. Spalten, die keine NULL-Werte enthalten dürfen (die Pflichtspalten), werden fett dargestellt. |
Sind die Spalten des Fremdschlüssels keine Pflichtspalten, handelt es sich um eine 0..1:*-Beziehung. Sind die Spalten des Fremdschlüssels Pflichtspalten, geht es um eine 1:*-Beziehung. Ist der Primärschlüssel oder ein Alternativschlüssel selbst ein Fremdschlüssel, geht es um eine 1:0..1-Beziehung. Und wenn für die Spalten des Fremdschlüssels eine Eindeutigkeitsbedingung gilt (markiert mit U für unique), die Spalten aber keine Pflichtfelder sind, geht es um eine 0..1:0..1-Beziehung.
1:1..n
Eine andere, seltener angewandte Möglichkeit besteht darin, in der Tabelle des 1-Teilnehmers die Daten oder zumindest die Schlüssel der n-Teilnehmer zu speichern. Dies ist manchmal vernünftig, wenn die obere Schranke n der Multiplizität eine kleine definierte Zahl ist. Wenn zum Beispiel in unserer Anwendung eine Person minimal eine und maximal drei Anschriften haben kann, können wir durchaus alle drei in der Tabelle Person speichern. Auf diese Art können wir sicherstellen, dass zumindest eine Anschrift vorhanden ist.
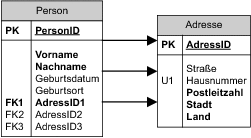
Abbildung 6.4 Umkehr der referenziellen Integrität
Der Nachteil dieser Vorgehensweise liegt wieder in der Redundanz und der dadurch erhöhten Komplexität der Anwendung. Hier sind es nicht die Daten selbst, die redundant sind, sondern wir haben redundante Datenstrukturen geschaffen.
Menge (Set)
Außer der Zuordnung der Objekte einer 1:n-Beziehung zueinander müssen wir noch andere Eigenschaften der Beziehung in Betracht ziehen. Ist die Beziehung geordnet? Können sich Elemente der Beziehung wiederholen? Die in der Abbildung 6.3 beschriebene Vorgehensweise eignet sich sehr gut für die Abbildung einer Menge (Set), in der ein Objekt maximal einmal auftreten kann und die Reihenfolge der Objekte keine Rolle spielt.
1:* {ordered}
Wenn die Reihenfolge der n-Teilnehmer eine Rolle spielt und sie sich nicht nach bereits existierenden Attributen bestimmen lässt, hat man grundsätzlich zwei Möglichkeiten. Wenn der 1-Teilnehmer nicht optional ist, kann man den Ersatzschlüssel der n-Teilnehmer so wählen, dass dessen Wert sich für die Bestimmung der Reihenfolge verwenden lässt. Der Primärschlüssel der n-Teilnehmer kann sogar aus dem Primärschlüssel des 1-Teilnehmers und einer Reihenfolgezahl bestehen.
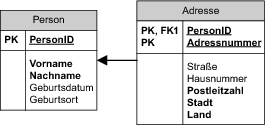
Abbildung 6.5 Der Fremdschlüssel ist ein Teil des Primärschlüssels.
0..1:* {ordered}
Wenn der 1-Teilnehmer jedoch optional ist, wenn also die n-Teilnehmer auch ohne den 1-Teilnehmer existieren können, kann ihr Primärschlüssel nicht den Primärschlüssel des 1-Teilnehmers beinhalten. In diesem Falle ist es meist notwendig, für die Bestimmung der Reihenfolge eine zusätzliche Spalte hinzuzufügen. Im Beispiel von Abbildung 6.6 ist die Einführung einer zusätzlichen Spalte Reihenfolgenummer für diesen Fall dargestellt.
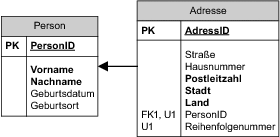
Abbildung 6.6 Abbildung einer geordneten 0..1:*-Beziehung
n:m
Bei einer n:m-Beziehung kann die Identität eines der Teilnehmer die Identität der anderen Teilnehmer der Beziehung nicht eindeutig bestimmen. Es ist also nicht möglich, diese Beziehung in einer der zwei Tabellen abzubilden. Stattdessen müssen wir eine zusätzliche Tabelle definieren, die Fremdschlüssel zu den Tabellen beider Teilnehmer der Beziehung enthält. Je nach Art der Beziehung – ist es eine Menge, ein Korb oder eine Liste – können wir die beiden Fremdschlüssel zusammen als Primärschlüssel der Beziehungstabelle definieren oder stattdessen eine neue Primärschlüsselspalte definieren.
Assoziationsklassen
Manche Beziehungen haben ihre eigenen Attribute. In Abschnitt 4.3.4 haben wir gezeigt, wie die Assoziationsklassen den »normalen« Klassen entsprechen. Somit können wir für das Speichern der Attribute einer Assoziationsklasse die gleichen Regeln anwenden, die auch für die »normalen« Klassen gelten. Gehört die Assoziationsklasse zu einer n:m-Beziehung, bietet sich die Beziehungstabelle an, um dort die Attribute der Assoziationsklasse zu speichern.
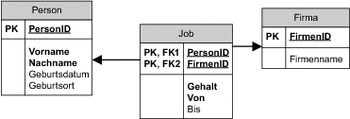
Abbildung 6.7 Abbildung einer n:m-Beziehung und einer Assoziationsklasse
6.3.3 Abbildung von Vererbungsbeziehungen auf eine
relationale Datenbank
Bisher gingen wir in unserer Beschreibung davon aus, dass alle Exemplare einer Klasse dieselben Attribute haben. Das ist natürlich eine sehr vereinfachte Sichtweise, denn zu einer Klasse gehören doch auch alle Exemplare ihrer Unterklassen, und die Unterklassen definieren für ihre Exemplare normalerweise zusätzliche Eigenschaften. Die Datenstruktur der Exemplare einer Unterklasse enthält also die Datenstruktur der Exemplare ihrer Oberklasse beziehungsweise ihrer Oberklassen. Die Speicherung der Daten der Exemplare der Unterklasse entspricht also der Speicherung der Daten einer 1:0..1-Kompositionsbeziehung. 0..1 deswegen, weil es auch Exemplare der Oberklasse geben kann, die nicht zu der Unterklasse gehören.
Bei der Verwendung der Vererbungshierarchie liegt der Schwerpunkt allerdings etwas anders als bei der Kompositionsbeziehung. Wir stellen uns zum Beispiel in einer Anwendung die Frage »Welche Objekte enthalten eine Produktnummer?« viel seltener als die Frage »Welche Produkte gibt es?«.
Daher sollten wir uns die gängigsten Speicherungsmöglichkeiten einer Klassenhierarchie genauer anschauen.
Um eine Klassenhierarchie auf eine relationale Datenbank abzubilden, gibt es in der Praxis drei verschiedene Möglichkeiten:
Drei Möglichkeiten, eine Klassenhierarchie zu speichern
- Wir bilden alle Klassen der Hierarchie auf eine Tabelle ab (Single Table Inheritance).
- Wir bilden jede Klasse der Hierarchie auf eine eigene Tabelle ab (Class Table Inheritance).
- Wir bilden jede Klasse der Hierarchie, die nicht abstrakt ist, auf eine Tabelle ab (Concrete Table Inheritance).
Alle drei Methoden haben ihre Anwendungsfälle, und es hängt zum Beispiel von der Art der Hierarchie und auch vom verwendeten Datenbanksystem ab, welche Modellierung adäquat ist.
Als Beispiel greifen wir uns diesmal eine Modellierung von fachlichen Objekten in einem Produktkatalog heraus. Wir bieten verschiedene Produkte an. Dazu gehören Dienstleistungen und physische Produkte wie Werkzeuge und Maschinen, die aus verschiedenen Teilen bestehen. Die physischen Produkte müssen irgendwo gelagert werden, und ein und dasselbe Produkt kann unter verschiedenen Markennamen zu unterschiedlichen Preisen verkauft werden. [Dies ist keine Marketingmasche. Die Preisunterschiede sind bestimmt durch unterschiedliche Garantieleistungen und durch die unterschiedlich aufwändige Präsentation in unterschiedlichen Baumärkten. ]
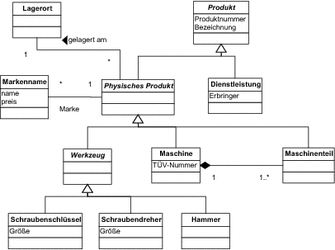
Abbildung 6.8 Beispielhierarchie zur Abbildung auf eine relationale Datenbank
Wir haben eine Reihe von abstrakten Klassen in der Hierarchie von Abbildung 6.8. Von diesen können keine Exemplare erstellt werden. Konkrete Klassen dagegen sind die folgenden: Maschinenteil, Maschine, Schraubenschlüssel, Schraubendreher, Hammer und Dienstleistung.
Wie würden wir nun die Klasse Produkt bei der Verwendung von Single Table Inheritance auf Tabellen einer relationalen Datenbank abbilden?
Single Table Inheritance
Hier resultiert eine einzige Tabelle mit dem Namen Produkt, die alle Informationen enthält. In Abbildung 6.9 ist diese Abbildung dargestellt.
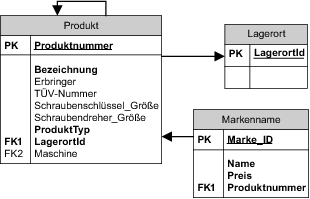
Abbildung 6.9 Abbildung von Vererbung auf genau eine Tabelle
Die gesamte Vererbungshierarchie ist bei diesem Vorgehen in einer Tabelle Produkt abgelegt. Da eine Maschine zum Beispiel kein Attribut »Erbringer« hat, müsste diese Spalte NULL-Werte zulassen, auch wenn sie für eine Dienstleistung ein Pflichtfeld ist. Theoretisch wäre es also möglich, inkonsistente Daten eintragen zu können. Um diese Konsistenzlücke zu schließen, könnte man die Möglichkeiten der gewählten Datenbank nutzen und sie bei jeder Erzeugung und jeder Änderung eines Datensatzes überprüfen lassen, ob bei einer Maschine die Spalte Erbringer leer und bei jeder Dienstleitung ausgefüllt ist.
Wie aber erkennt man, ob ein Datensatz zu einer Maschine, einer Dienstleistung oder einer anderen Produktklasse gehört? Da wir anhand der Produktnummer nicht den Typ des Produktes erkennen können, benötigen wir eine zusätzliche Spalte, in die wir den Typ explizit speichern – die Spalte ProduktTyp. Dies ist allerdings nicht immer erforderlich. Wenn wir aus den anderen Daten erkennen können, zu welcher konkreten Klasse der Datensatz gehört, wird eine solche Spalte nicht benötigt.
Concrete Table Inheritance
Eine andere Strategie, die ohne eine zusätzliche Typ-Spalte auskommt, ist die Concrete Table Inheritance. Die resultierende Tabellenstruktur ist in Abbildung 6.10 dargestellt. Bei dieser Strategie werden die Daten jeder konkreten Klasse in einer separaten Tabelle gespeichert. Der Vorteil dieser Strategie ist, dass für jeden Datensatz einer Tabelle klar ist, zu welcher Klasse das gespeicherte Objekt gehört, und die Bedingungen für die Spalten der Tabellen sich einfacher formulieren lassen. Der Nachteil ist die erhöhte Komplexität des Datenmodells – wir brauchen mehr Tabellen, mehrere Fremdschlüssel, und aus einem Pflichtfeld Produktnummer für den Fremdschlüssel in der Tabelle Markenname sind fünf optionale Fremdschlüsselfelder geworden.
Vielleicht wäre es sogar besser, aus der einen Tabelle Markenname fünf separate Tabellen zu machen, für jeden Produkttyp eine eigene.
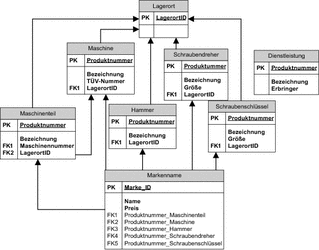
Abbildung 6.10 Abbildung jeder konkreten Klasse auf eine Tabelle
Ein weiterer Nachteil ist, dass wir fünf Tabellen lesen müssen, um ein Produkt zu finden, dessen konkreten Typ wir nicht kennen. Dies wäre auch der Fall, wenn wir eine Liste aller Produktbezeichnungen anzeigen sollten.
Diese Strategie wird üblicherweise gewählt, wenn die Klassen nur wenige Gemeinsamkeiten haben. In Java sind zum Beispiel alle Klassen Unterklassen der Klasse Object. Es wäre dann doch ein sehr merkwürdiges Datenmodell, das nur aus einer Tabelle Object bestehen würde.
Class Table Inheritance
Wenn wir aber die Produkte als solche häufig bearbeiten und uns nicht für deren konkreten Typ interessieren, können wir noch eine weitere Strategie wählen. Dabei bilden wir jede Klasse, auch die abstrakten Klassen, auf jeweils eine Tabelle ab. Die in unserem Beispiel resultierenden Tabellen sind in Abbildung 6.11 dargestellt. In diesem Falle müssen wir die Beziehungen zwischen den einzelnen Tabellen anders gestalten, da nun bestimmte Informationen ausgelagert werden. Hier wird deutlich, dass die Datenstruktur der Unterklassen eine Komposition aus ihren eigenen Daten und den Daten der Oberklasse ist.
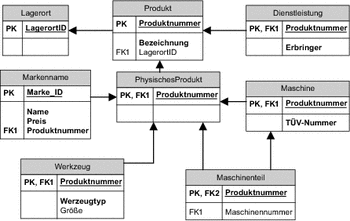
Abbildung 6.11 Abbildung jeder Klasse auf eine Tabelle
Die Tabellen, welche die konkreten Klassen repräsentieren, haben nun jeweils einen Verweis auf ihre abstrakte Oberklasse erhalten, da diese einen Teil der Information für das resultierende Objekt enthalten. Wenn wir nun die Bezeichnungen aller Produkte aus der Datenbank laden möchten, brauchen wir nur die Tabelle Produkt zu lesen. Brauchen wir dagegen die Daten einer Maschine, reicht uns das Lesen der Tabelle Maschine nicht mehr aus, denn um die Bezeichnung der Maschine zu erhalten, müssen wir die Tabelle Produkt auswerten.
Kombination der Vorgehensweisen
Wenn wir uns das Datenmodell genauer anschauen, erkennen wir, dass wir für die Speicherung der Werkzeugdaten nur eine Tabelle Werkzeug definiert haben. Für die Werkzeuge haben wir also die Strategie Single Table Inheritance gewählt. Wir können also durchaus verschiedene Strategien miteinander kombinieren, je nach Bedarf der konkreten Anwendung.
Optimierung durch Redundanz
Eine andere mögliche Abwandlung der »Class Table Inheritance« besteht darin, dass wir in jeder Tabelle alle Attribute der Klasse definieren – auch die von der Oberklasse geerbten. Dies bedeutet, dass die Daten redundant in mehreren Tabellen gespeichert werden und der Speicherbedarf und die Komplexität der Änderung der Daten erhöht werden.
Allerdings brauchen wir dann nur die Tabelle Maschine zu lesen, um alle Maschinendaten, auch die Bezeichnung, zu laden; und es würde reichen, die Tabelle Produkt zu lesen, um die Liste aller Produktbezeichnungen erstellen zu können.
Ob sich eine solche Einführung der Redundanz in eine Datenbank lohnt, muss für jede Anwendung selbst bewertet werden. Bewusst eingesetzt, kann dies durchaus eine sinnvolle Optimierung der Gesamtperformanz sein.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



