

11.2 Umsetzen der Generics, Typlöschung und Raw-Types 
Um Generics zu verstehen und um zu erfahren, was zur Laufzeit an Informationen vorhanden ist, lohnt es sich, sich anzuschauen, wie der Compiler Generics in Bytecode übersetzt.
11.2.1 Realisierungsmöglichkeiten
Im Allgemeinen gibt es zwei Möglichkeiten, generische Typen zu realisieren:
-
Heterogene Variante: Für jeden Typ (etwa String, Integer, Point) wird individueller Code erzeugt, also drei Klassendateien. Die Variante nennt sich auch Codespezialisierung.
-
Homogene Übersetzung: Aus der parametrisierten Klasse wird eine Klasse erzeugt, die anstelle des Typparameters nur zum Beispiel Object einsetzt. Für das konkrete Typargument setzt der Compiler Typumwandlungen in die Anweisungen.
Java nutzt die homogene Übersetzung, und der Compiler erzeugt nur eine Klassendatei. Es gibt keine multiplen Kopien der Klasse – weder im Bytecode noch im Speicher.
11.2.2 Typlöschung (Type Erasure)
Übersetzt der Java-Compiler die generischen Anwendungen, so löscht er dabei alle Typinformationen, da die Java-Laufzeitumgebung keine Generics im Typsystem hat. Das nennt sich Typlöschung (engl. type erasure). Wir können uns das so vorstellen, dass alles wegfällt, was in spitzen Klammern steht, und dass jede Typvariable zu Object wird.[ 213 ](Sind Bounds im Spiel – eine Typeinschränkung, die später noch vorgestellt wird –, wird ein präziserer Typ statt Object genutzt. )
|
Nach der Typlöschung |
|
|---|---|
public class Rocket<T> { |
public class Rocket { |
Tabelle 11.5 Generische Klasse im Quellcode und wie sie nach der Typlöschung aussieht
So entspricht der Programmcode nach der Typlöschung genau dem, was wir selbst auch ohne Generics am Anfang programmiert haben. Auch bei der Nutzung wird gelöscht:
|
Mit Generics |
Nach der Typlöschung |
|---|---|
Rocket<Integer> r = new Rocket<Integer>( 1 ); |
Rocket r = new Rocket( 1 ); |
Tabelle 11.6 Nutzung generischer Klassen und wie es nach der Typlöschung aussieht
Bei dem Ausdruck r.get() fügt der Compiler genau die explizite Typumwandlung ein, die wir in unserem ersten Beispiel noch von Hand eingesetzt haben.
[»] Aber …
Wenn der Compiler Bytecode erzeugt, der auch für ältere JVMs keine Probleme bereitet, so stellt sich die Frage, wo denn die Information darüber abgespeichert ist, ob ein Typ generisch deklariert wurde oder nicht? Irgendwo muss das stehen, denn der Compiler weiß das ja. Die Antwort ist, dass der Compiler diese Typinformationen, die nicht Teil des Typsystems der JVM sind, als Signatur-Attribute in den Konstantenpool des Bytecodes legt. Das Attribut ist ein UTF-8-Text, der von älteren Compilern als Kommentar überlesen wird. Mit dem Disassembler javap und dem Schalter –verbose lassen sich diese Informationen anzeigen.
Das große Ziel: Interoperabilität
Interoperabilität stand bei der Einführung der Generics ganz oben auf der Wunschliste. Zwei wichtige Anforderungen waren:
-
Die mit Generics deklarierten Typen – wie List<E> – müssen auf jeden Fall noch für alten Programmcode, der zum Beispiel mit einem Java 1.4-Compiler erzeugt wurde, nutzbar sein. Das funktioniert so, dass generisch deklarierte Klassen im Bytecode für einen »alten« Compiler oder eine »alte« Laufzeitumgebung so aussehen, als gäbe es keine Generics. Wir sprechen von Typlöschung. Hätte Sun sich nicht dieses Kompatibilitätsziel auf die Fahnen geschrieben, hätte die Umsetzung auch anders ausfallen können. Denn die Konsequenz der Typlöschung ist, dass es keine Informationen über das Typargument zur Laufzeit gibt. Das führt zu Überraschungen und Einschränkungen (insbesondere bei Arrays), die wir uns gleich anschauen werden. Was wir hier vor uns haben, ist der Wunsch nach Bytecode-Kompatibilität.
-
Auf der anderen Seite gibt es neben der Bytecode-Kompatibilität auch noch die Quellcode-Kompatibilität. Alter Programmcode, der zum Beispiel Listen als List list; statt als List<String> list; nutzt, soll immer noch übersetzbar sein, auch wenn er die überarbeiteten Datenstrukturen nicht generisch nutzt. Warnungen sind akzeptabel, aber keine Compilerfehler. Es gibt Millionen Zeilen alten Quellcodes, die Listen ohne Generics nutzen, ohne dass sofort ein Team alle Programmstellen anfasst und Typparameter einführt.
[»] Java Generics und C++-Templates
Java Generics gehen bei den Typbeschreibungen weit über das hinaus, was C++-Templates bieten. In C++ kann ein beliebiges Typargument eingesetzt werden – was zu unglaublichen Fehlermeldungen führt. Der C++-Compiler führt somit eher eine einfache Ersetzung durch. Doch durch die heterogene Umsetzung generiert der C++-Compiler für jeden genutzten Template-Typ unterschiedlichen (und wunderbar optimierten) Maschinencode. Im Fall von Java würde die heterogene Variante zu sehr vielen sehr ähnlichen Klassen führen, die sich nur in ein paar Typumwandlungen unterscheiden. Und da in Java sowieso nur Referenzen als Typvariablen möglich sind und keine primitiven Typen, ist auch eine besondere Optimierung an dieser Stelle nicht möglich. Durch die Codespezialisierung sind aber andere Dinge in C++ machbar, die in Java unmöglich sind, zum Beispiel Template-Metaprogramming. Der Compiler wird in diesem Fall als eine Art Interpreter für rekursive Template-Aufrufe genutzt, um später optimalen Programmcode zu generieren. Das ist funktionale Programmierung mit einem Compiler.
11.2.3 Probleme der Typlöschung
Typlöschung ist für die Laufzeitumgebung praktisch, weil sie überhaupt nicht an die Generics angepasst werden muss. So sehen zum Beispiel die seit Java 5 generisch deklarierten Datenstrukturen nach dem Übersetzungsvorgang genauso aus wie unter Java 1.4 und sind damit voll kompatibel. Sonst aber stellt die Typlöschung ein riesiges Problem dar, weil die Typinformationen zur Laufzeit nicht vorhanden sind.[ 214 ](Dass diese Typinformationen nicht vorliegen, wird auch damit begründet, dass die Laufzeit leiden könnte. Microsoft war das hingegen egal: Dort besteht Generizität in der Common Language Runtime (CLR), also auch in der Laufzeitumgebung. Microsoft ist damit einen klaren Schritt voraus. Doch gab es Generics (Parametric Polymorphism ist der offizielle Name) auch wie in Java nicht von Anfang an; sie zogen erst in Version 2 in die Sprache und CLR ein. Die alten Datenstrukturen wurden einfach als veraltet markiert, und die Entwickler waren gezwungen, auf die neuen generischen Varianten umzusteigen. )
[»] Reified Generics
Generische Parameter sind nicht zur Laufzeit zugänglich. Vielleicht kommt das irgendwann, in Java X, Java 2020 … Das Stichwort dazu lautet Reified Generics, also generische Informationen, die auch zur Laufzeit komplett zugänglich sind.
Kein new T()
Da durch die Typlöschung bei Deklarationen wie Rocket<T> die Parametervariable durch Object ersetzt wird, lässt sich zum Beispiel in der Rakete nicht Folgendes schreiben, um ein neues Transportgut vom Typ T zu erzeugen:
|
Gedacht: mit Generics (Compilerfehler!) |
Konsequenz aus der Typlöschung |
|---|---|
class Rocket<T> { |
class Rocket<T> { |
Tabelle 11.7 Warum »new T()« nicht funktionieren kann: Nur ein »new Object()« würde gebildet.
Als Aufrufer von newRocketContent() erwarten wir aber nicht immer ein lächerliches Object, sondern ein Objekt vom Typ T.
Kein instanceof
Der instanceof-Operator ist bei parametrisierten Typen ungültig, auch wenn sein Einsatz praktisch wäre, um zum Beispiel aufgrund der tatsächlichen Typen eine Fallunterscheidung vornehmen zu können:
void printType( Rocket<?> p ) {
if ( p instanceof Rocket<Number> ) //illegal generic type for instanceof
System.out.println( "Rocket mit Number" );
else if ( p instanceof Rocket<String> ) //
System.out.println( "Rocket mit String" );
}
Der Compiler meldet zu Recht einen Fehler – nicht nur eine Warnung –, weil es die Typen Rocket<String> und Rocket<Number> zur Laufzeit gar nicht gibt: Es sind nur typgelöschte Rocket-Objekte. Nach der Typlöschung würde unsinniger Code entstehen:
Keine Typumwandlungen in parametrisierten Typ
Typumwandlungen wie
Rocket<String> r = (Rocket<String>) new Rocket<Integer>(); //
sind illegal. Wir haben ja extra Generics, damit der Compiler die Typen testet. Und durch die Typlöschung verschwindet das Typargument, sodass der Compiler Folgendes erzeugen würde:
Rocket r = (Rocket) new Rocket();
Kein .class für generische Typen und keine Class-Objekte mit Typargument zur Laufzeit
Ein hinter einen Typ gesetztes .class liefert das Class-Objekt zum jeweiligen Typ:
Class<Object> objectClass = Object.class;
Class<String> stringClass = String.class;
Class selbst ist als generischer Typ deklariert.
Bei generischen Typen ist das .class nicht erlaubt. Zwar ist noch (mit Warnung) Folgendes gültig:
Class<Rocket> rocketClass = Rocket.class;Aber dies nicht mehr:
Class<Rocket<String>> rocketClass = Rocket<String>.class; //
Der Grund ist die Typlöschung: Alle Class-Objekte für einen Typ sind gleich und haben zur Laufzeit keine Information über das Typargument:
Rocket<String> r1 = new Rocket<String>();
Rocket<Integer> r2 = new Rocket<Integer>();
System.out.println( r1.getClass() == r2.getClass() ); // true
Alle Exemplare von generischen Typen werden zur Laufzeit vom gleichen Class-Objekt repräsentiert. Hinter Rocket<String> und Rocket<Integer> steckt also immer nur Rocket. Kurz gesagt: Alles in spitzen Klammern verschwindet zur Laufzeit.
Keine generischen Ausnahmen
Grundsätzlich ist eine Konstruktion wie class MyClass<T> extends SuperClass erlaubt. Aber der Compiler enthält eine spezielle Regel, die verhindert, dass eine generische Klasse Throwable (Exception und Error sind Unterklassen von Throwable) erweitern kann. Wäre zum Beispiel
class MyException<T> extends Exception { } //
erlaubt, könnte im Quellcode vielleicht ein
try { }
catch ( MyException<Typ1> e ) { }
catch ( MyException<Typ2> e ) { }
stehen, doch durch die Typlöschung würde das auf zwei identische catch-Blöcke hinauslaufen, was nicht erlaubt ist.
Keine statischen Eigenschaften
Statische Eigenschaften hängen nicht an einzelnen Objekten, sondern an Klassen. Rocket kann zum Beispiel einmal als parametrisierter Typ Rocket<String> und einmal als Rocket <Integer> auftauchen, also als zwei Instanzen. Aber kann Rocket auch eine statische Methode deklarieren, die auf den Typparameter der Klasse zurückgreift? Nein, das geht nicht. Würden wir in Rocket etwa die folgende statische Methode einsetzen
public static boolean isEmpty( T value ) { return value == null; } //
so gäbe es bei T die Fehlermeldung: »Cannot make a static reference to the non-static type T.«
Statische Variablen und die Parameter/Rückgaben von statischen Methoden sind nicht an ein Exemplar gebunden. Eine Typvariable jedoch, so wie wir sie bisher verwendet haben, ist immer mit dem Exemplar verbunden. Das T für den value ist ja erst immer dann festgelegt, wenn wir zum Beispiel Rocket<String> oder Rocket<Integer> mit einem Exemplar verbinden. Bei Rocket.isEmpty(""); zum Beispiel kann der Compiler nicht wissen, was für ein Typ gemeint ist, da für statische Methodenaufrufe ja keine Exemplare nötig sind, also nie ein parametrisierter Typ festgelegt wurde. Das Nutzen von Code wie Rocket<String>.isEmpty("") führt zu einem Compilerfehler, denn die Syntax ist nicht erlaubt.
Statische generische Methoden sind natürlich möglich, wie wir schon gesehen haben; sie haben dann eine eigene Typvariable.
Kein Überladen mit Typvariablen
Kommt nach der Typlöschung einfach nur Object heraus, kann natürlich keine Methode einmal mit einer Typvariablen und einmal mit Object parametrisiert sein. Folgendes ist nicht erlaubt:
public class Rocket<T> {
public T value;
public void set( T value ) { this.value = value; }
public void set( Object value ) { this.value = value; } //
}
Der Compiler liefert: »Method set(T) has the same erasure set(Object) as another method in type Rocket<T>«.
Ist der Typ spezieller, also etwa String, sieht das wieder anders aus. Dann taucht die Frage auf, welche Methode bei Rocket<String> aufgerufen wird. Die Leser dürfen das gerne prüfen.
Es lassen sich keine Arrays generischer Klassen bilden
Die Nutzung von Generics bei Arrays schränkt der Compiler ebenfalls ein. Während
Rocket[] rockets = new Rocket[1];
gültig ist und mit einer Warnung versehen wird, führt bei
Rocket<String>[] rockets; // (1)
rockets = new Rocket<String>[1]; // (2)
nicht die erste, aber die zweite Zeile zum Compilerfehler »Cannot create a generic array of Rocket<String>«.
Typsicher kann das nicht genutzt werden, aber drei schnelle Lösungen sind denkbar:
-
auf Generics ganz zu verzichten und ein @SuppressWarnings("unchecked") an die Array-Variable zu setzen
-
den Typ durch eine Wildcard zu ersetzen, sodass es etwa zu einem Rocket<?>[] rockets = new Rocket<?>[1]; kommt. Wildcards sind Platzhalter, die in Abschnitt 11.5.3, »Wildcards mit ?«, detaillierter vorgestellt werden.
-
gleich auf Datenstrukturen der Collection-API umzusteigen, bei denen ein Collection <String> rockets = new ArrayList<>(); keine Probleme bereitet
Als Zusammenfassung lässt sich festhalten, dass Array-Variablen von generischen Typen zwar deklariert (1), dass aber keine Array-Objekte gebaut werden können (2). Mit einem Trick funktioniert es:
class RocketFullOfMoney extends Rocket<BigInteger> {}
Rocket<BigInteger>[] rockets = new RocketFullOfMoney[1];
Hübsch ist das nicht, denn es muss extra eine temporäre Klasse angelegt werden.
11.2.4 Raw-Type
Generisch deklarierte Typen müssen nicht unbedingt parametrisiert werden, doch es ist einleuchtend, dass wir dem Compiler so viel Typinformation wie möglich geben sollten. Auf das Typargument zu verzichten, ist nur für die Rückwärtskompatibilität wichtig, da sonst viele parametrisierte neue Klassen nicht mehr mit altem Programmcode verwendet werden könnten. Wenn zum Beispiel Rocket unter Java 1.4 deklariert und mit den Sprachmitteln von Java 5 zu einem generischen Typ verfeinert wurde, kann es immer noch alten Programmcode geben, der wie folgt aussieht:
Rocket r = new Rocket(); // Gefährlich, wie wir gleich sehen werden
r.set( "Was ist die Telefonnummer der NASA? 10 9 8 7 6 5 4 3 2 1." );
String content = (String) r.get();
Ein generischer Typ, der nicht als parametrisierter Typ, also ohne Typargument, genutzt wird, heißt Raw-Type. In unserem Beispiel ist Rocket der Raw-Type von Rocket<T>. Bei einem Raw-Type kann der Compiler die Typkonformität nicht mehr prüfen, denn es ist der Typ nach der Typlöschung; get() liefert Object, und set(Object) kann alles annehmen.
Ein unter Java 1.4 geschriebenes Programm nutzt also nur Raw-Types. Trifft ein aktueller Compiler auf Programmcode, der einen generischen Typ nicht als parametrisierten Typ nutzt, fängt er an zu meckern, denn er wünscht, dass der Typ generisch verwendet wird (siehe Abbildung 11.1).
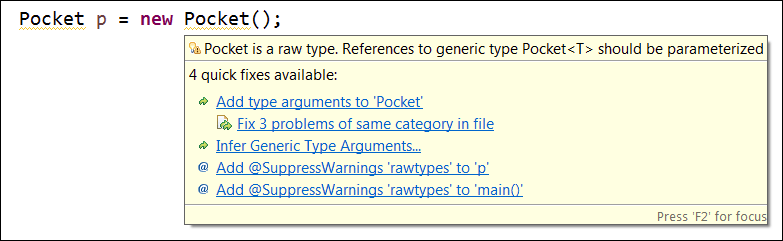
Abbildung 11.1 Eclipse warnt standardmäßig vor Raw-Types.
Auch bei set(…) gibt der Compiler eine Warnung aus, denn er sieht eine Gefahr für die Typsicherheit. Die Methode set(…) ist so entworfen, dass sie ein Argument von dem Typ akzeptiert, mit dem sie parametrisiert wurde. Fehlt durch die Verwendung des Raw-Types der konkrete Typ, bleibt Object, und der Compiler gibt bei den sonst mit einem Typ präzisierten Methoden eine Warnung aus:
p.set( "Type safety: The method set(Object) belongs to the " +
"raw type Rocket. References to generic type " +
"Rocket<T> should be parameterized" );
Der Hinweis besagt, dass die Rakete hätte typisiert werden müssen. Wenn wir nicht darauf achten, kann das schnell zu Problemen führen:
Rocket<String> r1 = new Rocket<>();
Rocket r2 = r1; // Compilerwarnung
r2.set( new java.util.Date() ); // Compilerwarnung
String string = r1.get(); //
System.out.println( string );
Der Compiler gibt keinen Fehler, aber Warnungen aus. Die dritte Zeile ist hochgradig problematisch, denn über die nicht parametrisierte Rakete können wir beliebige Objekte eintüten. Da aber das Objekt hinter r2 und dem typgelöschten r1 identisch ist, haben wir ein Typproblem, das zur Laufzeit zu einer ClassCastException führt:
Exception in thread "main" java.lang.ClassCastException: java.util.Date cannot be
cast to java.lang.String
Es kann also nur die Empfehlung ausgesprochen werden, Raw-Types in neuen Programmen zu vermeiden, da ihre Verwendung zu Ausnahmen führen kann, die erst zur Laufzeit auffallen.
Typumwandlungen
Ein Raw-Type lässt sich automatisch in eine speziellere Form bringen, wobei es natürlich Warnungen vom Compiler gibt:
Rocket r = new Rocket(); // (1) Warnung
r.set( "Roh macht nicht froh" ); // (2) Warnung
Rocket<Point> stringRocket = r; // (3) Warnung
Point result = stringRocket.get(); // (4) ClassCastException zur Laufzeit
Bei der Variablen p, die wir über den Raw-Type nutzen (2), prüft der Compiler gar keine Typen in set(…), denn er hat sie ja nie kennengelernt.
Zeile (3) verkauft dem Compiler den Raw-Type als parametrisierten Typ. Eine explizite Typumwandlung ist nicht nötig, denn Typumwandlungen sind nur zwischen »echten« Typen gültig, wie Object auf Rocket, nicht aber von Rocket auf Rocket<String>, da Rocket<String> ja der gleiche Class-Typ ist (siehe Abschnitt 11.2.3, »Probleme der Typlöschung«).
Eine Anweisung wie (4), die keinen String-Typ aus der Rakete holt, führt zu keinem Fehler zur Übersetzungszeit, sondern es knallt wegen einer internen Typumwandlung zur Laufzeit. So kann über diese Raw-nicht-raw-Hintertür ein falscher Typ in die Rakete kommen.

Abbildung 11.2 Warnung von Eclipse bei Raw-Types
Annotation SuppressWarnings
In seltenen Fällen muss in den Typ konvertiert werden. Als Beispiel soll cast(Object) dienen:
public <T> T cast( Object obj ) {
return (T) obj; // Compilerwarnung: Type safety: Unchecked cast from Object to T
}
Lässt sich der Cast nicht vermeiden, um dem Compiler den Typ zu geben und ihn somit glücklich zu machen, setzen wir eine @SuppressWarnings-Annotation:
@SuppressWarnings("unchecked")
public <T> T cast( Object obj ) {
return (T) obj;
}
Die Generics bieten uns Möglichkeiten, den Quellcode sicherer zu machen. Wir sollten diese Sicherheit nicht durch Raw-Types kaputtmachen.
 Unter den Preferences von Eclipse können drei Typen von Hinweisen für die Nutzung von Raw-Types angegeben werden: Der Compiler gibt einen harten Compilerfehler aus, eine Warnung, oder er ignoriert Raw-Types. Dass er Warnungen ausgibt, ist voreingestellt, und diese Vorgabe ist ganz gut.
Unter den Preferences von Eclipse können drei Typen von Hinweisen für die Nutzung von Raw-Types angegeben werden: Der Compiler gibt einen harten Compilerfehler aus, eine Warnung, oder er ignoriert Raw-Types. Dass er Warnungen ausgibt, ist voreingestellt, und diese Vorgabe ist ganz gut.
 Java ist auch eine Insel
Java ist auch eine Insel Jetzt Buch bestellen
Jetzt Buch bestellen


