

4 Arrays und ihre Anwendungen 
»Die aus der Reihe fallen, bilden den Anfang einer neuen Reihe.«
– Erhard Horst Bellermann (*1937)[ 120 ](http://ebellermann.wordpress.com)
4.1 Einfache Feldarbeit
Ein Array (auch auf Deutsch Feld oder Reihung genannt) ist ein spezieller Datentyp, der mehrere Werte zu einer Einheit zusammenfasst. Er ist mit einem Setzkasten vergleichbar, in dem die Plätze durchnummeriert sind. Angesprochen werden die Elemente über einen ganzzahligen Index. Jeder Platz (etwa für Schlümpfe) nimmt immer Werte des gleichen Typs auf (nur Schlümpfe und keine Pokémon). Normalerweise liegen die Plätze eines Arrays (seine Elemente) im Speicher hintereinander, doch ist dies ein für Programmierer nicht sichtbares Implementierungsdetail der virtuellen Maschine.
Jedes Array beinhaltet Werte nur eines bestimmten Datentyps bzw. Grundtyps. Dies können sein:
-
elementare Datentypen wie int, byte, long usw.
-
Referenztypen
-
Referenztypen anderer Arrays, um mehrdimensionale Arrays zu realisieren
4.1.1 Grundbestandteile
Für das Arbeiten mit Arrays müssen wir drei neue Dinge kennenlernen:
-
das Deklarieren von Array-Variablen
-
das Initialisieren von Array-Variablen sowie die Platzbeschaffung
-
den Zugriff auf Arrays, den lesenden Zugriff ebenso wie den schreibenden
[zB] Beispiel
-
Deklariere eine Variable randoms, die ein Array referenziert:
double[] randoms; -
Initialisiere die Variable mit einem Array-Objekt der Größe 10:
randoms = new double[ 10 ];
-
Belege das erste Element mit einer Zufallszahl und das zweite Element mit dem Doppelten des ersten Elements:
randoms[ 0 ] = Math.random();
randoms[ 1 ] = randoms[ 0 ] * 2;
Wir sehen, dass eckige Klammern an verschiedenen Stellen zum Einsatz kommen: einmal zur Deklaration des Typs, dann zum Aufbau des Arrays, dann zum Schreiben in Arrays und zum Lesen aus Arrays.
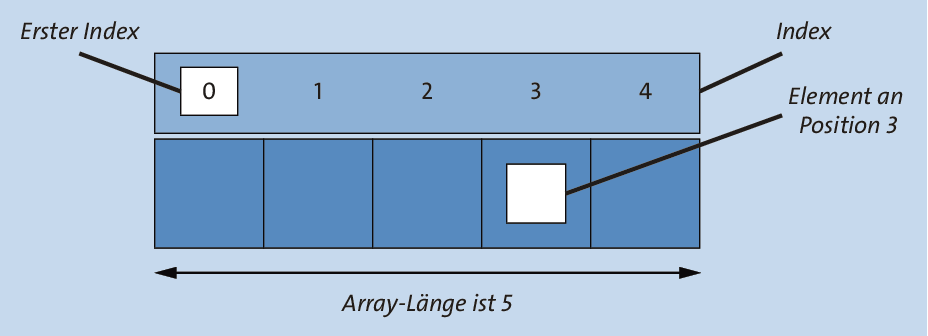
Abbildung 4.1 Begriffe eines Arrays
Diese drei Punkte schauen wir uns nun detaillierter an.
4.1.2 Deklaration von Array-Variablen
Die Deklaration einer Array-Variablen ähnelt einer gewöhnlichen Deklaration, nur dass nach dem Datentyp die Zeichen [ und ] gesetzt werden.
[zB] Beispiel
Deklariere zwei Array-Variablen:
int[] primes;
double[] incomm;
Eine Variable wie primes hat jetzt den Typ »ist Array« und »speichert int-Elemente«, also eigentlich zwei Typen.
[»] Hinweis
Die eckigen Klammern lassen sich bei der Deklaration einer Array-Variablen auch hinter den Namen setzen, doch ganz ohne Unterschied ist die Deklaration nicht. Das zeigt sich spätestens dann, wenn mehr als eine Variable deklariert wird:
int []primes,
matrix[], threeDimMatrix[][];
Das entspricht dieser Deklaration:
int primes[], matrix[][], threeDimMatrix[][][];
Damit Irrtümer dieser Art ausgeschlossen werden, sollten Sie in jeder Zeile nur eine Deklaration eines Typs schreiben. Nach reiner Java-Lehre gehören die Klammern jedenfalls hinter den Typbezeichner, so hat es der Java-Schöpfer James Gosling gewollt.
Arrays mit nichtprimitiven Elementen
Der Datentyp der Array-Elemente muss nicht zwingend ein primitiver sein. Auch ein Array von Objektreferenzen kann deklariert werden. Dieses Array besteht dann nur aus Referenzen auf die eigentlichen Objekte, die in dem Array abgelegt werden sollen. Die Größe des Arrays im Speicher errechnet sich demnach aus der Länge des Arrays, multipliziert mit dem Speicherbedarf einer Referenzvariablen. Nur das Array-Objekt selbst wird angelegt, nicht aber die Objekte, die das Array aufnehmen soll. Dies lässt sich einfach damit begründen, dass der Compiler auch gar nicht wüsste, welchen Konstruktor er aufrufen sollte.
[zB] Beispiel
Deklariere zwei Array-Variablen:
String[] names;
Point[] locations;
4.1.3 Array-Objekte mit new erzeugen
Das Anlegen der Array-Referenzvariablen allein erzeugt noch kein Array mit einer bestimmten Länge. In Java ist das Anlegen des Arrays genauso dynamisch wie die Objekterzeugung. Ein Array muss mit dem Schlüsselwort new erzeugt werden, da Arrays Objekte sind.[ 121 ](Programmiersprachen wie C(++) bieten bei der Felderzeugung Abkürzungen wie int array[100]. Das führt in Java zu einem Compilerfehler. ) Die Länge des Arrays wird in eckigen Klammern angegeben. Hier kann ein beliebiger Integer-Wert stehen, auch eine Variable. Selbst 0 ist möglich. Später kann die Größe nicht mehr verändert werden.
[zB] Beispiel
Erzeuge ein Array für zehn Elemente:
int[] values;
values = new int[ 10 ];
Die Array-Deklaration ist auch zusammen mit der Initialisierung möglich:
double[] values = new double[ 10 ];
Die JVM initialisiert die Arrays standardmäßig: bei primitiven Werten mit 0, 0.0 oder false und bei Verweisen mit null.
Arrays sind ganz normale Objekte
Dass Arrays Objekte sind, zeigen einige Indizien:
-
Eine spezielle Form der new-Schreibweise erzeugt ein Exemplar der Array-Klasse; new erinnert uns immer daran, dass ein Objekt zur Laufzeit aufgebaut wird.
-
Ein Array-Objekt kennt das Attribut length, und auf dem Array-Objekt sind Methoden – wie clone() und alles, was java.lang.Object hat – definiert.
-
Die Operatoren == und != haben ihre Objektbedeutung: Sie vergleichen lediglich, ob zwei Variablen auf das identische Array-Objekt verweisen, aber auf keinen Fall die Inhalte der Arrays (das kann aber Arrays.equals(…)).
Der Zugriff auf die Array-Elemente über die eckigen Klammern [] lässt sich als versteckter Aufruf über geheime Methoden wie array.get(index) verstehen. Der []-Operator wird bei anderen Objekten nicht angeboten.
4.1.4 Arrays mit { Inhalt }
Die bisherigen Deklarationen von Array-Variablen erzeugen noch lange kein Array-Objekt, das die einzelnen Array-Elemente aufnehmen kann. Wenn allerdings die Einträge direkt mit Werten belegt werden sollen, gibt es in Java eine Abkürzung, die ein Array-Objekt anlegt und zugleich mit Werten belegt.
[zB] Beispiel
Wertebelegung eines Arrays bei der Initialisierung:
int[] primes = { 2, 3, 5, 7, 7 + 4 };
String[] strings = {
"Haus", "Maus",
"dog".toUpperCase(), // DOG
new java.awt.Point().toString(),
};
In diesem Fall wird ein Array mit passender Größe angelegt, und die Elemente, die in der Aufzählung genannt sind, werden in das Array kopiert. Innerhalb der Aufzählung kann abschließend ein Komma stehen, wie die Aufzählung bei strings demonstriert.
[»] Hinweis
Auch leere Arrays ohne Inhalt sind erlaubt. Die Arrays sind initialisiert, haben aber keine Elemente und ihre length ist 0. Zwei Beispiele:
String names[] = {};oder
int primes[] = new int[0]
Es ist möglich, dass vor der schließenden geschweiften Klammer noch ein Komma folgt, sodass es etwa int[] primes = { 2, 3, }; heißt. Das vereinfacht das Hinzufügen, ein leeres Element produziert es nicht. Selbst Folgendes ist in Java möglich: int[] primes = { , };.
[»] Hinweis
Die Deklaration einer Array-Variablen mit Initialisierung funktioniert mit var nicht:
var primes = { 2, 3 }; //Array initializer needs an explicit target-type
4.1.5 Die Länge eines Arrays über das Attribut length auslesen
Die Anzahl der Elemente, die ein Array aufnehmen kann, wird Größe oder Länge genannt und ist für jedes Array-Objekt in der frei zugänglichen Objektvariablen length gespeichert. length ist eine public-final-int-Variable, deren Wert entweder positiv oder null ist. Die Größe lässt sich später nicht mehr ändern.
[zB] Beispiel
Ein Array und die Ausgabe der Länge:
int[] primes = { 2, 3, 5, 7, 7 + 4 };
System.out.println( primes.length ); // 5
Array-Längen sind final
Das Attribut length eines Arrays ist nicht nur öffentlich (public) und vom Typ int, sondern natürlich auch final. Schreibzugriffe sind nicht gestattet, denn eine dynamische Vergrößerung eines Arrays ist nicht möglich; ein Schreibzugriff führt zu einem Übersetzungsfehler.
4.1.6 Zugriff auf die Elemente über den Index
Der Zugriff auf die Elemente eines Arrays erfolgt mithilfe der eckigen Klammern [], die hinter die Referenz an das Array-Objekt gesetzt werden. In Java beginnt ein Array beim Index 0 (und nicht bei einer frei wählbaren Untergrenze wie in Pascal). Da die Elemente eines Arrays ab 0 nummeriert werden, ist der letzte gültige Index um 1 kleiner als die Länge des Arrays. Das heißt: Bei einem Array a der Länge n ist der gültige Bereich a[0] bis a[n – 1].
Da der Zugriff auf die Variablen über einen Index erfolgt, werden diese Variablen auch indexierte Variablen genannt.
[zB] Beispiel
Greife auf das erste und letzte Zeichen aus dem Array zu:
char[] name = { 'C', 'h', 'r', 'i', 's' };
char first = name[ 0 ]; // C
char last = name[ name.length - 1 ]; // s
[zB] Beispiel
Laufe das Array der ersten Primzahlen komplett ab:
int[] primes = { 2, 3, 5, 7, 11 };
for ( int i = 0; i < primes.length; i++ ) // Index: 0 <= i < 5 = primes.length
System.out.println( primes[ i ] );
Anstatt ein Array einfach nur so abzulaufen und die Werte auszugeben, soll unser nächstes Programm den Mittelwert einer Zahlenfolge berechnen und ausgeben:
Listing 4.1 src/main/java/com/tutego/insel/array/PrintTheAverage.java
public class PrintTheAverage {
public static void main( String[] args ) {
double[] numbers = { 1.9, 7.8, 2.4, 9.3 };
double sum = 0;
for ( int i = 0; i < numbers.length; i++ )
sum += numbers[ i ];
double avg = sum / numbers.length;
System.out.println( avg ); // 5.35
}
}
Das Array muss mindestens ein Element besitzen, sonst gibt es bei der Division durch 0 eine Ausnahme.
Über den Typ des Index *
Innerhalb der eckigen Klammern steht ein positiver Ganzzahl-Ausdruck vom Typ int, der sich zur Laufzeit berechnen lassen muss. long-Werte, boolean, Gleitkommazahlen oder Referenzen sind nicht möglich; durch int verbleiben aber mehr als zwei Milliarden Elemente. Bei Gleitkommazahlen bliebe die Frage nach der Zugriffstechnik. Hier müssten wir den Wert auf ein Intervall herunterrechnen.
[»] Hinweis
Der Index eines Arrays muss vom Typ int sein, das schließt Anpassungen von byte, short und char ein. Günstig ist ein Index vom Typ char, zum Beispiel als Laufvariable, wenn Arrays von Zeichen generiert werden:
char[] alphabet = new char[ 'z' - 'a' + 1 ]; // 'a' entspricht 97 und 'z' 122
for ( char c = 'a'; c <= 'z'; c++ )
alphabet[ c - 'a' ] = c; // alphabet[0]='a', alphabet[1]='b', usw.
Genau genommen haben wir es auch hier mit Indexwerten vom Typ int zu tun, weil mit den char-Werten vorher noch gerechnet wird.
Strings sind keine Arrays *
Ein Array von char-Zeichen hat einen ganz anderen Typ als ein String-Objekt. Während bei Arrays eckige Klammern erlaubt sind, bietet die String-Klasse keinen Zugriff auf Zeichen über []. Die Klasse String bietet jedoch einen Konstruktor an, sodass aus einem Array mit Zeichen ein String-Objekt erzeugt werden kann. Alle Zeichen des Arrays werden kopiert, sodass anschließend Array und String keine Verbindung mehr besitzen. Dies bedeutet: Wenn sich das Array ändert, ändert sich der String nicht automatisch mit. Das kann er auch nicht, da Strings unveränderlich sind.
4.1.7 Typische Array-Fehler
Beim Zugriff auf ein Array-Element können Fehler auftreten. Zunächst einmal kann das Array-Objekt fehlen, sodass die Referenzierung fehlschlägt.
[zB] Beispiel
Der Compiler bemerkt den folgenden Fehler nicht, und die Strafe ist eine NullPointerException zur Laufzeit:[ 122 ](Obwohl er sich bei nicht initialisierten lokalen Variablen auch beschwert. )
int[] array = null;
array[ 1 ] = 1; //
Weitere Fehler können im Index begründet sein. Ist der Index negativ[ 123 ](Ganz anders verhalten sich da Python oder Perl. Dort wird ein negativer Index dazu verwendet, ein Feldelement relativ zum letzten Array-Eintrag anzusprechen. Und auch bei C ist ein negativer Index durchaus möglich und praktisch. ) oder zu groß, dann gibt es eine IndexOutOfBoundsException. Jeder Zugriff auf das Array wird zur Laufzeit getestet, auch wenn der Compiler durchaus einige Fehler finden könnte.
[zB] Beispiel
Bei folgenden Zugriffen könnte der Compiler theoretisch Alarm schlagen, was aber zumindest der Standard-Compiler nicht tut. Der Grund ist, dass der Zugriff auf die Elemente auch mit einem ungültigen Index syntaktisch völlig in Ordnung ist.
int[] array = new int[ 100 ];
array[ -10 ] = 1; //
array[ 100 ] = 1; //
Wird die IndexOutOfBoundsException nicht abgefangen, bricht das Laufzeitsystem das Programm mit einer Fehlermeldung ab. Dass die Array-Grenzen überprüft werden, ist Teil von Javas Sicherheitskonzept und lässt sich nicht abstellen. Es ist aber heute kein großes Performance-Problem mehr, da die Laufzeitumgebung nicht jeden Index prüfen muss, um sicherzustellen, dass ein Block mit Array-Zugriff korrekt ist.
Spielerei: Der Index und das Inkrement *
Wir haben beim Inkrement schon ein Phänomen wie i = i++ betrachtet. Ebenso ist die Anweisung bei einem Array-Zugriff zu behandeln:
array[ i ] = i++;
Bei der Position array[i] wird i gesichert und anschließend die Zuweisung vorgenommen. Wenn wir eine Schleife um das Array herum konstruieren, erweitern wir dies zu einer Initialisierung:
Die Initialisierung ergibt 0, 1, 2 und 3. Von der Anwendung ist wegen mangelnder Übersichtlichkeit abzuraten.
4.1.8 Arrays an Methoden übergeben
Verweise auf Arrays lassen sich bei Methoden genauso übergeben wie Verweise auf ganz normale Objekte. In der Deklaration heißt es dann zum Beispiel foo(int[] val) statt foo(String val).
Wir haben bereits den Mittelwert einer Zahlenreihe ermittelt. Die Logik dafür ist perfekt in eine Methode ausgelagert:
Listing 4.2 src/main/java/com/tutego/insel/array/Avg1.java
public class Avg1 {
static double avg( double[] array ) {
double sum = 0;
for ( int i = 0; i < array.length; i++ )
sum += array[ i ];
return sum / array.length;
}
public static void main( String[] args ) {
double[] numbers = { 2, 3, 4 };
System.out.println( avg( numbers ) ); // 3.0
}
}
null-Referenzen prüfen
Referenzen bringen immer das Problem mit sich, dass sie null sein können. Syntaktisch gültig ist ein Aufruf von avg(null). Daher sollte eine Implementierung auf null testen und ein falsches Argument melden, etwa so:
if ( array == null || array.length == 0 )
throw new IllegalArgumentException( "Array null oder leer" );
Zu den Details siehe Kapitel 8, »Ausnahmen müssen sein«.
4.1.9 Mehrere Rückgabewerte *
Wenn wir in Java Methoden schreiben, dann haben sie über return höchstens einen Rückgabewert. Wollen wir aber mehr als einen Wert zurückgeben, müssen wir eine andere Lösung suchen. Zwei Ideen lassen sich verwirklichen:
-
Behälter wie Arrays oder andere Sammlungen fassen Werte zusammen und liefern sie als Rückgabe.
-
Spezielle Behälter werden übergeben, in denen die Methode Rückgabewerte platziert; eine return-Anweisung ist nicht mehr nötig.
Betrachten wir eine statische Methode, die für zwei Zahlen die Summe und das Produkt als Array liefert:
Listing 4.3 src/main/java/com/tutego/insel/array/MultipleReturnValues.java, Ausschnitt
static int[] productAndSum( int a, int b ) {
return new int[]{ a * b, a + b };
}
public static void main( String[] args ) {
System.out.println( productAndSum(9, 3)[ 1 ] );
}
4.1.10 Vorinitialisierte Arrays
Wenn wir in Java ein Array-Objekt erzeugen und gleich mit Werten initialisieren wollen, dann schreiben wir etwa:
int[] primes = { 2, 3, 5, 7, 11, 13 };
Java erlaubt es nicht, Array-Inhalte nach der Variablendeklaration zu initialisieren oder das Array auch ohne Variable als Argument zu nutzen:
primes = { 2, 5, 7, 11, 13 }; // Compilerfehler
avg( { 1.23, 4.94, 9.33, 3.91, 6.34 } ); // CompilerfehlerEin Versuch wie dieser schlägt mit der Compilermeldung »Array constants can only be used in initializers« fehl.
Zur Lösung gibt es zwei Ansätze. Der erste ist die Einführung einer neuen Variablen, hier tmpprimes:
int[] primes;
int[] tmpprimes = { 2, 5, 7, 11, 13 };
primes = tmpprimes;
Als zweiten Ansatz gibt es eine Variante der new-Schreibweise, die durch ein Paar eckiger Klammern erweitert wird. Es folgen in geschweiften Klammern die Initialwerte des Arrays. Die Größe des Arrays entspricht genau der Anzahl der Werte. Für die oberen Beispiele ergibt sich folgende Schreibweise:
int[] primes;
primes = new int[]{ 2, 5, 7, 11, 13 };
Diese Notation ist auch bei Methodenaufrufen sehr praktisch, wenn Arrays übergeben werden:
avg( new double[]{ 1.23, 4.94, 9.33, 3.91, 6.34 } );
Da hier ein initialisiertes Array mit Werten gleich an die Methode übergeben wird und keine zusätzliche Variable benutzt wird, heißt diese Art der Arrays anonyme Arrays. Eigentlich gibt es auch sonst anonyme Arrays, wie new int[2000].length zeigt, doch wird in diesem Fall das Array nicht mit eigenen Werten initialisiert.
Die Wahrheit über die Array-Initialisierung *
So schön die kompakte Initialisierung der Array-Elemente ist, so laufzeit- und speicherintensiv ist sie auch. Da Java eine dynamische Sprache ist, passt das Konzept der Array-Initialisierung nicht ganz in das Bild. Daher wird die Initialisierung auch erst zur Laufzeit durchgeführt.
Unser Primzahl-Array
int[] primes = { 2, 3, 5, 7, 11, 13 };
wird vom Java-Compiler umgeformt und analog zu Folgendem behandelt:
int[] primes = new int[ 6 ];
primes[ 0 ] = 2;
primes[ 1 ] = 3;
primes[ 2 ] = 5;
primes[ 3 ] = 7;
primes[ 4 ] = 11;
primes[ 5 ] = 13;
Erst nach kurzem Überlegen wird das Ausmaß der Umsetzung sichtbar: Zunächst ist es der Speicherbedarf für die Methoden. Ist das Array primes in einer Methode deklariert und mit Werten initialisiert, kostet die Zuweisung Laufzeit, da wir viele Zugriffe haben, die auch alle schön durch die Indexüberprüfung gesichert sind. Da zudem der Bytecode für eine einzelne Methode wegen diverser Beschränkungen in der JVM nur beschränkt lang sein darf, kann dieser Platz für richtig große Arrays schnell erschöpft sein. Daher ist davon abzuraten, etwa Bilder oder große Tabellen im Programmcode zu speichern. Unter C war es populär, ein Programm einzusetzen, das eine Datei in eine Folge von Array-Deklarationen verwandelte. Ist dies in Java wirklich nötig, sollten wir Folgendes in Betracht ziehen:
-
Wir verwenden ein statisches Array (eine Klassenvariable), sodass das Array nur einmal während des Programmlaufs initialisiert werden muss.
-
Liegen die Werte im Byte-Bereich, können wir sie in einen String konvertieren und später den String in ein Array umwandeln. Das ist eine sehr clevere Methode, Binärdaten einfach unterzubringen.
 Java ist auch eine Insel
Java ist auch eine Insel Jetzt Buch bestellen
Jetzt Buch bestellen


