


23.8 Das HTTP-Protokoll 

Das Hypertext Transfer Protocol (kurz HTTP) ist das Protokoll, mit dem sich der Webbrowser und der Webserver über das Internet miteinander unterhalten. Und da CGI auf dem HTTP-Protokoll aufbaut, ist es recht sinnvoll, sich auch ein wenig damit auszukennen. Natürlich ist es nicht meine Absicht, Ihnen alles über das Thema mitzuteilen, sondern nur das Wichtigste. Sollten Sie mehr Informationen benötigen, kann ich Ihnen die Webseite www.w3.org/Protocols/ empfehlen.
23.8.1 Web-Protokolle
Der Sinn dieses Abschnitts ist es, zu erklären, wo das HTTP-Protokoll seinen Platz in der Netzwerktechnik hat. Es gibt natürlich weitaus mehr Protokolle für das Web als nur HTTP. Beispiele wären das File-Transfer-Protokoll (besser bekannt als FTP), das TELNET-Protokoll, das Simple-Mail-Transfer-Protokoll (SMTP) und noch eine Menge mehr. Für Sie als CGI-Programmierer ist das HTTP-Protokoll am meisten von Interesse.
23.8.2 Wozu dienen Protokolle?
Im Prinzip können Sie die Protokolle der Netzwerktechnik mit Sprachen vergleichen. In aller Welt sprechen die Menschen gut tausend verschiedene Sprachen. Wenn Sie sich mit jedem Menschen auf der Welt unterhalten wollten, müssten Sie alle diese Sprachen beherrschen – ein schwieriges Unterfangen. Würde dasselbe auf Computer angewendet, ließe sich wohl kaum noch eine Webseite darstellen. Sie würden dann wahrscheinlich eine Fehlermeldung erhalten wie: Diese Webseite kann nicht angezeigt werden, da Ihr System das Protokoll nicht versteht.
23.8.3 Was ist ein Protokoll?
Protokolle sind eine Mischung aus Kommunikationsregeln und Nachrichtenformaten, deren Regeln vernetzte Computer befolgen müssen, wenn Sie Daten miteinander austauschen wollen. Werden z. B. Daten von Computer Ernie zum Computer Bert versendet, so werden diese zunächst in eine Nachricht verpackt. Diese Nachricht wird in einer bestimmten Kommunikationsregel des Protokolls definiert. In der Kommunikationsregel wird z. B. beschrieben, wie die Nachricht beim Zielrechner Bert behandelt werden soll, wenn ein Fehler bei der Übertragung auftritt. Zur Übertragung von Daten wird das IP-Protokoll (Internet Protocol) verwendet.
Die Sprache der Computer ist nicht ganz so komplex wie die des Menschen. Der Computer verständigt sich mit anderen Gleichgesinnten durch die Binärzahlen 0 und 1. Trotz dieser universellen Sprache sind nicht alle Computer vom gleichen Typ. Angefangen bei unterschiedlicher Hardware bis hin zu einem anderen Betriebssystem kann es dabei ziemliche Verständigungsprobleme geben. Und Protokolle sind sozusagen die Dolmetscher, die die Probleme der Kommunikation lösen. Damit ist es erst möglich, dass sich unterschiedliche Computertypen mit unterschiedlichen Betriebssystemen verständigen können.
23.8.4 Normen für die Netzwerktechnik
Damit jetzt die vernetzten Computer mit einheitlichen Protokollen miteinander kommunizieren können, musste zunächst eine einheitliche Netzwerktechnik entwickelt werden. Eine Normung war auch allmählich notwendig, denn durch die fortschreitende Entwicklung von Netzwerkkomponenten kamen im Laufe der Zeit immer mehr herstellerspezifische Netzwerke und Protokolle zustande. Dass dabei mit zunehmender Vernetzung immer mehr Probleme auftraten, liegt auf der Hand.
1978 hat sich dann ein Gremium mit dem Namen ISO (International Organization for Standardization) zusammengefunden, mit dem Ziel, eine Schnittstelle zu standardisieren, die für die Vernetzung von PCs in Betracht kommen könnte. Es dauerte danach weitere sechs Jahre, bis das ISO-Komitee einen Standard bekanntgab. Der Standard wurde Open System Interconnection (kurz OSI) genannt. Mit OSI wurde festgelegt, wie die Kommunikation der unterschiedlichen Rechner mit diversen Protokollen stattzufinden hat.
23.8.5 Das OSI-Schichtenmodell
Mit Einführung des OSI-Modells wurden endlich einheitliche Produkte für den Netzwerkeinsatz entwickelt, da die Hersteller gezwungen waren, sich an diesen Vorgaben zu orientieren. Es muss aber hinzugefügt werden, dass dies allein noch lange keine Realisierung aller Standards bedeutet. Beim OSI-Referenzmodell handelt es sich um ein geprüftes und bewährtes Modell für die Hard- und Softwareentwicklung. Ob und wie die Hersteller dieses Modell anwenden, bleibt immer noch deren Angelegenheit.
Das genormte OSI-Schichtenmodell wurde auf sieben Schichten verteilt. Jede Schicht hat dabei ihre eigene Aufgabe. Abbildung 23.9 gibt einen kurzen Überblick über diese sieben Schichten und die Protokolle, die die einzelnen Schichten nutzen können.
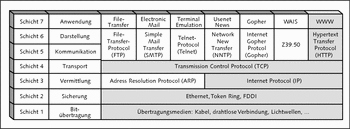
Abbildung 23.9 Das OSI-Schichtenmodell und die Protokolle
Nicht abgebildet sind hier die UDP-Protokolle. Das HTTP-Protokoll (in der Abbildung grau eingefärbt), das Sie zur CGI-Programmierung verwenden, ist über dem TCP-Protokoll angesiedelt. Der gesamte Webverkehr verläuft über das TCP/IP-Protokoll.
23.8.6 Die Elemente einer URL
Häufig begegnen Sie einer URL (Uniform Resource Locator), deren Bedeutung einem zunächst fremd erscheint. Betrachten Sie folgende URL:
Diese URL soll jetzt in ihre Einzelteile zerlegt werden.
»http« (Schema)
http ist das verwendete Protokoll, über das der Webbrowser mit dem Webserver kommuniziert. Es gibt natürlich noch mehr Protokolle außer dem HTTP. Mehr dazu erfahren Sie gleich bei den Ports. Danach folgt der Rechnername.
»www.pronix.de« (Rechnername)
Bei www.pronix.de handelt es sich um den Namen des Rechners, auf dem sich die Webseite oder das Dokument befindet. Dies kann aber auch eine IP-Adresse (beispielsweise http://127.0.0.1) und muss nicht immer ein Domainname (http://www.pronix.de) sein.
»80« (Portnummer)
Der Webserver nimmt hier über Port 80 einen Auftrag entgegen. Dass dieser Port bei der URL nicht angegeben werden muss, liegt daran, dass Port 80 der voreingestellte Port des HTTP-Protokolls ist.
Die Daten müssen aber nicht immer über Port 80 übertragen werden. Sie können genauso gut einen Server konfigurieren, mit dem Sie Daten über den Port 85 empfangen können. Folgende Ports und ihre Protokolle sind in der Regel voreingestellt:
| Protokoll | Port |
|
FTP (Datenverbindung) |
20 |
|
FTP (Steuerverbindung) |
21 |
|
Telnet |
23 |
|
SMTP |
25 |
|
DNS |
53 |
|
http |
80 |
|
HTTPS (SSL-verschlüsselt) |
443 |
|
POP3 |
110 |
|
NNTP |
119 |
|
LDAP (Standard) |
389 |
|
LDAP (SSL-verschlüsselt) |
636 |
»/cgi/name.cgi« (Pfadangabe)
Damit wird der Ort des gespeicherten Dokuments auf dem Webserver bezeichnet.
»?vorname=Clint&nachname=East« (Query-String)
Der Query-String kann aus mehreren Paaren von Namen und den dazugehörenden Werten bestehen. Die einzelnen Paare werden mit dem Zeichen & voneinander getrennt. Die Variable und der Wert werden mit einem = getrennt. In diesem Beispiel haben Sie folgende zwei Paare:
Variable des ersten Paars: vorname; Wert des ersten Paars: Clint Variable des zweiten Paars: nachname;Wert des zweiten Paars: East
Der Query-String wird noch ausführlicher behandelt.
23.8.7 Client-Anfrage – HTTP-Request (Browser-Request)
Das Erste bei einer HTTP-Verbindung ist immer die Anfrage (HTTP-Request) des Webbrowsers an den Webserver. Wenn Sie beispielsweise in Ihrem Browser die URL
eingeben und ![]() drücken, schickt der Browser eine Anfrage an den Webserver, die aus zwei Teilen besteht: zum einen aus der Anforderungszeile und zum anderen aus den Header-Feldern. Das sieht dann so aus:
drücken, schickt der Browser eine Anfrage an den Webserver, die aus zwei Teilen besteht: zum einen aus der Anforderungszeile und zum anderen aus den Header-Feldern. Das sieht dann so aus:
GET /index.html HTTP/1.1 Host: www.pronix.de Accept: image/gif, image/jpeg, image/pjpeg, */* Accept-Language: de Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1) Referer: ... ...
Die erste Zeile ist die sogenannte Request-Zeile:
GET /index.html HTTP/1.1
GET ist dabei die Request-Methode, mit der eine Ressource vom Server angefordert wird, ohne dass dabei irgendwelche Daten auf dem Server verändert werden. GET ist die Standard-Methode, wenn ein Browser per HTTP ein Dokument anfordert. In diesem Beispiel wird die Datei index.html angefordert. Das Protokoll, durch das der Webbrowser und der Webserver sich unterhalten sollen, ist hier HTTP mit der Versionsnummer 1.1.
Eine andere häufig verwendete Request-Methode ist POST. Im Wesentlichen unterscheiden sich diese beiden Methoden zur Datenübermittlung in der Art, wie die Daten an den Webserver übergeben werden.
Um Ihnen den Unterschied zwischen den beiden Request-Methoden GET und POST etwas deutlicher zu machen, folgt hier eine kurze theoretische Beschreibung.
GET
Hier soll bei einem HTML-Formular einfach die Eingabe eines Textfeldes ausgewertet werden. Ich verwende hierfür folgenden HTML-Code:
<form action="http://localhost/cgi-bin/auswert.cgi" method=get> <b>Bitte geben Sie Ihren Namen ein : </b> <input value="hallo" name="Textfeld" size="20"> <input type=submit value="abschicken"> </form>
Dadurch entsteht das folgende Textfeld mit einem Button:

Abbildung 23.10 Eingabefeld mit Button
Mit der Zeile
<form action="http://localhost/cgi-bin/auswert.cgi" method=get>
fordern Sie das CGI-Programm auswert.cgi mit der Methode GET (method=get) an. Dabei können Sie auch gleich sehen, wie Sie die Methode des HTTP-Requests bestimmen können. Beim Drücken des Buttons wird die CGI-Anwendung auf dem Server aufgerufen. Ein Blick auf die URL des Webbrowsers zeigt Folgendes:
Den Query-String können Sie jetzt auf dem Webserver mit der CGI-Anwendung auswert.cgi aus der gleichnamigen Umgebungsvariablen QUERY_STRING auslesen. In dieser Variablen befindet sich jetzt folgender String:
QUERY_STRING= Textfeld=hallo
POST
Wollen Sie das Gleiche mit der POST-Methode machen, müssen Sie nur Folgendes im HTML-Code umändern:
<form action="http://localhost/cgi-bin/auswert.cgi" method=post>
Jetzt befindet sich in der URL, beim Klicken des Buttons, kein Query-String mehr. In diesem Beispiel müssen Sie die Umgebungsvariable CONTENT_LENGTH nach der Anzahl der Bytes abfragen, die diese Nachricht enthält. Anschließend können Sie CONTENT_LENGTH Bytes von der Standardeingabe (stdin) einlesen – zum Beispiel mit fgets():
fgets(puffer, CONTENT_LENGTH, stdin);
Danach befindet sich die komplette Eingabe (Textfeld=IhrName) vom HTML-Formular im String puffer.
Sowohl bei der Methode GET als auch bei der POST-Methode liegen die Daten kodiert vor und müssen noch dekodiert werden. Wie das geht, erfahren Sie in Kürze.
Weitere Methoden
Es gibt noch einige weitere Methoden, auf die ich hier aber nicht eingehe. Diese Methoden werden in der Praxis kaum eingesetzt. Hier nur ein schneller Überblick zu den weiteren möglichen Anforderungen, die Sie an den Webserver stellen könnten:
- HEAD – holt nur die HTTP-Header und keinen Inhalt vom Webserver.
- PUT – erzeugt eine Ressource auf dem Server.
- DELETE – löscht eine Ressource auf dem Server.
- OPTIONS – dient zur Abfrage der möglichen Request-Methoden des Servers.
Request Header
Außer der Request-Zeile schickt der Browser dem Webserver noch einige Informationen, den sogenannten Request-Header, mit. Diese Informationen bestehen aus dem Feldnamen, der mit einem Doppelpunkt von seinem Wert getrennt wird. Dazu nochmals zur Erinnerung das Beispiel eines HTTP-Request, das Sie weiter oben schon gesehen haben:
GET /index.html HTTP/1.1
Host: www.pronix.de
Accept: image/gif, image/jpeg, image/pjpeg, */*
Accept-Language: de
Connection: Keep-Alive
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
Referer: ...In diesem Beispiel ist das Fettgedruckte der Request-Header.
In Tabelle 23.4 finden Sie einen Überblick zu einigen HTTP-Request-Headern. Diese Informationen schicken Sie praktisch immer mit, wenn Sie mit einem Webbrowser unterwegs sind und eine neue Webseite vom Webserver anfordern.
| Request-Header | Bedeutung |
Host |
Der Host ist der Zielrechner, auf dem sich das angeforderte Dokument befindet. |
Content-Length |
Damit der Server weiß, wie viele Daten er aus dem Nachrichten-Body des HTTP-Requests lesen soll, wird dieser Header verwendet. Natürlich gilt dies nur für den POST-Request (siehe POST). Bei einer Anforderung mit der Methode GET wird dieses Feld nicht mit angegeben. |
Content-Type |
Besitzt ein Request einen Nachrichten-Body, muss der Content-Type-Header mitgeschickt werden. Damit wird der Medientyp des Nachrichten-Bodys angegeben. |
User-Agent |
Darin befinden sich Angaben darüber, mit welchem Webbrowser und Betriebssystem die Anfrage vorgenommen wurde – wobei diese Angaben nicht immer stimmen müssen. Viele Programme und auch Webbrowser bieten eine Option an, diesen Header zu manipulieren. |
Referer |
Darin befindet sich in der Regel die URL, die der Anwender zuletzt besucht hat. Wenn der User aber eine URL direkt in den Webbrowser eingibt oder ein Bookmark verwendet, befindet sich nichts in diesem Header. |
Accept |
Es gibt mehrere Accept-Header. Darin schickt der Browser dem Server Daten, welche Arten von Response (Antworten vom Server) er verstehen kann. Zum Beispiel: Accept: Liste der Medientypen, die der Browser (Client) akzeptiert. Accept-Charset: Liste der Zeichensätze, die der Browser akzeptiert. Accept-Language: Sprachen, die der Browser akzeptiert. |
Cookies |
Damit teilt der Browser dem Server mit, ob er Cookies akzeptiert. Deaktivieren Sie zum Beispiel in Ihrem Browser die Cookies, so wird dieser Header nicht mitgeschickt. Der Server kann, falls Cookies akzeptiert werden, ein Cookie setzen. |
23.8.8 Serverantwort (Server-Response)
Nachdem Sie einen HTTP-Request des Webbrowsers ausführlich durchgearbeitet haben, wird Ihnen der Webserver auch irgendwann mit einer HTTP-Response antworten. Die Antwort besteht aus einer Statuszeile, ebenfalls aus einigen Header-Feldern und häufig auch aus einem Nachrichten-Body. Hier sehen Sie ein Antwort-Beispiel des Webservers:
HTTP/1.1 200 OK Date: Wed, 30 Oct 2002 01:21:22 GMT Server: Apache/1.3.14 Last Modified: Tue, 29 Oct 2002 22:21:19 GMT Content-Length: 2232 Content-Type: text/html <html> ... </html>
Der Statuscode
In der ersten Zeile, der Statuszeile, wird außer dem Protokoll mit der Versionsnummer ein dreistelliger Statuscode angegeben.
HTTP/1.1 200 OK
Anhand dieses Statuscodes bekommt der Webbrowser die Antwort auf seine Anforderung. In diesem Beispiel wird der Statuscode 200 zurückgegeben, was einem erfolgreichen Request vorangeht. Recht häufig dürfte Ihnen der Statuscode 404 im Internet begegnet sein. Dieser wird zurückgegeben, wenn das angeforderte Dokument nicht gefunden wurde.
Hierzu folgt ein Überblick über die möglichen Statuscodes. Tabelle 23.5 listet die fünf Gruppen von Codes auf, die anhand der ersten Ziffer unterschieden werden.
| Statusbereich | Bedeutung |
|
100–199 |
Allgemeine Informationen. Die Anfrage wird trotzdem noch zur Bearbeitung ausgeführt. |
|
200–299 |
Alles in Ordnung. Erfolgreiche Anfrage |
|
300–399 |
Veränderungsstatus, Verlagerungen (bzw. Umleitungen), weitere Maßnahmen müssen getroffen werden, um eine erfolgreiche Anfrage zu gewährleisten. |
|
400–499 |
Fehlermeldung vom Client (meistens Webbrowser) |
|
500–599 |
Fehlermeldung vom Server |
Tabelle 23.6 zeigt die in der Praxis etwas häufiger auftretenden Statuscodes und ihre Bedeutungen:
| Statuscode | Bedeutung |
|
200 |
alles okay |
|
201 |
POST-Befehl erfolgreich |
|
202 |
Anforderung akzeptiert |
|
203 |
GET-Anforderung erfüllt |
|
204 |
Anforderung erfüllt, aber Rücksendung nicht verstanden |
|
300 |
Datenquelle an mehreren Stellen gefunden |
|
301 |
Datenquelle war dauernd in Bewegung. |
|
302 |
Datenquelle war zeitweise in Bewegung. |
|
304 |
Datenquelle konnte nicht näher bestimmt werden. |
|
400 |
unverständliche Anforderung vom Client |
|
401 |
ein File wurde angefragt, für das sich der User ausweisen muss |
|
403 |
Anfrage war verständlich, der Server weigert sich jedoch, das Dokument zu senden, da dieser oder der Client keine Berechtigung hat. Beispiel: keine Leserechte der Datei. |
|
404 |
Datenquelle nicht gefunden |
|
405 |
Verfahren an Datenquelle nicht erlaubt. Zum Beispiel ist die Abfrage-Methode POST explizit gesperrt. |
|
406 |
Art der Datenquelle nicht erwünscht |
|
408 |
Anfrage Timeout -> Server überlastet? Fehlkonfiguriert? |
|
500 |
Fehler im CGI-Skript, falsche Zugriffsrechte, Server falsch konfiguriert |
|
501 |
Anfrage wird vom Server nicht unterstützt, da notwendige Module nicht implementiert sind. |
|
502 |
schlechte Netzverbindung oder Server überladen |
|
503 |
Dienst steht nicht zur Verfügung – Timeout, wenn z. B. ein Datenbankserver nicht reagiert. |
Server-Header
Es folgt eine kurze Beschreibung der gängigsten HTTP-Server-Header, die der Webserver dem Webbrowser sendet.
| Server-Header | Bedeutung |
Date |
Datum und Uhrzeit, wann die Antwort geschickt wurde |
Server |
Name und Versionsnummer des Webservers |
Content-Length |
Länge des Nachrichten-Body in Bytes |
Content-Type |
Art des Dokuments im Nachrichten-Body. text/html steht beispielsweise für eine HTML-Datei. Geben Sie dafür hingegen text/plain an, dann handelt es sich um eine reine Textdatei. Dieser Header wird bei fast allen CGI-Anwendungen benötigt, die einen Nachrichten-Body besitzen. |
Last Modified |
Datum der letzten Änderung des angeforderten Dokuments |
Set-Cookie |
Damit können Sie ein Cookie setzen. |
Location |
Speicherort des Dokuments |
23.8.9 Zusammenfassung
Jetzt haben Sie mit dem HTTP-Protokoll das schwierigste und wahrscheinlich auch langweiligste Kapitel hinter sich. Im Laufe der nächsten Seiten wird Ihnen einiges, was Ihnen vielleicht noch nicht so klar ist, in einem anderen Licht erscheinen. Speziell in den nächsten Abschnitten werden Sie sehen, wie Sie mit CGI-Anwendungen und dem HTTP-Webserver zusammenarbeiten können, um dynamische Webseiten zu erstellen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



