


22.3 Sortieralgorithmen 

Viele Programme und Computer (Server) erledigen oft den lieben langen Tag nichts anderes, als Daten zu sortieren. Wenn Sie das Sortieren verstanden haben, wird es Ihnen nicht mehr schwerfallen, andere Algorithmen zu verstehen. Das Sortieren könnte man sozusagen auch als »Basics für Algorithmen« bezeichnen. Hier einige Typen von Sortieralgorithmen:
- Internes Sortieren – internes Sortieren findet innerhalb des RAMs (Arbeitsspeicher) statt. Dabei werden meist Daten an das Programm geschickt und werden sortiert wieder ausgegeben.
- Externes Sortieren – beim externen Sortieren werden externe Speicherquellen (Festplatte, Streamer, Tape, ...) verwendet. Während des externen Sortierens werden zahlreiche Lese- und Schreibzugriffe auf externe Quellen ausgeführt. Externes Sortieren wird genutzt, wenn die Daten zum Sortieren nicht auf einmal im RAM verarbeitet werden können.
- Vergleichendes Sortieren – dabei wird häufig ein Schlüssel zum Sortieren verwendet. Dieser Schlüssel besteht meist nur aus einem kleinen Teil der Daten, der das Sortieren steuert.
- Stabiles Sortieren – stabil wird sortiert, wenn z. B. eine Arbeitnehmerliste, die nach Alphabet sortiert ist, nach Gehalt sortiert wird, ohne dass dabei die alphabetische Liste durcheinandergerät.
Im Folgenden werden häufig Arrays zum Sortieren verwendet. Diese sollten Sie sich als Schlüssel einer Datenstruktur vorstellen. Die Funktionen sind so aufgebaut, dass sie jederzeit mit ein wenig Tipparbeit an die eigenen Bedürfnisse angepasst werden können. Primär geht es darum, Ihnen die einzelnen Sortierverfahren näherzubringen, speziell deren Funktionen. Die Implementierung ist zumeist problemabhängig und richtet sich nach der Art der Daten, die es zu sortieren gilt.
22.3.1 »Selection Sort« – sortieren durch Auswählen
Der erste Sortieralgorithmus ist Selection Sort. Dieser Algorithmus sucht sich als Erstes das kleinste Element in der Liste, merkt es sich und tauscht es gegen das Element am Anfang aus, sodass sich dann das kleinste Element ganz am Anfang befindet. Als Nächstes wird das zweitkleinste Element in der Liste gesucht und wird gegen das an zweiter Stelle platzierte Element der Liste ausgetauscht usw.
Auf diese Weise haben immer die Elemente auf der linken Seite der aktuellen Position einen festen Platz und werden nicht mehr geändert. Abbildung 22.1 verdeutlicht den Vorgang:
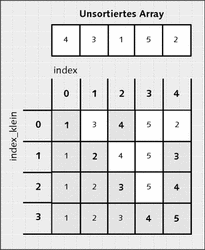
Abbildung 22.1 Sortieren durch Auswählen
Der Quellcode dazu sieht so aus:
/* selektion.c */
#include <stdio.h>
#include <stdlib.h>
void selection(int *array, int elemente) {
int index,index_klein,
wert, wert_klein;
/* Schleife wird von links nach rechts durchlaufen. */
for(index = 0; index < elemente; index++) {
/* aktuelle Position */
wert=index;
/* Schleife läuft durch bis ein kleineres Element als
* die aktuelle Position gefunden wurde oder bis zum Ende,
* was bedeutet, die aktuelle Position ist schon
* das kleinste Element. */
for(index_klein = index+1; index_klein <= elemente;
index_klein++) { /* Ein kleineres Element gefunden? */
if(array[index_klein] < array[wert])
/* Neues kleinstes Element */
wert=index_klein;
}
/* kleinstes Element an die aktuelle
* Position falls nötig */
if(wert != index) {
wert_klein=array[wert];
array[wert]=array[index];
array[index]=wert_klein;
}
}
}
int main(void) {
int i;
/* das Array zum Sortieren */
int test_array[] = { 5, 2, 7, 9, 1, 4, 3, 8, 6 };
int N = sizeof(test_array)/sizeof(int);
selection(test_array, N-1);
for(i = 0; i < N; i++)
printf("%d ", test_array[i]);
printf("\n");
return EXIT_SUCCESS;
}Natürlich können Sie mit Selection Sort auch andersherum sortieren, also vom größten Element abwärts. In diesem Fall muss nur die if-Abfrage geändert werden:
if(array[index_klein] > array[wert])
Der Vorteil von Selection Sort liegt darin, dass jedes Element höchstens einmal bewegt wird.
22.3.2 Insertion Sort
Das Prinzip von Insertion Sort (Sortieren durch direktes Einfügen) ist relativ einfach. Die einzelnen Elemente werden wieder von vorne nach hinten durchlaufen. Von der aktuellen Position aus wird jedes Element von rechts nach links weitergereicht – und das so lange, bis das bewegte Element größer oder gleich dem Element ist, das an der im Augenblick abgefragten Position liegt.
Der Platz für das Element, das verschoben wird, ist frei. Diese Lücke wird mit dem entsprechenden Wert an der richtigen Stelle gefüllt. Bildlich können Sie sich Insertion Sort folgendermaßen vorstellen:
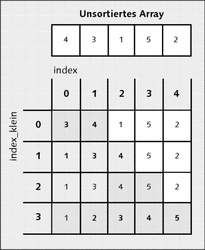
Abbildung 22.2 Insertion Sort
Der folgende Quellcode soll diesen Algorithmus noch verständlicher machen:
/* insertion.c */
#include <stdio.h>
#include <stdlib.h>
void insertion(int *array, int elemente) {
int index,index_klein,wert_klein;
/* Schleife von links-1 nach rechts */
for(index=1; index<=elemente; index++) {
/* aktuelle Position zwischenspeichern */
wert_klein=array[index];
/* Kleineren Wert als wert_klein suchen. Schleife läuft
* von aktueller Position von rechts nach links durch. */
for( index_klein=index;
array[index_klein-1] > wert_klein&&index_klein > 0;
index_klein-- )
/* wenn Vorgänger größer als aktuelles
* Element in wert_klein */
array[index_klein] = array[index_klein-1];
/* gespeichertes Element an neue Position ->
* Lücke auffüllen */
array[index_klein]=wert_klein;
}
}
int main(void) {
int i;
/* das Array zum Sortieren */
int test_array[] = { 5, 2, 7, 9, 1, 4, 3, 8, 6 };
int N = sizeof(test_array)/sizeof(int);
insertion(test_array, N-1);
for(i = 0; i < N; i++)
printf("%d ", test_array[i]);
printf("\n");
return EXIT_SUCCESS;
}
Abbildung 22.3 Geklammerte Werte symbolisieren den Elementetausch.
Das aktuelle Element wird hier in wert_klein gespeichert. Jetzt wird so lange umdisponiert, bis entweder ein Element kleiner als wert_klein ist oder bis Sie am Anfang des Arrays (Index 0) angekommen sind (was bedeuten würde, dass wert_klein das kleinste Element im Array ist).
Wie auch schon bei Selection Sort sind die Elemente bei Insertion Sort auf der linken Seite sortiert; nur mit dem Unterschied, dass dies noch keine endgültige Stellung wie bei Selection Sort bedeutet.
22.3.3 Bubble Sort
Bubble Sort ist ein recht einfaches Sortierverfahren. Dabei wird das vollständige Array durchlaufen, und jedes Mal – wenn notwendig – werden die benachbarten Elemente miteinander vertauscht.
Nach jedem Durchlauf bekommt immer das letzte Element einen festen Platz. Daher macht es auch Sinn, eine rückwärts zählende Schleife von dieser Position an einzusetzen. Hier sehen Sie den Quellcode zu Bubble Sort:
/* bubble.c */
#include <stdio.h>
#include <stdlib.h>
void bubble(int *array, int elemente) {
int i,temp;
while(elemente--)
for(i = 1; i <= elemente; i++)
if(array[i-1] > array[i]) {
temp=array[i];
array[i]=array[i-1];
array[i-1]=temp;
}
}
int main(void) {
int i;
/* das Array zum Sortieren */
int test_array[] = { 5, 2, 7, 9, 1, 4, 3, 8, 6 };
int N = sizeof(test_array)/sizeof(int);
bubble(test_array, N);
for(i = 0; i < N; i++)
printf("%d ", test_array[i]);
printf("\n");
return EXIT_SUCCESS;
}Da nach jedem Durchlauf das größte Element ganz nach rechts geholt wird und dies nicht mehrmals verglichen werden sollte, wurde von dieser Position aus eine rückwärts zählende Schleife eingesetzt:
while(elemente--)
Abbildung 22.4 zeigt die Arbeitsweise von Bubble Sort:
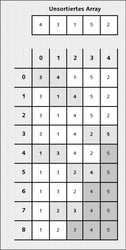
Abbildung 22.4 »Bubble Sort« in Aktion
Auf die letzten Durchläufe wurde in der Darstellung verzichtet, da keine Daten mehr verschoben werden.
22.3.4 Shellsort
Shellsort ist eine Erweiterung von Insertion Sort. Anstatt jedes benachbarte Element wie bei Insertion Sort zu vergleichen und zu sortieren, vergleicht Shellsort jedes n-te Element (bei beliebigem Anfangselement). Damit ist es möglich, Elemente zu sortieren, die in größeren Entfernungen voneinander liegen. Ist der Abstand für n beispielsweise 4, dann setzen sich folgende Gruppen von Elementen mit dem Index 0, 4, 8, 12 und 1, 5, 9, 13 2, 6, 10, 14 3, 7, 11, 15 usw. zusammen. Diese Gruppen werden einzeln sortiert. Danach wird n verringert, und dann werden die Gruppen n-1 sortiert. Dies geschieht so lange, bis n==1 ist und somit im letzten Durchlauf keine Unterteilung mehr stattfindet. Ist n gleich von Anfang an 1, könnten Sie sich den Aufwand sparen, da dies dem »Insertion Sort«-Algorithmus entspräche.
Natürlich hängt n von den Werten ab, die sortiert werden. Man spricht dabei von Distanzfolgen. Je besser diese Folge ist, desto schneller werden die Daten sortiert. Die Suche nach der optimalen Folge ist Aufgabe des Programmierers. Hier sehen Sie den Quellcode zu Shellsort:
/* shellsort.c */
#include <stdio.h>
#include <stdlib.h>
void shellsort (int *array, int elemente) {
int i, j, temp, n;
/* Anfangswert für die Distanz errechnen */
for ( n = 1; n <= elemente/9; n = 3*n+1);
for (; n > 0; n /= 3) {
for (i = n; i <= elemente; i++) {
temp = array[i];
/* Größer als temp und nicht elemente
* sowie >= und nicht > */
for(j = i;
j >= n && array[j-n] > temp;
j -= n) {
array[j] = array[j-n];
}
array[j] = temp;
}
}
}
int main(void) {
int i;
/* das Array zum Sortieren */
int test_array[] = { 5, 0, 2, 7, 9, 1, 4, 3, 8, 6 };
int N = sizeof(test_array)/sizeof(int);
shellsort(test_array, N-1);
for(i = 0; i < N; i++)
printf("%d ", test_array[i]);
printf("\n");
return EXIT_SUCCESS;
}Jetzt soll gezeigt werden, wie Sie die optimale Distanzfolge von Daten für Shellsort ermitteln. Es wird ein Array mit 10 Millionen Elementen erstellt, das Zahlen in absteigender Reihenfolge enthält. In diesem Fall müssten alle Elemente bei der Sortierung ausgetauscht werden. Getestet wird mithilfe einer Schleife und den Distanzfolgen von 2 bis 10.
Für das Profiling wird hierbei die Funktion clock() verwendet, die für diesen Zweck vollkommen ausreichen dürfte (mehr zum Profiling entnehmen Sie bitte dem entsprechenden Abschnitt 19.2, »Laufzeitmessung (Profiling)«).
Hier sehen Sie das Beispiel mit den verschiedenen Distanzfolgen:
/* profile_shellsort.c */
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10000000
#define MAX_TEST 10
/* das Array zum Sortieren */
int test_array[MAX];
void init_test_array(void) {
int i,j;
for(i = MAX, j = 0; i >= 0; i--,j++)
test_array[j] = i;
}
void shellsort(int *array, int elemente, int distanz) {
int i, j, temp, n = elemente;
for(; n > 0; n /= distanz)
for (i = n; i <= elemente; i++) {
temp = array[i];
/* Größer als temp und nicht elemente
* sowie >= und nicht > */
for(j = i;
j >= n && array[j-n] > temp;
j -= n) {
array[j] = array[j-n];
}
array[j] = temp;
}
}
int main(void) {
int distanz_folge;
float zeit;
clock_t start, ende;
for(distanz_folge =2;
distanz_folge <= MAX_TEST; distanz_folge++) {
init_test_array();
start = clock();
shellsort(test_array, MAX-1, distanz_folge);
ende = clock();
/* Ergebnis der Laufzeitmessung in Sekunden */
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Die Laufzeitmessung der Distanzfolge "
" %d ergab %2.2f Sekunden\n" ,distanz_folge,zeit);
}
return EXIT_SUCCESS;
}Je nach Power des Rechners erhalten Sie folgende Ausgabe (als Beispiel ein 1700–MHz-Pentium 4 mit 256 MB RAM):
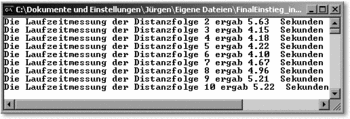
Abbildung 22.5 Ermitteln der optimalen Distanzfolge von Shellsort
In diesem Fall scheint eine Distanzfolge zwischen 3 und 6 das optimale Ergebnis zu liefern.
Diese Tests der Laufzeitmessungen mit Shellsort werden Sie wohl immer durchführen müssen, da bisher noch niemand in der Lage war, Shellsort genau zu analysieren. Aber verglichen mit Insertion Sort läuft Shellsort immer schneller ab. Zum Vergleich kann hierbei Insertion Sort (Distanzfolge = 1) mit eingebaut werden. Dabei sollte aber die Anzahl der Elemente reduziert werden, weil Insertion Sort eine Weile mit ihnen beschäftigt sein wird.
22.3.5 Quicksort
Ein oft eingesetzter Algorithmus ist Quicksort, da seine Implementierung nicht allzu schwer ist. Aufgrund ihrer häufigen Verwendung wurde diese Funktion in die ANSI-C-Bibliothek mit aufgenommen (qsort). Quicksort funktioniert nach dem Prinzip »Teile und herrsche«, also rekursiv. Die Daten werden immer in zwei Teile zerlegt und wieder sortiert. Diese zwei Teile werden wiederum jeweils in zwei Teile zerlegt und sortiert usw., bis die Daten sortiert sind. Die Rekursion beendet sich, wenn das Teilstück aus nur noch einem Element besteht. Hier sehen Sie den Quellcode von Quicksort:
/* quicksort.c */
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 50000
/* das Array zum Sortieren */
int test_array[MAX];
void my_qsort(int*, int*);
void init_test_array(void) {
int i, j;
for(i = MAX,j=0; i >= 0; i--,j++)
test_array[j] = i;
}
void print_test_array(void) {
int i;
for(i=0;i<MAX; i++)
printf("%d ",test_array[i]);
}
/* Die Funktion erhält einen Zeiger auf das erste
* und einen zweiten Zeiger auf das letzte Element.
* Hier werden dazu die Namen »links« und »rechts« verwendet.
*/
void my_qsort(int *links, int *rechts) {
int *ptr1 = links;
int *ptr2 = rechts;
int w, x;
/* x bekommt die Anfangsadresse der
* Mitte von links und rechts.
* Anstatt der Bitverschiebung hätten Sie
* auch einfach »geteilt durch 2« rechnen können.
*/
x = *(links + (rechts - links >> 1));
do {
while(*ptr1 < x) ptr1++;
while(*ptr2 > x) ptr2--;
if(ptr1 > ptr2)
break;
w = *ptr1;
*ptr1 = *ptr2;
*ptr2 = w;
} while(++ptr1 <= --ptr2);
if(links < ptr2) my_qsort(links, ptr2);
if(ptr1 < rechts) my_qsort(ptr1, rechts);
}
int main(void) {
init_test_array();
my_qsort(test_array, test_array+MAX);
print_test_array();
return EXIT_SUCCESS;
}Im Gegensatz zu den anderen bisher verwendeten Algorithmen sieht dieser schon ein wenig kryptischer aus. Daher soll er auch etwas genauer analysiert werden. Wir gehen von folgenden unsortierten Werten aus:
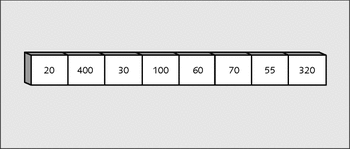
Abbildung 22.6 Werte sollen mit »Quicksort« sortiert werden.
Aufgerufen wird die Funktion mit:
my_qsort(test_array, test_array+MAX);
Somit zeigt in der Funktion my_qsort() der Zeiger links auf die Anfangsadresse von test_array, nämlich den Wert 20. Der rechte Zeiger verweist auf das Ende des Arrays, also den Wert 320. In der Funktion übernehmen zwei Zeiger diese Adressen:
int *ptr1 = links; int *ptr2 = rechts;
Durch die darauf folgende Berechnung
x = *(links + (rechts - links >> 1));
bekommt die Variable x zunächst den Wert 100 zugewiesen. Denn im Klartext ergibt diese Rechnung auf Zahlen bezogen:
x = *(0 + (7 - 0 / 2));
Das Ergebnis dieser Berechnung beträgt 3, und die Zahl mit dem Index [3] lautet 100. Weiter geht es mit folgender Zeile:
while(*ptr1 < x) ptr1++;
Der Zeiger ptr1 wird jetzt so lange inkrementiert, bis er auf ein Element zeigt, das größer als oder gleich dem Element von x ist. Im aktuellen Beispiel ist dies der Wert 400.
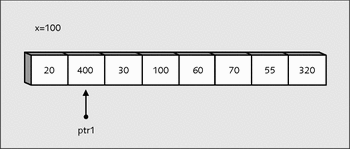
Abbildung 22.7 »ptr1« ist auf einen Wert gestoßen, der größer als »x« ist.
Genauso verläuft dies mit dem Zeiger ptr2:
while(*ptr2 > x) ptr2--;
Dieser wird so lange dekrementiert, bis er auf ein Element zeigt, das kleiner als oder gleich dem von x ist.
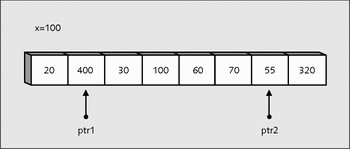
Abbildung 22.8 »ptr2« ist auf einen Wert gestoßen, der kleiner als »x« ist.
Als Nächstes wird überprüft, ob ptr1 schon weiter ist als ptr2. Trifft dies zu, wird die do while-Schleife abgebrochen. Hier stimmt dies aber nicht, und somit werden die beiden Elemente, auf die ptr1 und ptr2 zeigen, vertauscht:
w = *ptr1; *ptr1 = *ptr2; *ptr2 = w;
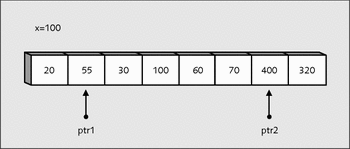
Abbildung 22.9 Werte von »ptr1« und »ptr2« tauschen
Jetzt bewegen sich die beiden Zeiger mit
++ptr1 <= --ptr2
aufeinander zu.
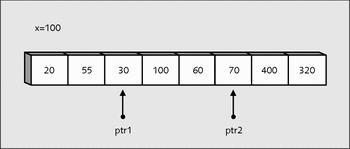
Abbildung 22.10 Die Zeiger nähern sich einander.
Danach folgen wieder:
while(*ptr1 < x) ptr1++; while(*ptr2 > x) ptr2--;
Die Bedingung für den Zeiger ptr1 trifft bereits nach der ersten Inkrementierung zu (100<60), und der zweite Zeiger wird gar nicht dekrementiert (70>100). So ergibt sich folgender Zustand:
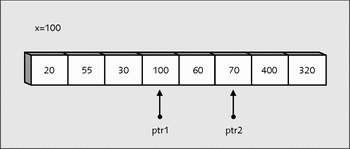
Abbildung 22.11 Wieder wurden zwei Werte ausgemacht, wo »ptr1« nicht kleiner und »ptr2« nicht größer als »x« sind.
Jetzt werden wieder beide Elemente ausgetauscht:
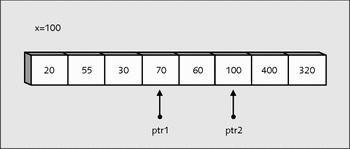
Abbildung 22.12 »ptr1«und »ptr2« nach dem Wertetausch
Danach werden beide Zeiger wieder aufeinander zu bewegt, sodass sich jetzt folgendes Bild ergibt (siehe Abbildung 22.13).
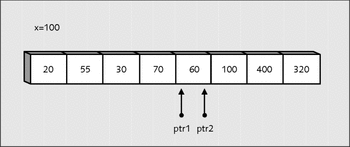
Abbildung 22.13 »ptr1« und »ptr2« treffen aufeinander.
Nach den beiden Zeilen
while(*ptr1 < x) ptr1++; while(*ptr2 > x) ptr2--;
ist jetzt die if-Bedingung (ptr1 > ptr2) wahr und bricht mit break die do while-Schleife ab. Folgender Zustand liegt dabei vor (siehe Abbildung 22.14).
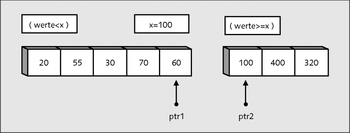
Abbildung 22.14 Ein Teilungsprozess findet statt.
Damit wurde der erste Teilungsprozess beendet. Daran lässt sich auch schon feststellen, dass alles, was sich links von der Teilungslinie befindet, größer, und alles, was rechts davon liegt, kleiner ist. Der Algorithmus funktioniert auch, wenn der Wert der Variablen x beispielsweise einem Wert entspricht, der weiter außen liegt. Die optimale Bedingung ist eine Teilung in der Mitte.
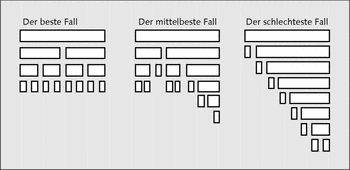
Abbildung 22.15 Quicksort ist von der Anordnung der Daten abhängig.
Nach der ersten Teilung sind nun weitere Schritte notwendig. Oder einfacher ausgedrückt: Im Prinzip sind nur noch zwei Schritte zu beachten: Es muss derselbe Vorgang für die linke und rechte Seite vorgenommen werden. In diesem Beispiel sind das die Zeilen:
if(links < ptr2) my_qsort(links, ptr2); if(ptr1 < rechts) my_qsort(ptr1, rechts);
Damit wird der weitere Vorgang rekursiv für beide Seiten ausgeführt – und zwar so lange, bis die Adresse links kleiner als ptr2 und die Adresse rechts größer als ptr1 ist. Einfach ausgedrückt ist dies der Fall, wenn kein Teilungsprozess mehr möglich ist.
22.3.6 qsort()
Sollten Sie in der Praxis vorhaben, den qsort()-Algorithmus einzusetzen, können Sie auch den Quicksort-Algorithmus qsort() verwenden, der in der Standard-Headerdatei <stdlib.h> implementiert ist. Dieser läuft zumeist stabiler und sicherer ab als die Eigenkreation, da Fehler bei der Implementierung seltener sind. Die Syntax von qsort() lautet:
void qsort(void *base, size_t num, size_t size,
int (*cmp)(void *elem1, void *elem2));base ist die Adresse des ersten Elements in der Liste oder in einem Array, das es zu sortieren gilt. Die Anzahl der Elemente geben Sie mit num und die Größe der einzelnen Elemente mit size an. cmp ist eine Adresse auf eine Vergleichsfunktion, die Sie selbst implementieren müssen. Schließlich kann qsort() nicht von vornherein wissen, welche Art von Daten (Strukturen, Arrays, Strings ) Sie sortieren wollen. So bleibt qsort() immer für den Allgemeingebrauch verfügbar. Hierzu zeige ich die Funktion qsort() der Standard-Bibliothek im Zeitvergleich mit unserer Eigenkreation:
/* profile_quicksort.c */
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 5000000
/* das Array zum Sortieren */
int test_array[MAX];
void my_qsort(int*, int*);
void init_test_array(void) {
int i, j;
for(i = MAX,j=0; i >= 0; i--,j++)
test_array[j] = i;
}
/* Vergleichsfunktion für qsort() */
int cmp_integer(const void *wert1, const void *wert2) {
return (*(int*)wert1 - *(int*)wert2);
}
/* Die Funktion erhält einen Zeiger auf das erste
* und einen zweiten Zeiger auf das letzte Element.
* Hier werden die Namen »links« und »rechts« verwendet.
*/
void my_qsort(int *links, int *rechts) {
int *ptr1 = links;
int *ptr2 = rechts;
int w, x;
/* x bekommt die Anfangsadresse der
* Mitte von »links« und »rechts«
* Statt der Bitverschiebung hätten Sie
* auch einfach »geteilt durch 2« rechnen können.
*/
x = *(links + (rechts - links >> 1));
do {
while(*ptr1 < x) ptr1++;
while(*ptr2 > x) ptr2--;
if(ptr1 > ptr2)
break;
w = *ptr1;
*ptr1 = *ptr2;
*ptr2 = w;
}while(++ptr1 <= --ptr2);
if(links < ptr2) my_qsort(links, ptr2);
if(ptr1 < rechts) my_qsort(ptr1, rechts);
}
int main(void) {
clock_t start,ende;
init_test_array();
start = clock();
qsort(test_array, MAX, sizeof(int), cmp_integer);
ende = clock();
printf("qsort() der Standard-Library: %.2f\n",
(float)(ende-start) / (float)CLOCKS_PER_SEC);
init_test_array();
start = clock();
my_qsort(test_array, test_array+MAX);
ende = clock();
printf("Selbst geschriebene Quicksort-Funktion %.2f\n",
(float)(ende-start) / (float)CLOCKS_PER_SEC);
return EXIT_SUCCESS;
}22.3.7 Zusammenfassung der Sortieralgorithmen
Jetzt werden die Sortieralgorithmen ein wenig analysiert. Es soll ein Beispiel erstellt werden, mit dem drei verschiedene Zustände von Daten sortiert werden.
- Zuerst sollen Daten sortiert werden, bei denen das größte Element ganz am Anfang ist und absteigend das kleinste Element ganz am Ende.
- Anschließend sollen Daten sortiert werden, die bereits in sortierter Form vorliegen. Denn es kann ja immer mal vorkommen, dass Herr Meier die Daten sortiert hat und Herr Müller wieder mal nichts davon weiß und diese nochmals sortiert.
- Im letzten Beispiel werden Daten sortiert, die mit Zufallsdaten belegt werden.
Die Anzahl der Elemente ist in einem solchen Fall natürlich auch entscheidend. Es werden dafür 1000, 10.000 und am Schluss 100.000 Elemente verwendet, die nach den vorhandenen Zuständen sortiert werden sollen.
Das Programm wurde der Übersicht halber etwas zusammengepresst. Es ist nur die Ausgabe des Programms von Interesse. Leiten Sie die Standardausgabe am besten in eine Textdatei um, indem Sie im Programm noch vor der for-Schleife in der main()- Funktion Folgendes eingeben:
freopen("benchmark.txt", "a+", stdout);Dies kann jetzt – abhängig vom Rechner – etwas dauern. Hier sehen Sie das kleine Benchmark dazu mit einigen Sortieralgorithmen:
/* sortbenchmark.c */
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define MAX 100000
/* ein Array von großen zu kleinen Werten sortieren */
int test_array[MAX];
void init_test_array(int elements) {
int i, j;
for(i = elements,j=0; i >= 0; i--,j++)
test_array[j] = i;
}
/* ein bereits sortiertes Array */
void init_test_array2(int elements) {
int i;
for(i = 0; i <= elements; i++)
test_array[i] = i;
}
/* ein Array mit (Pseudo)-Zufallszahlen */
void init_test_array3(int elements) {
int i;
for(i = 0; i <= elements; i++)
test_array[i] = rand();
}
/* Vergleichsfunktion für qsort() */
int cmp_integer(const void *wert1, const void *wert2) {
return (*(int*)wert1 - *(int*)wert2);
}
/* Die Funktion erhält einen Zeiger auf das erste
* und einen zweiten Zeiger auf das letzte Element.
* Hier werden die Namen »links« und »rechts« verwendet.
*/
void my_qsort(int *links, int *rechts) {
int *ptr1 = links;
int *ptr2 = rechts;
int w, x;
/* x bekommt die Anfangsadresse der
* Mitte von »links« und »rechts«.
* Statt der Bitverschiebung hätten Sie
* auch einfach »geteilt durch 2« rechnen können.
*/
x = *(links + (rechts - links >> 1));
do {
while(*ptr1 < x) ptr1++;
while(*ptr2 > x) ptr2--;
if(ptr1 > ptr2)
break;
w = *ptr1;
*ptr1 = *ptr2;
*ptr2 = w;
} while(++ptr1 <= --ptr2);
if(links < ptr2) my_qsort(links, ptr2);
if(ptr1 < rechts) my_qsort(ptr1, rechts);
}
void shellsort (int *array, int elemente) {
int i, j, temp, n;
/* Anfangswert für die Distanz errechnen */
for ( n = 1; n <= elemente/9; n = 3*n+1);
for (; n > 0; n /= 3) {
for (i = n; i <= elemente; i++) {
temp = array[i];
/* Größer als temp und nicht elemente
* sowie >= und nicht > */
for(j = i;
j >= n && array[j-n] > temp;
j -= n) {
array[j] = array[j-n];
}
array[j] = temp;
}
}
}
void selection(int *array, int elemente) {
int i, j, mini, temp;
for(i = 0; i < elemente; i++) {
mini=i;
for(j=i+1; j <= elemente; j++) {
if(array[j] < array[mini])
mini=j;
}
temp=array[mini];
array[mini]=array[i];
array[i]=temp;
}
}
void insertion(int *array, int elemente) {
int i, j, temp;
for(i = 1; i <= elemente; i++) {
temp=array[i]; /* aktuelles Element zwischenspeichern */
for(j=i; array[j-1] > temp && j > 0; j--)
/* solange der Vorgänger größer ist als das
* aktuelle Element in temp ... */
array[j] = array[j-1];
/* gespeichertes Element an neue Position */
array[j]=temp;
}
}
void bubble(int *array, int elemente) {
int i, temp;
while(elemente--)
for(i = 1; i <= elemente; i++)
if(array[i-1] > array[i]) {
temp=array[i];
array[i]=array[i-1];
array[i-1]=temp;
}
}
int main(void) {
int i;
int elemente=1000;
float zeit;
clock_t start, ende;
/* freopen("log.txt","a+",stdout); */
for(i=1; i<=3; i++, elemente*=10){
printf("\n\nSortieren von %d Elementen\n\n",elemente);
printf("\n%d. Versuch : alle %d Elemente muessen "
"sortiert werden\n\n",i,elemente);
/* Selectionsort */
init_test_array(elemente); start = clock();
selection(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Selectionsort: %.2f Sekunden\n",zeit);
/* Insertionsort */
init_test_array(elemente); start = clock();
insertion(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Insertionsort: %.2f Sekunden\n",zeit);
/* Bubblesort */
init_test_array(elemente); start = clock();
bubble(test_array, elemente); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Bubblesort : %.2f Sekunden\n",zeit);
/* Shellsort */
init_test_array(elemente); start = clock();
shellsort(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Shellsort : %.2f Sekunden\n",zeit);
/* Quicksort */
if(elemente < 50000){
init_test_array(elemente); start = clock();
my_qsort(test_array, test_array+elemente);
ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Quicksort : %.2f Sekunden\n",zeit);
}
/* qsort aus der Standard-Bibliothek <stdlib.h> */
init_test_array(elemente); start = clock();
qsort(test_array, elemente, sizeof(int), cmp_integer);
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("qsort : %.2f Sekunden\n",zeit);
/* 2. Versuch, eine bereits sortierte Liste */
printf("\n%d. Versuch : keins der %d Elemente muss "
"sortiert werden\n\n",i,elemente);
/* Selectionsort */
init_test_array2(elemente); start = clock();
selection(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Selectionsort: %.2f Sekunden\n",zeit);
/* Insertionsort */
init_test_array2(elemente); start = clock();
insertion(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Insertionsort: %.2f Sekunden\n",zeit);
/* Bubblesort */
init_test_array2(elemente); start = clock();
bubble(test_array, elemente); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Bubblesort : %.2f Sekunden\n",zeit);
/* Shellsort */
init_test_array2(elemente); start = clock();
shellsort(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Shellsort : %.2f Sekunden\n",zeit);
/* Quicksort */
init_test_array2(elemente); start = clock();
my_qsort(test_array, test_array+elemente); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Quicksort : %.2f Sekunden\n",zeit);
/* qsort aus der Standard-Bibliothek <stdlib.h> */
init_test_array2(elemente); start = clock();
qsort(test_array, elemente, sizeof(int), cmp_integer);
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("qsort : %.2f Sekunden\n",zeit);
/* 3. Versuch Zufallsdaten */
printf("\n%d. Versuch : %d Zufallszahlen muessen"
"sortiert werden\n\n",i,elemente);
/* Selectionsort */
init_test_array3(elemente); start = clock();
selection(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Selectionsort: %.2f Sekunden\n",zeit);
/* Insertionsort */
init_test_array3(elemente); start = clock();
insertion(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Insertionsort: %.2f Sekunden\n",zeit);
/* Bubblesort */
init_test_array3(elemente); start = clock();
bubble(test_array, elemente); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Bubblesort : %.2f Sekunden\n",zeit);
/* Shellsort */
init_test_array3(elemente); start = clock();
shellsort(test_array, elemente-1); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Shellsort : %.2f Sekunden\n",zeit);
/* Quicksort */
init_test_array3(elemente); start = clock();
my_qsort(test_array,test_array+elemente); ende = clock();
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("Quicksort : %.2f Sekunden\n",zeit);
/* qsort aus der Standard-Bibliothek <stdlib.h> */
init_test_array3(elemente); start = clock();
qsort(test_array, elemente, sizeof(int), cmp_integer);
zeit = (float)(ende-start) / (float)CLOCKS_PER_SEC;
printf("qsort : %.2f Sekunden\n",zeit);
}/* Ende for */
return EXIT_SUCCESS;
}In Tabelle 22.1 finden Sie eine Analyse der einzelnen Sortierfunktionen. Bei einigen Algorithmen wurde die Anzahl der Elemente nochmals erhöht, da diese bei den Anforderungen eine kaum nennenswerte Zeit benötigen.
| Anzahl | Zustand | Selektion | Insertion | Bubble | Shell | my_qsort | qsort() |
|
1000 |
alle sortieren |
0.03 |
0.04 |
0.02 |
0.06 |
0.11 |
0.12 |
|
1000 |
sortiert |
0.04 |
0.04 |
0.03 |
0.05 |
0.10 |
0.11 |
|
1000 |
Zufall |
0.03 |
0.04 |
0.04 |
0.06 |
0.11 |
0.11 |
|
10000 |
alle sortieren |
0.34 |
0.53 |
1.04 |
0.15 |
0.13 |
0.14 |
|
10000 |
sortiert |
0.36 |
0.07 |
0.45 |
0.04 |
0.15 |
0.13 |
|
10000 |
Zufall |
0.36 |
0.27 |
1.09 |
0.11 |
0.15 |
0.14 |
|
25000 |
alle sortieren |
2.32 |
3.79 |
7.74 |
0.13 |
0.16 |
0.15 |
|
25000 |
sortiert |
3.03 |
0.09 |
2.77 |
0.16 |
0.13 |
0.14 |
|
25000 |
Zufall |
2.84 |
1.71 |
7.10 |
0.15 |
0.16 |
0.15 |
|
50000 |
alle sortieren |
9.79 |
14.84 |
27.79 |
0.17 |
0.17 |
0.16 |
|
50000 |
sortiert |
10.15 |
0.10 |
10.01 |
0.18 |
0.18 |
0.17 |
|
50000 |
Zufall |
9.82 |
6.60 |
28.74 |
0.17 |
0.19 |
0.17 |
|
100000 |
alle sortieren |
33.55 |
52.39 |
97.87 |
0.19 |
0.19 |
0.18 |
|
100000 |
sortiert |
32.51 |
0.04 |
32.81 |
0.18 |
0.19 |
0.18 |
|
100000 |
Zufall |
32.60 |
27.40 |
119.58 |
0.19 |
0.18 |
0.19 |
|
1000000 |
alle sortieren |
– |
– |
– |
0.40 |
0.25 |
0.20 |
|
1000000 |
sortiert |
– |
– |
– |
0.31 |
0.19 |
0.19 |
|
1000000 |
Zufall |
– |
– |
– |
1.17 |
0.45 |
0.18 |
|
5000000 |
alle sortieren |
– |
– |
– |
2.10 |
0.60 |
0.32 |
|
5000000 |
sortiert |
– |
– |
– |
1.26 |
0.55 |
0.30 |
|
5000000 |
Zufall |
– |
– |
– |
9.75 |
2.10 |
0.40 |
Mithilfe dieser Analyse können Sie sich nun ein etwas detaillierteres Bild von der Effizienz der einzelnen Algorithmen machen. Natürlich sollten Sie diese Laufzeitmessung nicht allzu genau nehmen. Für eine exaktere und genauere Messung sollten Sie auf jeden Fall einen Profiler einsetzen. Denn das Programm zur Laufzeitmessung ist während der Ausführung sicherlich nicht das einzige Programm, das gerade auf Ihrem System läuft.
Die Frage nach dem besten Algorithmus lässt sich allerdings auch mit solch einer Analyse nicht exakt klären. Diese ist auch sehr abhängig von der Verteilung und Art der Daten, die es zu sortieren gilt. Außerdem ist es auch möglich, die einzelnen Algorithmen weiter zu optimieren. Beim Thema Algorithmen kommen Sie nicht darum herum, weitere Literatur zurate zu ziehen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt bestellen
Jetzt bestellen



