


7.3Threat Modeling
Sie wissen jetzt, wie man Bedrohungen in Bedrohungsbäumen darstellt. Nehmen Sie sich das Konzept Ihrer nächsten App, und erstellen Sie alle Bedrohungsbäume, die Ihnen einfallen. Wenn Sie jetzt zu den 99 % aller Menschen gehören, denen mit Mühe ein oder zwei Bedrohungen einfallen, dann sind Sie in guter Gesellschaft. Ohne weiteres Hilfsmittel aus dem Blauen heraus Bedrohungen identifizieren zu wollen, ist ähnlich schwierig, wie auf Befehl hin lustig zu sein – auch wenn Karnevalisten es Jahr für Jahr vergeblich versuchen und ihre Trauer über den sich nicht einstellenden Humor mit Alkohol ertränken.
Um dem Problem der Einfallslosigkeit zu begegnen, könnten Sie es den Karnevalisten gleichtun und sich volllaufen lassen. Das erhöht zwar nicht das Sicherheitsniveau Ihrer App, beschert Ihnen aber zumindest einen kurzweiligen Abend – und einen dicken Kopf am Tag danach.
Wir raten Ihnen allerdings, sich entweder einen Security-Experten einzukaufen oder sich einer Methodik zu bedienen, die Sie strukturiert durch den Prozess der Bedrohungsanalyse führt. Diese Methode nennt sich Threat Modeling – das Modellieren von Bedrohungen. Bekannt gemacht hat diese Methode die Firma Microsoft, indem sie Threat Modeling als integralen Bestandteil des Secure Development Lifecycle implementiert hat.
Ursprünglich stammt das Threat Modeling wie viele große Erfindungen der Menschheit aus dem militärischen Bereich. Ende der 1990er Jahre wurde es von der US-Army und der britischen Armee entwickelt. Mittlerweile ist es als Methodik zur Risikoanalyse in die Norm AS/NZS 4360 integriert, seit 2005 ist es Bestandteil des CVSS (Common Vulnerability Scoring System), und obendrein ist es Bestandteil von OCTAVE, der Operationally Critical Threat, Asset, and Vulnerability Evaluation, einem Ansatz zum Management von Informationssicherheitsrisiken des Software Engineering Institute der Carnegie Mellon University.
Der von Microsoft verwendete Ansatz beim Threat Modeling basiert auf der Idee, eine Applikation (ein System, eine Infrastruktur etc.) anhand eines Datenflussdiagramms (DFD) zu modellieren. Der Gedanke dahinter ist, dass Angriffe nur dort möglich sind, wo Daten in ein System gelangen oder ein System verlassen. Modelliert man den Fluss der Daten durch eine Anwendung, muss man »lediglich« an allen relevanten Stellen überlegen, welche Bedrohungen dort wirken können.
Das Threat Model wird erstmalig in der Designphase der Entwicklung erstellt, also bevor überhaupt eine einzige Zeile Code programmiert wird. Die Überlegung dahinter ist, dass es wesentlich günstiger ist, Sicherheitslücken so früh wie möglich im Entwicklungsprozess zu identifizieren. Denn je später eine Sicherheitslücke gefunden wird, desto teurer ist es, sie zu schließen.
Insbesondere ist das Threat Modeling auch dazu geeignet, Designfehler zu finden, eine Fehlerklasse, die sich mit automatischen Tools zur Codeanalyse nicht identifizieren lassen. Und eine auf einem Designfehler beruhende Sicherheitslücke zu schließen, kann extrem teuer oder gar unmöglich sein.
Die Geschichte vom Backup-Monster
Der Nichtmathematiker der beiden Autoren dieses Buches bekam vor einigen Jahren den Auftrag eines Kunden – nennen wir ihn der Einfachheit halber »Backup-Monster« –, dessen bereits im Betrieb befindliche Software für Online-Backups auf Sicherheitslücken hin zu untersuchen.
In einer Zeit, als jeder beim Begriff Cloud noch in den Himmel guckte, wollte Backup-Monster seinen Kunden mit der Software die Möglichkeit geben, automatisiert Backups von ihren Rechnern auf einen Server von Backup-Monster im Internet zu spielen. Natürlich wurde mit AES-256-Verschlüsselung geworben und damit, dass die Daten der Kunden absolut sicher seien und selbst von Backup-Monster nicht entschlüsselbar abgelegt würden.
Zum Zeitpunkt der Untersuchung hatte Backup-Monster einige Hundert bis tausend Kunden, die den Service fleißig nutzten und bereits mehrere Terabyte auf dem Server gesichert hatten. Beim Audit der Software kam dann heraus, dass Architekten und Programmierer gegen alle kryptografischen Regeln verstoßen hatten und die Software schlichtweg so offen wie ein Scheunentor war. Die Verstöße waren allesamt im Design angesiedelt (falscher Algorithmus, falsche Verschlüsselungsart, falsche Authentisierung).
Das Ergebnis war, dass Backup-Monster seine Software von Grund auf neu planen und schreiben musste. Denn bei einer Backup-Software hat die Verschlüsselung unmittelbaren Einfluss auf die Art und Geschwindigkeit der Datensicherung und lässt sich nicht durch den Austausch eines einzelnen Moduls ändern.
Da die Änderungen nicht nur Interna der Software betrafen, sondern auch die Kommunikation mit dem Server und insbesondere die Ablage der Backup-Daten auf dem Server, wurden mit dem Update auf einen Schlag alle auf dem Server liegenden Backups unbrauchbar. Backup-Monster hatte neben der Erstellung einer neuen Software also auch noch die unangenehme Aufgabe, allen Kunden mitzuteilen, dass ihre Backups sich in kleine Logikwölkchen aufgelöst hatten – und dass nicht ausgeschlossen werden konnte, dass irgendwer unbefugt auf diese Daten zugegriffen hatte.
Neben diesem Image-Schaden, der Backup-Monster viele Kunden kostete, verdoppelten sich die Kosten für die Erstellung der Software nahezu, da das komplette Design neu erstellt und anschließend implementiert werden musste.
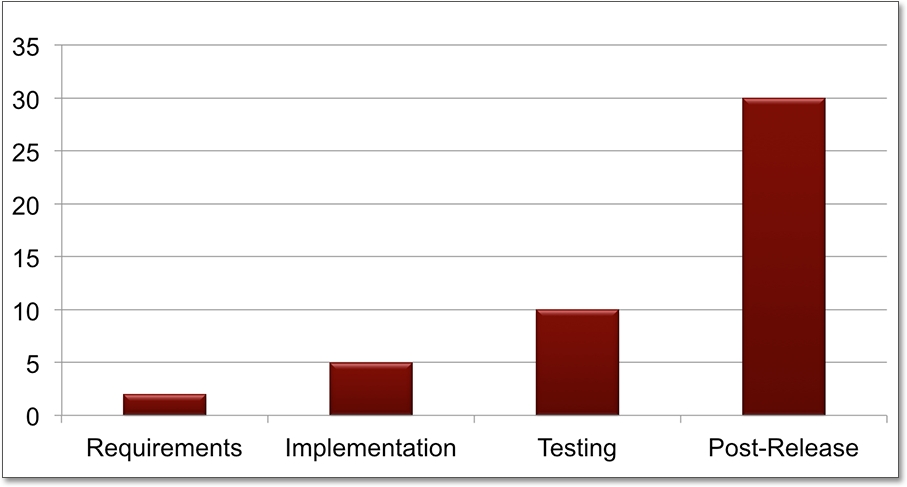
Abbildung 7.2 Die Kosten für die Fehlerbehebung in Software steigen umso mehr, je später der Fehler entdeckt wird.
Neben der vorstehenden Anekdote veranschaulicht der NIST-Report »The Economic Impacts of Inadequate Infrastructure for Software Testing« aus dem Jahr 2002 sehr deutlich den Zusammenhang zwischen dem Zeitpunkt, zu dem ein Fehler gefunden wird, und den Kosten, um ihn zu beheben, wie Abbildung 7.2 zeigt (das NIST ist das US-amerikanische Institut für Standardisierung: das National Institute of Standards and Technology).
7.3.1Erstellen eines Datenflussdiagramms
Abbildung 7.3 zeigt ein einfaches Datenflussdiagramm (DFD) für eine Banking-App, eine App also, die für den Zugriff auf Kontodaten bei einer Bank gedacht ist. Dieses Diagramm zeigt die App und ihre Kommunikationsbeziehungen. Es enthält noch keine näheren Informationen darüber, wie die App intern strukturiert ist. Ein Datenflussdiagramm dieser Detailtiefe bezeichnet man als Kontextdiagramm, und ein Kontextdiagramm ist die Grundlage eines Threat Models.
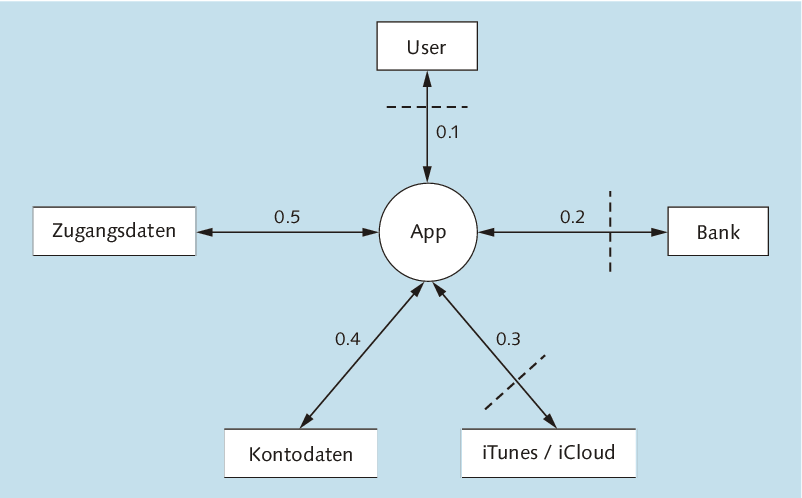
Abbildung 7.3 Kontextdiagramm einer Banking-App
Die nächste Ebene des Datenflussdiagramms, Ebene 1, zeigt die einzelnen Module der App (siehe Abbildung 7.4). Je nach Komplexität von Architektur oder App lässt sich das Datenflussdiagramm in weiteren Ebenen immer mehr verfeinern. Für die meisten Fälle genügen die Ebenen 0 und 1 aber vollkommen, denn wie Sie gleich sehen werden, lassen sich aus Abbildung 7.3 und Abbildung 7.4 schon alle für den Programmierer relevanten Bedrohungen ermitteln, die gegen die Banking-App wirken können.
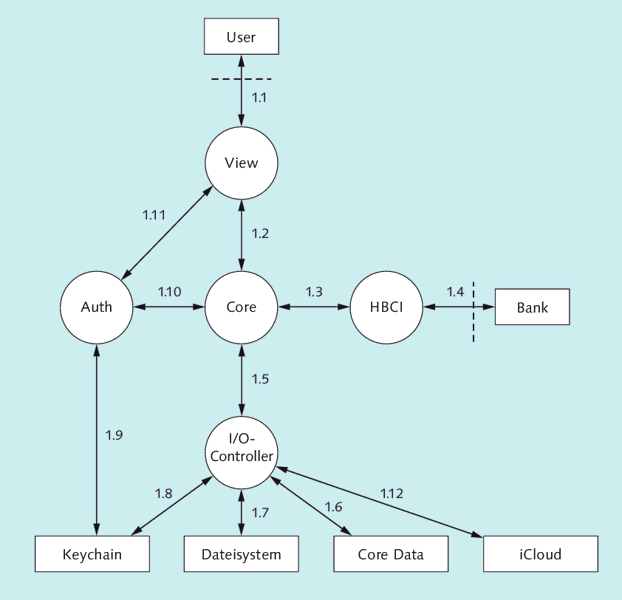
Abbildung 7.4 Ebene 1 der Banking-Applikation im Datenflussdiagramm
Bevor es an die Analyse des Datenflussdiagramms geht, ist noch ein kurzer Abstecher in die Formalitäten-Ecke notwendig, denn Sie werden wissen wollen, aus welchen Elementen ein Datenflussdiagramm überhaupt bestehen kann respektive was die vorstehenden Abbildungen überhaupt bedeuten.
Ein Datenflussdiagramm (DFD) kann aus den folgenden Elementen bestehen:
Im Folgenden sehen wir uns diese Elemente genauer an, bevor wir unsere Beispiel-App analysieren.
Entität
Eine Entität repräsentiert einen Akteur. Ein Akteur ist dadurch gekennzeichnet, dass er Aktionen ausführt, ohne dabei Daten zu verarbeiten. Ein Akteur erzeugt oder konsumiert Daten, verarbeitet sie aber nicht, zumindest nicht in einem für die sicherheitstechnische Analyse zu beachtenden Rahmen – ganz im Unterschied zu einem Prozess. In der Fachsprache bezeichnet man daher eine Entität im DFD als Quelle (erzeugt Daten) oder Senke (konsumiert Daten).

Beispiele für Entitäten sind:
- Benutzer
- Server
- Client
- Internet
- Applikation
- www.galileopress.de
- Lord Knut Knillenhauer
Prozess
Im Gegensatz zu einer Entität ist ein Prozess dadurch gekennzeichnet, dass er Daten verarbeitet. Das bedeutet, dass ein Prozess mindestens einen Dateneingang (Entry Point) und mindestens einen Datenausgang (Exit Point) besitzen muss. Ein Prozess kann niemals Quelle oder Senke in einem DFD sein. Die Daten, die ein Prozess verarbeiten soll, müssen von einem anderen Objekt zugeführt werden, und die verarbeiteten Daten müssen an ein anderes Objekt abgegeben werden.
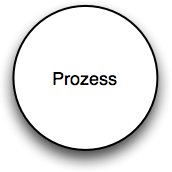
Beispiele für einen Prozess sind:
- App
- XML-Parser
- Authentisierungsmodul einer App
- Webserver
- I/O-Controller
Prozessgruppe
Eine Prozessgruppe ist nichts anderes als das, was der Name suggeriert: eine Gruppe von Prozessen, die der Übersichtlichkeit halber im DFD zu einer Gruppe zusammengefasst sind. Im Regelfall löst sich diese Gruppe in weiteren Ebenen des DFD auf. Eine komplexe App würde man beispielsweise in Ebene 0 als Prozessgruppe zeichnen und in den folgenden Ebenen dann in Module aufteilen.
Für die Prozessgruppe gelten folglich dieselben Regeln wie für einen Prozess: Sie muss mindestens einen Dateneingang und mindestens einen Datenausgang haben.

Abbildung 7.7 Prozessgruppe im DFD
Datenspeicher
Um mit Gertrude Stein zu sprechen: Ein Datenspeicher ist ein Datenspeicher ist ein Datenspeicher. Der Wortsinn steht für die Bedeutung im DFD. Jeder Ort, an dem Daten gespeichert werden, ist im DFD ein Datenspeicher. Im Gegensatz zu einem Prozess, der möglicherweise auch Daten speichert – und sei es nur temporär –, verarbeitet der Datenspeicher aber keine Daten, ist also ein rein passives Element und somit ausschließlich Quelle und/oder Senke von Informationen.

Abbildung 7.8 Datenspeicher im DFD
Beispiele für einen Datenspeicher sind:
- Datenbank
- Datei
- iCloud
- Heap/Stack
- Keychain
- Papierausdruck
Datenfluss
Der Datenfluss symbolisiert den eigentlichen Sinn des DFD, nämlich den Weg der Daten durch das modellierte System. Dabei stellt der Pfeil die Richtung des Datenverlaufes von einer Quelle zu einer Senke dar. Ein bidirektionaler Datenfluss kann entweder durch zwei gegenläufige Pfeile oder einen Doppelpfeil dargestellt werden.
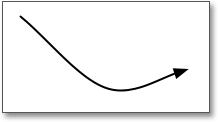
Abbildung 7.9 Datenfluss im DFD
Beispiele für einen Datenfluss sind:
- Netzwerkverkehr
- Benutzereingabe über GUI
- IPC
- Shared Memory
- RPC-Aufruf
Trust Boundary
Die Vertrauensgrenze oder Trust Boundary ist eine Erweiterung des ursprünglichen DFD für den Anwendungsfall des Threat Modelings. Eine Vertrauensgrenze trennt Bereiche unterschiedlicher Sicherheitsniveaus. Diese sind beim Threat Modeling von besonderem Interesse, da sich dort in der Regel die meisten Angriffsvektoren dadurch ergeben, dass Daten von einem unsicheren Bereich kommen und somit per se als nicht vertrauenswürdig gelten.

Abbildung 7.10 Vertrauensgrenze (Trust Boundary) im DFD
Beispiele für Vertrauensgrenzen sind:
- Firewall
- Prozesse mit unterschiedlichen Rechten
- Kommunikation über Netzwerke
- unterschiedliche Systeme (z. B. iPhone und iTunes-Rechner)
Analyse der Beispiel-App
Mit den Informationen aus den vorstehenden Absätzen können Sie nun die in Abbildung 7.3 und Abbildung 7.4 modellierte App analysieren. Das Kontextdiagramm zeigt, dass es zwei Entitäten gibt, die die App mit Daten beliefern. Der Benutzer gibt Daten über das GUI ein, und die Bank liefert Daten über das Netzwerk. Die App speichert die Zugangsdaten für das Online-Banking sowie die Bewegungs- und Transaktionsdaten in jeweils einem Datenspeicher. Zusätzlich ist zu beachten, dass Daten der App beim automatischen Backup über iTunes auf den Rechner des Benutzers gelangen können.
Ebene 1 teilt die App in ihre Hauptmodule auf, so dass der Datenfluss innerhalb der App sichtbar wird. Die Schnittstelle zum iTunes-Backup ist in dieser Ebene entfallen, da sie zur Darstellung im Kontextdiagramm keiner weiteren Detaillierung mehr bedarf.
Mit diesen beiden Diagrammen können Sie nun beginnen, spezifische Bedrohungen für die App zu ermitteln. Dazu ist es sinnvoll, eine Tabelle mit allen Elementen der Datenflussdiagramme zu erstellen, diese Tabelle Zeile für Zeile zu durchlaufen und für jedes Element zu überlegen, welche Bedrohung wirken kann. Entitäten, Prozesse und Datenspeicher lassen sich aufgrund der geringen Anzahl leicht in einer Tabelle wiederfinden. Um die vielen Datenflüsse sinnvoll in eine Tabelle überführen zu können, sollten Sie die Datenflüsse – wie in den beiden Abbildungen – mit Nummern versehen. Es hat sich in der Praxis als hilfreich herauskristallisiert, die Nummern aus der jeweiligen Ebene des DFD, gefolgt von einem Punkt und einer fortlaufenden Nummer, zusammenzusetzen. Damit ist sofort klar, in welcher Ebene sich der Datenfluss befindet, was bei komplexen Diagrammen mit vielen Ebenen extrem hilfreich ist.
Ein Datenflussdiagramm allein nützt natürlich nicht besonders viel, denn nur dadurch, dass Sie Ihre App schön aufgemalt haben, fallen Ihnen keine Bedrohungen ein. Es fehlen noch eine Methode und Quellen für beispielhafte oder häufig vorkommende Sicherheitslücken, die Sie als Hilfestellung verwenden können.
Informationsquellen zu Sicherheitslücken
Es gibt drei wichtige Quellen, die Informationen über Sicherheitslücken in IT-Systemen sammeln. Die erste und bei Programmierern wohl bekannteste ist das Open Web Application Security Project (OWASP) [Anm.: http://www.owasp.org] . OWASP ist ein freies, aus der Community heraus entstandenes Projekt, das sich ursprünglich nur mit der Sicherheit von Web-Applikationen beschäftigte. Daraus ist in der Zwischenzeit aber wesentlich mehr geworden: Es gibt mittlerweile sogar ein OWASP Mobile Security Project, das aber noch sehr in den Kinderschuhen steckt und daher keine Relevanz für die Praxis besitzt.
OWASP, das im Übrigen durch eine gemeinnützige Organisation gleichen Namens getragen wird, veröffentlicht regelmäßig eine Liste der 10 häufigsten Sicherheitslücken in Web-Applikationen, die OWASP Top 10. Neben einigen rein web-bezogenen Sicherheitslücken sind die OWASP Top 10 auch für iOS-Programmierer ein wichtiger Ratgeber, denn kaum eine App kommt heutzutage ohne Kommunikation mit dem Internet aus, und obwohl das Frontend eine App und kein Browser ist, lauern dieselben Gefahren, die in einer Web-Applikation lauern können, auch bei der Programmierung einer App, die mit Servern im Internet kommuniziert. Das ist Grund genug, einen kurzen Blick auf die OWASP Top 10 zu werfen (Version 2010).
Eine detaillierte Erläuterung der OWASP Top 10 und der darin aufgeführten Sicherheitslücken würde locker ein eigenes Buch füllen, daher möchten wir Sie an dieser Stelle auf das sehr ausführliche OWASP-Dokument verweisen. [Anm.: https://www.owasp.org/images/b/b8/OWASPTop10_DE_Version_1_0.pdf] Wir werden aber im weiteren Verlauf des Kapitels bei der Ausarbeitung des Threat Models auf einzelne Sicherheitslücken aus der Top 10 zu sprechen kommen, insbesondere auf A1, A7 und A9.
| ID | Thema | Bedrohung |
|
A1 |
Ein Angreifer kann Befehle in einen dafür nicht vorgesehenen Datenstrom injizieren. |
|
|
A2 |
Ein Server leitet schädliche Eingaben (Scripte) eines Angreifers ungefiltert an einen Benutzer weiter. |
|
|
A3 |
Ein Angreifer kann Anmelde- oder Session-Mechanismen umgehen oder manipulieren und so auf Daten anderer Benutzer zugreifen. |
|
|
A4 |
Ein Angreifer kann auf ungesicherte Objekte zugreifen (Dateien, URL etc.). |
|
|
A5 |
Ein Angreifer kann Aktionen im Benutzerkontext anderer Benutzer ausführen lassen. |
|
|
A6 |
Fehler in Konfiguration und Betrieb der Betriebsplattform führen zu Sicherheitslücken. |
|
|
A7 |
Ein Angreifer kann auf nicht oder fehlerhaft verschlüsselte Daten zugreifen. |
|
|
A8 |
Ein Angreifer kann einen nur auf Verbergen von URLs basierenden Zugriffsschutz umgehen. |
|
|
A9 |
Die Kommunikation zwischen den Netzwerkteilnehmern ist nicht ausreichend abgesichert und kann von einem Angreifer abgehört werden. |
|
|
A10 |
Ein Angreifer kann das Ziel von URL-Weiterleitungen manipulieren und damit Opfer auf falsche Seiten locken (z. B. Phishing-Angriffe). |
Eine weitere gute Informationsquelle ist die Liste der 25 gefährlichsten und häufigsten Softwarefehler, die Top 25 Most Dangerous Software Errors [Anm.: http://cwe.mitre.org/top25] . Herausgeber ist die MITRE Cooperation in Zusammenarbeit mit dem SANS Institute. MITRE ist eine US?amerikanische Forschungsorganisation, und das SANS Institute (SANS steht für SysAdmin, Audit, Networking, Security) ist ein genossenschaftlicher Zusammenschluss von IT-Fachleuten mit Fokus auf IT-Sicherheit.
Die MITRE Cooperation pflegt seit vielen Jahren eine öffentlich verfügbare Liste von Sicherheitslücken in IT-Systemen. Diese Liste mit dem Namen CVE (was für Common Vulnerabilities and Exposures steht) ist ein Industriestandard für die eindeutige Bezeichnung von Sicherheitslücken. Aus der CVE-Liste und den Erfahrungen des SANS (und weiterer IT-Sicherheitsunternehmen und -fachleute) entsteht jährlich die besagte Liste der 25 schlimmsten Software-Sicherheitslücken. Im Gegensatz zu den OWASP Top 10 ist diese Liste nicht primär auf die Sicherheit von Web-Anwendungen fokussiert, sondern auf IT-Systeme im Allgemeinen. Die meisten Elemente der OWASP Top 10 finden sich daher auch in dieser Liste wieder, wobei aus Konfigurationsfehlern resultierende Sicherheitslücken (OWASP A6) kein Bestandteil der Top 25 sind.
Die MITRE Cooperation war nicht immer ein Aushängeschild für IT-Sicherheit. Ganz im Gegenteil. Der bekannte KGB-Hack [Anm.: https://secure.wikimedia.org/wikipedia/de/wiki/KGB-Hack] Ende der 1980er Jahre lief zu großen Teilen über ungesicherte Systeme der MITRE Cooperation. Und wie es auch heute noch typisch für Institutionen ist, die man auf die Sicherheit ihrer IT-Systeme anspricht, stritt auch die MITRE Cooperation damals lange ab, ein Problem zu haben – so lange, bis es sich nicht mehr leugnen ließ.
Um Ihnen für den weiteren Verlauf des Kapitels weitere potenzielle Sicherheitslücken aufzuzeigen, finden Sie nachfolgend die Top 25 von MITRE und SANS aus dem Jahr 2011 samt einer kurzen Erläuterung, denn die Grundlage eines erfolgreichen Threat Models und der sicheren Programmierung ist die Kenntnis der wichtigsten Sicherheitslücken. Wo es dem Verständnis und der Wahrheitsfindung dient, sind einige Code-Beispiele eingefügt. Da alle aufgeführten Sicherheitslücken in Internet und Literatur bereits vielfach in epischer Breite und beliebiger Detailtiefe beschrieben sind, haben wir die folgenden Erläuterungen so kurz wie möglich gehalten, denn Sie möchten ja iOS-Apps programmieren und kein Fachmann für IT-Sicherheit werden.
Top 1: SQL Injection
Ein Angreifer schleust SQL-Befehle mit einer Eingabe in die Kommunikation ein und bringt diese Befehle somit auf der Datenbank zur Ausführung. Das Einschleusen erfolgt über die Benutzerschnittstelle, nicht über die Manipulation des Netzwerkverkehrs. SQL Injection ist daher ein Problem der Eingabevalidierung. Benutzereingaben müssen grundsätzlich auf schädliche Sonderzeichen hin untersucht werden, und diese Sonderzeichen müssen anschließend entfernt werden.
Eine beispielhafte SQL-Abfrage, die die Existenz eines Benutzers und die Richtigkeit seines Passwortes abfragt, ist die folgende:
select * from tbl.user where user='foo' and pw='bar';
Gibt es eine Zeile in der Tabelle tbl.user, bei der die Spalte user den Wert foo und die Spalte pw den Wert bar hat, ist der Benutzer vorhanden, das Passwort korrekt und die Anmeldung somit erlaubt.
Das SQL-Statement selbst steht fest, und die Werte für die Spalten user und pw kommen aus Benutzereingaben. In Objective-C abgebildet, sähe das Ganze wie folgt aus (die beiden NSString-Objekte user und pass simulieren in dem Beispiel die Benutzereingaben):
NSString *user = @"foo";
NSString *pass = @"bar";
NSString *query = [NSString stringWithFormat:
@"select * from tbl.user where user='%@'
and pass='%@'", user, pass];
NSLog(@"query: %@", query);
Listing 7.1 SQL-Befehl zur Autorisierung eines Benutzers
Das Ergebnis in der Konsole ist eine gültige SQL-Abfrage:
query: select * from tbl.user where user='foo' and pass='bar'
Gibt ein böswilliger oder neugieriger Benutzer statt seines regulären Passwortes aber einen simplen SQL-Befehl ein ...
NSString *pass = @"' or 1=1--";
... hat die ganze Abfrage jetzt eine ganz andere Bedeutung:
query: select * from tbl.user where user='foo'
and pass='' or 1=1--'
Diese Abfrage gibt als Ergebnis die Zeile der Tabelle tbl.user zurück, bei der die Spalte user den Wert foo hat, das Passwort leer ist oder die Bedingung 1=1 erfüllt ist. Und die letzte Bedingung ist immer erfüllt, denn 1 ist grundsätzlich immer 1! Ein Angreifer kann sich auf diese Weise also ohne Kenntnis des Passwortes am System anmelden. Der Grund dafür ist, dass der Programmcode die Eingabe des Benutzers ungefiltert in SQL-Befehle integriert und an die Datenbank schickt.
Die erste Maßnahme gegen SQL Injection ist daher die Validierung der Benutzereingabe auf schädliche Sonderzeichen – besonders auf das einfache Hochkomma, das Minuszeichen und das Semikolon.
Die zweite Maßnahme ist die Verwendung von Prepared Statements, sofern die jeweilige Datenbank dies unterstützt. Außerdem verfügen die meisten Datenbank-Bibliotheken über Abfragemethoden, die den Input-String direkt auf schädliche Sonderzeichen filtern.
Wenn Sie die iOS-eigene Datenbank SQLite verwenden, können Sie problemlos Prepared Statements [Anm.: https://www.sqlite.org/c3ref/stmt.html] verwenden, genauso wie bei vielen anderen gängigen Datenbanksystemen.
Whitelisting vs. Blacklisting
Zur Validierung von Eingabedaten gibt es zwei grundlegende Ansätze. Das Whitelisting definiert explizit die Zeichen, die erlaubt sind. Alle anderen Zeichen werden verworfen. Das Blacklisting definiert explizit die Zeichen, die verboten sind.
Sie sollten grundsätzlich bei allen sicherheitsrelevanten Auswahlverfahren das Whitelisting verwenden. Denn nur damit stellen Sie sicher, dass Sie nicht durch eigene Nachlässigkeit etwas übersehen oder von einem findigen Angreifer ausgetrickst werden.
Top 2: OS Injection
Analog zur SQL Injection kann ein Angreifer Betriebssystem-Befehle in eine Benutzereingabe schleusen und diese Befehle auf dem System zur Ausführung bringen, wenn die Benutzereingabe ungefiltert verarbeitet wird. Darüber hinaus gibt es gängige Injection-Angriffe gegen LDAP-Systeme und XML-Parser.
Die Maßnahme gegen diese Art von Angriffen sind analog zur SQL Injection die strikte Filterung von Benutzereingaben und, sofern möglich, die Einrichtung weiterer Filtermöglichkeiten auf dem Weg zum Backend.
Top 3: Buffer Overflow
Ein Angreifer kann die fehlende Längenüberprüfung einer Funktion ausnutzen und Speicherüberläufe provozieren, um z. B. eigenen Code zur Ausführung zu bringen. Besonders bekannt sind Angriffe gegen stackbasierte Buffer Overflows, die durch die Verwendung unsicherer C-Funktionen die Rücksprungadresse einer Funktion manipulieren und den Programmfluss dadurch auf Code umleiten, der vom Angreifer gesteuert wird.
Ein simples Beispiel für einen Angriff dieser Art zeigt der folgende C-Code:
char boo[4];
strcpy(boo, "AAAAAAAAAA");
NSLog(@"Peng!");
Listing 7.2 Simpler Buffer Overflow
Das Problem bei Listing 7.2 besteht darin, dass die Funktion strcpy die Länge ihrer Parameter nicht überprüft. So führt die Zuweisung von zehn Zeichen an ein nur vier Zeichen großes Array zu keiner Fehlermeldung während der Übersetzung. Zur Laufzeit überschreibt diese Zuweisung dann aber gnadenlos den Stack-Speicher – das Programm stürzt ab. Das Problem liegt also sowohl in der fehlenden Überprüfung durch die Sprache als auch in der falschen Verwendung der Funktion durch den Programmierer.
Neben stackbasierten Buffer Overflows gibt es solche, die auf dem Heap stattfinden. Grundsätzlich bezeichnet der Begriff Buffer Overflow aber alle Fehler, bei denen zu viele Daten in einen Puffer geschrieben werden.
Eine generische Maßnahme gegen Buffer Overflows gibt es nicht. Wenn Sie sich in der iOS-Programmierung nur auf der Ebene von Cocoa Touch bewegen, haben Sie keine Probleme mit Buffer Overflows. Sobald Sie aber in die C-Welt hinabtauchen, stehen Ihnen all die schönen Sicherheitslücken zur Verfügung, die C und seine Implementierung bietet. Apple hält zu diesem Thema den Secure Coding Guide bereit, der auf die Grundlagen der sicheren C-Programmierung eingeht. Werfen Sie im Bedarfsfall einen Blick dort hinein; sie finden das Dokument in der Xcode-Dokumentation. Grundsätzlich aber gilt, insbesondere für Programmierer ohne C-Erfahrung: Verwenden Sie in erster Linie den höchstmöglichen API-Level für Ihre Programmierung.
Top 4: Cross Site Scripting
Beim Cross Site Scripting (XSS) nutzt ein Angreifer fehlende Ein- und Ausgabevalidierung dazu, eigenen Schadcode über eine für XSS anfällige Applikation an Opfer zu liefern und dort zur Ausführung bringen zu lassen. Diese Art des Angriffs richtet sich gegen Clients, die in der Lage sind, JavaScript oder anderen aktiven Code auszuführen. Ein solcher Client ist z. B. jeder moderne Browser.
Beim XSS fungiert die Applikation mit der entsprechenden Sicherheitslücke nur als Mittelsmann. Anfällig sind alle Applikationen, die Benutzereingaben ungefiltert wieder ausgeben. Akzeptiert beispielsweise die Suchfunktion einer Web-Applikation beliebige Zeichen als Suchtext und gibt sie diese Zeichen ungefiltert mit den Suchergebnissen wieder aus, kann ein Angreifer JavaScript-Code an die Suchfunktion senden, der dann vom Webserver wieder ausgegeben wird. Der Browser interpretiert das JavaScript dann korrekt als JavaScript und führt den Code aus – fertig ist der Angriff. Alles, was der Angreifer tun muss, ist, seinen Opfern Links auf die Suchfunktion mit dem entsprechenden Schadcode zu senden. Klickt ein Opfer auf den Link, wird der Schadcode ausgeführt.
Die persistente Variante des XSS besteht darin, dass ein Angreifer Schadcode persistent in einer Applikation abspeichert. Ein Beispiel ist ein webbasiertes Forum, in dem ein Angreifer seine Postings neben normalem Text obendrein mit JavaScript-Code füllt. Jeder Benutzer, der sich anschließend ein solches Posting ansieht, hat den Schadcode dann in seinem Browser.
Abhilfe gegen XSS schafft das sogenannte Escapen von Sonderzeichen. Damit wandeln Sie die Sonderzeichen in der Benutzereingabe in unschädliche Varianten um, die vom Browser nicht als Code-Tags interpretiert werden. Allerdings ist beim XSS nicht nur die Eingabe-, sondern auch die Ausgabeseite relevant, denn Sie sollten nie davon ausgehen, dass alle Daten, die an den Benutzer gehen, aus vertrauenswürdiger Quelle stammen. Wenn Sie, um beim Beispiel des Forums zu bleiben, zwar alle Benutzereingaben auf schädliche Zeichen hin prüfen, sich aber über importierte RSS-Feeds XSS-Angriffe einhandeln, hilft Ihnen nur die Validierung der Ausgabedaten.
Das Escapen von Sonderzeichen ist mit Cocoa Touch praktischerweise ganz einfach, wie der folgende Code-Schnipsel zeigt:
NSString *evilString = @"c:\foobar<script>alert(23)</script>";
NSLog(@"evilString: %@", evilString);
NSString *sanitizedString =[evilString
stringByAddingPercentEscapesUsingEncoding:
NSUTF8StringEncoding];
NSLog(@"sanitizedString: %@", sanitizedString);
Listing 7.3 Escapen von Sonderzeichen
Der NSString evilString enthält neben sonstigen Sonderzeichen eckige Klammern, die dazu verwendet werden, Code für den Browser zu kennzeichnen. In der NSLog-Ausgabe sehen Sie, dass obendrein der Backslash zu einem Umbruch geführt hat, da er eine Formatierungsanweisung enthält:
2012-08-01 20:00:37.938 Top25Foo[32685:c07] evilString:
c:\foobar<script>alert(23)</script>
Der über die Methode stringByAddingPercentEscapesUsingEncoding ins UTF8-Format konvertierte NSString sanitizedString enthält hingegen nur noch sogenannte escapte Zeichen. Die stellt ein Browser zwar als die ursprünglichen Zeichen dar, interpretiert sie aber nicht mehr als Code-Tags:
2012-08-01 20:00:37.939 Top25Foo[32685:c07] sanitizedString:
c:%0Cfoobar%3Cscript%3Ealert(23)%3C/script%3E
Auf Ein- und Ausgabe angewendet, sorgt die Funktion also dadurch für Sicherheit, dass über sie keine XSS-Schwachstelle entstehen kann.
Top 5: Fehlende Authentisierung für sicherheitsrelevante Funktionen
Bei diesem Fehler handelt es sich weniger um einen Implementierungs- als vielmehr um einen Designfehler. Er besteht darin, dass der Zugriff auf sicherheitsrelevante Funktionen ohne wirksame Authentisierung möglich ist. Denken Sie bei der Implementierung sicherheitsrelevanter Funktionen daher immer daran, diese gut zu schützen. Wenn Ihre App beispielsweise einen Uploadservice für Dateien anbietet, dann wäre es ein typischer Fehler dieser Art, wenn die Uploadfunktion immer aktiviert wäre und jeder ohne Authentisierung die bereits hochgeladenen Dateien wieder herunterladen könnte. Damit fänden Sie in jedem öffentlichen Hotspot viele Freunde.
Top 6: Fehlende Autorisierung
Dieser Fehler liegt vor, wenn es entweder keine Autorisierungsfunktion gibt oder wenn eine vorhandene Autorisierungsfunktion fehlerhaft arbeitet. Wenn Ihre App beispielsweise im Kontext einer Client-Server-Architektur ein Rollenmodell verlangt, um verschiedene Benutzer und Benutzer unterschiedlicher Privilegierungsstufen zu unterscheiden, dann muss dieses Rollenmodell zum einen vorhanden, zum anderen sicher sein. Wenn ein Angreifer durch die Änderung eines Parameters Administratorrechte erlangt und auf die Daten aller Benutzer zugreifen kann, liegt ein Fehler dieser Art vor.
Top 7: Verwendung fest kodierter Geheimnisse
Es kommt ständig vor, dass eine App Geheimnisse speichern muss. Ein Geheimnis kann das Passwort für den Datenbankzugriff im Backend sein, ein Geheimnis kann ein Zertifikat sein, eine Seriennummer etc.
Ganz schlechter Stil – und ebendieser Fehler – ist das feste Einkodieren von Geheimnissen in die App, z. B. als NSString im Quelltext. Zum einen lässt sich ein String ohne weiteres aus der App wieder auslesen und ist somit allen zugänglich, die diese App in die Hände bekommen. Zum anderen lässt sich ein auf diese Weise gespeichertes Geheimnis nicht ändern – Sie müssten eine neue App übersetzen und verteilen.
iOS bietet zum Speichern von Geheimnissen die Keychain (siehe Abschnitt 7.4.2), daher gibt es zum Glück keine Ausrede dafür, Geheimnisse im Quelltext oder an vergleichbar unglücklicher Stelle zu speichern.
Top 8: Fehlende Verschlüsselung sensibler Daten
Die Überschrift beschreibt die Sicherheitslücke bereits sehr treffend. Gemeint sind damit alle Stellen, an denen personenbezogene oder andere sensible Daten nicht durch wirksame Verschlüsselung vor unbefugtem Zugriff geschützt werden. Das kann die Ablage im Dateisystem betreffen, die Übertragung im Netzwerk, Einträge in der Keychain etc. In Abschnitt 7.4.4, »Verzeichnisse und Datenattribute«, werden Sie die iOS-eigenen Mechanismen für die Verschlüsselung von Daten kennenlernen, so dass Ihnen dieser Fehler (hoffentlich) nicht unterlaufen wird.
Top 9: Unsichere Uploadfunktion
Beim Upload von Dateien auf Server kann es passieren, dass die fehlende Überprüfung der hochgeladenen Dateien dazu führt, dass ein Angreifer darüber Schadcode einschleust. Auf einem Webserver könnte beispielsweise ein Angreifer aktiven Code hochladen (z. B. Java oder PHP) und der Webserver den Code beim Abruf der hochgeladenen Datei ausführen. Damit stünde dem Angreifer der Webserver offen.
Auf eine App bezogen, könnte der Fall eintreten, dass eine App eine Server-Schnittstelle öffnet, um den Upload von Dokumenten auf ein iDevice zu ermöglichen. Gelingt es einem Angreifer, über diese Schnittstelle Dateien hochzuladen, die Schadcode oder sonstige Schadroutinen enthalten, öffnet diese App eine veritable Sicherheitslücke. Solch ein Schadcode kann z. B. ein Konfigurationsprofil für iOS sein, das der Angreifer mit dem iPhone Configuration Utility [Anm.: http://support.apple.com/kb/DL1465?viewlocale=de_DE] erstellt und ahnungslosen Nutzern in öffentlichen Hotspots über die Uploadfunktion der betreffenden App auf ihre iDevices lädt. Öffnet ein Benutzer dann die Datei, installiert sich das Profil, und je nachdem, welche Einstellungen der Angreifer vorgenommen hat, können diese die komplette Funktionsuntüchtigkeit des Gerätes bewirken.
Eine App sollte daher bei der Verwendung einer Uploadfunktion die hochgeladenen Dateien auf Typ und Inhalt hin prüfen.
Top 10: Sicherheitsrelevante Entscheidungen aufgrund unsicherer Eingaben
Diese Art von Fehler kommt häufig in einer Client-Server-Kommunikation vor. Rufen Sie sich die App aus dem Beispiel der SQL Injection noch einmal ins Gedächtnis. Diese App authentisiert einen Benutzer gegen eine Datenbank. Das heißt, dass der Benutzer nur Zugriff auf die Daten erhält, wenn seine Anmeldedaten in der Datenbank vorhanden sind. Die App validiert die Benutzereingaben, um zu verhindern, dass sich ein Angreifer über eine SQL Injection unbefugten Zugriff auf die Daten verschafft.
Nun ist die App auf dem iDevice aus Sicht des Datenbankservers, der sicher verwahrt in einem Rechenzentrum steht, ein unsicheres System. Daher sollte sich der Server nicht darauf verlassen, dass die Daten, die von der App kommen, vertrauenswürdig sind. Der Angreifer kann die Daten ja auch auf dem Weg von der App zum Server manipulieren, einfach indem er sich mit einem Proxyserver in die Mitte setzt. Wenn er dann dort eine SQL Injection in den Datenstrom einfügt, kann er die Datenbank kompromittieren. Der Server muss seinerseits also auch Maßnahmen gegen SQL Injection treffen.
Dies entspricht zum einen dem Prinzip Defense in Depth (siehe Abschnitt 7.3.3, »Generische Designgrundsätze«), vermeidet aber den Fehler, dass Daten aus unsicherer Quelle ungeprüft für sicherheitsrelevante Aktionen (in diesem Fall die Authentisierung des Benutzers) herangezogen werden.
Top 11: Ausführung mit nicht benötigten Rechten
Dieser Punkt subsumiert alle Sicherheitslücken, die daraus entstehen, dass Funktionen mit mehr Berechtigungen ausgeführt werden als nötig. Das betrifft bei der App-Entwicklung nicht die App selbst, denn diese bekommt Ihre Berechtigungen von iOS zugewiesen. Um beim Beispiel der SQL Injection zu bleiben, wären nicht benötigte Rechte dann vorhanden, wenn der Datenbankbenutzer, mit dem die App auf die Datenbank zugreift, über Administratorrechte auf der Datenbank verfügt (DB-Admin). Ist dies der Fall, wäre eine SQL Injection fatal, denn dann könnte ein Angreifer auf alle Daten in der Datenbank zugreifen.
Verwendet die App aber einen Datenbankbenutzer, der nur über so viele Rechte verfügt, wie notwendig sind – z. B. ausschließlich über lesenden Zugriff auf die Benutzertabelle –, dann hält sich der Schaden in Grenzen.
Top 12: Cross Site Request Forgery
Cross-Site Request Forgery (XSRF) ist eine web-spezifische Sicherheitslücke, die bei der App-Programmierung selbst nicht auftritt, sondern nur innerhalb einer Web-Applikation. Detaillierte Informationen dazu finden Sie in der Dokumentation des OWASP-Projekts [Anm.: https://www.owasp.org/index.php/Cross-Site_Request_Forgery_(CSRF)] .
Top 13: Path Traversal
Beim Path Traversal wird der Zugriff auf eine Ressource über Benutzereingaben manipuliert. Ein klassischer Fall ist eine Downloadfunktion, bei der ein Angreifer durch geschickte Manipulation von Parametern beliebige Dateien herunterladen kann. Wenn der Zugriff auf Ressourcen schon dynamisch erfolgen muss, sollte er nicht über Benutzereingaben manipulierbar sein. Überdies müssen Pfadelemente wie Punkte (.), Slashes (/) und Backslashes (\) aus Benutzereingaben herausgefiltert werden.
Top 14: Download ohne Integritätsprüfung
Eine Sicherheitslücke dieser Art entsteht, wenn eine App Code aus unsicherer Quelle nachlädt (also z. B. aus dem Internet) und diesen Code nicht auf Integrität hin prüft. Manipuliert ein Angreifer den Code, kann er darüber beliebigen Schadcode einschleusen.
Bei der Programmierung von Apps für den Apple App Store kann dieser Fehler nicht auftreten, da die Apple-Richtlinien das Nachladen von Code verbieten. Eine App mit so einer Funktion käme (falls Apple dies bei der Überprüfung der App bemerkt) daher nicht in den Store.
Programmierer im Enterprise-Umfeld müssen sich aber nicht an die Apple-Richtlinien halten, so dass eine App beliebigen Code nachladen kann. Denken Sie in diesem Fall immer daran, eine Integritätsprüfung zu implementieren, um sicherzustellen, dass der Code auch der ist, den Sie haben wollen.
Top 15: Fehlerhafte Autorisierung
Die fehlerhafte Autorisierung von Benutzern oder Rollen führt immer wieder zu schweren Sicherheitslücken, die den unbefugten Zugriff auf Ressourcen erlauben. Wenn Ihre App Trust- und Rollenmodelle verwendet, um Benutzer oder Rollen zu autorisieren, müssen Sie darauf achten, dass ein Angreifer den Autorisierungsmechanismus nicht umgehen kann.
Top 16: Verwendung von Funktionen in unsicheren Bereichen
Sicherheitslücken dieser Art entsprechen denen von Punkt 10, nur dass sie nicht aus der Verwendung von Informationen aus unsicherer Quelle resultieren, sondern aus der Verwendung von Funktionalität aus unsicherer Quelle, z. B. aus der Verwendung eines Frameworks, das Schadroutinen enthält.
Es ist schwierig, Sicherheitslücken dieser Art zu erkennen. Sie haben in Kapitel 2, »Die Reise nach iOS«, Kategorien kennengelernt. Es ist z. B. möglich, dass ein Framework über Kategorien die Methode einer Cocoa-Touch-Klasse überschreibt und mit unerwünschten Funktionen anreichert. Wenn Sie dieses Framework in den eigenen Code einbinden, ist diese Kategorie bei allen Klassen vorhanden, die über Importanweisungen mit dem Framework verbunden sind.
Ein anderer Fall ist das Auslagern von Funktionalität an einen Dienst, z. B. eine Cloud. Wenn Sie nicht zufällig Betreiber dieses Dienstes sind und eine belastbare Aussage über die Sicherheit desselben treffen können, sollten Sie den Dienst als grundsätzlich unsicher betrachten und die entsprechenden Vorkehrungen treffen, um die Gefahren zu minimieren, die aus dieser Annahme resultieren.
Top 17: Fehlerhafte Berechtigungen
Eine Sicherheitslücke dieser Art liegt vor, wenn eine wichtige Ressource nicht ausreichend vor unbefugtem Zugriff geschützt ist. Ein Klassiker sind falsche Dateisystemberechtigungen für sicherheitsrelevante Dateien. Wenn ein Angreifer lesend auf die Datei /etc/shadow in einem Linux-System zugreifen kann, hat er Zugriff auf die Passwort-Hashes aller Benutzer.
Mit solchen Feinheiten haben Sie dank der restriktiven Sandbox von iOS bei der App-Programmierung nicht zu kämpfen, trotzdem sollten Sie sich als App-Programmierer immer die Frage stellen, wer Zugriff auf eine Ressource bekommen muss, und den Zugriff grundsätzlich so restriktiv wie möglich gestalten.
Top 18: Verwendung potenziell unsicherer Funktionen
In der Beschreibung von Buffer Overflow (Top 3) haben Sie bereits die C-Funktion strcpy kennengelernt, die aufgrund der fehlenden Überprüfung der Pufferlänge grundsätzlich unsicher ist. Funktionen solcher Art gibt es einige, und die Verwendung dieser Funktionen führt immer wieder zu schweren Sicherheitslücken.
Darüber hinaus gehört die falsche Verwendung kryptografischer Funktionen bzw. die Verwendung unsicherer kryptografischer Funktionen zu dieser Fehlerklasse. So weist die API CCCryptor in iOS eine Sicherheitslücke auf, da es zwar standardmäßig den CBC-Modus [Anm.: https://secure.wikimedia.org/wikipedia/de/wiki/Cipher_Block_Chaining_Mode] für symmetrische Algorithmen verwendet, als Initialisierungsvektor aber nur Nullen verwendet. Das führt zu einer unsicheren Verschlüsselung. Die Verwendung von CCCryptor im Standardmodus ist daher ein Beispiel für die Verwendung einer potenziell unsicheren Funktion.
Top 19: Verwendung unsicherer kryptografischer Algorithmen
Neben der Verwendung unsicherer Funktionen ist die Verwendung unsicherer kryptografischer Algorithmen eine weitere typische Quelle von Sicherheitslücken. Sie müssen als Programmierer daher immer prüfen, dass die von Ihnen verwendeten Algorithmen noch als sicher gelten.
Die Verwendung sicherer Algorithmen allein ist noch kein Garant für Sicherheit. Sie müssen darüber hinaus auf die korrekte Verwendung achten. Dazu zählen insbesondere die folgenden Punkte:
- ausreichend lange und starke Schlüssel
- sichere Ablage von Schlüsselmaterial
- zufällige Initialisierungsvektoren
- Verwendung hinreichend zufälliger Zufallszahlen-Generatoren
Top 20: Falsche Berechnung von Puffergrößen
Dieser Punkt entspricht Punkt 3. Warum der falsche Umgang mit Puffergrößen zweimal in der Top 25 auftaucht ... Gute Frage.
Top 21: Fehlende Begrenzung von Anmeldeversuchen
Ein Weg, unbefugten Zugang zu Systemen zu erlangen, ist das Durchprobieren von Anmeldedaten, der sogenannte Brute-Force-Angriff. Hat eine App oder ein System keinen Mechanismus implementiert, um Brute-Force-Angriffe zu erkennen und zu unterbinden, kann ein Angreifer beliebig viel Zeit damit verbringen, sich Zugang zu verschaffen.
Implementieren Sie daher stets Mechanismen gegen Brute-Force-Angriffe, wenn Sie Authentisierungsfunktionen in Ihrer App haben. Ein gutes Beispiel ist das iPhone selbst. Mit aktiviertem Benutzercode haben Sie in der Standardkonfiguration sechs Anmeldeversuche, bevor das Gerät für eine Minute gesperrt wird. Ein angemessen starkes Passwort vorausgesetzt, braucht ein Angreifer schon sehr viel Glück, um dieses in sechs Versuchen zu erraten. Nach weiteren Fehlversuchen sperrt sich das iPhone am Ende für 60 Minuten, bis es sich nach 10 Anmeldeversuchen selbst löscht. Die gestaffelte Sperrung ist ein gutes Mittel, automatisierte Angriffe auszubremsen.
Top 22: Unsichere URL-Weiterleitung
Das Problem unsicherer URL-Weiterleitungen betrifft ausschließlich Web-Anwendungen und ist daher für die App-Programmierung nicht von Interesse. Grundsätzlich erlauben unsichere URL-Weiterleitungen einem Angreifer, Opfern Links von vertrauensvollen Institutionen zu schicken, die dann aufgrund einer fehlerhaft implementierten URL-Weiterleitungsfunktion an eine vom Angreifer kontrollierte Webseite weiterleiten, wo den Opfern dann Schadcode untergeschoben wird oder sie Opfer eines Phishing-Angriffs werden.
Top 23: Formatstring-Fehler
Formatstring-Fehler sind eine Erblast aus der C-Programmierung. Sie haben Formatstrings bereits in Kapitel 2, »Die Reise nach iOS«, kennengelernt und im weiteren Verlauf des Buches an zahlreichen Stellen verwendet. Formatstrings stellen aufgrund ihrer Natur eine grundsätzliche Gefahr dar: Ein Angreifer kann einen Formatstring, zu dem er die Eingabe liefern kann, durch eigene, eingeschleuste Formatierungsanweisungen dazu bringen, etwas anderes zu tun als vorgesehen – namentlich, unbefugt auf Speicher zuzugreifen. Bei der Verwendung von Formatstrings sollten Sie daher stets darauf achten, dass die Anzahl der Platzhalter der Anzahl der Argumente entspricht und dass Eingaben außerhalb ihres eigenen Kontrollbereichs nicht ungeprüft in einem Formatstring landen.
Top 24: Integer Overflow oder Wraparound
Computer sind folgsame Gesellen, denn sie machen genau das, was man ihnen sagt. Betrachten Sie die folgenden Code-Zeilen:
char foo = 127;
NSLog(@"foo vorher: %i", foo);
foo++;
NSLog(@"foo nachher: %i", foo);
Listing 7.4 Addition von 1 und 127 im Datentyp »char«
int bar = 4294967295;
NSLog(@"bar vorher: %u", bar);
bar++;
NSLog(@"bar nachher: %u", bar);
Listing 7.5 Addition von 1 und 4.294.967.295 im Datentyp »Integer«
int fooBar = 0;
NSLog(@"bar vorher: %u", fooBar);
fooBar--;
NSLog(@"bar nachher: %u", fooBar);
Listing 7.6 Subtraktion von 0 und 1 im Datentyp »Integer«
Die Konsolenausgabe von Listing 7.4 ist die folgende:
2012-08-02 21:06:38.514 Top25Foo[76237:c07] foo vorher: 127
2012-08-02 21:06:38.516 Top25Foo[76237:c07] foo nachher: –128
Was ist passiert? Der Datentyp char ist 8 Bit groß und kann daher 256 verschiedene Werte annehmen. Da es sich hier um ein char mit Vorzeichen handelt (signed), wird ein Bit für das Vorzeichen verbraucht: daher hat char einen Wertebereich von –128 bis 127. Die Addition von 1 und 127 führt also nicht etwa dazu, dass ein Laufzeitfehler auftritt, sondern der Computer schiebt die Bits einfach weiter: Ein Überlauf findet statt, und das Ergebnis ist -128. [Anm.: Das liegt an der Binärdarstellung der Werte.] Wenn dieser Wert in einem Programm zum Regeln einer Motorengeschwindigkeit genutzt wird, hätte der Überlauf fatale Folgen. Lachen Sie jetzt nicht; die europäische Rakete Ariane 5 sprengte sich bei ihrem Jungfernflug aufgrund eines Überlaufs selbst in die Luft!
In der Konsolenausgabe zu Listing 7.5 sehen Sie dasselbe Verhalten, diesmal mit einem Integer-Wert:
2012-08-02 21:19:38.561 Top25Foo[77833:c07]
bar vorher: 4294967295
2012-08-02 21:19:38.561 Top25Foo[77833:c07]
bar nachher: 0
Dieses Mal ist der Datentyp ohne Vorzeichen (unsigned). Die Addition von 1 und dem maximalen Integer-Wert 4.294.967.296 (32-Bit-Integer) führt zu einem Überlauf, und der Wert steht anschließend auf dem Minimalwert 0.
Das Listing 7.6 zeigt den umgekehrten Fall, die Subtraktion vom Minimalwert bei einem unsignierten 32-Bit-Integer. Der Wert »wrappt«, und heraus kommt der Maximalwert:
2012-08-02 21:19:38.562 Top25Foo[77833:c07]
bar vorher: 0
2012-08-02 21:19:38.563 Top25Foo[77833:c07]
bar nachher: 4294967295
Die Auswirkungen von Integer Overflows können mannigfaltig sein. Im besten Fall führen sie zum Absturz einer App, in schlimmeren Fällen zum Absturz einer Rakete. Achten Sie daher tunlichst darauf, Datentypen zu verwenden, die groß genug für die erwarteten Werte sind. Und vertrauen Sie nicht darauf, dass ein Benutzer nur Werte eingibt, die Sie erwarten. Aber dieses Thema hatten wir ja bereits.
Übrigens, die Verwendung von NSNumber als Wrapper für die primitiven C-Datentypen schützt Sie auch nicht vor Integer Overflows, wie das folgende Code-Beispiel zeigt:
NSNumber *tschar = [NSNumber numberWithChar:257];
NSLog(@"tschar: %i", [tschar charValue]);
Listing 7.7 »NSNumber« mit »char«-Wert 257
Das Ergebnis ist ernüchternd:
2012-08-02 21:31:43.466 Top25Foo[79525:c07] tschar: 1
Cocoa Touch nimmt Ihnen in Sachen Integer Overflows nicht das Denken ab. Denken Sie daran!
Top 25: Verwendung von Hashfunktionen ohne Salz
Die letzte Sicherheitslücke aus der Top 25 ist die Verwendung von Hashfunktionen ohne Salz. Das hört sich nicht lecker an, und es ist auch nicht lecker. Kryptografische Hashfunktionen verwendet man häufig dazu, Geheimnisse so zu speichern, dass sie nicht mehr wiederhergestellt werden können. Ein Anwendungsfall ist das Speichern von Passwort-Hashes.
Wer die Passwörter seiner Benutzer nicht im Klartext speichern möchte, was ja ein ungeheures Missbrauchspotenzial eröffnet, schickt sie durch eine kryptografische Hashfunktion – eine sogenannte Falltür-Funktion – und speichert nur den daraus resultierenden Hashwert. Aus diesem lässt sich das Passwort nicht mehr zurückrechnen. Um anschließend zu überprüfen, ob ein Benutzer sein Passwort korrekt eingegeben hat, müssen Sie nur die Eingabe durch dieselbe Hashfunktion schicken und das Ergebnis mit dem gespeicherten Hash vergleichen.
Es gibt zwar für aktuelle Hashfunktionen keine Möglichkeit, den Ausgangstext aus dem Hash zurückzurechnen, man kann aber Hashes im Voraus berechnen. [Anm.: http://www.freerainbowtables.com/de] Gelangt man dann als Angreifer in den Besitz von Passwort-Hashes, muss man nur noch die erbeuteten Hashes mit den Listen bereits errechneter Hashes vergleichen, um so auf die Passwörter zu kommen.
Nun nehmen die Listen vorausberechneter Hashes schnell viele Terabyte an Platz ein, und die Berechnung ist aufwendig, so dass es nicht für beliebige Texte vorberechnete Listen gibt, sondern nur für Passwörter bestimmter Länge und Komplexität. Da Benutzer gerne einfach zu merkende Passwörter nehmen, ist die Wahrscheinlichkeit sehr groß, dass sich aus einer erbeuten Datenbank die Passwörter über die vorausberechneten Hashes wiederherstellen lassen. Sind darüber hinaus Hashes von verschiedenen Systemen gleich, weiß der Angreifer, dass dort auch die Passwörter gleich sind.
Eine sichere Hashfunktion zeichnet sich dadurch aus, dass sie zwei Bedingungen erfüllt:
- Unumkehrbarkeit: Aus dem Hashwert darf der Klartext nicht rekonstruierbar sein.
- Kollisionsfreiheit: Verschiedene Klartexte dürfen nicht denselben Hashwert ergeben.
Um dies zu verhindern, sollte man beim Hashen von Passwörtern (oder anderen Geheimnissen) eine zufällige Zeichenkette vor den eigentlichen Text stellen. Diese Zeichenkette nennt man Salt (Salz), und sie sorgt dafür, dass Angriffe mit vorausberechneten Hash-Tabellen ins Leere laufen. Das ist wenig Aufwand für viel Sicherheit. Ein guter Tausch.
Zusammenfassung
Falls Sie sich bisher noch nicht mit sicherer Programmierung und typischen Sicherheitslücken auseinandergesetzt haben, werden Sie nun wahrscheinlich den Eindruck gewonnen haben, dass man in der IT-Sicherheit eine durchweg misanthropische Einstellung aufweisen muss. Und in der Tat ist es so, dass Misstrauen das oberste Gebot bei der sicheren Programmierung ist. Sie müssen zwar nicht gleich zum Menschenfeind werden, aber vertrauen Sie nichts und niemandem, den Sie nicht kennen. Daten aus nicht vertrauenswürdiger Quelle sind gefährlich.
Doch sichere Software lässt sich nicht allein durch das Beachten relevanter Punkte in der Implementierungsphase produzieren. Sicherheit lässt sich vielmehr nur durch einen Softwareentwicklungsprozess gewährleisten, der verschiedene Sicherheitsaspekte berücksichtigt, so dass eine durchgängige Qualität von der Anforderungsphase bis zum Ausrollen der Software entsteht.
Im Anhang des Buches finden Sie einen Anforderungskatalog, der die Anforderungen an einen Softwareentwicklungsprozess definiert, der das Erstellen sicherer Software ermöglicht. Insbesondere im Firmenumfeld lohnt sich ein Blick in diesen Anforderungskatalog.
Doch nun zurück zum Threat Model, einem integralen Bestandteil sicherer Softwareentwicklung, dem Sie sich jetzt – gewappnet mit dem Wissen um die typischsten Sicherheitslücken – nähern können.
7.3.2STRIDE
Nachdem Sie das Datenflussdiagramm (DFD) für Ihre App erstellt und alle Elemente in eine Tabelle überführt haben, kommt STRIDE ins Spiel. STRIDE hat seinen Ursprung ebenfalls bei Microsoft und ist ein Akronym, das sich aus den Anfangsbuchstaben der sechs Kategorien zusammensetzt, in die sich alle Bedrohungen einordnen lassen, die nach der STRIDE-Kategorisierung auf ein IT-System wirken können.
STRIDE ist also genau die Hilfe, die Sie benötigen, um Bedrohungen identifizieren zu können. Für jedes Element im DFD, also für jede Zeile der Tabelle, müssen Sie jetzt »nur« noch überlegen, welche Art von Bedrohungen aus den sechs STRIDE-Kategorien wirken kann. Sie erhalten mit STRIDE also eine generische Bedrohungsvorlage und können daraus eine konkrete Bedrohung ableiten – oder eben auch nicht, wenn keine Bedrohung vorhanden ist.
STRIDE steht für die folgenden sechs Kategorien:
- Spoofing: Vortäuschen einer falschen Identität
- Tampering: Verändern von Daten
- Repudiation: Abstreiten von Aktionen
- Information Disclosure: Preisgabe von Informationen
- Denial of Service: Störung eines Dienstes
- Elevation of Privileges: unbefugtes Erlangen von Rechten
Tabelle 7.2 führt für jede der sechs STRIDE-Bedrohungen eine generische Gegenmaßnahme und konkrete Maßnahmen auf:
| STRIDE | Maßnahme | Beispiel |
|
Spoofing |
Public-Key-Kryptografie |
|
|
Tampering |
Hash-Prüfung |
|
|
Repudiation |
Logging |
|
|
Information Disclosure |
Verschlüsselung |
|
|
Denial of Service |
Performance-Optimierung |
|
|
Elevation of Privileges |
Benutzerverwaltung |
Aufgrund ihrer Natur unterliegen nicht alle Elemente des DFD allen STRIDE-Bedrohungskategorien. Da eine Entität z. B. keine Daten verarbeitet, kann kein Tampering stattfinden. Ebenso ist Information Disclosure bei einer Entität keine Bedrohung. Ein Benutzer kann zwar seine Zugangsdaten für das Online-Banking bei Facebook veröffentlichen, dies ist aber keine Bedrohung, die für den Programmierer der Banking-App relevant ist – die Bedrohung ist out-of-scope oder, um Douglas Adams zu bemühen, ein PAL (Problem anderer Leute).
Abbildung 7.11 zeigt die möglichen Kombinationen von DFD-Element und STRIDE-Kategorie.
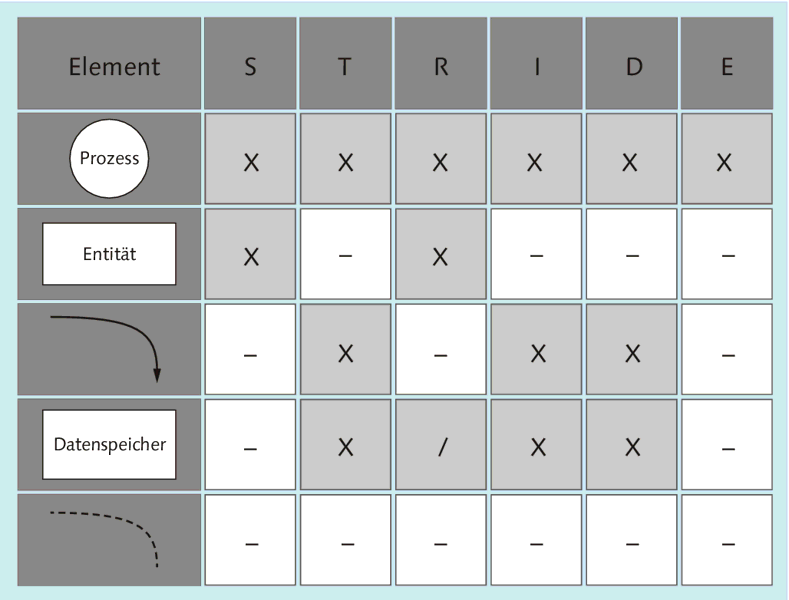
Abbildung 7.11 Zuordnung von DFD-Elementen zu STRIDE-Kategorien
Nun haben Sie alle Informationen beisammen, um sich methodisch der Bedrohungsanalyse Ihrer App anzunehmen. Erstellen Sie eine Tabelle aller Elemente, und überlegen Sie für jedes Element, welche in die Kategorisierung des STRIDE-Katalogs passende Bedrohung für das betreffende Element vorhanden sein könnte. Da die Tabelle Ihre Software auf dem gesamten Lebensweg begleiten wird, empfiehlt sich für die Erstellung ein dynamisches, bei der Arbeit mit Tabellen halbwegs sinnvolles Medium wie Numbers, OpenOffice oder Excel. Das Erweitern und Bearbeiten einer Tabelle ist damit schlichtweg einfacher, und da Sie das Threat Modeling nicht zum Selbstzweck durchführen, sondern möglichst effizient arbeiten möchten, sollte das Handwerkszeug Ihnen möglichst viel Arbeit abnehmen.

Abbildung 7.12 Threat Model der Beispiel-App
Wichtige Grundregeln beim Threat Modeling
Der große Nutzen des Threat Modelings liegt in der Methodik. Diese Methodik leitet auch einen unerfahrenen Anwender durch die schwierige Aufgabe, spezifische Bedrohungen für seine App zu ermitteln. Das Threat Modeling ist diese Methodik, und daher ist es für den Erfolg unerlässlich, diese Methodik strikt anzuwenden. Das Zeichnen eines DFD und das anschließende Anfertigen einer Tabelle aller Elemente und ihrer Bedrohungen führt für sich genommen zu keinen bahnbrechenden Erkenntnissen; beide Tätigkeiten sind aber darauf ausgerichtet, den Anwender zu führen.
Durch das methodische Vorgehen wird der Blick des Anwenders auf die wesentlichen Punkte gelenkt. Der Anwender wird gezwungen, sich intensiv Gedanken über seine App zu machen, und er erhält mit der STRIDE-Kategorisierung eine gute Hilfestellung, um selbständig Bedrohungen identifizieren zu können.
Es gibt zwei typische Fehler beim Threat Modeling. Der erste Fehler ist, die Methodik nicht durchgehend anzuwenden. Machen Sie sich immer die Mühe, ein ausreichend detailliertes DFD zu erstellen. Das zwingt Sie dazu, sich intensiv mit der Architektur Ihrer App auseinanderzusetzen. Erstellen Sie im Anschluss die Tabelle der Elemente und der Bedrohungen. Dieser Schritt ist nicht nur dazu gedacht, alle Elemente auf Bedrohungen aus dem STRIDE-Katalog abzuklopfen, die Tabelle ist überdies das zentrale Dokument des gesamten Vorgangs. Liegt eine vernünftige Dokumentation vor, können Sie immer darauf zurückgreifen, was insbesondere bei der Weiterentwicklung Ihrer App wichtig ist. Sie möchten nicht für jedes neue Feature ein neues Threat Model erstellen, sondern das vorhandene erweitern können.
Der zweite Fehler beim Threat Modeling ist es, über die Einordnung einer Bedrohung in eine der sechs STRIDE-Kategorien zu diskutieren. Ist, um bei der Beispiel-App zu bleiben, der Zugriff per Jailbreak (ID 1) nun ein Spoofing oder nicht eher eine Elevation of Privileges? Die Antwort ist: Das ist total egal! Es geht nicht darum, mögliche Bedrohungen möglichst passgenau in die sechs STRIDE-Kategorien einzuordnen, sondern darum, die sechs STRIDE-Kategorien zu verwenden, um Bedrohungen zu identifizieren! Allzu häufig verlieren sich Threat-Modeling-Workshops in dieser Diskussion, und das Ergebnis sind ein unvollständiges Threat Model, eine Software mit unentdeckten Sicherheitslücken und ein Team von Teilnehmern, das mit dem trügerischen Gefühl nach Hause geht, »richtig was geschafft« zu haben.
Denken Sie also immer daran: Niemand gibt Ihnen eine gute Note für eine schöne Zeichnung, eine formvollendete Tabelle und korrekt klassifizierte Bedrohungen. Heise online wird Ihnen aber sicher einen prominenten Platz in seinem Newsticker geben, wenn Ihre App durch eklatante Sicherheitslücken aufgefallen ist.
Um Ihnen den Einstieg und die Arbeit mit den STRIDE-Kategorien zu erleichtern, finden Sie nachfolgend zu jeder STRIDE-Kategorie einige Beispiele für Bedrohungen samt geeigneten Gegenmaßnahmen.
Spoofing
Spoofing subsumiert alle Bedrohungen, bei denen ein Angreifer eine Identität fälscht, austauscht oder austauscht. Der Begriff der Identität ist dabei nicht auf die Identität einer Person beschränkt, sondern umfasst alle Objekte, die über eine Identität verfügen. Das können die verschiedensten Arten von Objekten sein:
- Benutzer
- Server
- App
- RSS-Feed
- Bibliothek
- Framework
- IP-Adresse
- www.cocoaneheads.de
Tampering
Alle Angriffe, die mit der Veränderung von Daten zu tun haben, fallen in die Kategorie Tampering. Das reicht vom schreibenden Zugriff in eine Datenbank mittels SQL Injection über Manipulationen am Dateisystem bis zur Veränderung der Netzwerkkommunikation.
Repudiation
Repudiation fasst sowohl das Verschleiern von Aktionen und Angriffen durch fehlendes Logging als auch Angriffe gegen und über Logging-Mechanismen zusammen.
Information Disclosure
Die Preisgabe von Informationen jeglicher Art fällt in die Kategorie Information Disclosure. Informationen können dabei an den verschiedensten Stellen anfallen und von beliebiger Natur sein. Beispiele für Information Disclosure sind:
- Fehlermeldungen
- sensible Informationen im Syslog (»Konsole«)
- Verwendung von Klartextprotokollen für vertrauliche Daten
- Secret Key für symmetrische Verschlüsselung als String im Binary
- Debug-Symbole
- Netzwerkbanner von Serverdiensten
| Bedrohung | Maßnahme |
|
Eine App gibt bei (gezielter) Fehlbenutzung Fehlermeldungen mit Debug-Informationen aus. |
Fehlermeldungen sollten grundsätzlich neutral gehalten sein. Debug-Informationen und Stack-Traces sollten ausschließlich in separate Debug-Log-Dateien oder an den Syslog-Server geschrieben werden. |
|
Der geheime Schlüssel für die Verwendung eines symmetrischen Kryptoalgorithmus ist als String im App-Binary gespeichert. Ein Angreifer kann den String ohne großen Aufwand auslesen und erhält auf diese Weise Zugriff auf die Verschlüsselung. |
Sichere Ablage geheim zu haltender Informationen, z. B. in der Keychain. Keine Verwendung eines einzigen statischen Schlüssels für alle Instanzen einer App |
|
Übertragung von Zugangsdaten über ein Klartextprotokoll (anfällig für Man-in-the-Middle-Angriffe) |
Übertragung sensibler Daten ausschließlich über verschlüsselte Protokolle |
Denial of Service
Der Begriff Denial of Service ist aus Funk und Fernsehen im Zusammenhang mit DoS- oder DDoS-Angriffen (Distributed Denial of Service) auf Webseiten bekannt. Unter Denial of Service versteht man aber nicht nur netzwerkbasierte Angriffe, die darauf ausgelegt sind, einen Webserver in die Knie zu zwingen, sondern alle Arten von Angriffen, die dazu führen, dass ein System nicht mehr so funktioniert wie vorgesehen.
Elevation of Privileges
Die letzte STRIDE-Kategorie umfasst alle Angriffe, bei denen ein Angreifer Aktionen in einem anderen als dem eigenen Rechtekontext ausführt. Im Webbereich ist das Cross-Site-Scripting eine bekannte Schwachstelle, bei der ein Angreifer eigenen Code im Sicherheitskontext eines anderen Webservers ausführen kann.
7.3.3Generische Designgrundsätze
Beim sicheren Design von Software gibt es einige grundsätzliche Prinzipen, die Sie
als Entwickler verinnerlichen sollten. Da es nur eine Handvoll sind, sollte es Ihnen
nicht allzu schwerfallen, sie sich zu merken. Die konsequente Beachtung dieser Prinzipien
beim Design kann aber helfen, grobe Schnitzer zu vermeiden. Überdies taugt die Liste
der Prinzipien in Kundengesprächen gut zum Bullshit-Bingo. 
- Keep it simple, stupid: Von der Implementierung einer Klasse bis zum Design der Architektur sollte alles so einfach wie möglich gehalten sein. Komplexität führt zu Unübersichtlichkeit und Fehlern. Anstatt eine Methode in zwölf Ebenen zu schachteln, sollten Sie lieber eine Pause machen und darüber nachdenken, wo in der Planung etwas falsch gelaufen sein könnte.
- Need to know: Beim Umgang mit Informationen sollten Sie sich immer die Frage stellen: »Wer muss was wissen?« Niemand muss mehr wissen als nötig. »Niemand« kann eine Person sein, eine App, eine Klasse, ein Server etc.
- Attack Surface Reduction: Die Anzahl der Eintrittspunkte für Daten (Entry Points) sollte immer so gering wie möglich sein. Bevor Sie auf dem iPhone einen Serverdienst starten, sollten Sie lieber darüber nachdenken, ob es nicht auch umgekehrt geht (als Client).
- Datensparsamkeit: Nur die Daten einfordern, verarbeiten und speichern, die für den Betrieb zwingend notwendig sind. Große Datenbanken üben eine magische Anziehungskraft auf Angreifer aus.
- Secure by Default: Sie sollten sicherheitsrelevante Optionen standardmäßig aktivieren und den Benutzer oder Administrator diese manuell deaktivieren lassen, wenn es denn unbedingt notwendig ist.
- Least Privilege: Verwenden Sie grundsätzlich die geringstmöglichen Rechte zur Ausführung von Operationen.
- Defense in Depth: Verlassen Sie sich niemals auf singuläre Sicherheitsmechanismen, sondern implementieren Sie verschiedene Stufen der Sicherheit.
7.3.4Threat Modeling aus der Tube – das Microsoft SDL Threat Modeling Tool
Wie wir in der Einführung zum Threat Modeling bereits erwähnt haben, wurde diese Methodik im Bereich der Softwareentwicklung ursprünglich von Microsoft eingeführt und verfeinert. Nach den großen Wurm-Plagen und den nicht abreißenden Meldungen über Sicherheitslücken in Microsoft-Produkten trat Microsoft im Jahr 2003 auf die Bremse und legte mit dem Security Push den Grundstein für den in den folgenden Jahren immer weiter intensivierten und verfeinerten Secure Development Lifecycle (SDL).
Neben dem Ziel, eigene Produkte sicherer zu machen, lässt Microsoft auch Dritte an seinen Erkenntnissen rund um den SDL teilhaben und hat dazu das Microsoft SDL Pro Network ins Leben gerufen. Auf der dazugehörenden Website (http://www.microsoft.com/security/sdl) gibt es das Microsoft SDL Threat Modeling Tool kostenlos zum Download. Dieses Tool bietet eine Oberfläche zum Erstellen eines Datenflussdiagramms und erstellt aus diesem DFD selbständig die Tabelle der für die Elemente des DFD potenziell gefährlichen Bedrohungen – einfacher geht es wirklich nicht.
Nun wäre Microsoft nicht Microsoft, wenn es an der Sache nicht einen klitzekleinen Haken gäbe. Dieser äußert sich dergestalt, dass zwar das Tool kostenlos ist, Sie zum Benutzen aber eine installierte Version von Visio auf dem Rechner haben müssen, da die DFD-Erstellung im Tool über die Visio-Engine erfolgt. Honi soit qui mal y pense ... Der Umstand, dass das Tool nur für Windows erhältlich ist, ergibt sich direkt aus dem Visio-Zwang und muss hier nicht extra erwähnt werden. Trotzdem ist es zurzeit das einzige Tool, das Threat Modeling am DFD ermöglicht und diese Aufgabe auch hinreichend gut erledigt. Daher lohnt sich, sofern Windows und Visio vorhanden sind, auf jeden Fall ein Blick auf das Tool.
Das Tool wurde von Entwicklern für Entwickler konzipiert und nicht von Security-Experten für Security-Experten. Das schlägt sich in der angenehm intuitiven, zielgerichteten und einfachen Bedienung nieder. Nach dem Start erstellt das Tool ein rudimentäres DFD, um die grundlegende Funktionsweise zu demonstrieren (siehe Abbildung 7.13).
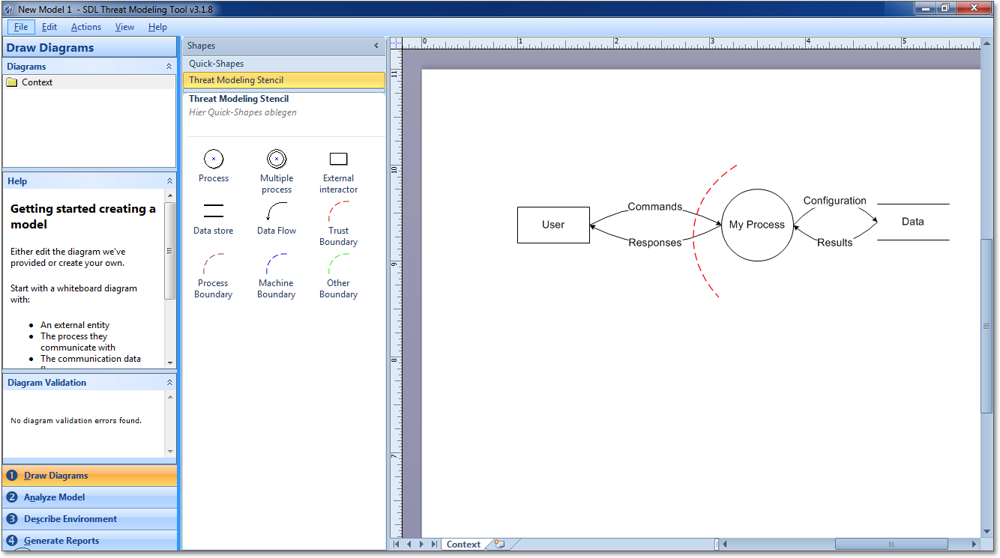
Abbildung 7.13 Das Microsoft SDL Threat Modeling Tool
Das DFD befindet sich, nicht zu übersehen, im rechten Teil des GUI. Links daneben, im Bereich Shapes, finden Sie alle Elemente, die Sie für die Erstellung eines DFD benötigen. Ziehen Sie die benötigten Elemente einfach in den Zeichenbereich rechts, und erstellen Sie die notwendigen Verknüpfungen.
Das Tool analysiert das DFD in Echtzeit und gibt Verstöße gegen die Semantik links im Bereich Diagram Validation aus. Das merken Sie spätestens dann, wenn Sie ein oder mehrere Elemente im DFD nicht korrekt verknüpft haben. So führt z. B. ein Prozess ohne Verbindungen zu der in Abbildung 7.14 gezeigten Fehlermeldung.
Der Bereich Help im linken Teil des GUI gibt eine Minimal-Anleitung für die Erstellung eines DFD und verweist auf die dem Tool beiliegende Hilfedatei, die übrigens sehr gut ist.
Links oben befindet sich im Bereich Diagrams die Übersicht über die Ebenen des DFD. Fügen Sie mit der rechten Maustaste einfach weitere Ebenen hinzu, wenn Sie Ihr Diagramm weiter aufteilen möchten. Das DFD unserer Beispiel-App lässt sich somit ohne großen Aufwand über alle Ebenen in dem Tool darstellen (siehe Abbildung 7.15).

Abbildung 7.14 Das Tool meldet einen Validierungsfehler.

Abbildung 7.15 DFD der Beispiel-App im Threat Modeling Tool
Der wahre Nutzen des Tools ergibt sich erst aus der Transformation der DFD-Elemente in die Liste der STRIDE-Kategorien. Dies erfolgt über den Button Analyze Model links unten im Fenster. Das Tool erstellt eine Liste der DFD-Elemente und fügt jedem Element die STRIDE-Bedrohungen hinzu, die für dieses Element wirken können (siehe die Zuordnungen in Abbildung 7.16).
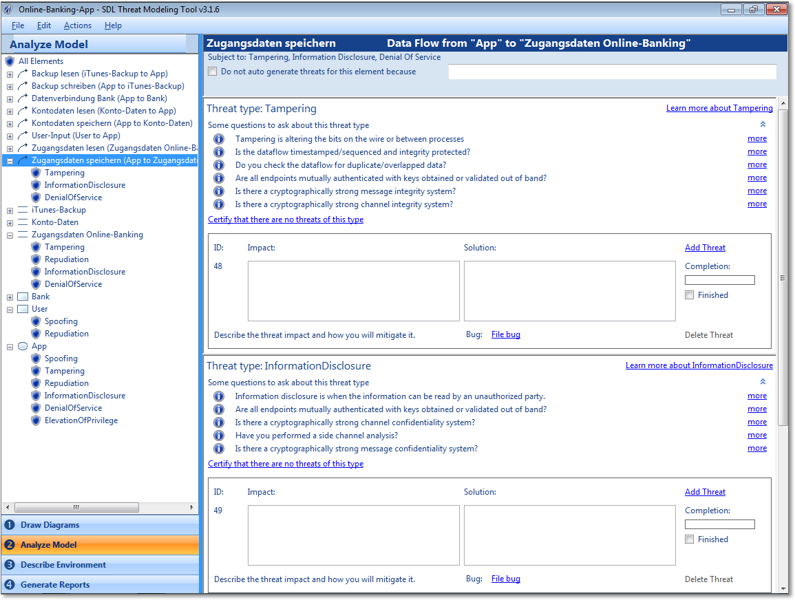
Abbildung 7.16 Die Liste der DFD-Elemente und ihrer STRIDE-Bedrohungen
Durch Auswahl eines Elements öffnet sich rechts im Fenster die Liste der STRIDE-Bedrohungen. Neben einigen Informationen und Beispielen zu den einzelnen Bedrohungen gibt es dort für jede Bedrohung ein Textfeld mit dem Titel Impact und eines mit dem Titel Solution (siehe Abbildung 7.17). Im Feld Impact formulieren Sie die von Ihnen identifizierte Bedrohung und im Feld Solution die entsprechende Maßnahme.
Möchten Sie keine Bedrohung formulieren, beispielsweise weil Ihnen keine einfällt oder weil Sie eine mögliche Bedrohung als akzeptabel erachten, klicken Sie auf den Link Certify that there are no threat of this type und geben die Begründung für diese Entscheidung an (siehe Abbildung 7.18).

Abbildung 7.17 Spoofing für das Element »User«

Abbildung 7.18 Ein akzeptiertes Risiko
Über den Button Describe Environment unten links im Fenster können Sie Metadaten zum Threat Model angeben, die das Tool in den Bericht übernimmt. Dies ist zu Dokumentationszwecken durchaus sinnvoll. Um einen Bericht zu erstellen, wählen Sie ebenfalls unten links Generate Reports aus und lassen sich das Threat Model anzeigen. Dieser Bericht enthält die von Ihnen angegebenen Metadaten, das oder die DFDs, eine nummerierte Aufzählung aller Elemente der DFDs sowie die komplette Liste aller von Ihnen formulierten Bedrohungen, Maßnahmen und Begründungen für akzeptierte Bedrohungen. Für Einsteiger in die Thematik, die Zugriff auf Windows und Visio haben, ist das Tool also eine sinnvolle Hilfe.

Abbildung 7.19 Der Threat-Model-Report
Verwirrende Tool-Vielfalt
Sie finden bei Microsoft zwei Tools zu dem Thema Threat Modeling. Eines ist das erwähnte Microsoft SDL Threat Modeling Tool, das andere heißt Microsoft Threat Analysis & Modeling. Das erste Tool haben Sie in diesem Abschnitt kennengelernt. Das zweite ist ein Tool, das Threat Modeling aus einer anderen Perspektive als dem DFD betrachtet. In diesem Tool, das übrigens auch kostenlos ist und ohne weitere Zusatzsoftware funktioniert (unter Windows), erfolgt das Identifizieren von Bedrohungen über Anwendungsfälle.
Der Benutzer muss eine Liste aller Anwendungsfälle seiner App erstellen, und das Tool versucht, zu diesen Anwendungsfällen aus einer Bedrohungsdatenbank selbständig Bedrohungen zu identifizieren. Der Ansatz ist interessant, die Umsetzung ist aber wenig gelungen, und überdies wird das Tool von Microsoft nicht weiter gepflegt. Es lohnt sich also nicht, sich näher damit zu beschäftigen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen


